go中waitGroup源码解读
waitGroup源码刨铣
前言
学习下waitGroup的实现
本文是在go version go1.13.15 darwin/amd64上进行的
WaitGroup实现
看一个小demo
func waitGroup() {
var wg sync.WaitGroup
wg.Add(4)
go func() {
defer wg.Done()
fmt.Println(1)
}()
go func() {
defer wg.Done()
fmt.Println(2)
}()
go func() {
defer wg.Done()
fmt.Println(3)
}()
go func() {
defer wg.Done()
fmt.Println(4)
}()
wg.Wait()
fmt.Println("1 2 3 4 end")
}
1、启动goroutine前将计数器通过Add(4)将计数器设置为待启动的goroutine个数。
2、启动goroutine后,使用Wait()方法阻塞主协程,等待计数器变为0。
3、每个goroutine执行结束通过Done()方法将计数器减1。
4、计数器变为0后,阻塞的goroutine被唤醒。
看下具体的实现
// WaitGroup 不能被copy
type WaitGroup struct {
noCopy noCopy
state1 [3]uint32
}
noCopy
意思就是不让copy,是如何实现的呢?
Go中没有原生的禁止拷贝的方式,所以如果有的结构体,你希望使用者无法拷贝,只能指针传递保证全局唯一的话,可以这么干,定义 一个结构体叫 noCopy,实现如下的接口,然后嵌入到你想要禁止拷贝的结构体中,这样go vet就能检测出来。
// noCopy may be embedded into structs which must not be copied
// after the first use.
//
// See https://golang.org/issues/8005#issuecomment-190753527
// for details.
type noCopy struct{}
// Lock is a no-op used by -copylocks checker from `go vet`.
func (*noCopy) Lock() {}
func (*noCopy) Unlock() {}
测试下
type noCopy struct{}
func (*noCopy) Lock() {}
func (*noCopy) Unlock() {}
type Person struct {
noCopy noCopy
name string
}
// go中的函数传参都是值拷贝
func test(person Person) {
fmt.Println(person)
}
func main() {
var person Person
test(person)
}
go vet main.go
$ go vet main.go
# command-line-arguments
./main.go:18:18: test passes lock by value: command-line-arguments.Person contains command-line-arguments.noCopy
./main.go:19:14: call of fmt.Println copies lock value: command-line-arguments.Person contains command-line-arguments.noCopy
./main.go:24:7: call of test copies lock value: command-line-arguments.Person contains command-line-arguments.noCopy
使用vet检测到了不能copy的错误
state1
// 64 位值: 高 32 位用于计数,低 32 位用于等待计数
// 64 位的原子操作要求 64 位对齐,但 32 位编译器无法保证这个要求
// 因此分配 12 字节然后将他们对齐,其中 8 字节作为状态,其他 4 字节用于存储原语
state1 [3]uint32
这点是wait_group很巧妙的一点,大神写代码的思路就是惊奇
这个设计很奇妙,通过内存对齐来处理wait_group中的waiter数、计数值、信号量。什么是内存对齐可参考什么是内存对齐,go中内存对齐分析
来分析下state1是如何内存对齐来处理几个计数值的存储
计算机为了加快内存的访问速度,会对内存进行对齐处理,CPU把内存当作一块一块的,块的大小可以是2、4、8、16字节大小,因此CPU读取内存是一块一块读取的。
合理的内存对齐可以提高内存读写的性能,并且便于实现变量操作的原子性。
在不同平台上的编译器都有自己默认的 “对齐系数”,可通过预编译命令#pragma pack(n)进行变更,n就是代指 “对齐系数”。
一般来讲,我们常用的平台的系数如下:
32 位:4
64 位:8
state1这块就兼容了两种平台的对齐系数
对于64未系统来讲。内存访问的步长是8。也就是cpu一次访问8位偏移量的内存空间。当时对于32未的系统,内存的对齐系数是4,也就是访问的步长是4个偏移量。
所以为了兼容这两种模式,这里采用了uint32结构的数组,保证在不同类型的机器上都是12个字节,一个uint32是4字节。这样对于32位的4步长访问是没有问题了,64位的好像也没有解决,8步长的访问会一次读入两个uint32的长度。
所以,下面的读取也进行了操作,将两个uint32的内存放到一个uint64中返回,这样就同时解决了32位和64位访问步长的问题。
所以,64位系统和32位系统,state1中counter,waiter,semaphore的内存布局是不一样的。
| state [0] | state [1] | state [2] | |
|---|---|---|---|
| 64位 | waiter | counter | semaphore |
| 32位 | semaphore | waiter | counter |
counter位于高地址位,waiter位于地址位
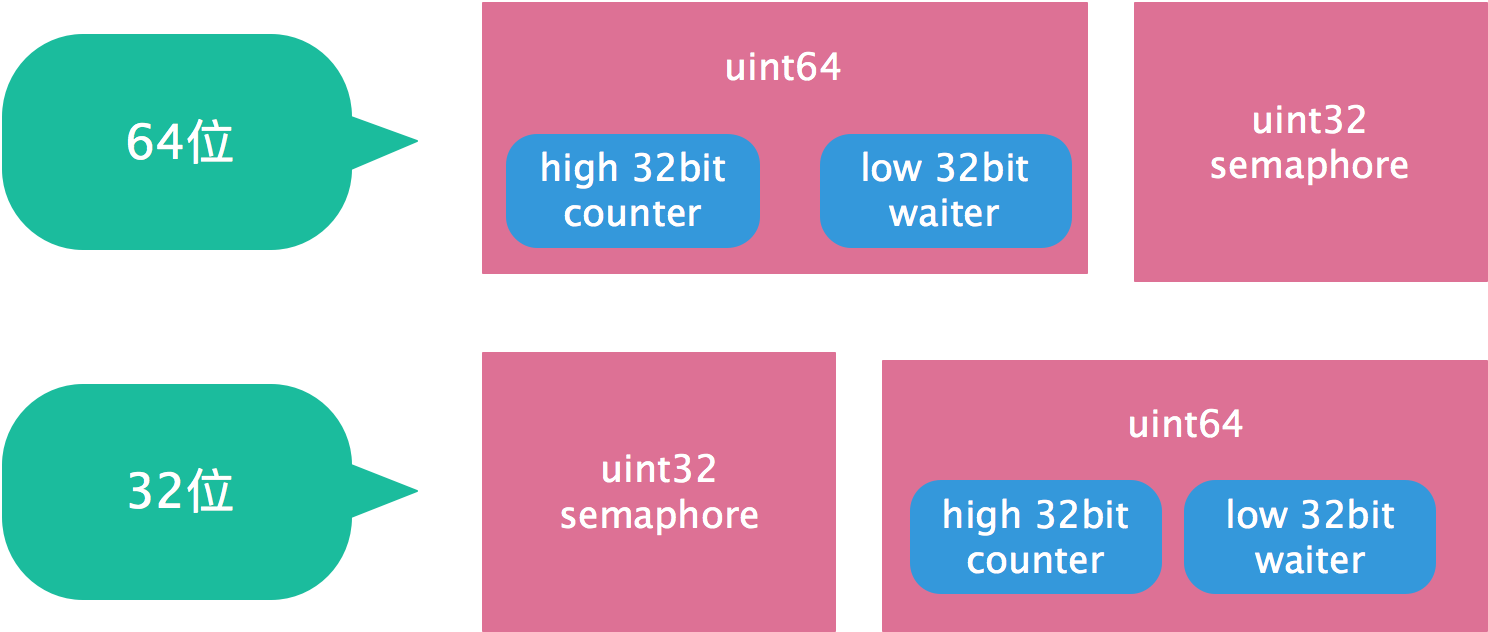
下面是state的代码
func (wg *WaitGroup) state() (statep *uint64, semap *uint32) {
// 判断是否是64位
if uintptr(unsafe.Pointer(&wg.state1))%8 == 0 {
return (*uint64)(unsafe.Pointer(&wg.state1)), &wg.state1[2]
} else {
return (*uint64)(unsafe.Pointer(&wg.state1[1])), &wg.state1[0]
}
}
对于count和wait在高低地址位的体现,在add中的代码可体现
// // 将 delta 加到 statep 的前 32 位上,即加到计数器上
state := atomic.AddUint64(statep, uint64(delta)<<32)
v := int32(state >> 32) // count
w := uint32(state) // wait
通过补码的移位来看下分析下
statep 0000 0000 0000 0000 0000 0000 0000 0001 0000 0000 0000 0000 0000 0000 0000 0000
int64(1) 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0001
int64(1)<<32: 0000 0000 0000 0000 0000 0000 0000 0001 0000 0000 0000 0000 0000 0000 0000 0000
statep+int64(1)<<32
state: 0000 0000 0000 0000 0000 0000 0000 0001 0000 0000 0000 0000 0000 0000 0000 0000
int32(state >> 32) 0000 0000 0000 0000 0000 0000 0000 0001
uint32(state): 0000 0000 0000 0000 0000 0000 0000 0000
再来看下-1操作
statep 0000 0000 0000 0000 0000 0000 0000 0001 0000 0000 0000 0000 0000 0000 0000 0000
int64(-1) 1111 1111 1111 1111 1111 1111 1111 1111 1111 1111 1111 1111 1111 1111 1111 1111
int64(-11)<<32: 1111 1111 1111 1111 1111 1111 1111 1111 0000 0000 0000 0000 0000 0000 0000 0000
statep+int64(-11)<<32
state: 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000
int32(state >> 32) 0000 0000 0000 0000 0000 0000 0000 0000
uint32(state): 0000 0000 0000 0000 0000 0000 0000 0000
关于补码的操作可参考原码, 反码, 补码 详解
信号量(semaphore)
信号量是Unix系统提供的一种保护共享资源的机制,用于防止多个线程同时访问某个资源。
可简单理解为信号量为一个数值:
当信号量>0时,表示资源可用,获取信号量时系统自动将信号量减1;
当信号量==0时,表示资源暂不可用,获取信号量时,当前线程会进入睡眠,当信号量为正时被唤醒。
WaitGroup中的实现就用到了这个,在下面的代码实现就能看到
Add(Done)
// Add将增量(可能为负)添加到WaitGroup计数器中。
// 如果计数器为零,则释放等待时阻塞的所有goroutine。
// 如果计数器变为负数,请添加恐慌。
//
// 请注意,当计数器为 0 时发生的带有正的 delta 的调用必须在 Wait 之前。
// 当计数器大于 0 时,带有负 delta 的调用或带有正 delta 调用可能在任何时候发生。
// 通常,这意味着对Add的调用应在语句之前执行创建要等待的goroutine或其他事件。
// 如果将WaitGroup重用于等待几个独立的事件集,新的Add调用必须在所有先前的Wait调用返回之后发生。
func (wg *WaitGroup) Add(delta int) {
// 获取counter,waiter,以及semaphore对应的指针
statep, semap := wg.state()
...
// 将 delta 加到 statep 的前 32 位上,即加到计数器上
state := atomic.AddUint64(statep, uint64(delta)<<32)
// 高地址位counter
v := int32(state >> 32)
// 低地址为waiter
w := uint32(state)
...
// 计数器不允许为负数
if v < 0 {
panic("sync: negative WaitGroup counter")
}
// wait不等于0说明已经执行了Wait,此时不容许Add
if w != 0 && delta > 0 && v == int32(delta) {
panic("sync: WaitGroup misuse: Add called concurrently with Wait")
}
// 计数器的值大于或者没有waiter在等待,直接返回
if v > 0 || w == 0 {
return
}
// 运行到这里只有一种情况 v == 0 && w != 0
// 这时 Goroutine 已经将计数器清零,且等待器大于零(并发调用导致)
// 这时不允许出现并发使用导致的状态突变,否则就应该 panic
// - Add 不能与 Wait 并发调用
// - Wait 在计数器已经归零的情况下,不能再继续增加等待器了
// 仍然检查来保证 WaitGroup 不会被滥用
// 这一点很重要,这段代码同时也保证了这是最后的一个需要等待阻塞的goroutine
// 然后在下面通过runtime_Semrelease,唤醒被信号量semap阻塞的waiter
if *statep != state {
panic("sync: WaitGroup misuse: Add called concurrently with Wait")
}
// 结束后将等待器清零
*statep = 0
for ; w != 0; w-- {
// 释放信号量,通过runtime_Semacquire唤醒被阻塞的waiter
runtime_Semrelease(semap, false, 0)
}
}
梳理下流程
1、首先获取存储在state1中对应的几个变量的指针;
2、counter存储在高位,增加的时候需要左移32位;
3、counter的数量不能小于0,小于0抛出panic;
4、同样也会判断,已经的执行wait之后,不能在增加counter;
5、(这点很重要,我自己看了好久才明白)计数器的值大于或者没有waiter在等待,直接返回
// 计数器的值大于或者没有waiter在等待,直接返回
if v > 0 || w == 0 {
return
}
因为waiter的值只会被执行一次+1操作,所以这段代码保证了只有在v == 0 && w != 0,也就是最后一个Done()操作的时候,走到下面的代码,释放信号量,唤醒被信号量阻塞的Wait(),结束整个WaitGroup。
Done()也是调用了Add
func (wg *WaitGroup) Done() {
wg.Add(-1)
}
Wait
// Wait blocks until the WaitGroup counter is zero.
func (wg *WaitGroup) Wait() {
// 获取counter,waiter,以及semaphore对应的指针
statep, semap := wg.state()
...
for {
// 获取对应的counter和waiter数量
state := atomic.LoadUint64(statep)
v := int32(state >> 32)
w := uint32(state)
// Counter为0,不需要等待
if v == 0 {
if race.Enabled {
race.Enable()
race.Acquire(unsafe.Pointer(wg))
}
return
}
// 原子(cas)增加waiter的数量(只会被+1操作一次)
if atomic.CompareAndSwapUint64(statep, state, state+1) {
...
// 这块用到了,我们上文讲的那个信号量
// 等待被runtime_Semrelease释放的信号量唤醒
// 如果 *semap > 0 则会减 1,等于0则被阻塞
runtime_Semacquire(semap)
// 在这种情况下,如果 *statep 不等于 0 ,则说明使用失误,直接 panic
if *statep != 0 {
panic("sync: WaitGroup is reused before previous Wait has returned")
}
...
return
}
}
}
梳理下流程
1、首先获取存储在state1中对应的几个变量的指针;
2、一个for循环,来阻塞等待所有的goroutine退出;
3、如果counter为0,不需要等待,直接退出即可;
4、原子(cas)增加waiter的数量(只会被+1操作一次);
5、整个Wait()会被runtime_Semacquire阻塞,直到等到退出的信号量;
6、Done()会在最后一次的时候通过runtime_Semrelease发出取消阻塞的信号,然后被runtime_Semacquire阻塞的Wait()就可以退出了;
7、整个WaitGroup执行成功。
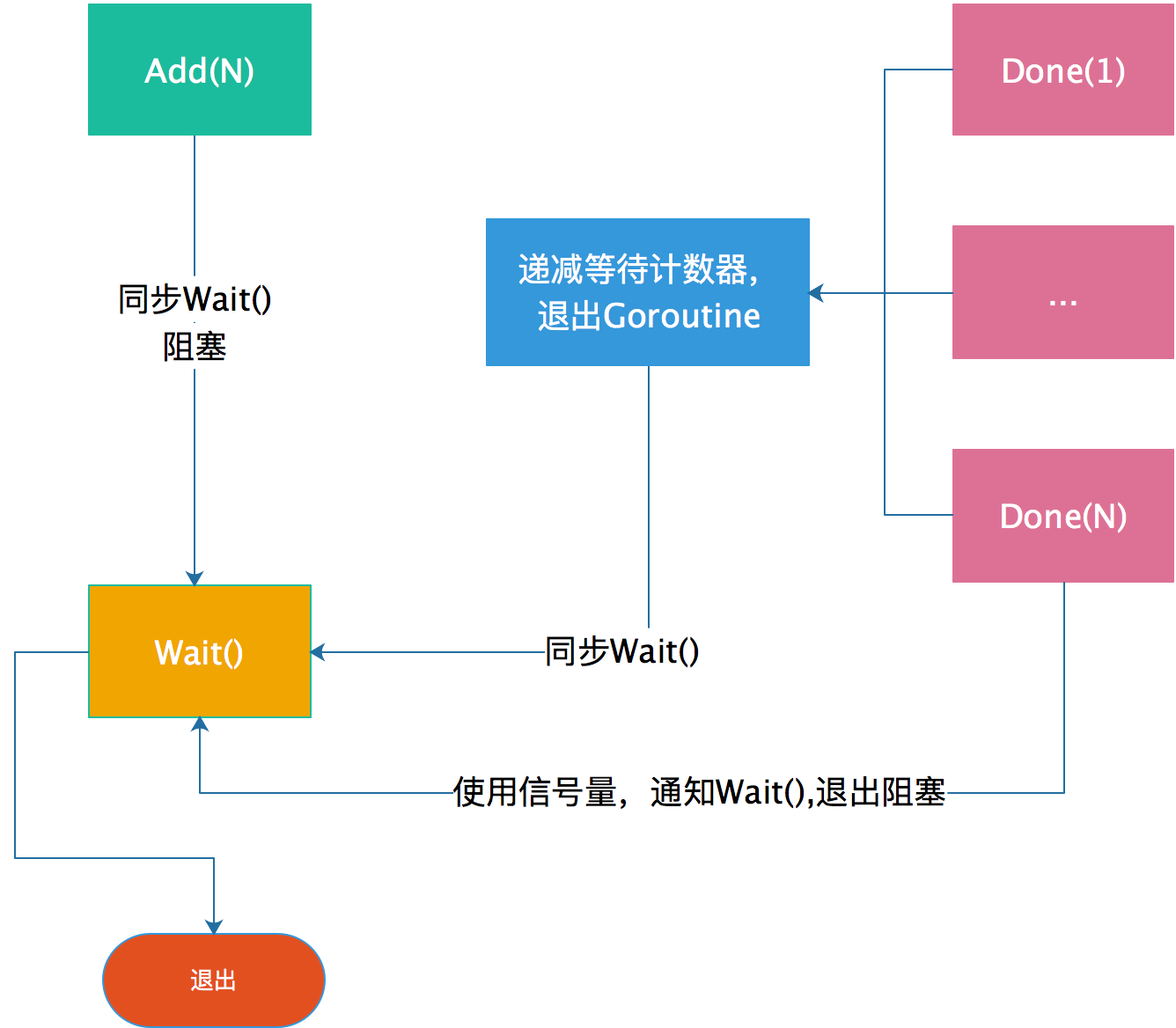
总结
代码中我感到设计比较巧妙的有两个部分:
1、state1的处理,保证内存对齐,设置高低位内存来存储不同的值,同时32位和64位平台的处理方式还不同;
2、信号量的阻塞退出,这块最后一个Done退出的时候,才会触发阻塞信号量,退出Wait(),然后结束整个waitGroup。再此之前,当Wait()在成功将waiter变量+1操作之后,就会被runtime_Semacquire阻塞,直到最后一个Done,信号的发出。
对于WaitGroup的使用
1、计数器的值不能为负数,可能是Add(-1)触发的,也可能是Done()触发的,否则会panic;
2、Add数量的添加,要发生在Wait()之前;
3、WaitGroup是可以重用的,但是需要等上一批的goroutine 都调用Wait完毕后才能继续重用WaitGroup。
参考
【《Go专家编程》Go WaitGroup实现原理】https://my.oschina.net/renhc/blog/2249061
【Go中由WaitGroup引发对内存对齐思考】https://cloud.tencent.com/developer/article/1776930
【Golang 之 WaitGroup 源码解析】https://www.linkinstar.wiki/2020/03/15/golang/source-code/sync-waitgroup-source-code/
【sync.WaitGroup】https://golang.design/under-the-hood/zh-cn/part1basic/ch05sync/waitgroup/
go中waitGroup源码解读的更多相关文章
- go中panic源码解读
panic源码解读 前言 panic的作用 panic使用场景 看下实现 gopanic gorecover fatalpanic 总结 参考 panic源码解读 前言 本文是在go version ...
- etcd中watch源码解读
etcd中watch的源码解析 前言 client端的代码 Watch newWatcherGrpcStream run newWatchClient serveSubstream server端的代 ...
- java中jdbc源码解读
在jdbc中一个重要的接口类就是java.sql.Driver,其中有一个重要的方法:Connection connect(String url, java.util.Propeties info); ...
- go中errgroup源码解读
errgroup 前言 如何使用 实现原理 WithContext Go Wait 错误的使用 总结 errgroup 前言 来看下errgroup的实现 如何使用 func main() { var ...
- 【原】Spark中Job的提交源码解读
版权声明:本文为原创文章,未经允许不得转载. Spark程序程序job的运行是通过actions算子触发的,每一个action算子其实是一个runJob方法的运行,详见文章 SparkContex源码 ...
- HttpServlet中service方法的源码解读
前言 最近在看<Head First Servlet & JSP>这本书, 对servlet有了更加深入的理解.今天就来写一篇博客,谈一谈Servlet中一个重要的方法-- ...
- AbstractCollection类中的 T[] toArray(T[] a)方法源码解读
一.源码解读 @SuppressWarnings("unchecked") public <T> T[] toArray(T[] a) { //size为集合的大小 i ...
- go 中 sort 如何排序,源码解读
sort 包源码解读 前言 如何使用 基本数据类型切片的排序 自定义 Less 排序比较器 自定义数据结构的排序 分析下源码 不稳定排序 稳定排序 查找 Interface 总结 参考 sort 包源 ...
- Mybatis源码解读-SpringBoot中配置加载和Mapper的生成
本文mybatis-spring-boot探讨在springboot工程中mybatis相关对象的注册与加载. 建议先了解mybatis在spring中的使用和springboot自动装载机制,再看此 ...
随机推荐
- python 引用(import)文件夹下的py文件
importlib.import_module动态导入模块: python中schedule模块的简单使用 || importlib.import_module动态导入模块 先看一下文件目录 1.同级 ...
- 国产网络损伤仪 SandStorm -- 只需要拖拽就能删除链路规则
国产网络损伤仪SandStorm可以模拟出带宽限制.时延.时延抖动.丢包.乱序.重复报文.误码.拥塞等网络状况,在实验室条件下准确可靠地测试出网络应用在真实网络环境中的性能,以帮助应用程序在上线部署前 ...
- Redis 主从复制(Replication)
为了保证服务的可用性,现代数据库都提供了复制功能,同时在多个进程中维护一致的数据状态. Redis 支持一主多从的复制架构,该功能被简化成了一条 SLAVEOF 命令,下面通过条命令来解析 Redis ...
- L3-002. 堆栈【主席树 or 线段树 or 分块】
L3-002. 堆栈 时间限制 200 ms 内存限制 65536 kB 代码长度限制 8000 B 判题程序 Standard 作者 陈越 大家都知道"堆栈"是一种"先 ...
- Rails框架学习
Don't Repeat Yourself! Convention Over Configuration. REST. Rails框架总览. Rails框架基本使用. Rails框架数据交互. Rai ...
- html5 image>usemap (attribute)
# html5 image>usemap (attribute) https://caniuse.com/#search=usemap http://www.w3.org/TR/html5 ...
- 微信小程序批量上传图片 All In One
微信小程序批量上传图片 All In One open-data https://developers.weixin.qq.com/miniprogram/dev/component/open-dat ...
- js var & let & const All In One
js var & let & const All In One js var & let & const 区别对比 var let const 区别 是否存在 hois ...
- macOS utils
macOS utils dr.unarchiver https://dr-unarchiver.en.softonic.com/mac https://dr-unarchiver.en.softoni ...
- nodejs 查看进程表
psaux tasklist system-tasks const { exec } = require("child_process"); const isWindows = p ...