Hive常用性能优化方法实践全面总结
Apache Hive作为处理大数据量的大数据领域数据建设核心工具,数据量往往不是影响Hive执行效率的核心因素,数据倾斜、job数分配的不合理、磁盘或网络I/O过高、MapReduce配置的不合理等等才是影响Hive性能的关键。
Hive在执行任务时,通常会将Hive SQL转化为MapReduce job进行处理。因此对Hive的调优,除了对Hive语句本身的优化,也要考虑Hive配置项以及MapReduce相关的优化。从更底层思考如何优化性能,而不是仅仅局限于代码/SQL的层面。
列裁剪和分区裁剪
Hive在读数据的时候,只读取查询中所需要用到的列,而忽略其它列。例如,若有以下查询:
SELECT age, name FROM people WHERE age > 30;
在实施此项查询中,people表有3列(age,name,address),Hive只读取查询逻辑中真正需要的两列age、name,而忽略列address;这样做节省了读取开销,中间表存储开销和数据整合开销。
同理,对于Hive分区表的查询,我们在写SQL时,通过指定实际需要的分区,可以减少不必要的分区数据扫描【当Hive表中列很多或者数据量很大时,如果直接使用select * 或者不指定分区,效率会很低下(全列扫描和全表扫描)】。
Hive中与列裁剪和分区裁剪优化相关的配置参数分别为:hive.optimize.cp和hive.optimize.pruner,默认都是true。
谓词下推
在关系型数据库如MySQL中,也有谓词下推(Predicate Pushdown,PPD)的概念。它就是将SQL语句中的where谓词逻辑都尽可能提前执行,减少下游处理的数据量。
如下Hive SQL语句:
select a.*, b.* from a join b on (a.id = b.id)where a.id > 15 and b.num > 16;
如果没有谓词下推,上述SQL需要在完成join处理之后才会执行where条件过滤。在这种情况下,参与join的数据可能会非常多,从而影响执行效率。
使用谓词下推,那么where条件会在join之前被处理,参与join的数据量减少,提升效率。
在Hive中,可以通过将参数hive.optimize.ppd设置为true,启用谓词下推。与它对应的逻辑优化器是PredicatePushDown。该优化器就是将OperatorTree中的FilterOperator向上提,见下图:
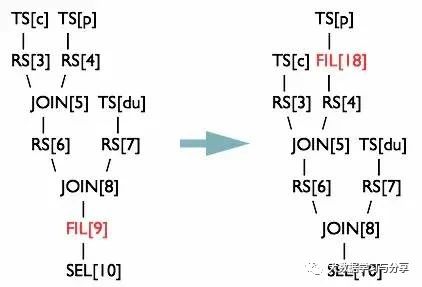
Hive join优化
关于Hive join,参考文章:《Hive join优化》。
hive.fetch.task.conversion
虽然Hive底层可以将Hive SQL转化为MapReduce执行,但有些情况不使用MapReduce处理效率跟高。比如对于如下SQL:
SELECT name FROM people;
在这种情况下,Hive可以简单地读取people对应的存储目录下的文件,然后返回数据。
在hive-default.xml.template文件中hive.fetch.task.conversion默认是more,老版本hive默认是minimal,该属性修改为more以后,在全局查找、字段查找、limit查找等都不走mapreduce。
<property>
<name>hive.fetch.task.conversion</name>
<value>more</value>
<description>
Expects one of [none, minimal, more].
Some select queries can be converted to single FETCH task minimizing latency.
Currently the query should be single sourced not having any subquery and should not have
any aggregations or distincts (which incurs RS), lateral views and joins.
0. none : disable hive.fetch.task.conversion
1. minimal : SELECT STAR, FILTER on partition columns, LIMIT only
2. more : SELECT, FILTER, LIMIT only (support TABLESAMPLE and virtual columns)
</description>
</property>
将hive.fetch.task.conversion设置成none,在Hive shell中执行如下语句,都会执行MapReduce程序。
hive> set hive.fetch.task.conversion=none;
hive> select name from people;
hive> select * from people;
把hive.fetch.task.conversion设置成more,然后执行如下语句,如下查询方式都不会执行MapReduce程序。
hive> set hive.fetch.task.conversion=more;
hive> select name from people;
hive> select * from people;
通过参数说明发现当把hive.fetch.task.conversion设置成none时,所有的程序都走mapreduce程序会耗费一定的时间。但就算设置成more,也只有部分sql语句会不走MapReduce程序,那有没有什么办法可以优化这个问题呢?这就不得不提本地模式了。
group by
1)map端预聚合
通过在map端进行一次预聚合(起一个combiner),可以有效减少shuffle的数据量,然后再在reduce端得到最终结果。
预聚合的配置参数为hive.map.aggr,默认值true。
此外,通过hive.groupby.mapaggr.checkinterval参数可以设置map端预聚合的条数阈值,超过该值就会分拆job,默认值100000。
2)数据倾斜时进行负载均衡处理
当group by时,如果某些key对应的数据量过大,会导致数据倾斜。
通过将参数hive.groupby.skewindata(默认false)设置为true,那么在进行group by时,会启动两个MR job。第一个job会将map端数据随机输入reducer,每个reducer做部分聚合操作,相同的group by key会分布在不同的reducer中。第二个job再将前面预处理过的数据按key聚合并输出结果,这样就起到了均衡的效果。
但是,相对于正常的任务执行,该参数配置为true时会多启动一个MR job,会增加开销,单纯依赖它解决数据倾斜并不能从根本上解决问题。因此,建议分析数据、Hive SQL语句等,了解产生数据倾斜的根本原因进行解决。
count(distinct)
count(distinct)采用非常少的reducer进行数据处理。数据量小时对执行效率影响不明显,但是当数据量大时,效率会很低,尤其是数据倾斜的时候。
可以通过group by代替count(distinct)使用。示例如下:
原SQL:SELECT count(DISTINCT id) FROM people;
group by替换后:SELECT count(id) FROM (SELECT id FROM people GROUP BY id) tmp;
注意:上述group by替换后,会启动两个MR job(只是distinct只会启动一个),所以要确保启动job的开销远小于计算耗时,才考虑这种方法。否则当数据集很小或者key的倾斜不明显时,group by还可能会比count(distinct)还慢。
此外,如何用group by方式同时统计多个列?下面提供一种SQL方案:
select tmp.a, sum(tmp.b), count(tmp.c), count(tmp.d) from (
select a, b, null c, null d from some_table
union all
select a, 0 b, c, null d from some_table group by a,c
union all
select a, 0 b, null c, d from some_table group by a,d
) tmp;
笛卡尔积
除非业务需要,在生产中要极力避免笛卡尔积,比如在join语句中不指定on连接条件,或者无效的on连接条件,Hive只能使用1个reducer来完成笛卡尔积。
本地模式
对于处理小数据量的任务,我们不需要通过集群模式进行处理(因为为该任务实际触发的job执行等开销可能比实际任务的执行时间还要长),Hive可以通过本地模式在单台机器上处理所有的任务。
可以通过设置hive.exec.mode.local.auto的值为true,来让Hive在适当的时候自动启动这个优化。
set hive.exec.mode.local.auto=true;
设置本地MR的最大输入数据量,当输入数据量小于这个值时采用本地MR的方式,默认为134217728,即128M
set hive.exec.mode.local.auto.inputbytes.max=51234560;
设置本地MR的最大输入文件个数,当输入文件个数小于这个值时采用本地MR的方式,默认为4
set hive.exec.mode.local.auto.input.files.max=10;
left semi join替代in/exsits
left semi join是in、exists的高效实现。比如,对于如下SQL
select t1.id, t1.name from t1 where t1.id in (select t2.id from t2);
改为left semi join执行:
select t1.id, t1.name from t1 left semi join t2 on t1.id = t2.id;
MapReduce相关的优化
1. mapper和reducer个数
关于MapReduce中mapper和reducer个数的决定机制,建议阅读文章:《详解MapReduce》
2. 合并小文件
1)输入阶段合并
设置参数hive.input.format为org.apache.hadoop.hive.ql.io.CombineHiveInputFormat。(默认值是org.apache.hadoop.hive.ql.io.HiveInputFormat)。
此外还需配置两个参数:mapred.min.split.size.per.node(单节点上的最小split大小)和mapred.min.split.size.per.rack(单机架上的最小split大小)。
如果有split大小小于这两个值,则会进行合并。
2)输出阶段合并
将hive.merge.mapfiles和hive.merge.mapredfiles都设为true,前者表示将map-only任务的输出合并,后者表示将map-reduce任务的输出合并。
此外,hive.merge.size.per.task可以指定每个task输出后合并文件大小的期望值,hive.merge.size.smallfiles.avgsize可以指定所有输出文件大小的均值阈值。如果平均大小不足的话,就会另外启动一个任务来进行合并。
3. 启用压缩
压缩job的中间结果数据和输出数据,可以用少量CPU时间节省很多空间,压缩方式一般选择Snappy。(关于Hadoop支持的压缩格式,参考文章:《 Hadoop支持的压缩格式对比和应用场景以及Hadoop native库 》)
要启用中间压缩,需要设定hive.exec.compress.intermediate为true,同时指定压缩方式hive.intermediate.compression.codec为org.apache.hadoop.io.compress.SnappyCodec。
另外,参数hive.intermediate.compression.type可以选择对块(BLOCK)还是记录(RECORD)压缩,BLOCK的压缩率比较高。
输出压缩的配置基本相同,打开hive.exec.compress.output即可。
4. JVM重用
在MR job中,默认是每执行一个task就启动一个JVM。可以通过配置参数mapred.job.reuse.jvm.num.tasks来进行JVM重用。
例如将这个参数设成5,那么就代表同一个MR job中顺序执行的5个task可以重复使用一个JVM,减少启动和关闭的开销。但它对不同MR job中的task无效。
采用合适的存储格式
在HiveQL的create table语句中,可以使用stored as ...指定表的存储格式。Hive目前支持的存储格式有TextFile、SequenceFile、RCFile、avro、orc、parquet等。
当然,我们也可以采用alter table … [PARTITION partition_spec] set fileformat,修改具体表的文件格式
parquet和orc是企业中常用的两种数据存储格式,具体可以参考官网:
https://parquet.apache.org/和https://orc.apache.org/。
推测执行
在分布式集群环境下,由于负载不均衡或者资源分布不均等原因,会造成同一个作业的多个job之间运行速度不一致,有些job的运行速度可能明显慢于其他任务,则这些job会拖慢整个作业的执行进度。为了避免这种情况发生,Hadoop采用了推测执行(Speculative Execution)机制。
"推测执行"机制,根据一定的规则推测出"拖后腿"的任务,并为这样的任务启动一个备份任务,让该任务与原始任务同时处理同一份数据,并最终选用最先成功运行完成任务的计算结果作为最终结果。
Hive同样可以开启推测执行。设置开启推测执行参数(在配置文件mapred-site.xml中进行配置)
<property>
<name>mapreduce.map.speculative</name>
<value>true</value>
<description>If true, then multiple instances of some map tasks
may be executed in parallel.</description>
</property> <property>
<name>mapreduce.reduce.speculative</name>
<value>true</value>
<description>If true, then multiple instances of some reduce tasks
may be executed in parallel.</description>
</property>
hive本身也提供了配置项来控制reduce-side的推测执行:
<property>
<name>hive.mapred.reduce.tasks.speculative.execution</name>
<value>true</value>
<description>Whether speculative execution for reducers should be turned on. </description>
</property>
关于调优这些推测执行变量,目前还很难给出一个具体建议。如果用户对于运行时的偏差非常敏感的话,那么可以将这些功能关闭掉。如果用户因为输入数据量很大而需要执行长时间的map或者reduce task的话,那么启动推测执行造成的浪费是非常巨大。
推荐文章:
一次Java内存泄漏的排查
经典的SparkSQL/Hive-SQL/MySQL面试-练习题
关注微信公众号:大数据学习与分享,获取更对技术干货
Hive常用性能优化方法实践全面总结的更多相关文章
- (摘录)26个ASP.NET常用性能优化方法
数据库访问性能优化 数据库的连接和关闭 访问数据库资源需要创建连接.打开连接和关闭连接几个操作.这些过程需要多次与数据库交换信息以通过身份验证,比较耗费服务器资源. ASP.NET中提供了连接池(Co ...
- 26个ASP.NET常用性能优化方法
数据库访问性能优化 数据库的连接和关闭 访问数据库资源需要创建连接.打开连接和关闭连接几个操作.这些过程需要多次与数据库交换信息以通过身份验证,比较耗费服务器资源. ASP.NET中提供了连接池(Co ...
- ASP.NET26 个常用性能优化方法
数据库访问性能优化 数据库的连接和关闭 访问数据库资源需要创建连接.打开连接和关闭连接几个操作.这些过程需要多次与数据库交换信息以通过身份验证,比较耗费服务器资源. ASP.NET中提供了连接池(Co ...
- 【读书笔记】读《高性能网站建设指南》及《高性能网站建设进阶指南:Web开发者性能优化最佳实践》
这两本书就一块儿搞了,大多数已经理解,简单做个标记.主要对自己不太了解的地方,做一些记录. 一.读<高性能网站建设指南> 0> 黄金性能法则:只有10%~20%的最终用户响应时间 ...
- HBase性能优化方法总结(转)
本文主要是从HBase应用程序设计与开发的角度,总结几种常用的性能优化方法.有关HBase系统配置级别的优化,这里涉及的不多,这部分可以参考:淘宝Ken Wu同学的博客. 1. 表的设计 1.1 Pr ...
- HBase性能优化方法总结(一):表的设计
本文主要是从HBase应用程序设计与开发的角度,总结几种常用的性能优化方法.有关HBase系统配置级别的优化,可参考:淘宝Ken Wu同学的博客. 下面是本文总结的第一部分内容:表的设计相关的优化方法 ...
- redmine在linux上的mysql性能优化方法与问题排查方案
iredmine的linux服务器mysql性能优化方法与问题排查方案 问题定位: 客户端工具: 1. 浏览器inspect-tool的network timing工具分析 2. 浏览 ...
- [原创]浅谈H5页面性能优化方法
[原创]浅谈H5页面性能优化方法 前阶段公司H5页面性能测试,其中测试时也发现了一些性能瓶颈问题,接下来我们在来谈谈H5页面性能优化,仅仅是一些常用H5页面性能优化措施,其实和Web页面性能优化思路大 ...
- .NET 性能优化方法总结==转
.NET 性能优化方法总结 目录 目录 1. C#语言方面... 4 1.1 垃圾回收... 4 1.1.1 避免不必要的对象创建... 4 1.1.2 不要使用空析构函数 ★... 4 1.1.3 ...
随机推荐
- 浅谈强连通分量(Tarjan)
强连通分量\(\rm (Tarjan)\) --作者:BiuBiu_Miku \(1.\)一些术语 · 无向图:指的是一张图里面所有的边都是双向的,好比两个人打电话 \(U ...
- Python 的 10 个开发技巧!太实用了
1. 如何在运行状态查看源代码? 查看函数的源代码,我们通常会使用 IDE 来完成. 比如在 PyCharm 中,你可以 Ctrl + 鼠标点击 进入函数的源代码. 那如果没有 IDE 呢? 当我们想 ...
- C#中搜索xsd文件中的某个数据源
步骤 1.打开***.xsd文件. 2.数据源之间的空白处,右键->属性. 3.在VS右侧会跳出一个属性窗口. 4.有个名称为DataSet的下拉框,所有的数据源名称都在其中,单击即可定位到所选 ...
- [.NET] - Enhanced Strong Naming (加强版的强签名程序集) – 如何迁移原有的强命名程序集
依据文档: https://msdn.microsoft.com/en-us/library/hh415055(v=vs.110).aspx 虽然文档上给出了看似完整的步骤,但是如果按照上面的步骤,结 ...
- Java进阶专题(二十) 消息中间件架构体系(2)-- RabbitMQ研究
前言 接上文,这个继续介绍RabbitMQ,并理解其底层原理. 介绍 RabbitMQ是由erlang语言开发,基于AMQP(Advanced Message Queue 高级消息队列协议)协议实现的 ...
- sql中模糊查询和在开始和结束时间之间
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE mapper PUBLIC "-/ ...
- idea提交svn不显示新建文件
在idea中,使用svn提交时可能会出现 预期文件没出现在提交目录里. 是因为没有把新建文件添加到版本控制里. 解决办法:右键选择文件→subversion→add to vcs. 自动把新文件添加 ...
- 在Ubuntu14.04下配置Samba 完成linux和windows之间的文件共享
在Windows和Linux之间传递文件可以使用Samba服务.下面是安装步骤: 1. 安装Samba. sudo apt-get install samba 2. 修改配置文件 sudo gedit ...
- ProceedingJoinPoint 某些方法记录一下
转载与百度知道,记录一下.遇到在去看API 官方文档//拦截的实体类 Object target = point.getTarget(); //拦截的方法名称 String methodName = ...
- 多线程并行_countDown
/** * 首次启动加载数据至缓存 */ public class ApplicationStartTask { private static Logger logger = LoggerFactor ...