NumPy速查笔记(持续更新中)
1 总览
NumPy是基于Python的科学计算包,主要用来进行科学计算。
2 ndarray
ndarray全名叫做n dimension array,习惯称为多维数组。ndarray既可以表示标量,还可以表示向量、矩阵,甚至是张量。
ndarray有如下属性:
dtype数据类型shape多维数组的尺寸ndim维度,等同轴的个数size元素的个数itemsizenbytesbaseflagsstridesdataT转置realimagflatctypes
ndarray的方法其实已经可以对当前ndarray进行处理和运算的,但也可以把当前ndarray当做参数传递给NumPy顶层的函数np.<function_name>。
举例:
ndarray.dot(x)和np.dot(ndarray, x)是一样的
3 常用API
3.1 创建ndarray
创建ndarray大致可分为五种方法。
(1)将Python类似数组的对象转化成Numpy数组
array(object, dtype=None, copy=True, order='K', subok=False, ndmin=0)asarray(a, dtype=None, order=None)asanyarray(a, dtype=None, order=None)ascontiguousarray(a, dtype=None)asmatrix(data, dtype=None)copy(a, order='K')
(2)numpy内置的数组创建
注意:
(1) prototype表示array-like,就是类似数组的对象
(2) 部分对角矩阵涉及对角线的索引。0表示原始主对角线,1表示往右上平移一个单位,-1表示往左下平移一个单位
empty(shape, dtype=float, order='C')随机矩阵empty_like(prototype, dtype=None, order='K', subok=True, shape=None)eye(N, M=None, k=0, dtype=<class 'float'>, order='C')伪单位矩阵identity(n, dtype=None)真实的单位矩阵ones(shape, dtype=None, order='C')ones_like(a, dtype=None, order='K', subok=True, shape=None)zeros(shape, dtype=float, order='C')zeros_like(a, dtype=None, order='K', subok=True, shape=None)full(shape, fill_value, dtype=None, order='C')单一值填充矩阵full_like(a, fill_value, dtype=None, order='K', subok=True, shape=None)arange([start, ]stop, [step, ]dtype=None)相当于python的rangelinspace(start, stop, num=50, endpoint=True, retstep=False, dtype=None, axis=0)在区间内生成若干个等距离的数据点logspace(start, stop, num=50, endpoint=True, base=10.0, dtype=None, axis=0)$base^{start}$到$base^{stop}$geomspace(start, stop, num=50, endpoint=True, dtype=None, axis=0)meshgrid(*xi, **kwargs)mgrid()ogrid()indices(dimensions, dtype=<class 'int'>, sparse=False)diag(v, k=0)如果v是一维的,构建一个对角阵,v为第k个主对角线上的元素;如果v是二维的,抽取出主对角线的元素并返回diagflat(v, k=0)将输入铺平成一维数组,然后以此为对角线元素构建矩阵tri(N, M=None, k=0, dtype=<class float>)== 创建N*M的下三角矩阵,第k个对角线及其下方都为1tril(m, k=0)把多维数组m变成下三角矩阵,第k对角线及其以上用0填充triu(m, k=0)把多维数组m变成上三角矩阵,第k对角线及其以下用0填充vander(x, N=None, increasing=False)创建范德蒙德矩阵mat(data, dtype=None)把data解析成matrix,若输入已经是matrix,将不会再次复制而是直接使用bmat(obj, ldict=None, gdict=None)从字符串、嵌套序列或者数组中创建矩阵
>>> np.empty([3, 3])
array([[1.69118108e-306, 2.04722549e-306, 6.23054972e-307],
[7.56605239e-307, 1.33511562e-306, 8.01097889e-307],
[1.24610723e-306, 8.34444713e-308, 2.29179042e-312]])
>>> np.empty_like([1, 2, 3])
array([0, 0, 0])
>>> np.identity(4)
array([[1., 0., 0., 0.],
[0., 1., 0., 0.],
[0., 0., 1., 0.],
[0., 0., 0., 1.]])
>>> np.eye(3, 4, k=1)
array([[0., 1., 0., 0.],
[0., 0., 1., 0.],
[0., 0., 0., 1.]])
>>> np.arange(12)
array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11])
>>> np.linspace(1, 5, 20)
array([1. , 1.21052632, 1.42105263, 1.63157895, 1.84210526,
2.05263158, 2.26315789, 2.47368421, 2.68421053, 2.89473684,
3.10526316, 3.31578947, 3.52631579, 3.73684211, 3.94736842,
4.15789474, 4.36842105, 4.57894737, 4.78947368, 5. ])
>>> np.logspace(1, 5, 3)
array([1.e+01, 1.e+03, 1.e+05])
>>> np.tri(3, 3, -1)
array([[0., 0., 0.],
[1., 0., 0.],
[1., 1., 0.]])
>>> np.triu([[1, 2, 3], [2, 3, 4], [4, 5, 6], [5, 6, 7]])
array([[1, 2, 3],
[0, 3, 4],
[0, 0, 6],
[0, 0, 0]])
难点: meshgrid()
meshgrid的作用,根据两个向量,在空间中画网格,返回两个矩阵,分别是网格上每个点的横坐标和纵坐标。
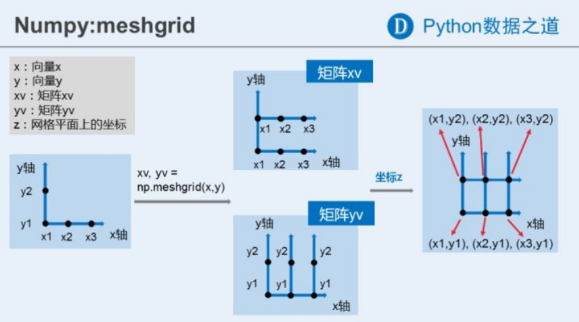
>>> np.meshgrid([1, 2, 3], [2, 3, 4])
[array([[1, 2, 3],
[1, 2, 3],
[1, 2, 3]]), array([[2, 2, 2],
[3, 3, 3],
[4, 4, 4]])]
(3)从磁盘中读取标准格式或者自定义格式的多维数组
fromfile(file, dtype=float, count=-1, sep='', offset=0)fromfunction(function, shape, **kwargs)fromiter(iterable, dtype, count=-1)loadtxt(fname, dtype=<class 'float'>, comments='#', delimiter=None, converters=None, skiprows=0, usecols=None, unpack=False, ndmin=0, encoding='bytes', max_rows=None)
(4)通过使用字符串或缓冲区从原始字节创建数组
fromstring(string, dtype=float, count=-1, sep='')frombuffer(buffer, dtype=float, count=-1, offset=0)
(5)使用特殊的库函数
通过随机函数来创建,对数据进行初始化的时候很常用。
random.rand(d0, d1, ..., dn)依次传入每个维度的大小,生成[0, 1)的均匀分布(uniform distribution)random.randn(d0, d1, ..., dn)依次传入每个维度的大小,生成[0, 1)的标准正态分布(standard normal distribution)random.randint(low, high=None, size=None, dtype='l')整数的随机分布,大小为[low, high)random.choice(a, size=None, replace=True, p=None)在a中随便选size个元素(可以重复)random.bytes(length)生成随机的字节
random.rand_integer()已经弃用
3.2 索引和切片
numpy有三种索引方式:基本索引、高级索引和字段索引。
(1)基本索引
start:stop:step,这个和python一样
...索引
newaxis扩展维度,严格来说,这个不是用来索引数据的,而是用来扩展维度的,类似的操作是np.expand_dim()
>>> np.array([1, 2, 3, 4])[:, np.newaxis]
array([[1],
[2],
[3],
[4]])
:可以实现按顺序进行多个索引,这个和python一样
和:相比,用数组可以自定义顺序进行多个索引
>>> np.array([0, 1, 2, 3, 4])[[1, 2, 3]]
array([1, 2, 3])
(2)高级索引
>>> np.arange(12).reshape(4, 3)
array([[ 0, 1, 2],
[ 3, 4, 5],
[ 6, 7, 8],
[ 9, 10, 11]])
多轴索引
逗号隔开的索引,依次作用在多个轴上
>>> np.arange(12).reshape(4, 3)[2:, 1:]
array([[ 7, 8],
[10, 11]])
复合索引
每个轴上可以是不同形式的基本索引
>>> np.arange(12).reshape(4, 3)[[1, 2, 3], 1:]
array([[ 4, 5],
[ 7, 8],
[10, 11]])
布尔索引
用一个包含布尔值的布尔数组来达到索引的目的,但要注意,长度是有限制的,必须和第一个维度的长度相等。
>>> np.array([0, 1, 2, 3, 4])[[True, False, False, False, True]]
array([0, 4])
>>> a = np.array([0, 1, 2, 3, 4])
>>> a > 2
array([False, False, False, True, True])
>>> a[a>2]
array([3, 4])
(4)字段索引
暂时不是很清楚。
>>> x = np.zeros((2,2), dtype=[('a', np.int32), ('b', np.float64, (3,3))])
>>> x
array([[(0, [[0., 0., 0.], [0., 0., 0.], [0., 0., 0.]]),
(0, [[0., 0., 0.], [0., 0., 0.], [0., 0., 0.]])],
[(0, [[0., 0., 0.], [0., 0., 0.], [0., 0., 0.]]),
(0, [[0., 0., 0.], [0., 0., 0.], [0., 0., 0.]])]],
dtype=[('a', '<i4'), ('b', '<f8', (3, 3))])
>>> x['a']
array([[0, 0],
[0, 0]])
>>> x['b']
array([[[[0., 0., 0.],
[0., 0., 0.],
[0., 0., 0.]],
[[0., 0., 0.],
[0., 0., 0.],
[0., 0., 0.]]],
[[[0., 0., 0.],
[0., 0., 0.],
[0., 0., 0.]],
[[0., 0., 0.],
[0., 0., 0.],
[0., 0., 0.]]]])
>>> x['b'].shape
(2, 2, 3, 3)
3.3 改变多维数组的形状
(1)通过指定新维度来直接改变形状
copyto(dst, src, casting='same_kind', where=True)把一个数组复制到另一个数组上去,可能会有传播shape(a)等价于a.shapereshape(a, newshape, order='C')更改形状ravel(a, order='C')返回一个连续的拉伸的数组,等价于a.reshape(-1)ndarray.flat这是ndarray的一个属性,同样可以实现拉伸,返回的不是数组,而是一个numpy.flatiter对象,可以用[]进行索引ndarray.flatten(order='C')返回一个被拉伸之后的数组
>>> a
array([[1, 1, 1],
[1, 1, 1]])
>>> b = np.array([3, 3, 3])
>>> np.copyto(a, b)
>>> a
array([[3, 3, 3],
[3, 3, 3]])
>>> np.ravel([[1, 2, 3], [4, 5, 6]])
array([1, 2, 3, 4, 5, 6])
>>> a = np.array([[1, 2, 3], [4, 5, 6]])
>>> a
array([[1, 2, 3],
[4, 5, 6]])
>>> a.reshape(-1)
array([1, 2, 3, 4, 5, 6])
>>> np.reshape(a, -1)
array([1, 2, 3, 4, 5, 6])
>>> np.reshape(a, [3, 2])
array([[1, 2],
[3, 4],
[5, 6]])
>>> a
array([[1, 2, 3],
[4, 5, 6]])
>>> a.flat
<numpy.flatiter object at 0x0000022EC2B7F120>
>>> a.flat[0]
1
>>> a
array([[1, 2, 3],
[4, 5, 6]])
>>> a.flatten()
array([1, 2, 3, 4, 5, 6])
(2)通过转置来改变形状
ndarray.T这个已经提过,但是仅限于矩阵使用transpose(a, axes=None)高维张量的转置moveaxis(a, source, destination)把source维移到destination维上,其余都不变,size为[3, 4, 5]把0轴移到2轴就得到[4, 5, 3]rollaxis(a, axis, start=0)把axis轴移到start轴上,其余不变,[3, 4, 5]如果把2轴移到0轴上,就是[5, 3, 4] ??swapaxies(a, axis1, axis2)在内部交换多维数组a的两个轴
>>> a.shape
(1, 2, 3)
>>> np.transpose(a, [0, 2, 1]).shape
(1, 3, 2)
(3)通过直接改变维度(如压缩)来改变形状
squeeze(a, axis=None)压缩掉一个维度,那个维度的长度必须为1expand_dim(a, axis)扩充一个维度,和np.newaxis类似
>>> a.shape
(2, 1, 3)
>>> np.squeeze(a, axis=1).shape
(2, 3)
>>> np.expand_dims(a, axis=0).shape
(1, 2, 1, 3)
(2)拼接与合并
np.r_沿着第一个轴连接np.c_沿着第二个轴把多维数组进行拼接,注意这不是括号,因为不是函数或者方法
>>> np.r_[[1, 2, 3], 5, 6, np.array([7, 8])]
array([1, 2, 3, 5, 6, 7, 8])
>>> np.r_[[[1, 2], [2, 3]], [[3, 4], [5, 6]]]
array([[1, 2],
[2, 3],
[3, 4],
[5, 6]])
>>> np.c_[[1, 2, 3], [2, 3, 4]]
array([[1, 2],
[2, 3],
[3, 4]])
3.4 线性代数计算
一般都去用torch或者tensorflow了,所以这里一般没用到。
3.5 permutation
random.shuffle(x)原地随机打散元素random.permutation(x)返回一个打散的多维数组,如果是多维的,只作用于第一个轴
3.6 np.frompyfunc()
如何通过一个函数,来对ndarray的所有数据进行处理。比如:
mapping_dict = {"china": 1, "usa": 2}
arr = np.array(["china", "usa"])
func = np.frompyfunc(lambda x: mapping_dict[x], 1, 1)
func(arr)
'''
output:
array([1, 2], dtype=object)
'''
3.7 和其他工具包的转换
ndarray和python互转
ndarray.tolist()
np.array(list)
NumPy速查笔记(持续更新中)的更多相关文章
- Access增删改查 (持续更新中)
关于Access数据库(2003)的增删改查,其实和Sql大体差不多,但是还有很多不一样的地方.下面列几个容易犯的错误: 1.Access数据库的位置: conn = new OleDbConnec ...
- react-navigation 使用笔记 持续更新中
目录 基本使用(此处基本使用仅针对导航头部而言,不包含tabbar等) header怎么和app中通信呢? React-Navigation是目前React-Native官方推荐的导航组件,代替了原用 ...
- GOF 的23种JAVA常用设计模式 学习笔记 持续更新中。。。。
前言: 设计模式,前人总结下留给后人更好的设计程序,为我们的程序代码提供一种思想与认知,如何去更好的写出优雅的代码,23种设计模式,是时候需要掌握它了. 1.工厂模式 大白话:比如你需要一辆汽车,你无 ...
- 微信小程序练习笔记(更新中。。。)
微信小程序练习笔记 微信小程序的练习笔记,用来整理思路的,文档持续更新中... 案例一:实现行的删除和增加操作 test.js // 当我们在特定方法中创建对象或者定义变量给与初始值的时候,它是局部 ...
- Makefile速查笔记
Makefile速查笔记 Makefile中的几个调试方法 一. 使用 info/warning/error 增加调试信息 a. $(info "some text")打印 &qu ...
- BLE资料应用笔记 -- 持续更新
BLE资料应用笔记 -- 持续更新 BLE 应用笔记 小书匠 简而言之,蓝牙无处不在,易于使用,低耗能和低使用成本.'让我们'更深入地探索这些方面吧. 蓝牙无处不在-,您可以在几乎每一台电话.笔记本电 ...
- java字节码速查笔记
java字节码速查笔记 发表于 2018-01-27 | 阅读次数: 0 | 字数统计: | 阅读时长 ≍ 执行原理 java文件到通过编译器编译成java字节码文件(也就是.class文件) ...
- fastadmin 后台管理框架使用技巧(持续更新中)
fastadmin 后台管理框架使用技巧(持续更新中) FastAdmin是一款基于ThinkPHP5+Bootstrap的极速后台开发框架,具体介绍,请查看文档,文档地址为:https://doc. ...
- 痞子衡嵌入式:史上最强i.MX RT学习资源汇总(持续更新中...)
大家好,我是痞子衡,是正经搞技术的痞子.今天痞子衡给大家介绍的是i.MX RT学习资源. 类别 资源 简介 官方汇总 i.MXRT产品主页 恩智浦官方i.MXRT产品主页,最权威的资料都在这里,参考手 ...
随机推荐
- 我和ABP vNext 的故事
Abp VNext是Abp的.NET Core 版本,但它不仅仅只是代码重写了.Abp团队在过去多年社区和商业版本的反馈上做了很多的改进.包括性能.底层的框架设计,它融合了更多优雅的设计实践.不管你是 ...
- 【翻译】Scriban README 文本模板语言和.NET引擎
scriban Scriban是一种快速.强大.安全和轻量级的文本模板语言和.NET引擎,具有解析liquid模板的兼容模式 Github https://github.com/lunet-io/sc ...
- java 获取传入值的区间
/** * 获取值的区间 * * @param num 值 */ public static Map<String, Integer> getNumSection(Integer num) ...
- [jvm] -- 常用内存参数配置篇
新生代 ( Young ) 与老年代 ( Old ) 的比例的值为 1:2 ( 该值可以通过参数 –XX:NewRatio 来指定 ) Eden : from : to = 8 : 1 : 1 ( 可 ...
- [jvm] -- 类文件结构篇
类文件结构 结构图 魔数 头四个字节,作用是确定这个文件是否为一个能被虚拟机接收的 Class 文件. Class 文件版本 第五和第六是次版本号,第七和第八是主版本号. 高版本的 Java 虚拟机 ...
- web自动化 -- 切换 iframe
先看源码 switch_to_frame() frame() 具体用法
- PHP代码实现二分法查找
需求:定义一个函数接收一个数组对象和一个要查找的目标元素,函数要返回该目标元素在数组中的索引值,如果目标元素不存在数组中,那么返回-1表示. //折半查找法(二分法): 使用前提必需是有序的数组. / ...
- [Abp vNext 源码分析] - 23. 二进制大对象系统(BLOB)
一.简介 ABP vNext 在 v 2.9.x 版本当中添加了 BLOB 系统,主要用于存储大型二进制文件.ABP 抽象了一套通用的 BLOB 体系,开发人员在存储或读取二进制文件时,可以忽略具体实 ...
- 豆瓣 9.0 分的《Python学习知识手册》|百度网盘免费下载|
豆瓣 9.0 分的<Python学习知识手册>|百度网盘免费下载| 提取码:nuak 这是之前入门学习Python时候的学习资料,非常全面,从Python基础.到web开发.数据分析.机器 ...
- PHP simplexml_load_file() 函数
实例 转换 XML 文件为 SimpleXMLElement 对象,然后输出对象的键和元素: <?php高佣联盟 www.cgewang.com$xml=simplexml_load_file( ...