Hadoop入门进阶课程5--MapReduce原理及操作
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,博主为石山园,博客地址为 http://www.cnblogs.com/shishanyuan 。该系列课程是应邀实验楼整理编写的,这里需要赞一下实验楼提供了学习的新方式,可以边看博客边上机实验,课程地址为 https://www.shiyanlou.com/courses/237
【注】该系列所使用到安装包、测试数据和代码均可在百度网盘下载,具体地址为 http://pan.baidu.com/s/10PnDs,下载该PDF文件
1、环境说明
部署节点操作系统为CentOS,防火墙和SElinux禁用,创建了一个shiyanlou用户并在系统根目录下创建/app目录,用于存放Hadoop等组件运行包。因为该目录用于安装hadoop等组件程序,用户对shiyanlou必须赋予rwx权限(一般做法是root用户在根目录下创建/app目录,并修改该目录拥有者为shiyanlou(chown –R shiyanlou:shiyanlou /app)。
Hadoop搭建环境:
l 虚拟机操作系统: CentOS6.6 64位,单核,1G内存
l JDK:1.7.0_55 64位
l Hadoop:1.1.2
2、MapReduce原理
2.1 MapReduce简介
MapReduce 是现今一个非常流行的分布式计算框架,它被设计用于并行计算海量数据。第一个提出该技术框架的是Google 公司,而Google 的灵感则来自于函数式编程语言,如LISP,Scheme,ML 等。MapReduce 框架的核心步骤主要分两部分:Map 和Reduce。当你向MapReduce 框架提交一个计算作业时,它会首先把计算作业拆分成若干个Map 任务,然后分配到不同的节点上去执行,每一个Map 任务处理输入数据中的一部分,当Map 任务完成后,它会生成一些中间文件,这些中间文件将会作为Reduce 任务的输入数据。Reduce 任务的主要目标就是把前面若干个Map 的输出汇总到一起并输出。从高层抽象来看,MapReduce的数据流图如下图所示:
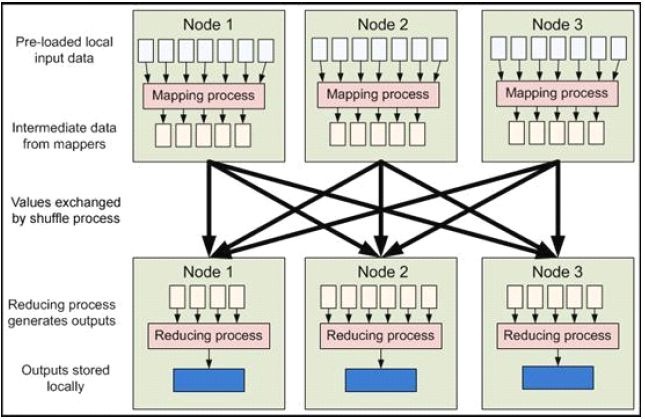
2.2 MapReduce流程分析
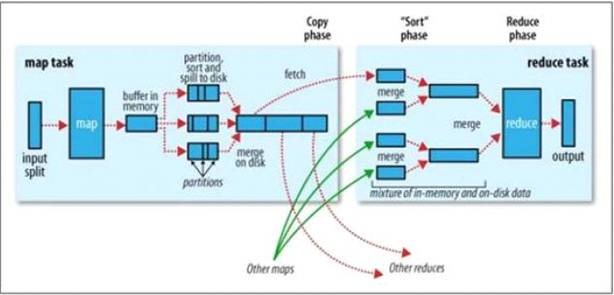
2.2.1 Map过程
1. 每个输入分片会让一个map任务来处理,默认情况下,以HDFS的一个块的大小(默认为64M)为一个分片,当然我们也可以设置块的大小。map输出的结果会暂且放在一个环形内存缓冲区中(该缓冲区的大小默认为100M,由io.sort.mb属性控制),当该缓冲区快要溢出时(默认为缓冲区大小的80%,由io.sort.spill.percent属性控制),会在本地文件系统中创建一个溢出文件,将该缓冲区中的数据写入这个文件;
2. 在写入磁盘之前,线程首先根据reduce任务的数目将数据划分为相同数目的分区,也就是一个reduce任务对应一个分区的数据。这样做是为了避免有些reduce任务分配到大量数据,而有些reduce任务却分到很少数据,甚至没有分到数据的尴尬局面。其实分区就是对数据进行hash的过程。然后对每个分区中的数据进行排序,如果此时设置了Combiner,将排序后的结果进行Combia操作,这样做的目的是让尽可能少的数据写入到磁盘;
3. 当map任务输出最后一个记录时,可能会有很多的溢出文件,这时需要将这些文件合并。合并的过程中会不断地进行排序和combia操作,目的有两个:
l尽量减少每次写入磁盘的数据量
l尽量减少下一复制阶段网络传输的数据量。最后合并成了一个已分区且已排序的文件。为了减少网络传输的数据量,这里可以将数据压缩,只要将mapred.compress.map.out设置为true就可以了
4. 将分区中的数据拷贝给相对应的reduce任务。有人可能会问:分区中的数据怎么知道它对应的reduce是哪个呢?其实map任务一直和其父TaskTracker保持联系,而TaskTracker又一直和JobTracker保持心跳。所以JobTracker中保存了整个集群中的宏观信息。只要reduce任务向JobTracker获取对应的map输出位置就可以了。
2.2.2 Reduce过程
1. Reduce会接收到不同map任务传来的数据,并且每个map传来的数据都是有序的。如果reduce端接受的数据量相当小,则直接存储在内存中(缓冲区大小由mapred.job.shuffle.input.buffer.percent属性控制,表示用作此用途的堆空间的百分比),如果数据量超过了该缓冲区大小的一定比例(由mapred.job.shuffle.merge.percent决定),则对数据合并后溢写到磁盘中;
2. 随着溢写文件的增多,后台线程会将它们合并成一个更大的有序的文件,这样做是为了给后面的合并节省时间。其实不管在map端还是reduce端,MapReduce都是反复地执行排序,合并操作;
3. 合并的过程中会产生许多的中间文件(写入磁盘了),但MapReduce会让写入磁盘的数据尽可能地少,并且最后一次合并的结果并没有写入磁盘,而是直接输入到reduce函数。
2.3 MapReduce工作机制剖析
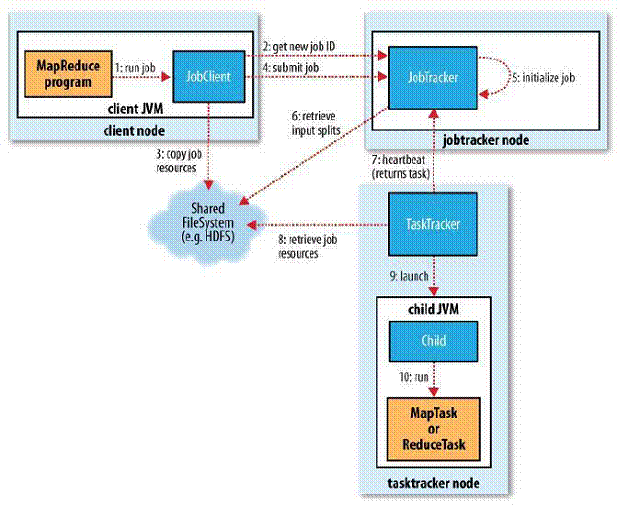
1.在集群中的任意一个节点提交MapReduce程序;
2.JobClient收到作业后,JobClient向JobTracker请求获取一个Job ID;
3.将运行作业所需要的资源文件复制到HDFS上(包括MapReduce程序打包的JAR文件、配置文件和客户端计算所得的输入划分信息),这些文件都存放在JobTracker专门为该作业创建的文件夹中,文件夹名为该作业的Job ID;
4.获得作业ID后,提交作业;
5.JobTracker接收到作业后,将其放在一个作业队列里,等待作业调度器对其进行调度,当作业调度器根据自己的调度算法调度到该作业时,会根据输入划分信息为每个划分创建一个map任务,并将map任务分配给TaskTracker执行;
6.对于map和reduce任务,TaskTracker根据主机核的数量和内存的大小有固定数量的map槽和reduce槽。这里需要强调的是:map任务不是随随便便地分配给某个TaskTracker的,这里有个概念叫:数据本地化(Data-Local)。意思是:将map任务分配给含有该map处理的数据块的TaskTracker上,同时将程序JAR包复制到该TaskTracker上来运行,这叫“运算移动,数据不移动”;
7.TaskTracker每隔一段时间会给JobTracker发送一个心跳,告诉JobTracker它依然在运行,同时心跳中还携带着很多的信息,比如当前map任务完成的进度等信息。当JobTracker收到作业的最后一个任务完成信息时,便把该作业设置成“成功”。当JobClient查询状态时,它将得知任务已完成,便显示一条消息给用户;
8.运行的TaskTracker从HDFS中获取运行所需要的资源,这些资源包括MapReduce程序打包的JAR文件、配置文件和客户端计算所得的输入划分等信息;
9.TaskTracker获取资源后启动新的JVM虚拟机;
10. 运行每一个任务;
3、测试例子1
3.1 测试例子1内容
下载气象数据集部分数据,写一个Map-Reduce作业,求每年的最低温度
3.2 运行代码
3.2.1 MinTemperature
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class MinTemperature { public static void main(String[] args) throws Exception {
if(args.length != 2) {
System.err.println("Usage: MinTemperature<input path> <output path>");
System.exit(-1);
} Job job = new Job();
job.setJarByClass(MinTemperature.class);
job.setJobName("Min temperature");
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
job.setMapperClass(MinTemperatureMapper.class);
job.setReducerClass(MinTemperatureReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
3.2.2 MinTemperatureMapper
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper; public class MinTemperatureMapper extends Mapper<LongWritable, Text, Text, IntWritable>{ private static final int MISSING = 9999; @Override
public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { String line = value.toString();
String year = line.substring(15, 19); int airTemperature;
if(line.charAt(87) == '+') {
airTemperature = Integer.parseInt(line.substring(88, 92));
} else {
airTemperature = Integer.parseInt(line.substring(87, 92));
} String quality = line.substring(92, 93);
if(airTemperature != MISSING && quality.matches("[01459]")) {
context.write(new Text(year), new IntWritable(airTemperature));
}
}
}
3.2.3 MinTemperatureReducer
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer; public class MinTemperatureReducer extends Reducer<Text, IntWritable, Text, IntWritable> { @Override
public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { int minValue = Integer.MAX_VALUE;
for(IntWritable value : values) {
minValue = Math.min(minValue, value.get());
}
context.write(key, new IntWritable(minValue));
}
}
3.3 实现过程
3.3.1 编写代码
进入/app/hadoop-1.1.2/myclass目录,在该目录中建立MinTemperature.java、MinTemperatureMapper.java和MinTemperatureReducer.java代码文件,执行命令如下:
cd /app/hadoop-1.1.2/myclass/
vi MinTemperature.java
vi MinTemperatureMapper.java
vi MinTemperatureReducer.java
MinTemperature.java:
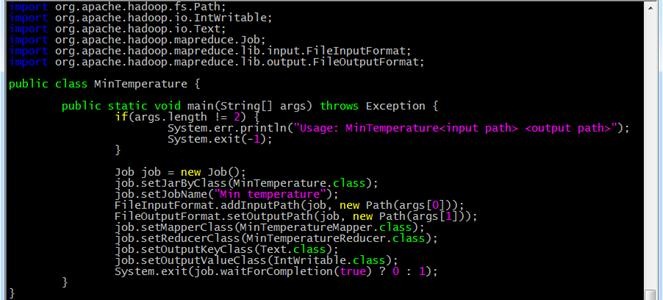
MinTemperatureMapper.java:
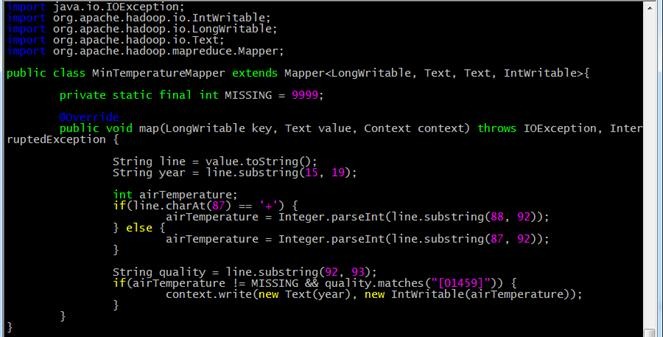
MinTemperatureReducer.java:

3.3.2 编译代码
在/app/hadoop-1.1.2/myclass目录中,使用如下命令对java代码进行编译,为保证编译成功,加入classpath变量,引入hadoop-core-1.1.2.jar包:
javac -classpath ../hadoop-core-1.1.2.jar *.java
3.3.3 打包编译文件
把编译好class文件打包,否则在执行过程会发生错误。把打好的包移动到上级目录并删除编译好的class文件:
jar cvf ./MinTemperature.jar ./Min*.class
mv *.jar ..
rm Min*.class
3.3.4 解压气象数据并上传到HDFS中
把NCDC气象数据解压,并使用zcat命令把这些数据文件解压并合并到一个temperature.txt文件中
cd /home/shiyanlou
unzip temperature
cd temperature
zcat *.gz > temperature.txt

气象数据具体的下载地址为 ftp://ftp3.ncdc.noaa.gov/pub/data/noaa/ ,该数据包括1900年到现在所有年份的气象数据,大小大概有70多个G,为了测试简单,我们这里选取一部分的数据进行测试。合并后把这个文件上传到HDFS文件系统的/class5/in目录中:
hadoop fs -mkdir -p /class5/in
hadoop fs -copyFromLocal temperature.txt /class5/in
hadoop fs -ls /class5/in

3.3.5 运行程序
以jar的方式启动MapReduce任务,执行输出目录为/class5/out:
cd /app/hadoop-1.1.2
hadoop jar MinTemperature.jar MinTemperature /class5/in/temperature.txt /class5/out
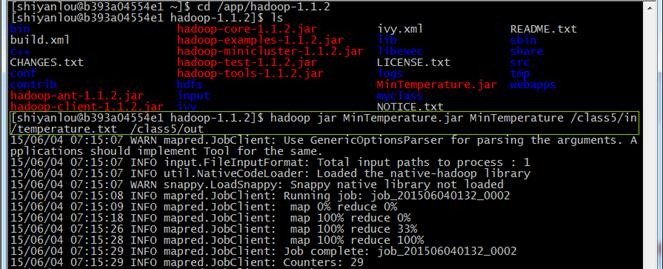
3.3.6 查看结果
执行成功后,查看/class5/out目录中是否存在运行结果,使用cat查看结果(温度需要除以10):
hadoop fs -ls /class5/out
hadoop fs -cat /class5/out/part-r-00000

3.3.7 通过页面结果(由于实验楼环境是命令行界面,以下仅为说明运行过程和结果可以通过界面进行查看)
1.查看jobtracker.jsp
http://XX. XXX.XX.XXX:50030/jobtracker.jsp
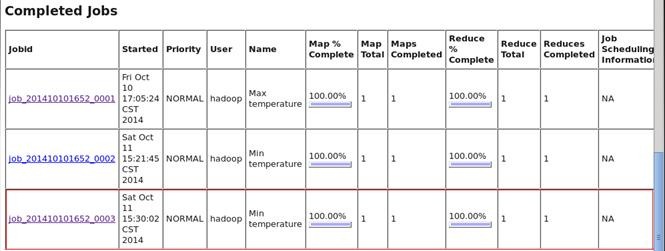
查看已经完成的作业任务:
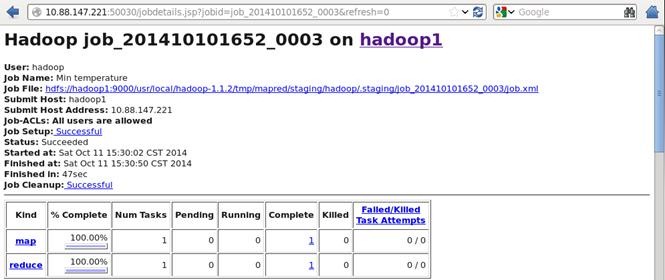
任务的详细信息:
2. 查看dfshealth.jsp
http://XX. XXX.XX.XXX:50070/dfshealth.jsp
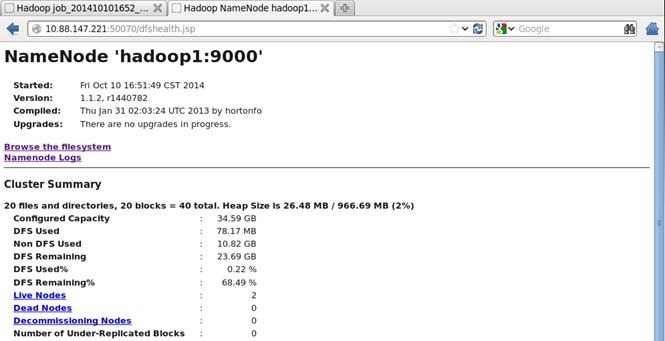
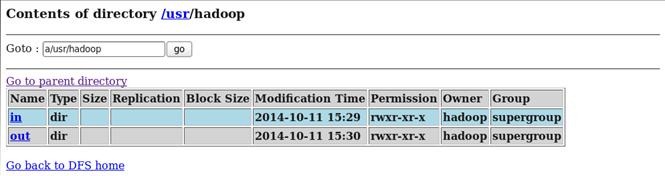
分别查看HDFS文件系统和日志
4、测试例子2
4.1 测试例子2内容
如果求温度的平均值,能使用combiner吗?有没有变通的方法?
4.2 回答
不能直接使用,因为求平均值和前面求最值存在差异,各局部最值的最值还是等于整体的最值的,但是对于平均值而言,各局部平均值的平均值将不再是整体的平均值了,所以不能直接用combiner。可以通过变通的办法使用combiner来计算平均值,即在combiner的键值对中不直接存储最后的平均值,而是存储所有值的和个数,最后在reducer输出时再用和除以个数得到平均值。
4.3 程序代码
4.3.1 AvgTemperature.java
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class AvgTemperature { public static void main(String[] args) throws Exception { if(args.length != 2) {
System.out.println("Usage: AvgTemperatrue <input path><output path>");
System.exit(-1);
} Job job = new Job();
job.setJarByClass(AvgTemperature.class);
job.setJobName("Avg Temperature");
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1])); job.setMapperClass(AvgTemperatureMapper.class);
job.setCombinerClass(AvgTemperatureCombiner.class);
job.setReducerClass(AvgTemperatureReducer.class); job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class); job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class); System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
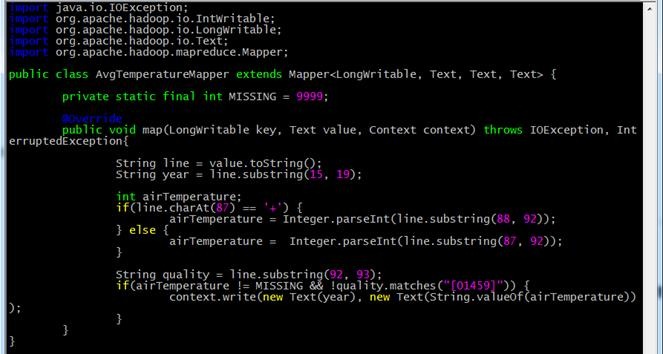
4.3.2 AvgTemperatureMapper.java
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper; public class AvgTemperatureMapper extends Mapper<LongWritable, Text, Text, Text> { private static final int MISSING = 9999; @Override
public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException{ String line = value.toString();
String year = line.substring(15, 19); int airTemperature;
if(line.charAt(87) == '+') {
airTemperature = Integer.parseInt(line.substring(88, 92));
} else {
airTemperature = Integer.parseInt(line.substring(87, 92));
} String quality = line.substring(92, 93);
if(airTemperature != MISSING && !quality.matches("[01459]")) {
context.write(new Text(year), new Text(String.valueOf(airTemperature)));
}
}
}
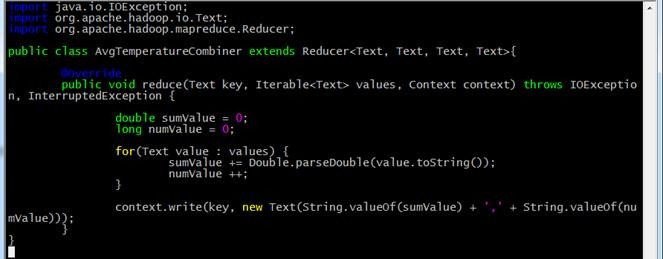
4.3.3 AvgTemperatureCombiner.java
import java.io.IOException;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer; public class AvgTemperatureCombiner extends Reducer<Text, Text, Text, Text>{ @Override
public void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException { double sumValue = 0;
long numValue = 0; for(Text value : values) {
sumValue += Double.parseDouble(value.toString());
numValue ++;
} context.write(key, new Text(String.valueOf(sumValue) + ',' + String.valueOf(numValue)));
}
}
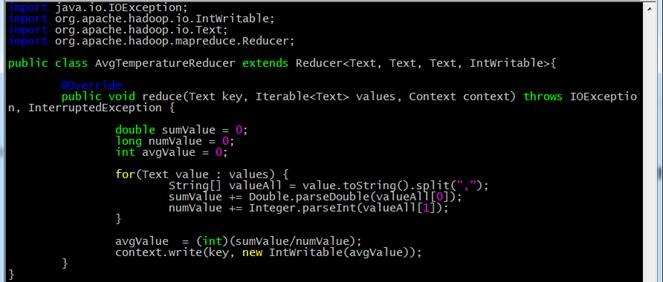
4.3.4 AvgTemperatureReducer.java
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer; public class AvgTemperatureReducer extends Reducer<Text, Text, Text, IntWritable>{ @Override
public void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException { double sumValue = 0;
long numValue = 0;
int avgValue = 0; for(Text value : values) {
String[] valueAll = value.toString().split(",");
sumValue += Double.parseDouble(valueAll[0]);
numValue += Integer.parseInt(valueAll[1]);
} avgValue = (int)(sumValue/numValue);
context.write(key, new IntWritable(avgValue));
}
}
4.4 实现过程
4.4.1 编写代码
进入/app/hadoop-1.1.2/myclass目录,在该目录中建立AvgTemperature.java、AvgTemperatureMapper.java、AvgTemperatureCombiner.java和AvgTemperatureReducer.java代码文件,代码内容为4.3所示,执行命令如下:
cd /app/hadoop-1.1.2/myclass/
vi AvgTemperature.java
vi AvgTemperatureMapper.java
vi AvgTemperatureCombiner.java
vi AvgTemperatureReducer.java
AvgTemperature.java:
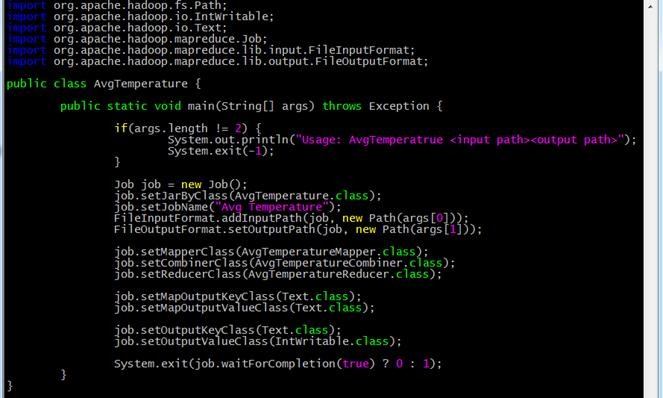
AvgTemperatureMapper.java:
AvgTemperatureCombiner.java:
AvgTemperatureReducer.java:
4.4.2 编译代码
在/app/hadoop-1.1.2/myclass目录中,使用如下命令对java代码进行编译,为保证编译成功,加入classpath变量,引入hadoop-core-1.1.2.jar包:
javac -classpath ../hadoop-core-1.1.2.jar Avg*.java
4.4.3 打包编译文件
把编译好class文件打包,否则在执行过程会发生错误。把打好的包移动到上级目录并删除编译好的class文件:
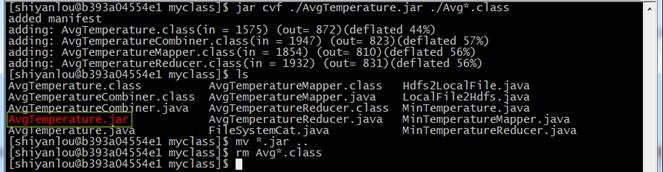
jar cvf ./AvgTemperature.jar ./Avg*.class
ls
mv *.jar ..
rm Avg*.class
4.4.4 运行程序
数据使用作业2求每年最低温度的气象数据,数据在HDFS位置为/class5/in/temperature.txt,以jar的方式启动MapReduce任务,执行输出目录为/class5/out2:
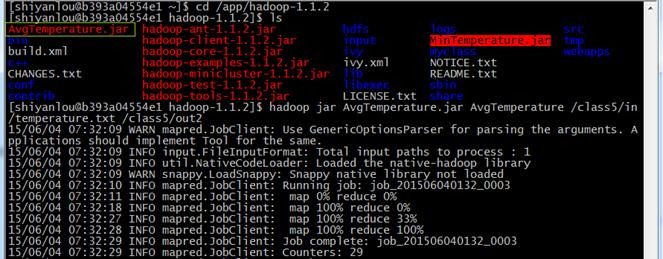
cd /app/hadoop-1.1.2
hadoop jar AvgTemperature.jar AvgTemperature /class5/in/temperature.txt /class5/out2
4.4.5 查看结果
执行成功后,查看/class5/out2目录中是否存在运行结果,使用cat查看结果(温度需要除以10):
hadoop fs -ls /class5/out2
hadoop fs -cat /class5/out2/part-r-00000

Hadoop入门进阶课程5--MapReduce原理及操作的更多相关文章
- Hadoop入门进阶课程4--HDFS原理及操作
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,博主为石山园,博客地址为 http://www.cnblogs.com/shishanyuan ...
- Hadoop入门进阶课程1--Hadoop1.X伪分布式安装
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,博主为石山园,博客地址为 http://www.cnblogs.com/shishanyuan ...
- (转)Hadoop入门进阶课程
http://blog.csdn.net/yirenboy/article/details/46800855 1.Hadoop介绍 1.1Hadoop简介 Apache Hadoop软件库是一个框架, ...
- Hadoop入门进阶课程11--Sqoop介绍、安装与操作
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,博主为石山园,博客地址为 http://www.cnblogs.com/shishanyuan ...
- Hadoop入门进阶课程10--HBase介绍、安装与应用案例
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,博主为石山园,博客地址为 http://www.cnblogs.com/shishanyuan ...
- Hadoop入门进阶课程9--Mahout介绍、安装与应用案例
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,博主为石山园,博客地址为 http://www.cnblogs.com/shishanyuan ...
- Hadoop入门进阶课程8--Hive介绍和安装部署
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,博主为石山园,博客地址为 http://www.cnblogs.com/shishanyuan ...
- Hadoop入门进阶课程7--Pig介绍、安装与应用案例
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,博主为石山园,博客地址为 http://www.cnblogs.com/shishanyuan ...
- Hadoop入门进阶课程6--MapReduce应用案例
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,博主为石山园,博客地址为 http://www.cnblogs.com/shishanyuan ...
随机推荐
- Swift - UITableViewCell倒计时重用解决方案
Swift - UITableViewCell倒计时重用解决方案 效果 源码 https://github.com/YouXianMing/Swift-Animations // // CountDo ...
- Weblogic Session复制策略与方式
在Weblogic中,HttpSession Replication的方式是通过在weblogic.xml中的session- descriptor的定义persistent-store-type来实 ...
- RESTful 接口规范
原文地址:http://www.coderli.com/translate-restful-standard-resolved OneCoder最近一直在使用Restful API,最近正好看到一篇自 ...
- nginx+tomcat+java部署总结
昨天部署了一下nginx+tomcat+java出现了很多问题,以下为整理总结. 使用了两种部署方式,一种是源码部署,一种是war部署. java源码部署总结: 环境:nginx+tomcat 部署方 ...
- C++ 代码换行
1.字符串太长,换行显示,怎么办?2.使用反斜杠,如下: string str = "abcd\ 1234"; 注意:反斜杠后面不准有任何字符.下一行开头的制表符不包含在整个字符串 ...
- python 与数据结构
在上面的文章中,我写了python中的一些特性,主要是简单为主,主要是因为一些其他复杂的东西可以通过简单的知识演变而来,比如装饰器还可以带参数,可以使用装饰类,在类中不同的方法中调用,不想写的太复杂, ...
- SQL Server 2016 需要单独安装SSMS
默认安装完 MSSQL 后,不自带 SSMS 的管理工具了,需要的话可以单独安装,貌似更专业了一些. https://msdn.microsoft.com/library/mt238290.aspx ...
- jarsigner 签名android apk
1.查看签名: jarsigner -verify app_signed.apk 查看是否签名,如果已经签名会打印 "jar verified". jarsigner -verif ...
- [转载] linux下打开windows txt文件中文乱码问题
原文链接 在linux操作系统下,我们有时打开在windows下的txt文件,发现在windows下能正常显示的txt文件出现了中文乱码. 出现这种情况的原因为两种操作系统的中文压缩方式不同,在win ...
- JAVA本地远程连接linux程序监控状态
环境: 1.本地window 2.程序部署在centos 一,启动访问权限安全守护程序 新建文件:jstatd.all.policy ,注意路径 grant codebase "$JA ...