BGP总结(三)
3.BGP路由汇总
在大规模的网络中,BGP路由表十分庞大,给设备造成了很大的负担,同时使发生路由振荡的几率也大大增加,影响网络的稳定性。路由聚合是将多条路由合并的机制,它通过只向对等体发送聚合后的路由而不是发送所有的具体路由的方法,减小路由表的规模。并且被聚合的路由如果发生路由振荡,也不再对网络造成影响,从而提高了网络的稳定性。
BGP在IPv4网络中支持自动聚合和手动聚合两种方式,而IPv6网络中仅支持手动聚合方式:
※自动汇总:对BGP引入的路由进行聚合。配置自动聚合后,BGP将按照自然网段聚合路由(例如非自然网段A类地址10.1.1.1/24和10.2.1.1/24将聚合为自然网段A类地址10.0.0.0/8),并且向对等体只发送聚合后的路由。
※手动汇总:对BGP本地路由表中存在的路由进行聚合。手动聚合可以控制聚合路由的属性,以及决定是否发布具体路由。
为了避免路由聚合可能引起的路由环路,BGP设计了AS_Set属性。AS_Set属性是一种无序的AS_Path属性,标明聚合路由所经过的AS号。当聚合路由重新进入AS_Set属性中列出的任何一个AS时,BGP将会检测到自己的AS号在聚合路由的AS_Set属性中,于是会丢弃该聚合路由,从而避免了路由环路的形成。
1)自动汇总
无论在路由器上是否开启auto-summary都不会影响BGP精确通告的BGP路由,该特性只有两个作用:
当在路由器上使用汇总通告的时候,如果该路由器路由表中,拥有汇总条目的明细路由的时候并且该路由器开启自动汇总,则该路由器会将明细路由抑制并且在其主类网络边界汇总后发送给邻居。
当在路由器的BGP进程中重发布外部路由器是,如果开启了auto-summary,那么该路由器会将这些路由以主类的形发送给邻居。还会将重发布进入的路由器的下一跳地址写为0.0.0.0,即便这些路由本身携带metric,在BGP表中也不会继承。
2)手动汇总
1、在本地创建一条指向null 0的聚合路由,并且该路由器上通告该聚合路由即可,并不需要通告明细路由。
创建环回:
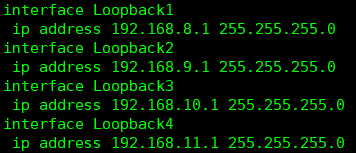
null 0聚合路由

宣告:

查看:show ip bgp
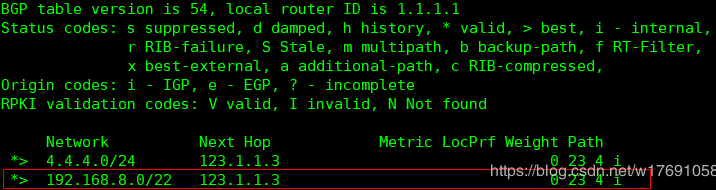
2、AGG聚合


AGG普通聚合后,聚合路由和明细路由均会发送

仅发送聚合路由summary-only


在R3上汇总R4的环回路由

在R3上做汇总会出现as-path中没出现R4中AS号,易形成路由黑洞

解决方法:
as-set:汇总路由不会再传回明细所在的路由器中
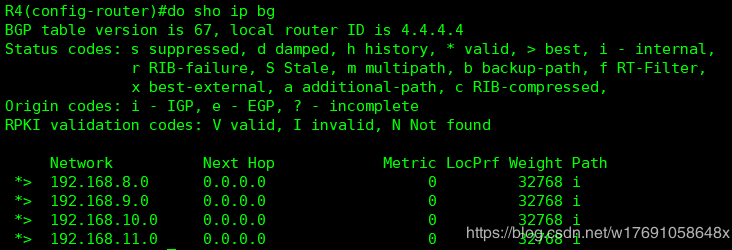
聚合原则:只要聚合命令配置了,该路由器如果在BGP表中拥有该聚合内的明细路由,则会直接在本地BGP表中生成该聚合路由,并且再通告给其他邻居。
4.BGP路由决策
BGP的RIB(Routing Information Base,路由选择信息库)包括三部分:
Adj-RIBs-In:存储了从对等体学习到的路由理新中未经处理的路由信息,这些包含在Adj-RIBs-In中的路由被认为是可行路由。
Loc-RIB:包含了BGP发言者对Adj-RIBs-In中的路由应用本地策略之后选定的路由
Adj-RIBs-Out:包含了BGP发言者向对等体宣告路由。
BGP有三个部分既可以是3个不同的数据库,也可以是利用指针来区分不同部分的单一数据库。BGP路由决策通过对Adj-RIBs-In中的路由应用本地路由策略,且向Loc-RIB 和Adj-RIBs-Out中输入选定或修改的路由进行路由选择。其有三个阶段。
第一阶段:计算每条可行路由的优先级;
第二阶段:从所有可用路由中为特定目的地选出最佳路由,并将其安装到Loc-RIB中。
第三阶段:将相应的路由加入到Adj-RIBs-Out中,以便向对等体进行宣告。
以下为BGP选路原则的13条:
1)weight
cisco私有的参数。本地有效。缺省条件下,本地始发的路径具有相同的WEIGHT值(即32768),所有其他的路径的weight值为0。越大越优选。影响路由器的出站流量。
2)local-preference
本地优先级,可以在本AS和大联盟内传递。越大越优先。影响路由器的出站流量。默认情况下,local-preference为100。
3)本地起源
路由器本地始发的路径优先。在BGP的转发表里显示为0.0.0.0。依次降低的优先级顺序是:default-originate(针对每个邻居配置)、default-informaiton-originate(针对每种地址簇配置)、network、redistribute、aggregate-address。
4)as-path
评估as-path的长度,as-path列表最短的路径优先。聚合后继承明细路由的属性,在大括号里面的as-path在计算长度时,只算一个。在联盟内小括号里面的AS号,在选路时,不计算到as-path长度里面。
5)起源代码
评估路由的origin code属性,有3个i<e<?。i代表用network将IGP引入BGP的,或者是聚合等路由,e代表EGP,?代表重分布进BGP的路由。i为0,e为1,?为3。越小越优。
6)MED
metric传递不能传出AS。例外:始发路由器可以metric传给邻居,可以是IBGP/EBGP,但是EBGP再传不出去。MED相当于IGP路由的metric值,越小越优先。
7)EBGP优于IBGP
这里EBGP>联盟内的EBGP>IBGP。
8)最近的IGP邻居
这里是指peer的更新源在我的路由表里显示,哪个最近哪个最优。OSPF是否考虑O、OIA、OE1、OE2?只看cost不看O/OIA/OE。
9)如果配置了maximum-path[ibgp]n,如果存在多条等价的路径,会插入多条路径。
BGP默认maximum-path=1,只能有一条最优路径,但可以通过命令来改变,如果没有IBGP参数,默认只能做EBGP的负载均衡。做负载均衡还有一个条件,就是上面的8条都比不出哪条最优的情况下,才有可能出现负载均衡。做了BGP的负载均衡后,在BGP的转发表里还是一个最优,但在路由表里可以出现2个下一跳。
10)最老的
与本端最早建立邻居关系的peer,被优选。因为它最稳定。但一般不考虑,会跳过这个继续往下选。如果以下任一条件为真,这一步将会被忽略:启用了bgp bestpath compare-routerid,多条路径具有相同的router-id,因为这些路由都是从同一台路由器接收过来的;当前没有最佳路径。缺乏当前最佳路径的例子发生在正在通告最佳路径的邻居失效的时候。
11)最低的ROUTER-ID
BGP优选来自具有最低的路由器ID的BGP路由器的路由。Router-id是路由器上最高的IP地址,并且优选环回口。也可以通过bgp router-id命令静态的设定路由器ID。如果路径包含RR属性,那么在路径选择过程中,就用originator-id来替代路由器ID。
12)多跳路径的始发路由器ID相同,那么选择CLUSTER_LIST长度短的,因为每经过一个RR,cluster-list会加上这个RR的router-id
如果多条路径的始发router-id相同,那么BGP将优选cluster-list长度最短的路径。这种情况仅仅出现在BGP RR的环境下。
13)BGP优选来自于最低的邻居地址的路径。是BGP的neighbor配置中的那个地址,如果是环回口,则看环回口地址的高低。
BGP优选来自于最低的邻居地址的路径。这是BGP的neighbor配置中所使用的IP地址,并且它对应于与本地路由器建立TCP连接的远端对等体。
5.路由翻动(route flaps)和路由惩罚(route dampening)
路由翻动产生的原因有很多种比如:链路不稳定、路由器接口故障、ISP工程施工、管理员错误配置和错误故障检查等等都能造成路由翻动,由于路由翻动会造成每台路由器重新计算路由,从而消耗了大量的网络带宽和路由器的CPU资源。
BGP邻居的flaping
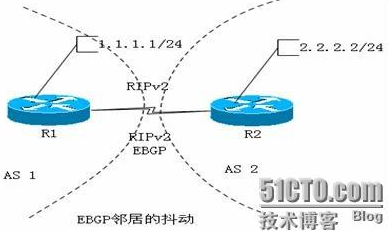
当R1与R2两台路由器运行IGP协议,并且建立EBGP的邻居关系,用环回口建立邻居关系。这时假如R1、R2将他们的更新源通告进了BGP,然后通过BGP传递给对方,这时由于从EBGP学到的路由的AD为20,大于IGP的默认AD,这时会产生邻居的flaping现象。这时show ip bgp summary可以看到每经过60秒BGP table version is 1, main routing table version 1会改变一次。BGP转发表里变化了多少次。
用debug ip bgp、debug ip bgp update来查看BGP的flaping。
解决方法:
(1)EBGP建邻居时不要将环回口引入BGP。
(2)Network + backdoor
BGP路由下一跳的flaping

R1、R2、R3因为属于同一个AS,所以运行一个IGP,R2-R4,R3-R5之间的链路并没有通告进IGP中。R1、R2、R3 IBGP对等体关系,R3在指R1时,打了neighbor 1.1.1.1 next-hop-self;R4、R2 ,R5、R3 ,R4、R5为EBGP对等体关系,它们都拿直连接口建立邻居关系。
这时R4将它的环回口4.4.4.0/24和R2-R4的直连网络24.0.0.0/24引入BGP,这时在R1上就会产生路由下一跳flaping的现象。这时show ip bgp summary可以看到每经过60秒BGP table version is 1, main routing table version 1会改变一次。
解决方法:
1)静态路由(R1上静态路由)
2)在IBGP邻居所处的IGP中宣告
3)将与EBGP直连的网络重分布进IGP
4)neighbor x.x.x.x next-hop-self(R2指R1时输入)
路由惩罚(route dampening)由RFC2439描述,它主要由以下三个目的:
※提供了一种机制,以减少由于不稳定路由引起的路由器处理负载
※防止持续的路由抖动
※增强了路由的稳定性,但不牺牲表现良好的(well-behaved)路由的收敛时间。
ROUTER BG 1
BG DAMP 15 750 2000 60 ---- 针对所有的路由。
BG DAMP ROUTE-MAP XXX
ROUTE-MAP XXX
MATIP ADD PREFIS XX
SET DAM 15 750 2000 60 ---DEFAULT
IP PREFIX XX PERMIT 1.1.1.0/24
SH IP BG 1.1.1.0
SH IP BG DAM PARA
Dampening为每一条前缀维护了一个路由抖动的历史记录。Dampening算法包含以下几个参数:
u 历史记录――――当一条路由flaping后,改路由就会被分配一个惩罚值,并且它的惩罚状态被设置为history。
u 惩罚值(penalty)――――路由每flaping一次,这个惩罚值就会增加。默认的路由flaping惩罚值为1000。如果只有路由属性发生了变化,那么惩罚值为500。这个值是硬件编码的。
u 抑制门限(suppress limit)――――如果惩罚值超过了抑制门限,改路由将被惩罚或dampen。路由状态将由history转变为damp状态。默认值的抑制门限是2000,它可以被设置。
u 惩罚状态(damp state)――――当路由处于惩罚状态时,路由器在最佳路径选择中将不考虑这条路径,因此也不会把这条前缀通告给它的对等体。
u 半衰期(half life)――――在一半的生命周期的时间内,路由的惩罚值将被减少,半衰期的缺省值是15分钟。路由的惩罚值每5秒钟减少一次。半衰期的值可以被设置。
u 重用门限(reuse limit)――――路由的惩罚值不断的递减。当惩罚值降到重用门限以下时,改路由将不再被抑制。缺省的重用门限为750。路由器每10秒钟检查一次那些不需要被抑制的前缀。重用门限时可以被配置的。当惩罚值达到了重用门限的一半时,这条前缀的历史记录(history)将被清除,以便更有效率的使用内存。
u 最大抑制门限/最大抑制时间――――如果路由在短时间内表现出极端的不稳定性,然后又稳定下来,那么累计的惩罚值可能会导致这条路由在过长的时间里一直处于惩罚状态。这就是设置最大抑制门限的基本目的。如果路由表现出连续的不稳定性,那么惩罚值就停留在它的上限上,使得路由保持在惩罚状态。最大抑制门限是用公式计算出来的。最大抑制时间为一条路由停留在惩罚状态的最长时间。默认为60分钟(半衰期的4倍)可以配置。
最大抑制门限=重用门限×2(最大抑制时间÷半衰期)
由于最大抑制门限为公式算出来的,所以有可能最大抑制门限≤抑制门限,当这种情况发生时,dampening的设置是没有效果的。如重用门限=750,抑制门限=3000,半衰期=30分钟,最大抑制时间=60分钟。按照这样的配置,算出来的最大抑制门限为3000,与抑制门限一样,因为必须超过抑制门限,才能对路由进行dampening,所以这时dampening的设置没有效果。
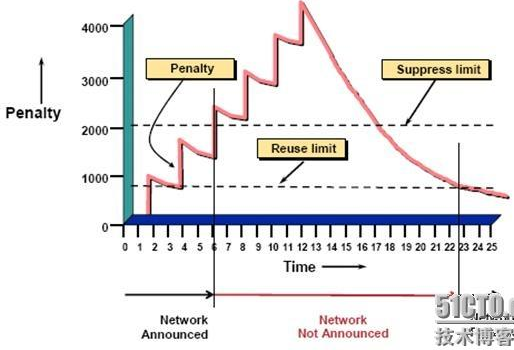
BGP的dampening仅仅影响EBGP的路由。Dampening是基于每条路径的路由而操作的。如果一条前缀具有两条路径,并且其中一条被惩罚了,那么另一条前缀仍然是可用的,可以通告给BGP对等体。
命令:bgp dampening [route-map XX] [{Half-life reuse-limit suppress-limit Maximum-time }]
如果挂了route-map,那么就在route-map里面匹配特定EBGP路由,来设置dampening值。
检查命令:
show ip protocol
sh ip bgp dampening ?
dampened-paths 只显示(清除)被抑制的路由。
flap-statistics 显示(清除)所有出现摆动的路由以及该路由出现摆动的次数。
parameters Display details of configured dampening parameters
show ip bgp neighbors 1.1.1.1 dampened-routes
show ip bgp neighbors 1.1.1.1 flap-statistics
6.路由反射器(即RR,Route Reflector)
由于IBGP的水平分割问题,所以IBGP需要Full Mesh。由于整个IBGP full mesh的话,需要建的session数为n*(n-1)/2。不具有扩展性。所以产生两种解决方法,路由反射器是其中一种,而另一种则是联邦。
路由反射器是被配置为允许它把通过IBGP所获悉的路由通告到其他IBGP对等体的路由器,路由器反射器与其他路由器有部分IBGP对等关系,这些路由器被称为客户。客户间的对等是不需要的,因为路由反射器将在客户间传递通告。 如下图所示。

其优点:减少AS内BGP邻居关系的数量,从而减少了TCP连接数;在AS内可以有多个路由反射器,即是为了冗余也是为了分成组,以进一步减少所需IBGP会话的数量。路由反射器的路由器可以与非路由反射器的路由器共存,所以配置更简单。
RFC1966中定义了3条RR用来决定要宣告哪条路由的规则,具体使用时取决于路由是如何学习到的。
如果路由学习自非客户IBGP对等体,则仅反射给客户路由器。
如果路由学习自某客户,则反射给所有非客户和客户路由器(发起该路由的客户除外)。
如果路由学习自EBGP对等体,则反射给所有非客户和客户路由器
路由反射器的客户并不知道自己是客户。客户和非客户经过路由反射器反射的路由更新将会带上cluster-list和originator,可用于IBGP防环。Cluster-id默认为路由反射器自己的router-id,可以通过命令bgp cluster-id 1.1.1.1来修改,cluster-id为32位的值,可以写成点分十进制,也可以写成十进制数;originator为IBGP内起源路由器的router-id。路由反射器是IBGP的特性,出了IBGP后,路由反射器所有的特性消失(即路由携带的cluster-list和originator全部消失)。
neighbor 1.1.1.1 route-reflector-client
可以通过这条命令来将IBGP的peer 1.1.1.1变为自己的客户。建议对每个IBGP邻居都打上。
当路由反射器的客户full mesh时,可以用no bgp client-to-client reflection禁止客户到客户的路由反射。可以减少路由更新。
如下图为路由反射器的基本配置。
7.BGP联邦
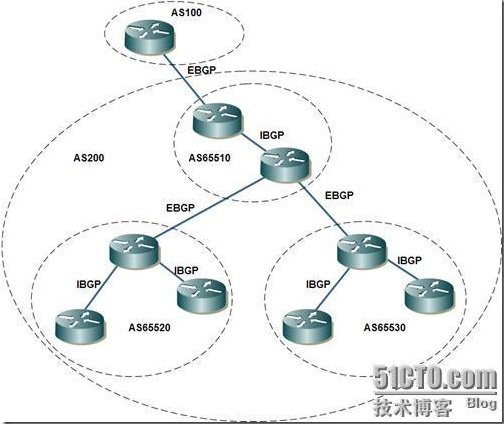
联邦既有EBGP的特性,又有IBGP的特性。联盟是另一种控制大量IBGP对等体的方法,它就是一个被细分为一组子自治系统(称为成员自治系统)的AS。如下图所示。
联盟增加了两种类型的AS_PATH属性
AS_CONFED_SEQUENCE:一个去往特定目的地所经路径上的有序AS号列表,其用法与AS_SEQUENCE完全一样,区别在于该列表中的AS号属于本地联盟中的自治系统。
AS_CONFED_SET:一个去往特定目的地所经路径上的无序AS号列表,其用法与AS_SET完全一样,区别在于该列表中的AS号属于本地联盟中的自治系统。
由于AS_PATH发生被用于成员自治系统之间,因而保留了环路预防功能。将Update消息发送给联盟之外的对等体时,将从AS_PATH属性中剥离AS_CONFED_SEQUENCE和AS_CONFED_SET信息,而将联盟ID附加到AS_PATH中。
Local_preference和MED可以在联邦内传递。联盟内的小AS号,在as-path里显示在小括号里,在as-path计算长度时,不被考虑。下一跳在联邦内传递不会改变。
BGP总结(三)的更多相关文章
- BGP - 4,BGP的三张表
1,BGP的三张表 邻居表(adjancy table) BGP表(forwarding database):BGP默认不做负载均衡,会选出一条最优的,放入路由表 路由表 ...
- BGP路由协议详解(完整篇)
原文链接:http://xuanbo.blog.51cto.com/499334/465596/ 2010-12-27 12:02:45 上个月我写一篇关于BGP协议的博文,曾许诺过要完善这个文档,但 ...
- RIP、OSPF、BGP、动态路由选路协议、自治域AS
相关学习资料 tcp-ip详解卷1:协议.pdf http://www.rfc-editor.org/rfc/rfc1058.txt http://www.rfc-editor.org/rfc/rfc ...
- BGP笔记
BGP:用于AS与AS之间的路由,但现在也越来越多的用在IDC内部了 BGP是应用层协议,应用TCP协议(唯一一个运用TCP的路由协议) IGP和EGP的区别:IGP运行在一个AS之内,EGP运行在A ...
- BGP的那些安全痛点(转)
0x00 BGP(RFC 1771. RFC 4271)定义 全称是Border Gateway Protocol, 对应中文是边界网关协议,最新版本是BGPv4. BGP是互联网上一个核心的互联网去 ...
- BGP总结(一)
0.AS 狭义:在RIP.OSPF和EIGRP等IGP协议中,AS表示只运行此单种协议的路由域 广义:运行多个IGP协议的路由域,多个IGP协议之间通过路由重发布来实现通信,AS和AS之间通过BGP来 ...
- 学习总结---OSPF协议
总结: 1.ospf协议报文不会泛洪扩散,而是逐级路由器处理后,再从所有ospf启用端口发送出去,也就是说,只能从邻居接收到ospf报文,报文的源ip是邻居的ip地址,目的ip是组播ip. 2.开启o ...
- OSPF协议总结
总结: 1.ospf协议报文不会泛洪扩散,而是逐级路由器处理后,再从所有ospf启用端口发送出去,也就是说,只能从邻居接收到ospf报文,报文的源ip是邻居的ip地址,目的ip是组播ip. 2.开启o ...
- 游戏场景下的DDoS风险分析及防护
欢迎大家前往腾讯云+社区,获取更多腾讯海量技术实践干货哦~ 作者:腾讯游戏云资深架构师 vince 本篇文章主要是分享游戏业务面临的安全风险场景,以及基于这些场景的特点,我们应该如何做好对应的防护. ...
随机推荐
- spark的运行指标监控
sparkUi的4040界面已经有了运行监控指标,为什么我们还要自定义存入redis? 1.结合自己的业务,可以将监控页面集成到自己的数据平台内,方便问题查找,邮件告警 2.可以在sparkUi的基础 ...
- Spring Boot GraphQL 实战 03_分页、全局异常处理和异步加载
hello,大家好,我是小黑,又和大家见面啦~ 今天我们来继续学习 Spring Boot GraphQL 实战,我们使用的框架是 https://github.com/graphql-java-ki ...
- FastApi 进阶
前言 终于有了第一个使用 FastApi 编写的线上服务, 在开发的过程中还是遇到了些问题, 这里记录一下 正文 目录结构 我们知道, FastApi 的启动方式推荐使用 uvicorn, 其启动方式 ...
- 【老孟Flutter】2021 年 Flutter 官方路线图
老孟导读:这是官方公布的2021年路线图,向我们展示了2021年 Flutter 的主要工作及计划. 原文地址:https://github.com/flutter/flutter/wiki/Road ...
- 【Java基础】集合
集合 集合概述 一方面, 面向对象语言对事物的体现都是以对象的形式,为了方便对多个对象 的操作,就要对对象进行存储.另一方面,使用 Array 存储对象方面具有一些弊端,而 Java 集合就像一种容器 ...
- HBASE Shell基本命令
定义 HBASE是一种分布式.可扩展.支持海量数据存储的NoSQL数据库. HBASE数据模型 逻辑上,HBASE的数据模型同关系型数据库类似,数据存储到一张表中,有行有列,但是从HBASE的底层物理 ...
- 【Linux】fstab中 每个字段代表的含义
默认情况下,fstab中已经有了当前的分区配置,内容可能类似: # <file system> <mount point> <type> <options ...
- 【ORACLE】awr报告问题分析
本文转自:http://www.linuxidc.com/Linux/2015-10/123959.htm 感谢分享 1.问题说明 运维人员都有"节日休假恐怖症",越到节日.休假和 ...
- pg_rman的安装与使用
1.下载对应数据库版本及操作系统的pg_rman源码 https://github.com/ossc-db/pg_rman/releases 本例使用的是centos6.9+pg10,因此下载的是pg ...
- 入门OJ:简单的网络游戏
题目描述 在某款极具技术含量的网络游戏中,佳佳靠着他的聪明智慧垄断了游戏中的油田系统.油田里有许多油井,这些油井排成一个M*N的矩形.每个油井都有一个固定的采油量.每两个相邻的油井之间有一条公路,这些 ...