Java Bean拷贝工具Orika原理解析
最近面试被问及对象拷贝怎样才能高效,实际上问的就是Orika或者BeanCopier的原理。由于网上对Orika原理的解析并不太多~因此本文重点讲解一下Orika的原理。(Orika是基于JavaBean规范的属性拷贝框架,所以不了解什么是JavaBean的话请先百度)
首先,先纠正一下一些网上的错误说法,Java反射慢,所以要使用Orika基于Javasisst效率更好,我要说明的是Orika的整个流程是需要使用到Java的反射的,只是在真正拷贝的属性的时候没有使用反射。这里先简单讲解一下Orika的执行流程:先通过内省(反射)把JavaBean的属性(getset方法等)解析出来,进而匹配目标和源的属性-->接着根据这些属性和目标/源的匹配情况基于javasisst生成一个 GeneratedMapper的代理对象(真正的执行复制的对象)并放到缓存中-->接着就基于这个对象的 mapAtoB和mapBtoA方法对属性进行复制。
有了上面的流程其实只需要看看GeneratedMapper这个代理对象到底是怎样的估计大家就明白了,直接贴出来。虚线上面就是复制的Orika需要复制的属性值,分别为id和productName,虚线下面就是GeneratedMapper的代理实现,可以看到实际上就是生成了一个get set的拷贝方法。看到这里大家就知道了实际上复制就是调用了GeneratedMapper.mapAtoB
CanalSyncMapper canalSyncMapper = new CanalSyncMapper();
canalSyncMapper.setId(1L);
canalSyncMapper.setProductName("你好再见");
TestProduct map = new DefaultMapperFactory.Builder().build().getMapperFacade().map(canalSyncMapper, TestProduct.class);
-------------------------------------GeneratedMapper------------------------------------------------------------------------------------
public void mapAtoB(java.lang.Object a, java.lang.Object b, ma.glasnost.orika.MappingContext mappingContext) {
super.mapAtoB(a, b, mappingContext);
// sourceType: CanalSyncMapper
cn.danvid.canal_test.mapper.CanalSyncMapper source = ((cn.danvid.canal_test.mapper.CanalSyncMapper)a);
// destinationType: TestProduct
cn.danvid.canal_test.mapper.TestProduct destination = ((cn.danvid.canal_test.mapper.TestProduct)b);
destination.setId(((java.lang.Long)source.getId()));
destination.setProductName(((java.lang.String)source.getProductName()));#如果有多个字段需要复制就多个getset
if(customMapper != null) {
customMapper.mapAtoB(source, destination, mappingContext);
}
}
public void mapBtoA(java.lang.Object a, java.lang.Object b, ma.glasnost.orika.MappingContext mappingContext) {
super.mapBtoA(a, b, mappingContext);
// sourceType: TestProduct
cn.danvid.canal_test.mapper.TestProduct source = ((cn.danvid.canal_test.mapper.TestProduct)a);
// destinationType: CanalSyncMapper
cn.danvid.canal_test.mapper.CanalSyncMapper destination = ((cn.danvid.canal_test.mapper.CanalSyncMapper)b);
destination.setId(((java.lang.Long)source.getId()));
destination.setProductName(((java.lang.String)source.getProductName()));#如果有多个字段需要复制就多个getset
if(customMapper != null) {
customMapper.mapBtoA(source, destination, mappingContext);
}
}
可以看到实际上Orika使用map的时候,目标对象我们传的是class类,但到了GeneratedMapper.mapAtoB传入的是一个对象那么实际上目标对象是先基于Java反射创建出来,然后再复制的,所以Orika也要用到反射。
其实到这里大概原理都讲完了,如果大家有兴趣也可以接着看我把细节再讲一下。
==========================================================================================================================
大家点击MappFacade.map里面实际上源码是这样
public <S, D> D map(final S sourceObject, final Class<D> destinationClass, final MappingContext context) {
MappingStrategy strategy = null;
try {
if (destinationClass == null) {
throw new MappingException("'destinationClass' is required");
}
if (sourceObject == null) {
return null;
}
D result = context.getMappedObject(sourceObject, TypeFactory.valueOf(destinationClass));
if (result == null) {
strategy = resolveMappingStrategy(sourceObject, null, destinationClass, false, context);#1.实际上就是创建GeneratedMapper
result = (D) strategy.map(sourceObject, null, context); #2.实际上调用的是这个方法
}
return result;
} catch (MappingException e) {
throw exceptionUtil.decorate(e);
} catch (RuntimeException e) {
if (!ExceptionUtility.originatedByOrika(e)) {
throw e;
}
MappingException me = exceptionUtil.newMappingException(e);
me.setSourceClass(sourceObject.getClass());
me.setDestinationType(TypeFactory.valueOf(destinationClass));
me.setMappingStrategy(strategy);
throw me;
}
}
上面代码备注上有亮点,先讲第二点=>打断点会发现,在执行strategy.map的时候最终就是调用了GeneratedMapper.mapAtoB方法。
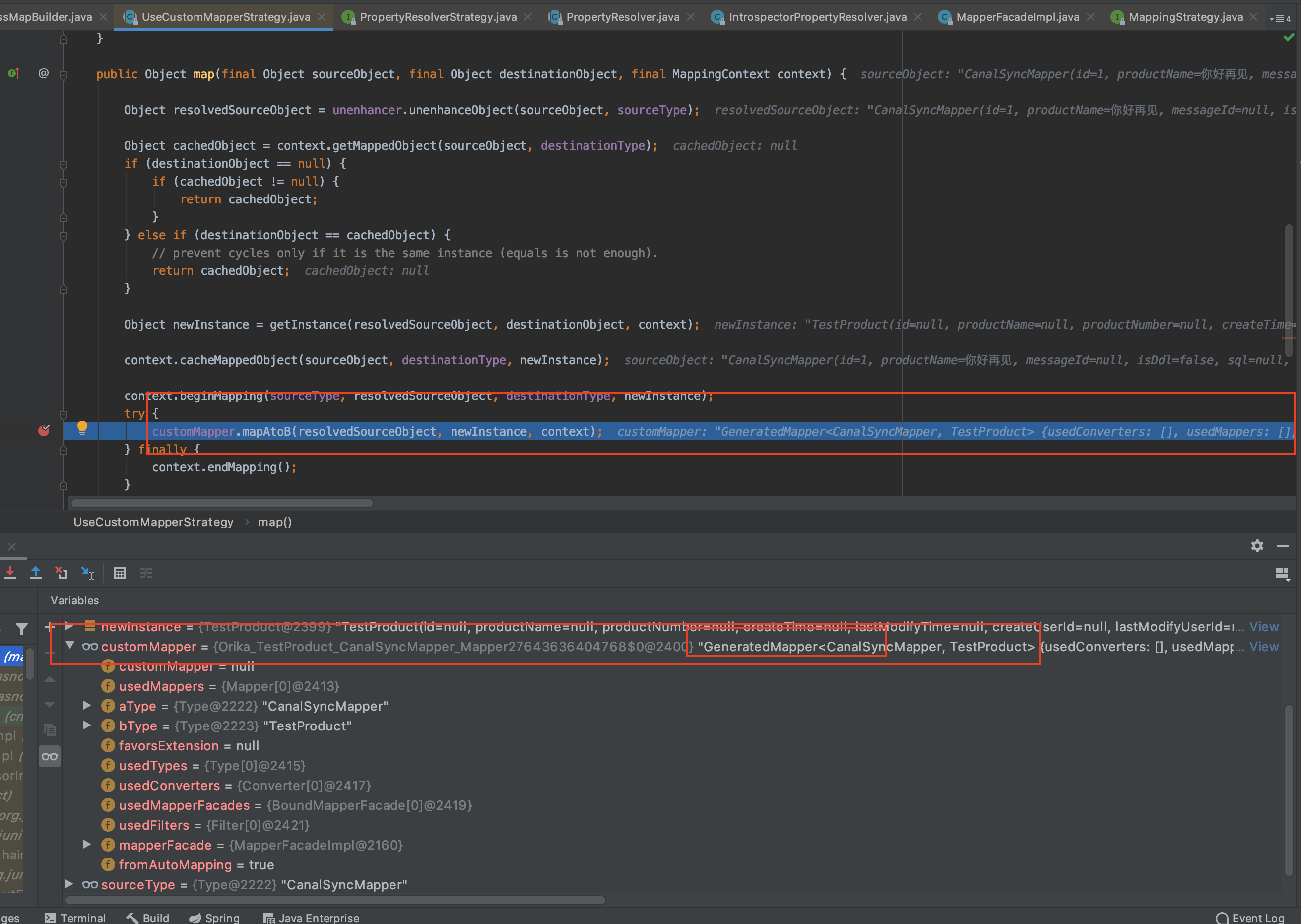
讲完第二点实际上我们就是关注这个 GeneratedMapper的生成过程,也就是备注的第一点 strategy = resolveMappingStrategy(sourceObject, null, destinationClass, false, context);这个方法,从下面代码可以看出来strategy会被缓存起来。
public <S, D> MappingStrategy resolveMappingStrategy(final S sourceObject, final java.lang.reflect.Type initialSourceType,
final java.lang.reflect.Type initialDestinationType, final boolean mapInPlace, final MappingContext context) { Key key = new Key(getClass(sourceObject), initialSourceType, initialDestinationType, mapInPlace);
MappingStrategy strategy = strategyCache.get(key); if (strategy == null) { ......
} /*
* Set the resolved types on the current mapping context; this can be
* used by downstream Mappers to determine the originally resolved types
*/
context.setResolvedSourceType(strategy.getAType());
context.setResolvedDestinationType(strategy.getBType());
context.setResolvedStrategy(strategy); return strategy;
}
接着我们就看看if (strategy == null)里面干了什么,如下,我们重点看备注部分
@SuppressWarnings("unchecked")
Type<S> sourceType = (Type<S>) (initialSourceType != null ? TypeFactory.valueOf(initialSourceType)
: typeOf(sourceObject));
Type<D> destinationType = TypeFactory.valueOf(initialDestinationType);
MappingStrategyRecorder strategyRecorder = new MappingStrategyRecorder(key, unenhanceStrategy);
final Type<S> resolvedSourceType = normalizeSourceType(sourceObject, sourceType, destinationType);
strategyRecorder.setResolvedSourceType(resolvedSourceType);
strategyRecorder.setResolvedDestinationType(destinationType);
if (!mapInPlace && canCopyByReference(destinationType, resolvedSourceType)) {
/*
* We can copy by reference when destination is assignable from
* source and the source is immutable
*/
strategyRecorder.setCopyByReference(true);
} else if (!mapInPlace && canConvert(resolvedSourceType, destinationType)) {
strategyRecorder.setResolvedConverter(mapperFactory.getConverterFactory().getConverter(resolvedSourceType, destinationType));
} else {
strategyRecorder.setInstantiate(true);
Type<? extends D> resolvedDestinationType = resolveDestinationType(context, sourceType, destinationType,
resolvedSourceType);
strategyRecorder.setResolvedDestinationType(resolvedDestinationType);
strategyRecorder.setResolvedMapper(resolveMapper(resolvedSourceType, resolvedDestinationType, context));#重点关注
if (!mapInPlace) { strategyRecorder.setResolvedObjectFactory( mapperFactory.lookupObjectFactory(resolvedDestinationType, resolvedSourceType, context)); } } strategy = strategyRecorder.playback(); if (log.isDebugEnabled()) { log.debug(strategyRecorder.describeDetails()); } MappingStrategy existing = strategyCache.putIfAbsent(key, strategy); if (existing != null) { strategy = existing; }
重点关注resolveMapper(resolvedSourceType, resolvedDestinationType, context)这个方法,里面实际调用了mapperFactory.lookupMapper(mapperKey, context)方法,如下
public Mapper<Object, Object> lookupMapper(MapperKey mapperKey, MappingContext context) {
Mapper<?, ?> mapper = getRegisteredMapper(mapperKey.getAType(), mapperKey.getBType(), false);
if (internalMapperMustBeGenerated(mapper, mapperKey)) {
mapper = null;
}
if (mapper == null && useAutoMapping) {
synchronized (this) {
mapper = getRegisteredMapper(mapperKey.getAType(), mapperKey.getBType(), false);
boolean internalMapperMustBeGenerated = internalMapperMustBeGenerated(mapper, mapperKey);
if (internalMapperMustBeGenerated) {
mapper = null;
}
if (mapper == null) {
try {
...
ClassMapBuilder<?, ?> builder = classMap(mapperKey.getAType(), mapperKey.getBType()).byDefault(); #1.基于内省收集属性
for (MapperKey key : discoverUsedMappers(builder)) {
builder.use(key.getAType(), key.getBType());
}
final ClassMap<?, ?> classMap = builder.toClassMap();
buildObjectFactories(classMap, context);
mapper = buildMapper(classMap, true, context); #2.根据收集的属性创建GeneratedMapper
initializeUsedMappers(mapper, classMap, context);
...
} catch (MappingException e) {
e.setSourceType(mapperKey.getAType());
e.setDestinationType(mapperKey.getBType());
throw exceptionUtil.decorate(e);
}
}
}
}
return (Mapper<Object, Object>) mapper;
}
#1.基于内省收集属性:ClassMapBuilder<?, ?> builder = classMap(mapperKey.getAType(), mapperKey.getBType()).byDefault();这个方法里面最终会调用到下面这个
protected ClassMapBuilder(Type<A> aType, Type<B> bType, MapperFactory mapperFactory, PropertyResolverStrategy propertyResolver,
DefaultFieldMapper... defaults) { if (aType == null) {
throw new MappingException("[aType] is required");
} if (bType == null) {
throw new MappingException("[bType] is required");
} this.mapperFactory = mapperFactory;
this.propertyResolver = propertyResolver;
this.defaults = defaults; aProperties = propertyResolver.getProperties(aType);#这里就是使用了内省机制获取属性
bProperties = propertyResolver.getProperties(bType);#这里就是使用了内省机制获取属性
propertiesCacheA = new LinkedHashSet<String>(); propertiesCacheB = new LinkedHashSet<String>(); this.aType = aType; this.bType = bType; this.fieldsMapping = new LinkedHashSet<FieldMap>(); this.usedMappers = new LinkedHashSet<MapperKey>(); }
最终会调用IntrospectorPropertyResolver.collectProperties 下面就是内省收集属性了。
protected void collectProperties(Class<?> type, Type<?> referenceType, Map<String, Property> properties) {
try {
BeanInfo beanInfo = Introspector.getBeanInfo(type);
PropertyDescriptor[] descriptors = beanInfo.getPropertyDescriptors();
for (final PropertyDescriptor pd : descriptors) {
try {
Method readMethod = getReadMethod(pd, type);
if (!includeTransientFields && isTransient(readMethod)) {
continue;
}
Method writeMethod = getWriteMethod(pd, type, null);
Property property =
processProperty(pd.getName(), pd.getPropertyType(), readMethod, writeMethod, type, referenceType, properties);
postProcessProperty(property, pd, readMethod, writeMethod, type, referenceType, properties);
} catch (final Exception e) {
/*
* Wrap with info for the property we were trying to
* introspect
*/
throw new RuntimeException("Unexpected error while trying to resolve property " + referenceType.getCanonicalName()
+ ", [" + pd.getName() + "]", e);
}
}
} catch (IntrospectionException e) {
throw new MappingException(e);
}
}
#2.根据收集的属性创建GeneratedMapper:有了属性就可以基于Javasisst创建GeneratedMapper了,如下:
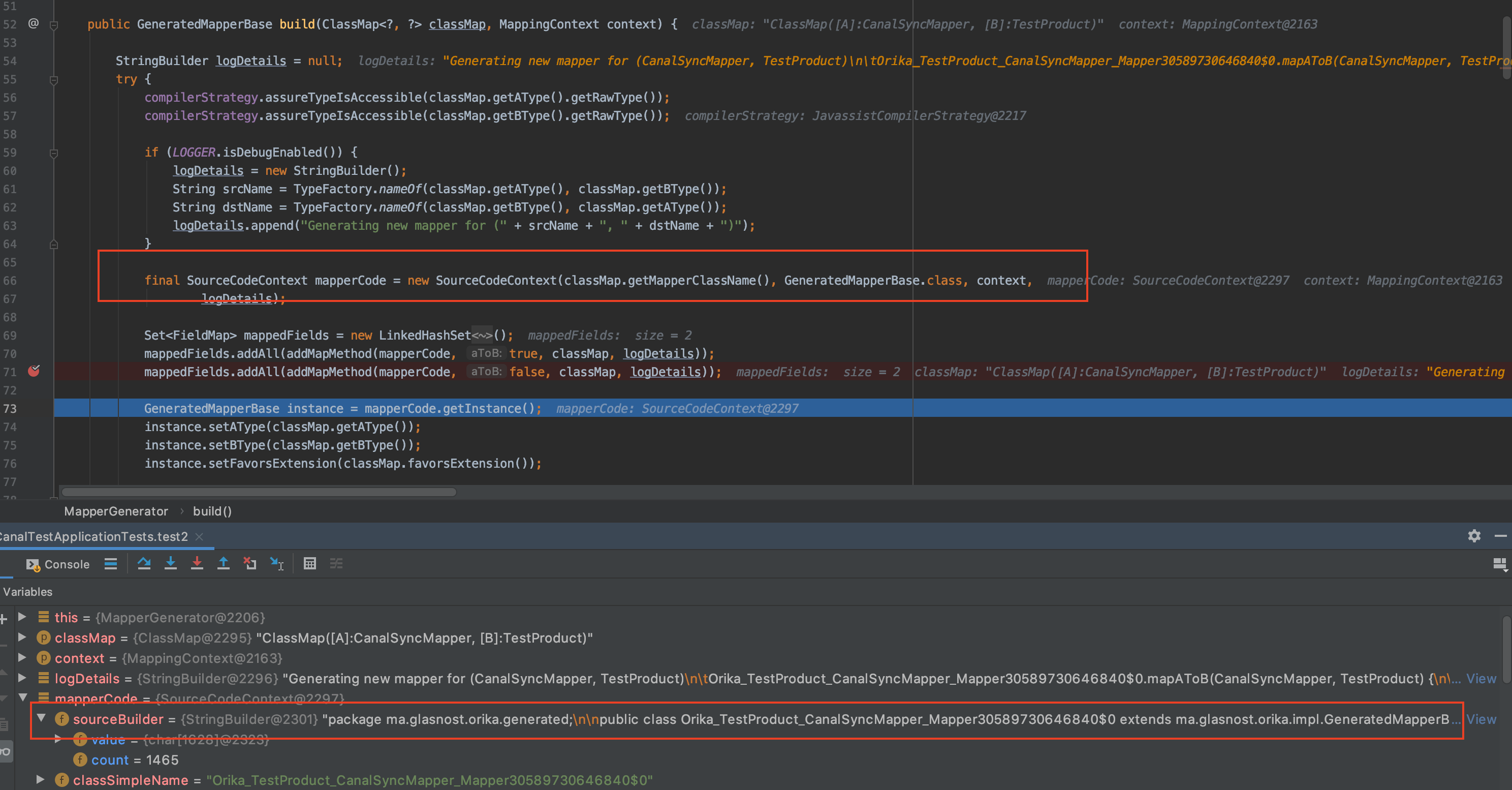
可以看到mapperCode已经拼接生成了一个class的字符串(sourceBuilder),这个字符串如下
package ma.glasnost.orika.generated;
public class Orika_TestProduct_CanalSyncMapper_Mapper30589730646840$0 extends ma.glasnost.orika.impl.GeneratedMapperBase {
public void mapAtoB(java.lang.Object a, java.lang.Object b, ma.glasnost.orika.MappingContext mappingContext) {
super.mapAtoB(a, b, mappingContext);
// sourceType: CanalSyncMapper
cn.danvid.canal_test.mapper.CanalSyncMapper source = ((cn.danvid.canal_test.mapper.CanalSyncMapper)a);
// destinationType: TestProduct
cn.danvid.canal_test.mapper.TestProduct destination = ((cn.danvid.canal_test.mapper.TestProduct)b);
destination.setId(((java.lang.Long)source.getId()));
destination.setProductName(((java.lang.String)source.getProductName()));
if(customMapper != null) {
customMapper.mapAtoB(source, destination, mappingContext);
}
}
public void mapBtoA(java.lang.Object a, java.lang.Object b, ma.glasnost.orika.MappingContext mappingContext) {
super.mapBtoA(a, b, mappingContext);
// sourceType: TestProduct
cn.danvid.canal_test.mapper.TestProduct source = ((cn.danvid.canal_test.mapper.TestProduct)a);
// destinationType: CanalSyncMapper
cn.danvid.canal_test.mapper.CanalSyncMapper destination = ((cn.danvid.canal_test.mapper.CanalSyncMapper)b);
destination.setId(((java.lang.Long)source.getId()));
destination.setProductName(((java.lang.String)source.getProductName()));
if(customMapper != null) {
customMapper.mapBtoA(source, destination, mappingContext);
}
}
}
至此,应该明白的整个流程了把~
Java Bean拷贝工具Orika原理解析的更多相关文章
- Java volatile 关键字底层实现原理解析
本文转载自Java volatile 关键字底层实现原理解析 导语 在Java多线程并发编程中,volatile关键词扮演着重要角色,它是轻量级的synchronized,在多处理器开发中保证了共享变 ...
- [性能] Bean拷贝工具类性能比较
Bean拷贝工具类性能比较 引言 几年前做过一个项目,接入新的api接口.为了和api实现解耦,决定将api返回的实体类在本地也建一个.这样做有两个好处 可以在api变更字段的时候保持应用稳定性 可以 ...
- Java并发包JUC核心原理解析
CS-LogN思维导图:记录CS基础 面试题 开源地址:https://github.com/FISHers6/CS-LogN JUC 分类 线程管理 线程池相关类 Executor.Executor ...
- java bean 转换工具
考量要素: 1.简单的约定优于配置的同名属性copy 2.嵌套属性copy 3.flattern(扁平化)支持,要支持N层结构的copy到一层结构. 4.性能 如下这个网页,里面提到了好多工具. ht ...
- 就因为加了Lombok的@Accessors(chain = true),bean拷贝工具类不干活了
前言 这次新建了一个工程,因为 Lombok 用得很习惯,但以前的话,一般只用了@Data,@AllArgsConstructor,@EqualsAndHashCode等常规注解:那这个Accesso ...
- Bean拷贝工具
Apache BeanUtils Spring BeanUtils cglib BeanCopier Hutool BeanUtil Mapstruct Dozer 1.Apache BeanUti ...
- Java 7 和 Java 8 中的 HashMap原理解析
HashMap 可能是面试的时候必问的题目了,面试官为什么都偏爱拿这个问应聘者?因为 HashMap 它的设计结构和原理比较有意思,它既可以考初学者对 Java 集合的了解又可以深度的发现应聘者的数据 ...
- Java - "JUC线程池" ThreadPoolExecutor原理解析
Java多线程系列--“JUC线程池”02之 线程池原理(一) ThreadPoolExecutor简介 ThreadPoolExecutor是线程池类.对于线程池,可以通俗的将它理解为"存 ...
- JAVA MD5加密算法实现与原理解析
public static String md5Encode(String inputStr) { MessageDigest md5 = null; try { md5 = MessageDiges ...
随机推荐
- Vue基础(1)
Vue简介 1.JavaScript框架 2.简化Dom操作 3.响应式数据驱动 Vue基础 通过下面代码引用vue: <script src="https://cdn.jsdeliv ...
- 阿里云服务器SQLSERVER 2019 远程服务器环境搭建【原创】【转载请注明出处】
之前做过本地服务器SQLSERVER环境搭建.局域网环境SQLSERVER搭建.一直没有尝试自己完成一个云端服务器的环境搭建.今天就根据一个成功的例子给大家分享一下. 一.云端数据库安装与搭建 我的服 ...
- Sysbench测试神器:一条命令生成百万级测试数据
1. 基准测试 基准测试(benchmarking)是性能测试的一种类型,强调的是对一类测试对象的某些性能指标进行定量的.可复现.可对比的测试. 进一步来理解,基准测试是在某个时候通过基准测试建立一个 ...
- zookeeper Cli的常用命令
zookeeper Cli的常用命令 服务管理 启动ZK服务: zkServer.sh start 查看ZK状态: zkServer.sh status 停止ZK服务: zkServer.sh sto ...
- Redis学习笔记(五)——数据结构之哈希(Hash)
一.介绍 Redis hash是一个string类型的field和value的映射表,hash特别设于用于存储对象. Redis中每个hash可以存储232 - 1 键值对(40多亿). 基本命令: ...
- AngularJS——ui-router
深究AngularJS--ui-router详解 原创 2016年07月26日 13:45:14 标签: angularjs / ui-router / ui-view 25043 1.配置使用ui- ...
- Software Construction内容归纳
本篇博文是对于2020春季学期<软件构造>课程的总结归纳,由于原先编辑于word,格式不方便直接导入该博客,可以到本人github中进行自取. https://github.com/zqy ...
- .NET CORE QuartzJob定时任务+Windows/Linux部署
前言 以前总结过一篇基于Quartz+Topshelf+.netcore实现定时任务Windows服务 https://www.cnblogs.com/gt1987/p/11806053.html.回 ...
- Java程序员成长之路
北哥在前文总结了程序员的核心能力,但在专业能力维度,只是做了大概的阐述,并没有详细展开.从今天开始,我会把我作为程序员成长过程中,学习的知识总结成系列文章陆续发出来,供大家学习参考. 本文是第一篇,关 ...
- 【SpringBoot】03.SpringBoot整合Servlet的两种方式
SpringBoot整合Servlet的两种方式: 1. 通过注解扫描完成Servlet组件注册 新建Servlet类继承HttpServlet 重写超类doGet方法 在该类使用注解@WebServ ...