无所不能的Embedding5 - skip-thought的兄弟们[Trim/CNN-LSTM/quick-thought]
这一章我们来聊聊skip-thought的三兄弟,它们在解决skip-thought遗留问题上做出了不同的尝试【Ref1~4】, 以下paper可能没有给出最优的解决方案(对不同的NLP任务其实没有最优只有最合适)但它们提供了另一种思路和可能性。上一章的skip-thought有以下几个值得进一步探讨的点
- Q1 RNN计算效率低:Encoder-Decoder都是用的RNN, RNN这种依赖上一步输出的计算方式天然和并行计算互斥, 所以训练那叫一个慢
- Q2 Decoder:作为最后预测时完全用不到的组件,Decoder在训练时占用了大量时间,能否优化?
- Q3 通用文本向量的样本构建:skip-thought只预测前/后一个句子合理么?
- Q4 两个decoder的神奇设计有道理么?
- Q5 pretrain word embedding考虑一下?
- Q6 除了hidden_state还有别的提取句子向量的方式么?
以下按照文章让人眼前一亮的程度从小到大排序
Trim/Rethink skip-thought
【Ref1/2】是同一个作者的a/b篇对skip-thought模型的一些细节进行调整,并在benchmark里拿到了和skip-thought不相上下的结果。主要针对以上Q4,Q5,Q6
作者认为两个decorder的设计没啥必要,基于中间句子的信息,前后句子可以用相同的decoder进行reconstruct。这个假设感觉对翻译类的语言模型不太能接受,不过放在训练通用文本向量的背景下似乎是可以接受的,因为我们希望encoder部分能尽可能提取最大信息并能够在任意上下文语境中泛化,所以简化Decoder更合适。
作者对比了用Glove,word2vec来初始化词向量,结果显示在Evaluation上会比随机初始化表现更好。感觉用预训练词向量初始化的好处有两个,一个是加速收敛,另一个是在做vocabulary expansion时,linear-mapping可能会更准确,用预训练词向量来初始化已经是比较通用的解决方案了。
针对Q6,原始的skip-thought最终输出的文本向量就是Encoder最后一个hidden_state,那我们有没有可能去利用到整个sequence的hiddden state输出呢? 作者提出可以借鉴avg+max pooling, 对Encoder部分所有hidden state做avg, max pooling然后进行拼接作为 输出的文本向量=\([\frac{\sum_{i=1}^T h_i}{T} , max_{i=1}^T h_i]\)。这种方案的假设其实不是把embedding作为一个整体来看,而是把embedding的每一个unit单独作为一个/类特征来看,序列不同位置的output state可能提取了不同的信息,通过avg/max来抽取最有代表性的特征作为句子特征。这个问题我们之后还会多次碰到,语言模型训练好了拿什么做句子向量更合适呢?这里留个伏笔吧
所以感觉自己实现的其实是Trimed skip-thought, 我用的word2vec来初始化,只用了1个decoder来训练pair样本。。。感兴趣的望过来 Github-Embedding-skip_thought
Trim算是对skip-thought进行了瘦身,想要提速?看下面
CNN-LSTM
【Ref3】对Q1给出的解决方案是用CNN来替代RNN作为提取句子信息的Encoder, 这样就可以解决RNN计算无法并行的问题。具体实现就需要解决两个问题:
- 如何把不定长的sequence压缩到相同长度
- CNN如何抽取序列特征
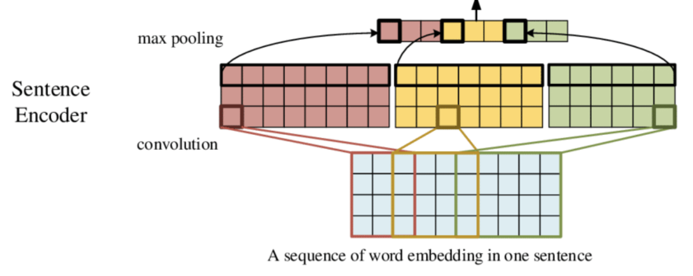
模型结构如上,这里sequence的token经过embedding之后作为输入, 假定sequence的padding length相同都是N,embedding的维度都是K, 输入就是N * K。按1维图像来理解,这里N是图像长度,K是图像channel。
作者定义了3种不同kernel_size=3/4/5的cnn cell,其实和n-gram的原理近似就是分别学习局部window_size=3/4/5的三种序列信息,因为cnn是共享参数的所以1个filter只能提取1种token组合的序列特征,所以每个cnn cell都有800个filter。以kernel_size=3为例,cnn的权重向量维度是3K800, 和sequence embedding 进行计算后的输出是(N-3+1)* 800。
为了压缩到相同长度,在以上输出后加入了max_pooling层(多数cnn用于NLP的任中max据说都比avg要好),沿sequence维度进行pooling把以上输出压缩到1* 800,简单理解就是每个filter在该sequence上只保留最显著的1个特征。3个不同kernel_size的输出拼接就得到了hidden_size=2400的向量。这也是最终得到的文本对应的向量表达。
考虑只有encoder差别比较大,索性把CNN-LSTM和上一章的skip-thought放一块了,只对encoder/decoder的cell选择做了区分。这里只给出CNN Encodere的实现,bridge的部分是参考了google的seq2seq,完整代码看这里Github-Embedding-skip_thought
def cnn_encoder(input_emb, input_len, params):
# batch_szie * seq_len * emb_size -> batch_size * (seq_len-kernel_size + 1) * filters
outputs = []
params = params['encoder_cell_params']
for i in range(len(params['filters'])):
output = tf.layers.conv1d(inputs = input_emb,
filters = params['filters'][i],
kernel_size = params['kernel_size'][i], # window size, simlar as n-gram
strides = params['strides'][i],
padding = params['padding'][i]
)
output = params['activation'][i](output)
# batch_size * (seq_len-kernel_size + 1) * filters -> batch_size * filters
outputs.append(tf.reduce_max(output, axis=1))
# batch_size * sum(filters)
output = tf.concat(outputs, axis=1)
return ENCODER_OUTPUT(output=output, state=(output,))
感觉这里压缩到相同长度也可以用Padding,以及cnn学习不同长度的文本信息,作者用的是不同kernel size做拼接,也可以尝试stack cnn,这样两个kernel=3的cnn就能学到长度为9的文本序列信息。
Decoder这里作者使用了LSTM,不过就像之前在skip-thought中提到的,因为有teacher forcing感觉decoder并不十分重要这里就不提了。
论文还有一个比较有意思的点就Q3,作者对skip-thought的核心假设发出了灵魂提问:为啥中间句子的信息=用于reconstruct前后句子的信息? (其实上面Trim的论文中中也做了类似的尝试这里和在一起说)
作者给出了几个方案
- 中间句子reconstruct中间句子的autoencoder任务
- 中间句子reconstruct中间句子,以及前/后1个句子的composite任务
- 放大时间窗口,用中间句子预测之后好几个句子的hierarchical任务
感觉autoencoder更多捕捉intra-sentence的syntax信息,比如语法/句式结构,而前后句子的reconstruct任务学习inter-sentence的semantic信息,例如上下文语境。所以是不是也可以理解为,autoencoder训练得到文本向量的相似可能会长得相似,而前后句子训练得到的文本向量的相似会更多存在语义/上下文语境的相似。
抛去直觉唯指标论的话,在Trim论文里加入AE的模型只在question-type的分类任务(more syntax)上有提升,对其他例如movie-review等semantic classification任务都有损失。但在CNN的论文里只用AE/加入AE的模型在所有分类任务上表现都更好,我也是有些迷惑。。。
那究竟什么训练样本可以训练得到通用的文本向量?这里的通用是指在任意downstream任务里都能拿到不错的效果。这里留个疑问吧,看后面USE等基于多任务联合学习的尝试能不能解答这个问题~
Quick-thought
【Ref4】终于跳出了翻译类语言模型的框框,对Q2给出了新的解决方案。既然对于文本向量表达来说Decoder又慢又没用,那咱索性不要了,直接把reconstruct任务替换为分类任务。之后这个思路也在BERT预训练中作为NSP训练任务直接使用。
这里分类任务的思路和word2vec中使用的negative sampling来训练词向量可以说是同样的配方熟悉的味道, 都涉及到正负样本的构建,对于word2vec的skip-gram来说正样本就是window_size内的单词,负样本从词典中随机采样得到。这里Quick-thought和skip-thought保持一致,正样本是window_size内的句子,也就是用中间句子来预测前后句子,负样本则是batch里面除了前后句子之外的其他句子。
既然提到正负样本,那skip-thought的正负样本是什么呢? 考虑到teacher-forcing的使用,skip-thought是基于中间句子和前后句子T-1的单词来预测第T个单词是什么,负样本就是除了第T个单词外vocabulary里面的其他单词(和skip-gram一毛一样)。所以作者也在论文中提到这种reconstruct任务可能会学到过于表面的文本信息而难以学到更general的语义信息。而分类任务这种只需要上下文句子整体比其他句子更相似的训练框架不会存在这个问题。

模型结构如上,Encoder部分用任意方式提取信息,可以是skip-thogut里面使用的gru,也可以用上面的CNN。这里和skip-gram一样用两套独立参数的encoder分别对input和target来进行信息提取得到两个定长的output state。为了保证最大化state学到的文本信息,分类器这里采取了最简单的操作,就是两个state直接做向量内积,然后内积直接做binary classification。
在预测的时候用两个encoder分别对输入句子进行信息提取,然后把得到的state进行拼接作为模型提取的文本向量
懒得挪地就把quick thought也和skip thought也放在一起了,反正Encoder部分是可以共享的, 完整代码看这里Github-Embedding-skip_thought
class EncoderBase(object):
def __init__(self, params):
self.params = params
self.init()
def init(self):
with tf.variable_scope('embedding', reuse=tf.AUTO_REUSE):
self.embedding = tf.get_variable(dtype = self.params['dtype'],
initializer=tf.constant(self.params['pretrain_embedding']),
name='word_embedding' )
add_layer_summary(self.embedding.name, self.embedding)
def general_encoder(self, features):
encoder = ENCODER_FAMILY[self.params['encoder_type']]
seq_emb_input = tf.nn.embedding_lookup(self.embedding, features['tokens']) # batch_size * max_len * emb_size
encoder_output = encoder(seq_emb_input, features['seq_len'], self.params) # batch_size
return encoder_output
def vectorize(self, state_list, features):
with tf.variable_scope('inference'):
result={}
# copy through input for checking
result['input_tokenid']=tf.identity(features['tokens'], name='input_id')
token_table = tf.get_collection('token_table')[0]
result['input_token']= tf.identity(token_table.lookup(features['tokens']), name='input_token')
result['encoder_state'] = tf.concat(state_list, axis = 1, name ='sentence_vector')
return result
class QuickThought(EncoderBase):
def __init__(self, params):
super(QuickThought, self).__init__(params)
def build_model(self, features, labels, mode):
input_encode = self.input_encode(features)
output_encode = self.output_encode(features, labels, mode)
sim_score = tf.matmul(input_encode.state[0], output_encode.state[0], transpose_b=True) # [batch, batch] sim score
add_layer_summary('sim_score', sim_score)
loss = self.compute_loss(sim_score)
def input_encode(self, features):
with tf.variable_scope('input_encoding', reuse=False):
encoder_output = self.general_encoder(features)
add_layer_summary('state', encoder_output.state)
add_layer_summary('output', encoder_output.output)
return encoder_output
def output_encode(self, features, labels, mode):
with tf.variable_scope('output_encoding', reuse=False):
if mode == tf.estimator.ModeKeys.PREDICT:
encoder_output = self.general_encoder(features)
else:
encoder_output=self.general_encoder(labels)
add_layer_summary('state', encoder_output.state)
add_layer_summary('output', encoder_output.output)
return encoder_output
def compute_loss(self, sim_score):
with tf.variable_scope('compute_loss'):
batch_size = sim_score.get_shape().as_list()[0]
sim_score = tf.matrix_set_diag(sim_score, np.zeros(batch_size))
# create targets: set element within diagonal offset to 1
targets = np.zeros(shape = (batch_size, batch_size))
offset = self.params['context_size']//2 ## offset of the diagonal
for i in chain(range(1, 1+offset), range(-offset, -offset+1)):
diag = np.diagonal(targets, offset = i)
diag.setflags(write=True)
diag.fill(1)
targets = targets/np.sum(targets, axis=1, keepdims = True)
targets = tf.constant(targets, dtype = self.params['dtype'])
losses = tf.nn.softmax_cross_entropy_with_logits(labels = targets,
logits = sim_score)
losses = tf.reduce_mean(losses)
return losses
欢迎留言吐槽以及评论哟~
无所不能的embedding系列
https://github.com/DSXiangLi/Embedding
无所不能的Embedding1 - Word2vec模型详解&代码实现
无所不能的Embedding2 - FastText词向量&文本分类
无所不能的Embedding3 - word2vec->Doc2vec[PV-DM/PV-DBOW]
无所不能的Embedding4 - Doc2vec第二弹[skip-thought & tf-Seq2Seq源码解析]
【REF】
- Rethinking Skip-thought: A Neighbourhood based Approach, Tang etc, 2017
- Triming and Improving Skip-thought Vectors, Tang etc, 2017
- Learning Generic Sentence Representations Using Convolutional Neural Netword, Gan etc, 2017
- An Efficient Framework fir learning sentennce representations, Lajanugen etc, 2018
- https://zhuanlan.zhihu.com/p/50443871
无所不能的Embedding5 - skip-thought的兄弟们[Trim/CNN-LSTM/quick-thought]的更多相关文章
- Bert不完全手册3. Bert训练策略优化!RoBERTa & SpanBERT
之前看过一条评论说Bert提出了很好的双向语言模型的预训练以及下游迁移的框架,但是它提出的各种训练方式槽点较多,或多或少都有优化的空间.这一章就训练方案的改良,我们来聊聊RoBERTa和SpanBER ...
- 【机器学习Machine Learning】资料大全
昨天总结了深度学习的资料,今天把机器学习的资料也总结一下(友情提示:有些网站需要"科学上网"^_^) 推荐几本好书: 1.Pattern Recognition and Machi ...
- linq的简单查询 和 组合查询
以Car表和Brand表为例,其中Car表的Brand是Brand表的Brandcode. (1)建立两表的linq(一定要做好主外键关系,),创建之后不用修改,如要添加,另建文件. (2)Car表的 ...
- 机器学习(Machine Learning)&深度学习(Deep Learning)资料【转】
转自:机器学习(Machine Learning)&深度学习(Deep Learning)资料 <Brief History of Machine Learning> 介绍:这是一 ...
- Webform--LinQ 分页组合查询
一.linq高级查 1.模糊查(字符串包含) public List<User> Select(string name) { return con.User.Where(r => r ...
- 谈一谈深度学习之semantic Segmentation
上一次发博客已经是9月份的事了....这段时间公司的事实在是多,有写博客的时间都拿去看paper了..正好春节回来写点东西,也正好对这段时间做一个总结. 首先当然还是好好说点这段时间的主要工作:语义分 ...
- zz全面拥抱Transformer
放弃幻想,全面拥抱Transformer:自然语言处理三大特征抽取器(CNN/RNN/TF)比较 在辞旧迎新的时刻,大家都在忙着回顾过去一年的成绩(或者在灶台前含泪数锅),并对2019做着规划,当然也 ...
- 机器学习(Machine Learning)与深度学习(Deep Learning)资料汇总
<Brief History of Machine Learning> 介绍:这是一篇介绍机器学习历史的文章,介绍很全面,从感知机.神经网络.决策树.SVM.Adaboost到随机森林.D ...
- Linux就这个范儿 第10章 生死与共的兄弟
Linux就这个范儿 第10章 生死与共的兄弟 就说Linux系统的开机.必须经过加载BIOS.读取MBR.Boot Loader.加载内核.启动init进程并确定运行等级.执行初始化脚本.启动内核模 ...
随机推荐
- vim-配置教程+源码
目录 概念 前言 参考链接 vim 优点 vim 配置 vim 配置方法一 vim 配置方法二 自动添加文件头 一般设置 插件 ** 映射 YouCompleteMe 插件 其它配置 概念 前言 放弃 ...
- Thinkphp3.2 cms之权限管理
五.权限管理 <?php namespace Admin\Controller; use Think\Controller; class CommonController extends Con ...
- 2、Django源码分析之启动wsgi发生了哪些事
一 前言 Django是如何通过网络socket层接收数据并将请求转发给Django的urls层? 有的人张口就来:就是通过wsgi(Web Server Gateway Interface)啊! D ...
- leetcode4:sort-list
题目描述 在O(n log n)的时间内使用常数级空间复杂度对链表进行排序. Sort a linked list in O(n log n) time using constant space co ...
- .NET 5.0正式发布,功能特性介绍(翻译)
本文由葡萄城技术团队翻译并首发 转载请注明出处:葡萄城官网,葡萄城为开发者提供专业的开发工具.解决方案和服务,赋能开发者. 我们很高兴今天.NET5.0正式发布.这是一个重要的版本-其中也包括了C# ...
- 想更改Github仓库中的某个文件结构
虽然有各种版本回退啥的,可是感觉好麻烦,还是没搞来,后来发现可以直接先删除,然后在本地更改,更改完之后重新添加一次即可 删除远程库的某个文件: $ git pull origin master 将远程 ...
- EF6 Code First 博客学习记录
学习一下ef6的用法 这个学习过程时按照微软官网的流程模拟了一下 就按照下面的顺序来写吧 1.连接数据库 自动生成数据库 2.数据库迁移 3.地理位置以及同步/异步处理(空了再补) 4.完全自动迁移 ...
- Martini初步
部分内容来自http://jerkwin.github.io/9999/08/01/Martini%E7%B2%97%E7%B2%92%E5%8C%96%E5%8A%9B%E5%9C%BA%E4%BD ...
- python + appium 执行报错整理
1.driver.find_element_by_id("com.taobao.taobao:id/searchEdit").send_keys("adidas" ...
- Spring源码之Springboot中监听器介绍
https://www.bilibili.com/video/BV12C4y1s7dR?p=11 监听器模式要素 事件 监听器 广播器 触发机制 Springboot中监听模式总结 在SpringAp ...