The Successor Representation: Its Computational Logic and Neural Substrates
郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布!

Received May 14, 2018; revised June 28, 2018; accepted July 5, 2018.
This work was supported by the National Institutes of Health (CRCNS R01-1207833), the Office of Naval Research (N000141712984), and the Alfred P. Sloan Research Fellowship. I thank Geoff Schoenbaum, Matt Gardner, Nathaniel Daw, Kim Stachenfeld, Matt Botvinick, Evan Russek, and Ida Momennejad for collaboration on these ideas.
The author declares no competing financial interests.
Correspondence should be addressed to Dr. Samuel J. Gershman, Department of Psychology, Harvard University, 52 Oxford Street, Room 295.05, Cambridge, MA 02138. E-mail: gershman@fas.harvard.edu.
DOI:10.1523/JNEUROSCI.0151-18.2018
Copyright©2018 the authors 0270-6474/18/387193-08$15.00/0
Abstract
强化学习是智能体学习预测长期未来奖励的过程。我们已经了解了很多关于大脑的强化学习算法,但是我们对这些算法所作用的状态和动作的表示形式知之甚少。一个有用的起点是,在给定其计算结构约束的情况下,询问我们希望大脑具有哪种表示形式。遵循此逻辑将导致产生后继表示形式的概念,该后继表示形式根据环境与其他状态之间的预测关系对状态进行编码。最近的行为和神经研究为后继表示形式提供了证据,而计算研究则探索了扩展原始思想的方法。本文回顾了这些方面的进展,并在一个更广泛的框架内对其进行了组织,以了解大脑如何在强化学习的效率和灵活性之间进行权衡取舍。
Key words: cognitive map; dopamine; hippocampus; reinforcement learning; reward
Introduction
强化学习是预测和最大化未来奖励的问题,这在一定程度上是困难的,因为可能的未来数量巨大,以至于无法穷举。在大学之间选择的潜在学生不能考虑她可能遵循的所有可能的职业道路。可以尝试从经验中学习,选择一所大学并探索其后果,但她可能做不到足够次数来找到最优的大学。她可以预先规划,在每个决策点从精神上选择最有前途的选项(“首先我要去城市大学,然后我要学习化学专业,然后我要去一家制药公司工作,等等。”),或者她可以从自己的目标(例如,变得富有,出名等等)开始进行反向规划。但是,如果您探索错误的道路,规划可能会出错(要是我主修计算机科学而不是化学!)。还有另一种方法是重新想象目标状态,不去规划到达目标的路径,而只考虑从特定起点完成目标的频率(例如,有多少名就读城市大学的学生继续成为药物化学家?)。如果她可以访问此类统计信息,则该准学生可以有效地确定最优大学。
如该示例所示,强化学习算法的成功关键取决于其对环境的表示形式。一种非常灵活的表示方法,例如,知道每个状态转换到其他状态的频率(例如,化学学位毕业后获得制药工作的可能性),可以非常准确,但计算起来很麻烦——规划需要大量的脑力劳动 。另一方面,非常僵化的表示形式(例如,根据过去的经验总结每所大学的良好程度的摘要)是有效的(不需要规划),但是如果环境变化(例如制药业崩溃)可能就没用了。预测性摘要统计量(例如,有多少学生作为化学家获得工作)在某些情况下既灵活又高效(例如,如果化学工资突然增加,则城市大学的学生知道获得化学家的工作将很有用)。
不同的表示形式显然具有不同的优点和缺点。计算模型可以帮助我们根据一般原理理解这些折衷,指导我们回答一个基本问题:什么使表示形式对强化学习有用?这个问题对于强化学习的神经科学研究是及时的,该研究发现了丰富且有时是不规则的算法和表示形式。这些发现中的一个教训是,强化学习不是一件事,而是多方面的事情。一套半分离的“系统”,每个系统都可以独立解决强化学习问题(Dolan and Dayan, 2013;Kool et al., 2018)。这些系统在计算效率和灵活性之间做出了不同的权衡(图1),如下一节所述。通过对折衷空间进行形式化,我们可以弄清楚是什么使给定的计算结构成为“良好”的表示形式。
在这个总体框架内,我们将关注于最近复兴的关于如何平衡效率和灵活性的想法,称为后继表示形式(SR; Dayan, 1993)。基本想法是构建环境的“预测图”,以总结环境状态之间的长期预测关系。我们将展示该预测图在用作强化学习的表示形式时,如何针对特定的计算结构(线性函数逼近)是最优的。最近的实验已经开始表明,SR可能构成用于强化学习的单独系统的一部分,这对我们如何理解海马体和多巴胺的功能具有影响。
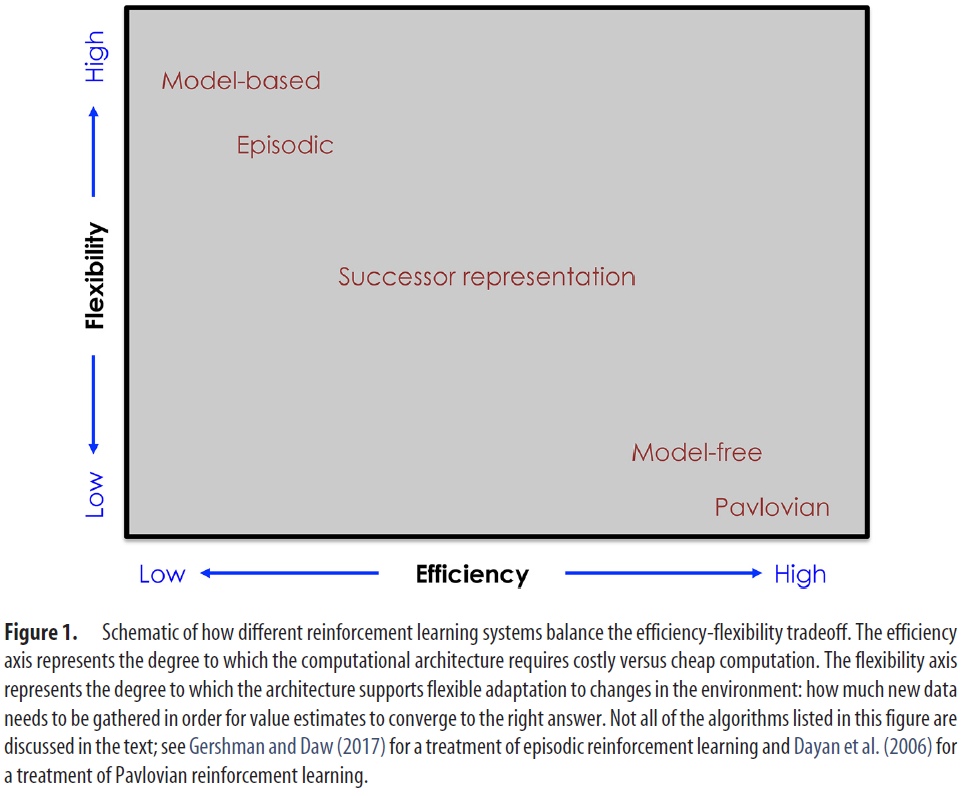
图1. 不同强化学习系统如何平衡效率-灵活性权衡的示意图。效率轴表示计算结构需要昂贵vs廉价计算的程度。灵活性轴表示结构支持对环境变化进行灵活适应的程度:需要收集多少新数据才能使价值估算收敛到正确答案。文本中并未讨论该图中列出的所有算法。见Gershman and Daw(2017)的episodic强化学习方法和Dayan et al.(2006)的巴甫洛夫强化学习方法。
An efficiency-flexibility tradeoff for reinforcement learning
强化学习与价值评估有关,价值评估是智能体期望在未来获得的总奖励,而短期奖励比长期奖励的权重更高。形式上,价值定义为期望折扣未来收益(Sutton and Barto, 1998):
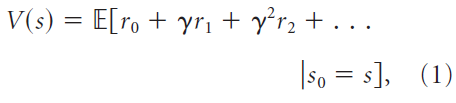
其中s表示环境状态,rt表示在时间 t 收到的奖励,并且γ是获取对近端奖励的偏好的折扣因子。期望E[·]表示状态转换和奖励中随机性的均值(即,转换和奖励可能是概率性的,导致经验性奖励序列中的随机性)。为了简化说明,我们选择省略动作,尽管我们的处理方法可以直接处理动作(Russek et al., 2017)。
为了使强化学习问题易于处理,通常会做出额外的假设,即转换和奖励由马尔可夫过程控制,这意味着奖励和状态转换仅取决于当前状态,而与先前的历史无关。形式上,这对应于以下假设:E[rt] = R(st)和P(st+1|st) = T(st, st+1),其中R称为奖励函数,T称为转换函数。在此假设下,可以得出易于处理的算法以进行价值函数估算,如Sutton and Barto(1998)所详细描述的。
有模型算法(例如价值迭代和蒙特卡洛树搜索)学习基础的“模型”(即奖励函数R和转换函数T),并使用该模型通过迭代计算来计算价值函数的估计值。例如,价值迭代反复迭代以下更新:
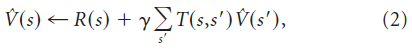
最终将收敛到真实价值函数。直观地,价值迭代从对价值函数的猜测开始,然后通过强制相邻状态的价值之间的一致性来迭代地完善此猜测。这种架构的计算量很大,因为每次模型更新时,价值估计都必须在整个状态空间上进行迭代。这种架构的优势在于它的灵活性:环境的局部更改导致模型的局部更改,因此,拥有模型的智能体仅需要少量经验即可适应此类更改。
有模型算法代表了计算效率和表示形式灵活性之间的一种折衷方案(图1)。另一个极端是无模型算法,例如时序差分学习,无需学习模型就可以直接从经历的转换和奖励中估计价值函数V。在最节省的计算结构中,估计价值函数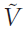 由存储每个状态的估计价值的查找表表示。但是,当状态数很大且经验稀疏时,查找表策略可能会失败。为了对状态进行某种推广,线性函数近似结构将价值分配为状态特征的加权组合(图2):
由存储每个状态的估计价值的查找表表示。但是,当状态数很大且经验稀疏时,查找表策略可能会失败。为了对状态进行某种推广,线性函数近似结构将价值分配为状态特征的加权组合(图2):
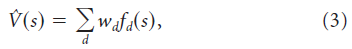
其中wd是特征d的权重,而fd(s)是特征d的激活。用于更新权重的时序差分学习规则采用以下形式:

其中,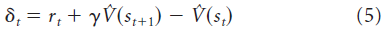 是时序差分误差。如果价值函数被高估,则δt将为负,因此活动特征的权重[fd(st) > 0]将减小;而如果价值函数被低估,则δt将为正,而活动特征的权重将增加。请注意,时序差分学习“bootstrap”其价值估计,使用一个估计来改进另一个估计。这在计算上是有效的,但也导致了灵活性:转换或奖励函数的局部变化将在价值函数中产生非局部变化,因此,只要环境变化,就需要通过时序差分更新来重新学习整个价值函数。在无模型的情况下,这就需要直接经历状态转换和奖励。
是时序差分误差。如果价值函数被高估,则δt将为负,因此活动特征的权重[fd(st) > 0]将减小;而如果价值函数被低估,则δt将为正,而活动特征的权重将增加。请注意,时序差分学习“bootstrap”其价值估计,使用一个估计来改进另一个估计。这在计算上是有效的,但也导致了灵活性:转换或奖励函数的局部变化将在价值函数中产生非局部变化,因此,只要环境变化,就需要通过时序差分更新来重新学习整个价值函数。在无模型的情况下,这就需要直接经历状态转换和奖励。
上述线性函数逼近架构已被广泛用于强化学习的神经模型中(Schultz et al., 1997;Daw and Touretzky, 2002;Ludvig et al., 2008;Gershman, 2017a),但是对于非线性的价值函数将失败。这促使某些模型采用非线性函数逼近架构(Schmajuk and DiCarlo, 1992;Mondragón, 2017),该策略在某些机器学习应用中被证明是成功的(Mnih et al., 2015)。即使使用非线性结构,无模型算法通常在计算上也比有模型的结构节俭。节俭的代价是不灵活:不同状态的价值耦合在一起,这意味着环境的局部更改将导致价值函数的非局部更改,因此,无模型智能体将不得不重新访问许多状态以进行更新它们的价值。函数逼近有时可以通过启用状态间的泛化来缓解此问题,但有时也可能通过混叠具有不同价值的状态而加剧该问题。
重要的是要认识到,函数近似结构的适当选择在很大程度上取决于表示的选择。例如,众所周知,线性结构无法解决“异或”问题(在动物学习文献中被称为“负模式”),例如,学习到我喜欢西兰花和冰淇淋但不喜欢西兰花冰淇淋时, 特征是基本特征(例如,西兰花1个特征和冰淇淋1个特征)。但是,添加编码西兰花冰淇淋的联合特征将允许线性结构解决该问题。更广泛地讲,许多机器学习算法试图通过将输入映射到新的特征空间中来解决复杂的非线性问题,在该特征空间中线性方法将很好地起作用(Schölkopf and Smola, 2002;Bengio, 2009)。这种观点也渗透到了计算神经科学领域,使我们对目标识别(DiCarlo and Cox, 2007)和运动控制(Sussillo and Abbott, 2009)有了更深入的了解。
我们也可以反过来问:对于给定的函数逼近架构选择,最优表示形式是什么?考虑到线性结构的分析易处理性,计算简单性和半生物学合理性,它们通常被视为一个合理的起点(Poggio and Bizzi, 2004)。这直接将我们引向了SR。

图2. 不同强化学习系统如何在具有三个状态(s1, s2, s3)的简单迷宫中计算价值的示意图。与每个状态相关联的奖励价值由R(s)表示,并且其价值估计由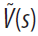 表示。转换概率由T(s, s')表示,后继表示形式由M(s, s')表示。该参数γ表示折扣因子。假设(出于说明目的)无模型价值函数估计是x和y空间坐标的线性函数,其中wx表示x坐标的权重。
表示。转换概率由T(s, s')表示,后继表示形式由M(s, s')表示。该参数γ表示折扣因子。假设(出于说明目的)无模型价值函数估计是x和y空间坐标的线性函数,其中wx表示x坐标的权重。
The computational logic of the successor representation
尽管上面我们在线性和非线性结构的相对优点之间进行了区分,但事实证明,任何价值函数都可以表示为“预测”特征的线性组合(Dayan, 1993):
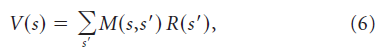
其中M(s, s')是SR,定义为状态s'的折扣性,是在状态s发起的轨迹上平均的结果。SR可以直观地看作是一种预测图,它根据不久将要访问的其他状态对每个状态进行编码。从线性函数近似结构可以准确表示价值函数的意义上说,这是“最优的”,前提是特征与SR相对应,即fd(s) = M(s, d),其中d是状态索引。
SR的定义类似于价值函数。SR不是累积奖励(如价值函数中那样),而是累积状态占用。学习算法之间也存在类比。在时序差分学习中,使用奖励预测误差(观察到的奖励与期望奖励之差)更新价值估计。还可以为SR导出时序差分学习算法,其中误差信号是观察到的状态占用与期望状态占用之差(Russek et al., 2017):
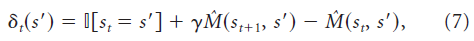
其中如果其论据为真,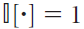 ,否则为0。直观地,该学习规则指出,应增加访问比期望频繁的状态期望占用(正预测误差),而应减少访问比期望较少的状态期望占用(负预测误差)。注意,与用于价值学习的时序差分误差不同,用于SR学习的时序差分误差是矢量价值的,每个后继状态都有一个误差。也有可能为SR定义一个线性函数逼近器,在这种情况下,每个特征都存在一个误差(Gardner et al., 2018)。
,否则为0。直观地,该学习规则指出,应增加访问比期望频繁的状态期望占用(正预测误差),而应减少访问比期望较少的状态期望占用(负预测误差)。注意,与用于价值学习的时序差分误差不同,用于SR学习的时序差分误差是矢量价值的,每个后继状态都有一个误差。也有可能为SR定义一个线性函数逼近器,在这种情况下,每个特征都存在一个误差(Gardner et al., 2018)。
就效率-灵活性的权衡而言,SR位于有模型算法和无模型算法之间。一方面,它的效率与具有线性函数逼近的无模型强化学习相当。另一方面,它具有有模型算法的某些灵活性,因为奖励函数已经超出了对未来轨迹的期望,因此奖励函数的变化将立即传播到所有状态价值。这意味着只有R(s)发生变化时,智能体无需平均状态即可更新V(s)。但是请注意,转换函数的变化并非如此:SR实际上是状态转换统计量的编译形式,与价值函数是奖励统计量的编译形式非常相似。正是这种汇编赋予了效率和灵活性。
接下来,我们转向行为和神经证据,即大脑计算SR并将其用于强化学习。
Behavioral evidence
动物和人类具有“目标定向”行为的能力,能够在追求目标时灵活地适应环境或内部状态的变化。例如,Adams(1982)研究表明,受过训练以按下蔗糖杠杆的大鼠随后在不存在杠杆的情况下将蔗糖与疾病分开配对(从而使蔗糖强化刺激贬值)后在灭绝测试中停止了杠杆按压。至关重要的是,大鼠在贬值处理后没有机会重新学习杠杆按压的价值,因此排除了行为的纯粹的无模型解释。同样,关于动物可以在没有直接强化的情况下学习的各种情况下的观察,例如潜伏学习(Tolman, 1948),很难与无模型学习相协调。相反,这些实验现象已被解释为有模型的控制的证据(Daw et al., 2005)。然而,事实证明,它们并不是对有模型的控制的强烈判断:它们可以通过基于SR的账户来解释(Russek et al., 2017)。
以潜伏学习为例,其中将动物无任何奖励地放在迷宫中几天,然后训练使其导航到迷宫中的奖励位置。最早的发现是Tolman(1948)首次报道的,如果动物在没有奖励的情况下被预先训练,它们在奖励阶段的学习速度就会更快。SR为这一发现提供了自然的解释(Russek et al., 2017),因为SR可以在预训练过程中学习而无需直接强化。然后,在训练阶段,奖励函数将更新并与SR组合以计算价值。重要的是,奖励函数(不同于价值函数)可以局部学习,因此可以更快地学习。
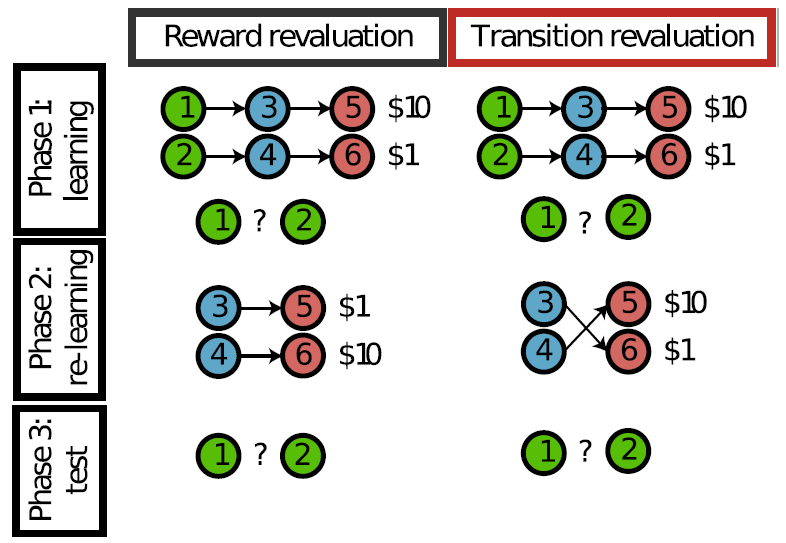
如前一部分所述,SR预测了行为灵活性的独特模式,其对奖励结构变化的敏感性高于对转换结构变化的敏感性。奖励结构变化会立即传播到这些价值,因为奖励预测是显式且局部表示的(即每个状态1个奖励预测)。相反,转换结构变化只会逐渐传播,因为SR丢弃了局部转换结构:这并不代表一个状态以某种概率跟随另一个状态的事实,而只是一个状态在未来的某个时候会比另一个状态更频繁地发生。这意味着,当转换结构更改时,必须重新学习整个SR。Momennejad et al.(2017)利用这一事实设计了一种高度判断性的测试,用于检验人类强化学习是否遵循基于SR的学习算法的预测(图3)。
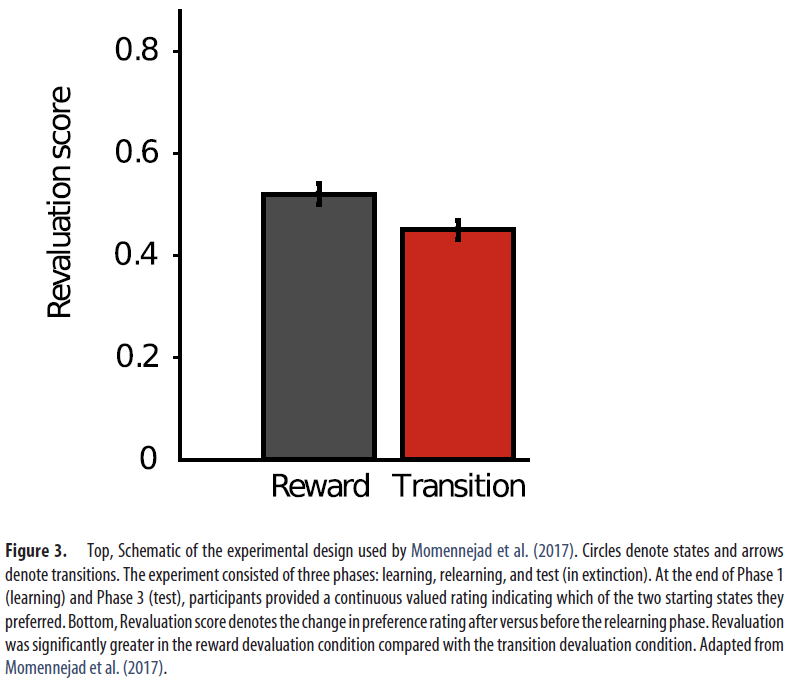
基本逻辑与用于研究啮齿动物(Dickinson, 1985)和人类(Valentin et al., 2007;Gershman et al., 2014)的行为的目标导向的贬值研究相同。在第一阶段,受试者首先学会了导致不同奖励量的两个状态链(具有不同的起始状态)。这种差异化的奖励是根据受试者对开始状态的偏好而注册的,从而导致了更多奖励的最终状态。在第二阶段,通过更改奖励结构(奖励贬值)或更改转换结构(转换贬值)来更改任务。两种形式的贬值都会改变初始状态的价值,从而使奖励最大化的智能体将扭转在第一阶段学到的偏好。至关重要的是,受试者仅经历了从每个链的中间状态开始的这些变化。这削弱了时序差分学习算法,该算法需要不间断的状态序列来学习正确的价值(但请参见Gershman et al., 2014)。在第三阶段,再次要求受试者在一种起始状态之间进行选择。重估是作为最后一个阶段与第一阶段之间的优先级差来衡量的(较高的价值表示重估较大)。
基于人类以时序差分更新规则学习SR的假设,Momennejad et al.(2017)预测并确认,与转换贬值条件相比,奖励贬值条件的重估将更大(即,受试者在奖励重估条件下更频繁地颠倒其偏好),尽管这两个更改对起始状态的价值都具有同等的影响。由于将价值函数解析为预测状态和奖励成分的方式,SR能够响应奖励变化而快速调整价值。但是,在使用时序差分学习进行更新的假设下,SR无法享受这种快速调整。然而,有趣的是,尽管SR的时序差分学习预测不应发生任何重估,但在转换贬值条件下,受试者还是能够表现出zero-shot重估。模型比较表明,受试者正在结合使用基于SR和有模型的策略,从而SR提供了对价值函数的初始估计,然后通过有模型的计算对其进行了完善。强化学习系统之间的这种“合作”相互作用已在许多实验中观察到,并以多种方式实现(有关综述,请参见Kool et al., 2018)。
Neural evidence
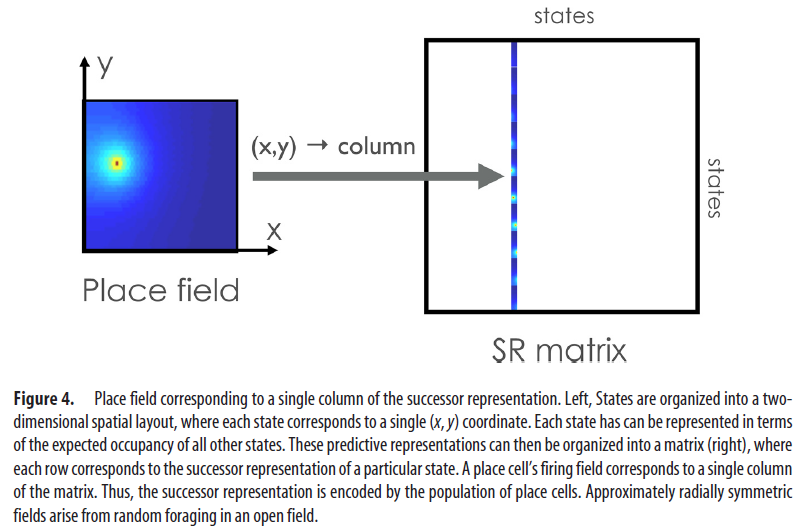
考虑一下在具有统一分布的奖励的开放领域中SR的外观(图4)。因为智能体同样喜欢沿任何方向移动,所以给定状态(对应于空间位置)的SR在空间上将是径向对称的,其宽度取决于折扣因子γ(价值越大的γ,转换成的宽度越大)。如果我们现在想象一个为每个状态编码这种空间功能的神经元集合,那么得到的群体代码将非常类似于在海马体中观察到的经典位置场(Stachenfeld et al., 2017)。
尽管在随机觅食的简单设置中SR看起来像是纯粹的空间代码,但它在更复杂的环境中具有更丰富的特性。例如,在野外添加不可逾越的障碍会导致SR在障碍周围扭曲(Stachenfeld et al., 2017),这与实验观察结果一致(Muller and Kubie, 1987;Skaggs and McNaughton, 1998;Alvernhe et al., 2011)。SR还可以解释为什么位置细胞在反复遍历的过程中变得与行进方向相反(Mehta et al., 2000)。随着在可靠的状态序列中学习了预测表示形式,即将出现的状态将变得可以提前预测。位置细胞对非空间因素也很敏感:位置场倾向于聚集在奖励位置周围(Hollup et al., 2001),这是在SR模型中出现的,因为动物倾向于更频繁地访问这些状态。人体大脑影像学研究概括了这些观察结果,表明海马体在预测表示形式中起着重要作用(Schapiro et al., 2016;Garvert et al., 2017)。
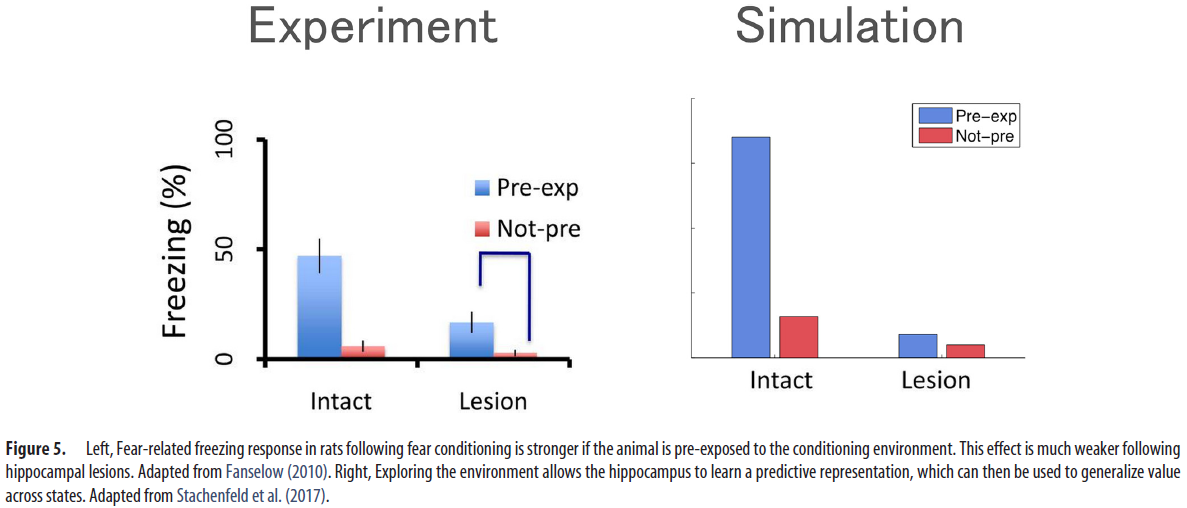
SR模型为这些神经观察和动物学习数据之间的桥梁。例如,情境恐惧调节文献中的一个众所周知的发现是预先暴露于情境的促进作用(Fanselow, 2010)。从SR的角度来看,这本质上是一种潜伏学习:动物发展出一种预测表示形式,然后可以用来将恐惧从调节设备中的一个位置推广到所有其他位置(图5)。重要的是,海马体病变会导致暴露前效应急剧下降,这与SR模型对该区域编码预测图的解释一致。
一个重要的问题涉及如何学习SR。如果我们要认真对待时序差分学习的故事,似乎需要的是传达状态(或感官特征)预测误差的矢量价值误差信号。最近的一项提议认为,中脑多巴胺神经元的阶段性发放提供了必要的误差信号(Gardner et al., 2018)。对于相位多巴胺的常规解释,这似乎是异质的,据此,发放率传达了时序差分误差以进行价值更新(等式5)。然而,最近的一些研究似乎与多巴胺的``纯奖励''解释相矛盾:(1)多巴胺神经元对感觉预测误差做出响应(Takahashi et al., 2017),(2)多巴胺瞬变对于由这些误差驱动的学习是必需的(Chang et al., 2017),以及(3)多巴胺瞬变对于学习刺激既足够且必要——刺激联想(Sharpe et al., 2017)。使用模拟,Gardner et al.(2018)表明,所有这些发现都可以在多巴胺发出SR的时序差分误差的假设下得到解释。
正如Brea et al.(2016)所展示的那样,除了时序差分学习框架之外,还可以使用生物学合理的可塑性规则来学习后继表示形式。尤其是,STDP会产生一种前瞻性编码形式,其中树突会学会预测未来的胞体脉冲。Brea et al.(2016)表明,这种前瞻性编码在数学上等同于SR,并且与许多神经生理学观察结果一致。例如,在猴子执行延迟的配对相关任务时,某些前额神经元在预期可预期的刺激时似乎会逐渐倾斜(Rainer et al., 1999)。
Conclusions and future directions
什么可以产生强化学习的一个良好表示形式?这个问题没有唯一的答案,因为表示形式的优劣取决于它所参与的计算结构。为了更好地理解这种相互作用,我们根据效率(计算成本)和灵活性(系统适应环境变化的速度)之间的折衷分析了不同的表示形式选择。大脑似乎利用了多个强化学习系统,这些学习系统在该空间中占据了不同的位置(Kool et al., 2018)。重要的是,效率的每一次提高都伴随着灵活性的降低(图1)。
对于线性函数逼近架构,我们证明了正确的表示形式是SR,从某种意义上来说,完美学习的SR可以进行精确的价值计算。SR在效率-灵活性空间中处于中间位置,其效率可与线性无模型方法相媲美,而灵活性可与有模型的方法相媲美。这种情况和其他计算属性导致最近对机器学习SR的兴趣重新兴起(Kulkarni et al., 2016;Barreto et al., 2017;Zhang et al., 2017)。
本文所审查的研究计划仍处于起步阶段,仍然存在许多问题。在这里,我们重点介绍其中一些问题。
首先,我们建议多巴胺传达用于更新SR的矢量价值信号(Gardner et al., 2018)。在这一点上这完全是推测性的,因为除了有限和间接的方式之外,没有人系统地研究过多巴胺信号是否是矢量价值的。多巴胺神经元的综合记录将有助于对该假设进行更具决定性的检验。
其次,SR不太可能是一个独立的强化学习系统。经验(Momennejad et al., 2017)和理论(Russek et al., 2017)的论据表明,它与有模型的计算和无模型的计算都相互作用。但是,这些交互的性质仍不清楚。一旦我们有了更加系统的计算到大脑结构的映射,我们就可以更好地解决这个问题。例如,Momennejad et al.(2017)提出的证据表明,有模型的计算会逐步完善基于SR的价值函数初始估计。如果这是真的,那么我们应该期望早日看到与SR相关的神经信号,然后再将其替换为有模型的神经信号。另一个可能性是,有模型的系统会规划到一定深度,然后使用SR来计算启发式价值函数(Keramati et al., 2016)。另一个可能性是,SR为有模型的规划提供了有效的搜索空间,可以使用吸引子动态来实现它(Corneil and Gerstner, 2015)。
第三,我们假设价值函数近似值(至少是与SR相接的近似值)是线性的。这是一个合理的假设吗?这个问题本质上很难回答,因为我们不知道如何直接分析神经电路使用的函数逼近架构。当然,大多数生物学上现实的神经回路都是非线性的,但问题是线性模型是否有用。随着我们了解有关强化学习的电路计算的更多信息,关于表示的假设可能会随之改变。
第四,我们假设大脑知道它处于什么状态,而且具有整个状态空间的某种表示形式。但是实际上,我们经常对基础状态有不确定性(状态推断问题),也可能对状态空间本身有不确定性(状态发现问题)。这些问题提出了在状态不确定的情况下如何考虑SR的问题。一些理论认为,大脑在感觉数据的条件下在隐含状态上形成后验分布(Daw et al., 2006;Gershman et al., 2010;Rao, 2010;Soto et al., 2014;Babayan et al., 2018;Starkweather et al., 2018),在这种情况下,需要在概率分布的连续空间上定义SR。尽管这在数学上是一个定义明确的问题,但这是一个悬而未决的问题,即大脑如何以计算上易于处理的方式实现这一目标。
第五,如果海马体编码SR,那么我们可以对重估实验中它对转换和奖励操作的响应做出预测(Momennejad et al., 2017)。具体来说,我们希望当奖励改变时,一旦动物的策略开始改变,海马体神经元的发放率就应该做出响应,因为动物只有在改变其策略时才会观察到状态占用的变化。相反,由于状态占用统计量的变化,转换变化应导致海马体神经元立即做出响应(在任何策略变化之前)。
最后,另外一条独立的研究线将SR联系到记忆中(Gershman, 2017b)。特别是,SR与条目-内容关联的数学模型密切相关(Gershman et al., 2012),而时序差分学习算法提供了一种思考如何更新这些关联的新方法(Smith et al., 2013;Manns et al., 2015)。目前,尚不清楚记忆和强化学习是否依赖于共同的神经底物,尽管对海马体的共同依赖表明这是一个合理的推测。
The Successor Representation: Its Computational Logic and Neural Substrates的更多相关文章
- AlexNet论文翻译-ImageNet Classification with Deep Convolutional Neural Networks
ImageNet Classification with Deep Convolutional Neural Networks 深度卷积神经网络的ImageNet分类 Alex Krizhevsky ...
- 中文版 ImageNet Classification with Deep Convolutional Neural Networks
ImageNet Classification with Deep Convolutional Neural Networks 摘要 我们训练了一个大型深度卷积神经网络来将ImageNet LSVRC ...
- Research Guide for Neural Architecture Search
Research Guide for Neural Architecture Search 2019-09-19 09:29:04 This blog is from: https://heartbe ...
- 课程一(Neural Networks and Deep Learning),第一周(Introduction to Deep Learning)—— 2、10个测验题
1.What does the analogy “AI is the new electricity” refer to? (B) A. Through the “smart grid”, AI i ...
- Neural Networks and Deep Learning
Neural Networks and Deep Learning This is the first course of the deep learning specialization at Co ...
- Research Guide: Pruning Techniques for Neural Networks
Research Guide: Pruning Techniques for Neural Networks 2019-11-15 20:16:54 Original: https://heartbe ...
- [译]深度神经网络的多任务学习概览(An Overview of Multi-task Learning in Deep Neural Networks)
译自:http://sebastianruder.com/multi-task/ 1. 前言 在机器学习中,我们通常关心优化某一特定指标,不管这个指标是一个标准值,还是企业KPI.为了达到这个目标,我 ...
- [Z] 计算机类会议期刊根据引用数排名
一位cornell的教授做的计算机类期刊会议依据Microsoft Research引用数的排名 link:http://www.cs.cornell.edu/andru/csconf.html Th ...
- CCF推荐国际学术期刊
中国计算机学会推荐国际学术期刊 (计算机系统与高性能计算) 一.A类 序号 刊物简称 刊物全称 出版社 网址 1 TOCS ACM Transactions on Computer Systems A ...
随机推荐
- pandas_数据排序
import pandas as pd # 设置列对齐 pd.set_option("display.unicode.ambiguous_as_wide",True) pd.set ...
- luogu P6224 [BJWC2014]数据 KD-tree 标准板子 重构+二维平面内最近最远距离查询
LINK:数据 这是一个我写过的最标准的板子. 重构什么的写的非常的标准 常数应该也算很小的. 不过虽然过了题 我也不知道代码是否真的无误 反正我已经眼查三遍了... 重构:建议先插入 插入过程中找到 ...
- luogu P3223 [HNOI2012]排队
LINK:排队\ 原谅我没学过组合数学 没有高中数学基础水平... 不过凭着隔板法的应用还是可以推出来的. 首先考虑女生 发现一个排列数m! 两个女生不能相邻 那么理论上来说存在无解的情况 而这道题好 ...
- Multiple dex files define解决记录
引用多个library时经常会遇到Multiple dex files define错误,最常见的是support库多次定义,此时可用以下gradle命令来查看工程的引用树: gradlew -q d ...
- Dynamics365 Field Service Work Order Theory
Come from :https://neilparkhurst.com/2016/08/20/field-service-work-order-theory/ In this post I aim ...
- asp.net core 2.1的全局模型验证统一方案
网上的统一模型验证,有效到asp.net core 2.0 2.1的mvc还可以用 webapi嘛,想想就好,自己琢磨了一顿,才发现这东西应该这样玩 首先吧api上面的特性注释了 //[ApiCont ...
- 【NOI2001】方程的解数 题解(dfs+哈希)
题目描述 已知一个方程 k1*x1^p1+k2*x2^p2……+kn*xn^pn=0. 求解的个数.其中1<=x<=150,1<=p<=6; 答案在int范围内 输入格式 第一 ...
- 修改当前项目maven仓库地址
pom.xml中修改 <repositories> <repository> <id>nexus-aliyun</id> <name>Nex ...
- Java语言特性
Java的语言特性: 1.语法相对简单 2.面向对象 3.分布性 4.可移植性 5.安全性 6.健壮性 7.解释性 8.多线程 9.动态性与并发性 Java中的面向对象编程: 面向对象程序设计(Obj ...
- “随手记”开发记录day13
今天继续对我们的项目进行更改. 今天我们需要做的是增加“修改”功能.对于已经添加的记账记录,长按可以进行修改和删除的操作. 但是今天并没有完成……