无所不能的Embedding 2. FastText词向量&文本分类
Fasttext是FaceBook开源的文本分类和词向量训练库。最初看其他教程看的我十分迷惑,咋的一会ngram是字符一会ngram又变成了单词,最后发现其实是两个模型,一个是文本分类模型[Ref2],表现不是最好的但胜在结构简单高效,另一个用于词向量训练[Ref1],创新在于把单词分解成字符结构,可以infer训练集外的单词。这里拿quora的词分类数据集尝试了下Fasttext在文本分类的效果, 代码详见 https://github.com/DSXiangLi/Embedding
Fasttext 分类模型
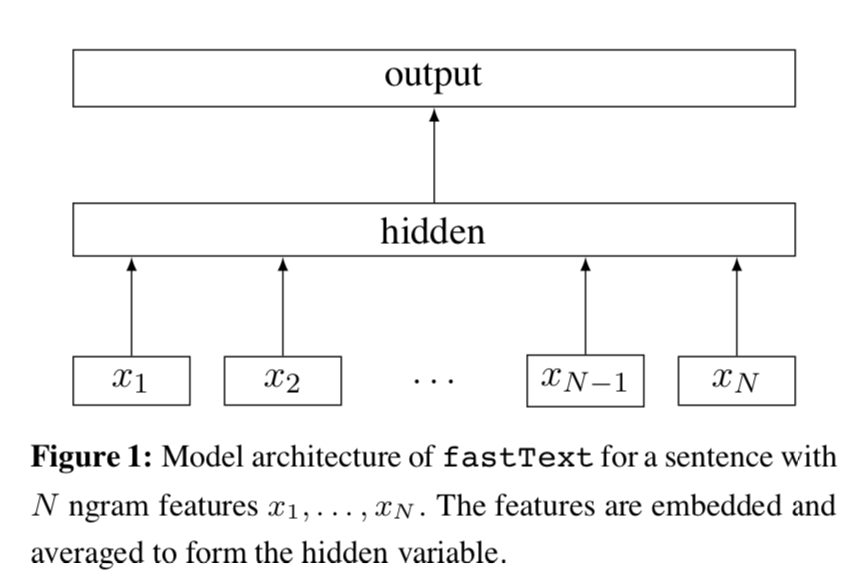
Fasttext分类模型结构很直观是一个浅层的神经网络。先对文本的每个词做embedding得到\(w_i\), 然后所有词的embedding做平均得到文本向量\(w_{doc}\),然后经过1层神经网络对label进行预测
w_{doc} &= \frac{1}{n}\sum_{i=1}^n w_{i} \\
p &= \sigma {(\beta \cdot w_{doc})} \\
\end{align}
\]
只说到这里,其实会发现和之前word2vec的CBOW基本是一样的,区别在于CBOW预测的是center word, 而Fasttext预测的是label,例如新闻分类,情感分类等,同时CBOW只考虑window_size内的单词,而Fasttext会使用变长文本内的所有单词。
看到Fasttext对全文本的词向量求平均, 第一反应是会丢失很多信息,对于短文本可能还好,但对于长文本效果应该不咋地。毕竟不能考虑到词序信息,是词袋模型的通病。Fasttext对此的解决办法是加入n-gram特征。这里的n-gram是单词级别的n-gram, 把相连的n个单词当作1个单词来做embedding,这样就可以考虑到局部的词序信息。当然副作用就是需要学习的embedding规模会大幅上升,只是2-gram就会比word要多得多。
Fasttext对此的解决方法是使用hashing把n-gram映射到bucket, 相同bucket的n-gram共享一个词向量。
在Quora的文本数据集上我自己实现了一版fasttext分类模型, LeaderBoard的F1在0.71左右,因为要用Kernel提交太麻烦只在训练集上跑了下在0.68左右,所以fasttext的分类模型确实是胜在一个快字。
Fasttext 词向量模型
Fasttext另一个模型就是词向量模型,是在Skip-gram的基础上,创新加入了subword信息。也就是把单词分解成字符串,模型学习的是字符串embedding
,单词的embedding由字符embedding求平均得到,这也是Fasttext词向量可以infer样本外单词的原因。
关于模型和训练细节,和前一章讲到的word2vec是一样的,感兴趣的可以来这里搂一眼 无所不能的Embedding 1 - Word2vec模型详解&代码实现
这里我们只细讨论下和subword相关的源代码。这里n-gram不再指单词而是字符,模型参数maxn,minn会设定n-gram的上界和下界。当设定minn = 2, maxn=3的时候,‘where’单词对应的subwords是<'wh','her','ere',re'>,还有<'where'>本身。
当时paper看到这里第一个反应是英文可以这么搞,因为英文可以分解成字符,且一些前缀后缀是有特殊含义的,中文咋整,拆偏旁部首么?!来看代码答疑解惑
void Dictionary::initNgrams() {
for (size_t i = 0; i < size_; i++) {
std::string word = BOW + words_[i].word + EOW; // 词前后加入<>用来区分单词和字符
words_[i].subwords.clear();
words_[i].subwords.push_back(i); //先把单词本身加入subword
if (words_[i].word != EOS) {
computeSubwords(word, words_[i].subwords);
}
}
}
void Dictionary::computeSubwords(
const std::string& word,
std::vector<int32_t>& ngrams,
std::vector<std::string>* substrings) const {
for (size_t i = 0; i < word.size(); i++) {
std::string ngram;
if ((word[i] & 0xC0) == 0x80) {
continue; // 遇到10开头字节跳过,保证中文从第一个字节开始读
}
for (size_t j = i, n = 1; j < word.size() && n <= args_->maxn; n++) {
ngram.push_back(word[j++]);
while (j < word.size() && (word[j] & 0xC0) == 0x80) {
ngram.push_back(word[j++]); // 如果是中文,读取该字符的所有字节
}
if (n >= args_->minn && !(n == 1 && (i == 0 || j == word.size()))) {// subword满足长度,得到hash值加入到ngrams里面
int32_t h = hash(ngram) % args_->bucket;
pushHash(ngrams, h);
if (substrings) {
substrings->push_back(ngram);
}
}
}
}
}
核心在computeSubwords部分, 乍一看十分迷幻的是(word[i] & 0xC0) == 0x80) 。这里0xC0二进制是11 00 00 00,和它做位运算是取字节的前两个bit,0x80二进制是10 00 00 00,前两位是10,其实也就是判断word[i]前两个bit是不是10,。。。10又是啥?
字符编码笔记:ASCII,Unicode 和 UTF-8 这里附上阮神的博客,广告费请结一下~
简单来说就是Fasttext要求输入为UTF-8编码,这里需要用到UTF-8的两条编码规则:
- 单字节的符号,字节的第一位是0后面7位是unicode,英文的ASCII和utf-8是一样滴
- n字节的符号,第一个字节的前n位是1,后面字节的前两位一律是10,是的此10就是彼10。

因为所有的英文都是单字节,而中文在utf-8中通常占3个字节,也就是只有读到中文字符中间字节的时候(word[i] & 0xC0) == 0x80) 判断成立。所以判断本身是为了完整的读取一个字符的全部字节,也就是说中文的subword最小单位只能到单个汉字,而不会有更小的粒度了。而个人感觉汉字粒度并不能像英文单词的构词一样带来十分有效的信息,所以Fasttext的这一创新感觉对中文并不会有太多增益。
不过说起拆偏旁部首,蚂蚁金服人工智能部在2018年还真发表过一个引入汉子偏旁部首信息的词向量模型cw2vec理论及其实现,感兴趣的可以去看看哟~
REF
- P. Bojanowski, E. Grave, A. Joulin, T. Mikolov, Enriching Word Vectors with Subword Information
- A. Joulin, E. Grave, P. Bojanowski, T. Mikolov, Bag of Tricks for Efficient Text Classification
- A. Joulin, E. Grave, P. Bojanowski, M. Douze, H. Jégou, T. Mikolov, FastText.zip: Compressing text classification models
- https://zhuanlan.zhihu.com/p/64960839
无所不能的Embedding 2. FastText词向量&文本分类的更多相关文章
- 文本情感分析(二):基于word2vec、glove和fasttext词向量的文本表示
上一篇博客用词袋模型,包括词频矩阵.Tf-Idf矩阵.LSA和n-gram构造文本特征,做了Kaggle上的电影评论情感分类题. 这篇博客还是关于文本特征工程的,用词嵌入的方法来构造文本特征,也就是用 ...
- 无所不能的embedding 3. word2vec->Doc2vec[PV-DM/PV-DBOW]
这一节我们来聊聊不定长的文本向量,这里我们暂不考虑有监督模型,也就是任务相关的句子表征,只看通用文本向量,根据文本长短有叫sentence2vec, paragraph2vec也有叫doc2vec的. ...
- NLP︱高级词向量表达(二)——FastText(简述、学习笔记)
FastText是Facebook开发的一款快速文本分类器,提供简单而高效的文本分类和表征学习的方法,不过这个项目其实是有两部分组成的,一部分是这篇文章介绍的 fastText 文本分类(paper: ...
- 文本分类(TFIDF/朴素贝叶斯分类器/TextRNN/TextCNN/TextRCNN/FastText/HAN)
目录 简介 TFIDF 朴素贝叶斯分类器 贝叶斯公式 贝叶斯决策论的理解 极大似然估计 朴素贝叶斯分类器 TextRNN TextCNN TextRCNN FastText HAN Highway N ...
- NLP之词向量
1.对词用独热编码进行表示的缺点 向量的维度会随着句子中词的类型的增大而增大,最后可能会造成维度灾难2.任意两个词之间都是孤立的,仅仅将词符号化,不包含任何语义信息,根本无法表示出在语义层面上词与词之 ...
- 基于word2vec训练词向量(二)
转自:http://www.tensorflownews.com/2018/04/19/word2vec2/ 一.基于Hierarchical Softmax的word2vec模型的缺点 上篇说了Hi ...
- PyTorch在NLP任务中使用预训练词向量
在使用pytorch或tensorflow等神经网络框架进行nlp任务的处理时,可以通过对应的Embedding层做词向量的处理,更多的时候,使用预训练好的词向量会带来更优的性能.下面分别介绍使用ge ...
- 使用Python中的NLTK和spaCy删除停用词与文本标准化
概述 了解如何在Python中删除停用词与文本标准化,这些是自然语言处理的基本技术 探索不同的方法来删除停用词,以及讨论文本标准化技术,如词干化(stemming)和词形还原(lemmatizatio ...
- [Algorithm & NLP] 文本深度表示模型——word2vec&doc2vec词向量模型
深度学习掀开了机器学习的新篇章,目前深度学习应用于图像和语音已经产生了突破性的研究进展.深度学习一直被人们推崇为一种类似于人脑结构的人工智能算法,那为什么深度学习在语义分析领域仍然没有实质性的进展呢? ...
随机推荐
- 23种设计模式 - 领域问题(Interpreter)
其他设计模式 23种设计模式(C++) 每一种都有对应理解的相关代码示例 → Git原码 ⌨ 领域问题 Interpreter 动机(Motivation) 在软件构建过程中,如果某一特定领域的问题比 ...
- RVO+CA
http://gamma.cs.unc.edu/RVO/ http://gamma.cs.unc.edu/CA/ https://arongranberg.com/astar/docs/writing ...
- Laptop(线段树+离散化)
链接:https://ac.nowcoder.com/acm/contest/16/A来源:牛客网 题目描述 FST是一名可怜的小朋友,他很强,但是经常fst,所以rating一直低迷. 但是重点在于 ...
- Mybatis源码学习第七天(插件开发原理)
插件概述: 插件是用来改变或者扩展mybatis的原有功能,mybatis的插件就是通过继承Interceptor拦截器实现的,在没有完全理解插件之前j禁止使用插件对mybatis进行扩展,有可能会导 ...
- 为什么ping不通google.com
前言 为什么在ping不通Google的时候,我们却可以web直接访问Google (已开启SSR 翻 墙) SSR访问Google 因为GFW的限制导致国内无法直接访问谷歌,那么SSR为什么能绕过限 ...
- python基础四(json\os\sys\random\string模块、文件、函数)
一.文件的修改 文件修改的两种思路: 1.把文件内容拿出来,做修改后,清空原来文件的内容,然后把修改过的文件内容重新写进去. 步骤: 1.打开文件:f=open('file','a+') #必须用a ...
- Linux:less and Aix:more
在运维工作中,经常要查询应用日志,有Linux和Aix系统,个人感觉,Linux查询日志用less命令比较方便,Aix查询日志用more命令比较方便,在此总结一下两个命令的使用方法 AIX more命 ...
- [LeetCode]78. 子集(位运算;回溯法待做)
题目 给定一组不含重复元素的整数数组 nums,返回该数组所有可能的子集(幂集). 说明:解集不能包含重复的子集. 示例: 输入: nums = [1,2,3] 输出: [ [3], [1], ...
- [Codeforces1174B]Ehab Is an Odd Person
题目链接 https://codeforces.com/contest/1174/problem/B 题意 给一个数组,只能交换和为奇数的两个数,问最终能得到的字典序最小的序列. 题解 内心OS:由题 ...
- Java虚拟机栈--栈帧
栈帧的内部结构 每个栈帧中存储着 1.局部变量表(Local Variables) 2.操作数栈(Operand Stack)(或表达式栈) 3.动态链接(Dynamic Linking)(或执行&q ...