Federated Learning with Matched Averaging
挖个坑吧,督促自己仔细看一遍论文(ICLR 2020),看看自己什么时候也能中上那么一篇(流口水)~
郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布!

Abstract
联邦学习允许边缘设备协同学习共享模型,同时将训练数据保留在设备上,将模型训练能力与将数据存储在云中的需求分离开来。针对例如卷积神经网络(CNNs)和LSTMs等的现代神经网络结构的联邦学习问题,我们提出了联邦匹配平均(FedMA)算法。FedMA通过对提取到的具有相似特征的隐元素(即卷积层的通道;LSTM的隐状态;全连接层的神经元)进行匹配和平均,按层构建共享全局模型。我们的实验表明,FedMA训练的深度CNN和LSTM结构在实际数据集上优于流行的最新联邦学习算法,同时提高了通信效率。
1 INTRODUCTION
移动电话、传感器网络或车辆等边缘设备可以访问大量数据。然而,由于数据隐私、网络带宽限制和设备可用性等问题,将所有本地数据收集到数据中心并进行集中训练是不现实的。为了解决这些问题,联邦学习正在兴起(McMahan等人,2017年;Li等人,2019年;Smith等人,2017年;Caldas等人,2018年;Bonawitz等人,2019年),以允许本地用户合作训练共享的全局模型。
典型的联邦学习范式包括两个阶段:(i)客户机独立地在其数据集上训练模型(ii)数据中心上载其局部训练模型。然后,数据中心将接收到的模型聚合到一个共享的全局模型中。标准聚合方法之一是FedAvg(McMahan等人,2017年),其中局部模型的参数按元素平均,权重与客户端数据集的大小成比例。FedProx(Sahu等人,2018)为用户的局部损失函数添加了一个近端项,通过限制它们接近全局模型来限制局部更新的影响。不可知联邦学习(AFL)(Mohri et al.,2019)作为FedAvg的另一个变体,优化了由客户机分布混合而成的集中分布。
FedAvg算法的一个缺点是权值的坐标平均可能会对性能产生严重的不利影响,从而影响通信效率。这一问题是由于神经网络参数的排列不变性质而产生的,即对于任何给定的神经网络,它的许多变化只在参数的顺序上不同,构成了实际等价的局部最优。概率联邦神经匹配(PFNM)(Yurochkin等人,2019年)通过在对NNs的参数求平均值之前找到其参数的排列来解决这个问题。PFNM进一步利用贝叶斯非参数机制来调整全局模型大小以适应数据的异质性。结果表明,PFNM具有更好的性能和通信效率,但它只针对全连接NNs开发,并在简单的体系结构上进行了测试。
我们在这项工作中的贡献:(i)我们演示了PFNM如何应用于CNNs和LSTMs,但是我们发现,在应用于现代深度神经网络架构时,PFNM对加权平均的改善非常小;(ii)我们提出了联邦匹配平均(FedMA),以PFNM的匹配和模型大小自适应为基础,提出了一种新的面向现代CNNs和LSTMs的分层联邦学习算法;(iii)在联邦学习约束下,对真实数据集的FedMA进行了实证研究。
2 FEDERATED MATCHED AVERAGING OF NEURAL NETWORKS
在这一节中,我们将讨论著名神经网络结构类别的置换不变性,并在NNs的参数空间中建立适当的平均概念。我们将从单隐层全连接网络的最简单情况开始,接着是深层架构,最后是卷积架构和递归架构。

注:L是隐含层的节点数目,置换矩阵∏将W(1)的L列与W(2)的L行进行置换;对于异质数据集,我们应该找到对应的置换矩阵,进行匹配平均。
2.1 MATCHED AVERAGING FORMULATION

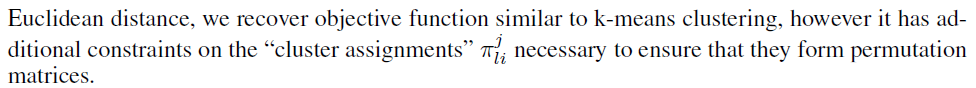
注:在数据集j的第l个神经元上,全局模型的神经元与其相似度的权值总和为1;全局模型的第i个神经元与数据集j的神经元相似度的权值总和为1;置换矩阵∏的逆为权值矩阵;若是数据集大小不平衡,可以参照FedAvg算法进行加权;将匹配平均根据(2)转化为最大二部匹配问题。

注:在每次迭代中,先根据给定的权值矩阵估计找到对应的全局模型,然后根据匈牙利算法将全局模型和数据集j'上的局部神经元进行匹配,得到新的拓展全局模型;由于数据异质性,局部模型j'可能存在部分神经元,它们不存在于由其他局部模型构成的全局模型中。因此,我们希望避免“差”匹配,即如果最优匹配的代价大于某个阈值,我们将从相应的局部神经元创建一个新的全局神经元而不是匹配。我们还需要一个中等大小的全局模型,因此用一些递增函数f(L')来惩罚它的大小。其中,全局模型大小记为L。

注:最终的L值即为上图式子中的L',对应于数据集j'上局部神经元成功匹配的全局模型神经元的最大序号(从1开始计数);当Lj与L不相等时,置换矩阵的作用是与其他数据集上学到的权重进行对齐,然后填充部分权重为0的哑神经元。最后平均过程中,哑神经元不算入计数。
2.2 PERMUTATION INVARIANCE OF KEY ARCHITECTURES
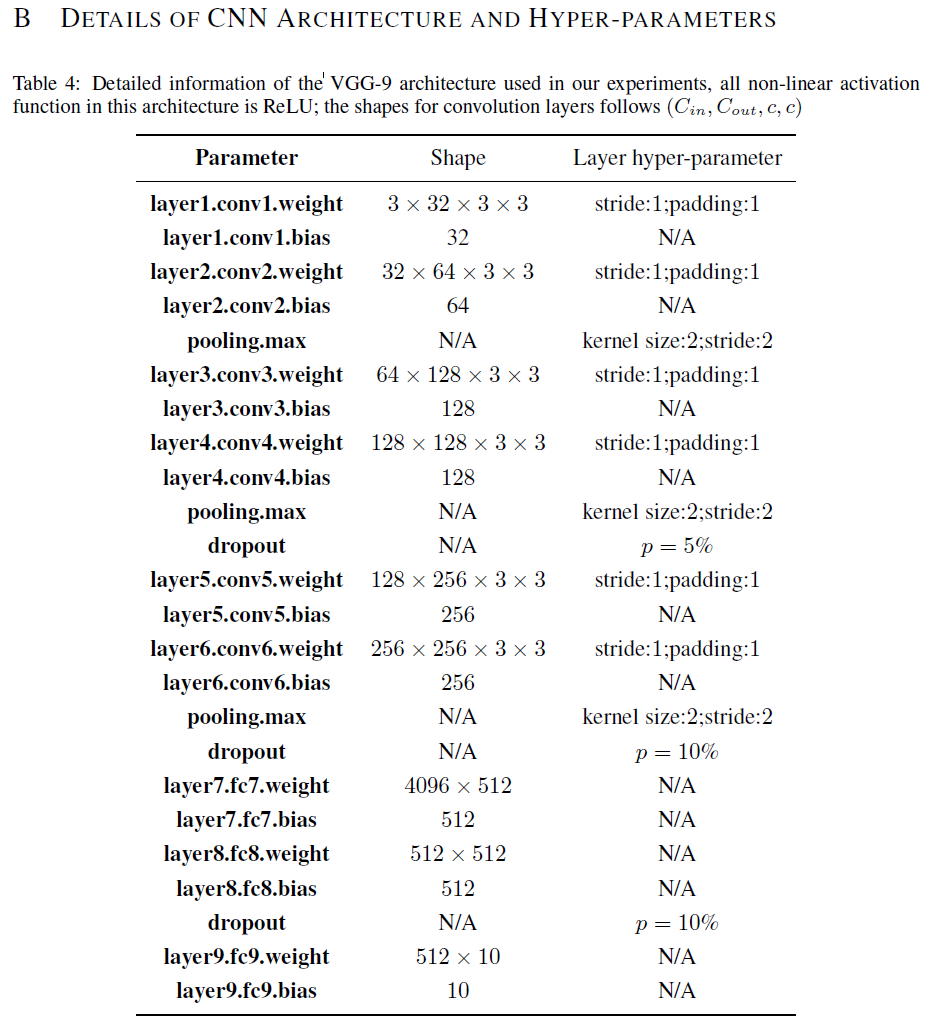
在讨论卷积和递归结构之前,我们讨论了深层全连接网络中的置换不变性和相应的匹配平均方法。我们将利用它作为处理LSTMs和CNN架构(如VGG (Simonyan&Zisserman,2014))的构建块,VGG在实践中广泛使用。

注:由于输出类相同,∏(N)恒等。任何连续的中间层对内的置换耦合导致一个NP难的组合优化问题,因此我们考虑递归(层内)匹配平均公式。



2.3 FEDERATED MATCHED AVERAGING (FEDMA) ALGORITHM
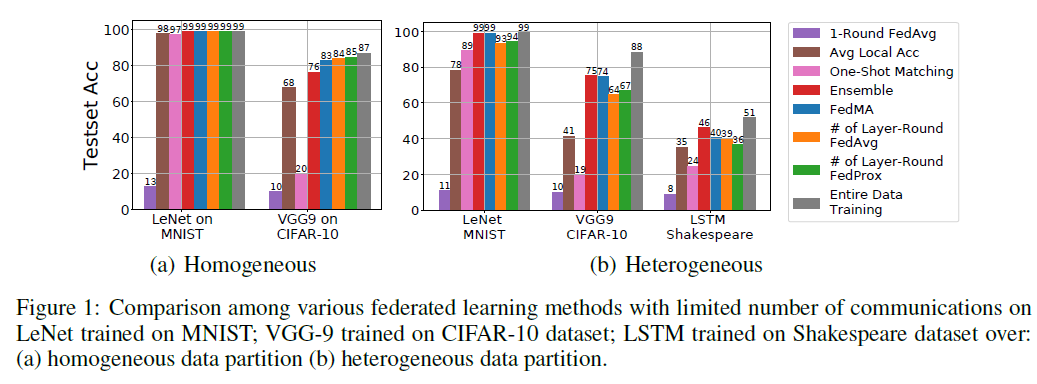
定义CNNs和LSTMs的类别置换不变性允许我们将PFNM(Yurochkin et al.,2019)扩展到这些结构,但是我们在图1中的实证研究(参见One-Shot Matching)表明,这种扩展在解决更复杂任务所需的深层结构上失败。我们的结果表明,对匹配平均层的递归处理可能导致较差的整体解决方案。为了缓解这一问题,并利用“浅层”架构上匹配平均的优势,我们提出以下分层匹配方案。首先,数据中心只从客户端收集第一层的权重,并执行前面描述的单层匹配以获取联邦模型的第一层权重。然后,数据中心将这些权重广播给客户机,客户机继续对其数据集上的所有连续层进行训练,并保持联邦匹配层处于冻结状态。接着,将此过程不断重复,直至最后一层。对最后一层,我们根据每个客户端数据点的类别比例对其进行加权平均。我们在算法1中总结了我们的联邦匹配平均(FedMA)。FedMA方法要求通信轮数等于网络中的层数。在图1中,我们展示了层匹配FedMA在更深的VGG-9 CNN和LSTM上的性能。在更具挑战性的异构环境中,FedMA优于相同通信轮次(LeNet和LSTM为4,VGG-9为9)训练的FedAvg、FedProx和其他基准,即客户端独立CNNs及其集成。
FedMA与通信:我们已经证明,在异构数据场景中,FedMA优于其他联邦学习方法,但是它在性能上仍然落后于完整数据训练。当然,在联邦学习的约束下,完整数据训练是不可能的,但它是我们应该努力达到的性能上限。为了进一步提高我们方法的性能,我们提出了带通信的FedMA,其中局部客户在新一轮开始时接收到匹配的全局模型,并在前一轮匹配结果的基础上重建与原始局部模型大小(例如VGG-9的大小)相等的局部模型。此过程允许将全局模型的大小保持在较小的范围内,而不是使用完全匹配的全局模型作为每轮客户机之间的起点的幼稚策略。

3 EXPERIMENTS
我们对带通信的FedMA进行了实证研究,并将其与最新方法进行比较,即FedAvg(McMahan等人,2017)和FedProx(Sahu等人,2018);分析了在客户数量不断增长的情况下的性能,并可视化了FedMA的匹配行为,以研究其可解释性。我们的实验研究是在三个真实世界的数据集上进行的。关于数据集和相关模型的摘要信息见补充表3。
实验设置:我们在PyTorch中实现了FedMA和所考虑的基准方法(Paszke等人,2017)。我们将我们的实证研究部署在一个模拟的联邦学习环境中,在这个环境中,我们将分布式集群中的一个集中式节点作为数据中心,其他节点作为本地客户端。我们实验中的所有节点都部署在Amazon EC2上的p3.2xlarge实例上。为了简化起见,我们假设数据中心对所有客户进行抽样,以加入每一轮通信的训练过程。
对于CIFAR-10数据集,我们使用数据增强(随机裁剪和翻转)并对每个单独的图像进行正则化(细节在补充中提供)。我们注意到,我们忽略了VGG架构中的所有批正则化处理(Ioffe & Szegedy,2015)层,并将其留给以后的工作。
对于CIFAR-10,我们考虑了两种数据划分策略来模拟联邦学习场景:(i)均匀划分,其中每个本地客户端具有每个类的大致相等的比例;(ii)数据点的数量和类比例不平衡的异构划分。我们通过采样pk∼DirJ(0.5)并将第k类训练实例以pk,j的比例分配给本地客户端j,模拟了一个异构划分为J个客户端的情况。我们使用CIFAR-10中的原始测试集作为我们的全局测试集,并在该测试集上进行了所有的精度测试。对于莎士比亚的数据集,因为根据Caldas等人(2018年)的说法,每部戏剧中的每个角色都被视为不同的客户,它具有内在的异质性。我们对Shakespeare数据集进行预处理,过滤掉数据点小于10k的客户端,最后得到132个客户端。我们选择训练集中80%的数据。然后,我们随机抽取132名客户中的J=66名进行实验。我们将客户机上的所有测试集合并,作为我们的全局测试集。
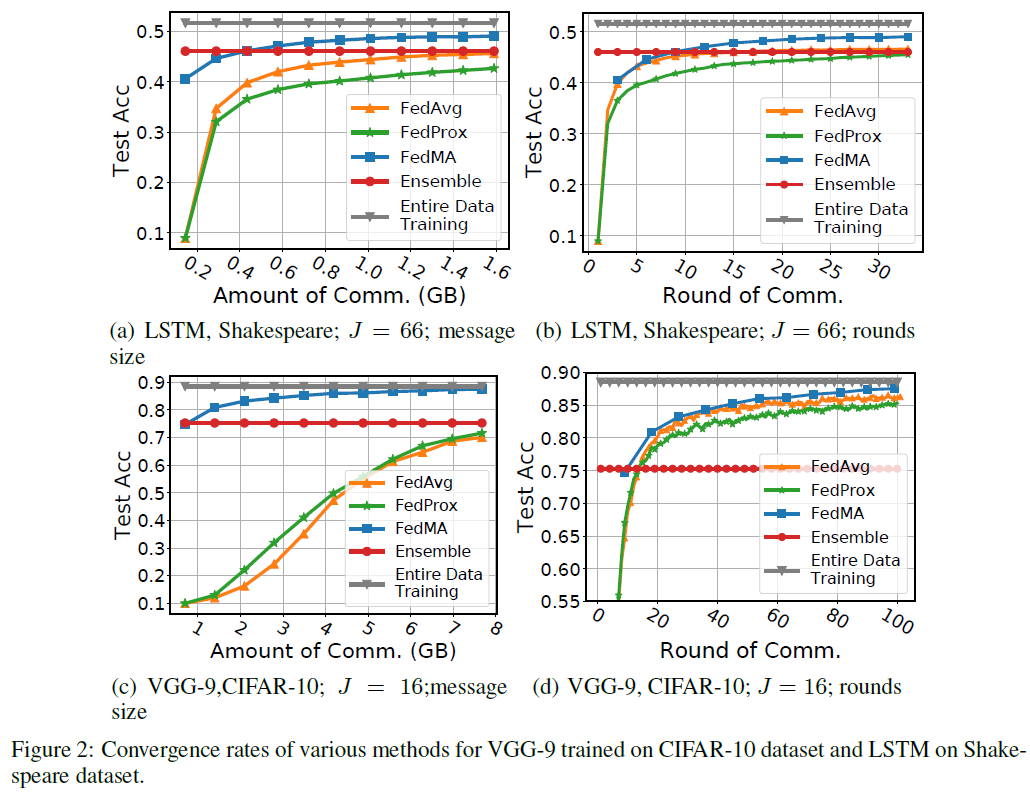
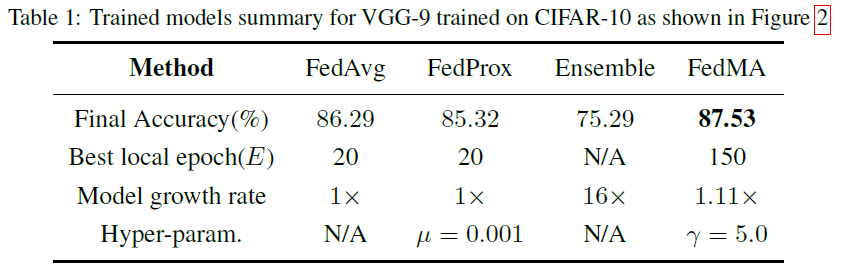
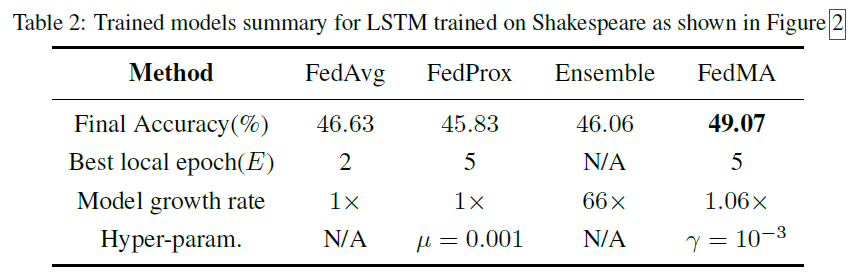
通信效率和收敛速度:在本实验中,我们研究了FedMA的通信效率和收敛速度。我们的目标是将我们的方法与FedAvg和FedProx进行比较,在数据中心和客户机之间交换的总消息大小(以千兆字节为单位)和全局模型实现良好性能所需的通信轮数(回想一下,完成一次FedMA过程需要的轮数等于局部模型中的层数)测试数据的性能。我们还比较了集成方法的性能。我们在具有VGG-9本地模型的J=16个客户机的CIFAR-10和具有1层LSTM网络的J=66个客户机的Shakespeare数据集上评估了异构联邦学习场景下的所有方法。我们确定了FedMA、FedAvg和FedProx允许的总通信轮数,即FedMA为11轮,FedAvg和FedProx为99/33轮,分别用于VGG-9/LSTM实验。我们注意到局部训练epoch是三种方法共有的参数,因此我们调整局部训练epoch(我们用E表示)(综合分析将在下一个实验中给出),并记录在最佳E值下的收敛速度,这个最佳E值对应全局测试集产生最佳的最终模型精度。我们还注意到FedProx中还有另一个超参数,即与代理项相关的系数μ,我们还使用网格搜索来调整参数,并记录我们发现的最佳μ值,即VGG-9和LSTM实验的0.001。FedMA在所有情况下都优于FedAvg和FedProx(图2),当我们在图2(a)和图2(c)中将收敛性作为消息大小的函数进行评估时,它的优势尤其明显。表1和表2总结了所有训练模型的最终性能。
局部训练epochs的影响:先前研究的局部训练epoch的影响(McMahan等人,2017年;Caldas等人,2018年;Sahu等人,2018年),局部训练epoch的数量可以影响FedAvg的性能,有时会导致发散。在异质条件下,我们研究了E在FedAvg、FedProx和FedMA上对CIFAR-10上训练的VGG-9的影响。我们考虑的候选局部epoch是E∈{10,20,50,70,100,150}。
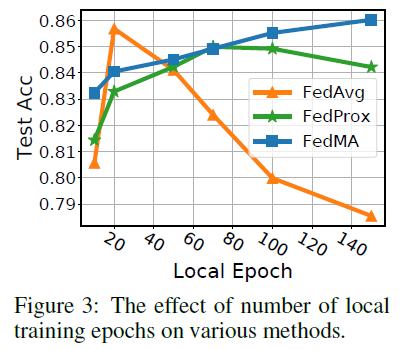
对于每个候选的E,我们运行FedMA 6轮,而FedAvg和FedProx为54轮,并记录每个方法所达到的最终精度。结果如图3所示。我们观察到训练时间越长,FedMA的收敛速度越快,这与我们假设的FedMA在质量较高的局部模型上返回更好的全局模型相吻合。对于FedAvg,较长的局部训练会导致最终精度下降,这与之前文献中的观察结果相符(McMahan et al.,2017;Caldas et al.,2018;Sahu et al.,2018)。FedProx在一定程度上防止了精度的下降,但最终模型的精度仍在下降。实验结果表明,FedMA是本地客户机可以用来训练模型的唯一方法。
处理数据偏差:现实世界中的数据往往在每一类中表现出多模性,例如地理多样性。已经证明,在广泛使用的ImageNet数据集中存在可观察到的美洲中心和欧洲中心偏差(Shankar等人,2017年;Russakovsky等人,2015年)。在这些数据上训练的分类器“学习”这些偏差,并且在表现不足的领域(模式)上表现不佳,因为相应的支配领域和类之间的相关性可以阻止分类器学习特征和类之间有意义的关系。例如,接受过美洲中心和欧洲中心数据训练的分类器可以学习将白色婚纱与“新娘”类相关联,因此在婚礼传统不同的国家拍摄的婚礼图像上表现不佳(Doshi,2018)。
数据偏差场景是联邦学习的一个重要方面,但是在以往的联邦学习工作中很少受到关注。在这项研究中,我们认为FedMA可以处理这类问题。如果我们将每个域(如地理区域)视为一个客户端,本地模型将不会受到聚合数据偏差的影响,并学习特征和类之间有意义的关系。然后可以使用FedMA来学习一个没有偏见的好的全局模型。我们已经展示了FedMA在跨客户机异构数据的联邦学习问题上的强大性能,这个场景非常类似。为了验证这一猜想,我们进行了以下实验。

利用CIFAR-10数据集,随机选取5个类,使其中95%的训练图像灰度化,模拟了领域迁移问题。对于剩下的5类,我们只将5%的相应图像转换为灰度。通过这样做,我们创建了5个以灰度图像为主的类和5个以彩色图像为主的类。在测试集中,每个类都有一半灰度图像和一半彩色图像。我们预计,完整数据训练将提取灰度和某些类之间的非信息相关性,这将导致没有这些相关性的测试性能较差。在图4中,我们看到,与常规(即无偏差)训练和测试相比,在没有任何灰度缩放的情况下,完整数据训练的性能较差。
接下来我们比较了基于联邦学习的方法。我们将图像从彩色主导类和灰度主导类分割为两个客户端。然后,我们对这两个客户机使用带通信的FedMA、FedAvg和FedProx。FedMA明显优于完整数据训练和其他联邦学习方法,如图4所示。这一结果表明了一个很有意思的事情,FedMA可能超越联邦学习约束下的学习,在联邦学习约束下,完整数据训练是性能的上限,但也可以通过消除数据偏差来优于完整数据训练。
我们考虑另外两种方法来消除无联邦学习约束的数据偏差。减轻数据偏差的一种方法是有选择地收集更多的数据来降低数据集偏差。在我们的实验中,这意味着为灰度主导类获得更多的彩色图像,为彩色主导类获得更多的灰度图像。我们通过简单地做一个完整数据训练来模拟这个场景,训练和测试图像中的每个类都有相同数量的灰度和彩色图像。这个过程,色彩平衡(Color Balanced),执行良好,但选择性收集新的数据在实践中可能是昂贵的,甚至不可能。与其收集新数据,不如考虑将可用数据过采样来降低偏差。在过采样中,我们对表示不足的领域进行采样(通过替换采样),以使每个类的彩色图像和灰度图像的比例相等(过采样的图像也通过数据增强,例如随机翻转和裁剪,以进一步增强数据多样性)。这种方法可能容易对过采样的图像进行过度拟合,我们发现,与有偏数据集上的集中训练相比,这种方法只提供了模型精度的边际提高,并且性能明显不如FedMA。
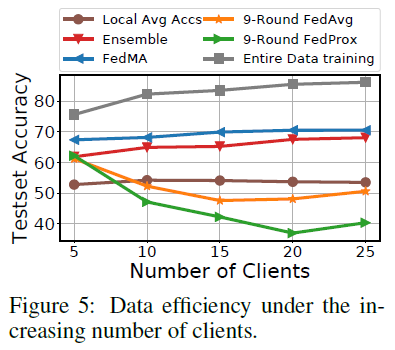
数据效率:众所周知,当有更多的训练数据可用时,深度学习模型表现得更好。然而,在联邦学习的约束下,数据效率并没有得到充分的研究。这里的挑战是,当新的客户机加入联邦系统时,它们各自都会带来自己的数据分布版本,如果处理不当,尽管客户机之间的数据量不断增加,但这可能会降低性能。为了模拟这个场景,我们首先将整个训练CIFAR-10数据集划分为5个同质的部分。然后我们把每个同质数据块进一步非均匀地分成5个子块。使用此策略,我们将CIFAR-10训练集划分为25个异质的小子数据集,每个子数据集包含大约2K个数据点。我们进行了一个5步实验研究:从随机选择的由5个相关的异质子块组成的同质块开始,我们模拟了一个5客户机的联邦学习异构问题。对于每个连续的步骤,我们添加一个剩余的同质数据块,其中包含5个具有异质子数据集的新客户端。结果如图5所示。在联邦学习系统中添加新的客户端时,FedMA(单轮)的性能提高,而FedAvg(9轮通信)的性能下降。

可解释性:FedMA的优点之一是它比FedAvg更有效地利用通信轮次。FedMA不是直接按元素平均权重,而是识别匹配的卷积滤波器组,然后将它们平均到全局卷积滤波器中。很自然地会问“匹配的过滤器看起来怎么样?”。在图6中,我们可视化了一对匹配的局部滤波器、聚合的全局滤波器和FedAvg方法在相同输入图像上返回的滤波器生成的表示。匹配滤波器和用FedMA找到的全局滤波器正在提取输入图像的相同特征,即客户端1的滤波器0和客户端2的滤波器23正在提取马腿的位置,而相应的匹配全局滤波器0也在提取相同位置。对于FedAvg,全局滤波器0是客户端1的滤波器0和客户端2的滤波器0的平均值,这明显篡改了客户端1的滤波器0的腿部提取功能。
4 CONCLUSION
本文提出了一种新的分层联邦学习算法FedMA,该算法利用概率匹配和模型大小自适应,适用于现代CNNs和LSTMs体系结构。通过实验验证了FedMA的收敛速度和通信效率。在未来,我们希望将FedMA扩展到寻找最优平均策略。此外,如何使FedMA支持更多的构建块,例如CNN和批正则化层中的剩余结构,也是后续的研究方向。

Federated Learning with Matched Averaging的更多相关文章
- 【流行前沿】联邦学习 Partial Model Averaging in Federated Learning: Performance Guarantees and Benefits
Sunwoo Lee, , Anit Kumar Sahu, Chaoyang He, and Salman Avestimehr. "Partial Model Averaging in ...
- 【流行前沿】联邦学习 Federated Learning with Only Positive Labels
核心问题:如果每个用户只有一类数据,如何进行联邦学习? Felix X. Yu, , Ankit Singh Rawat, Aditya Krishna Menon, and Sanjiv Kumar ...
- 【论文笔记】A Survey on Federated Learning: The Journey From Centralized to Distributed On-Site Learning and Beyond(综述)
A Survey on Federated Learning: The Journey From Centralized to Distributed On-Site Learning and Bey ...
- Local Model Poisoning Attacks to Byzantine-Robust Federated Learning
In federated learning, multiple client devices jointly learn a machine learning model: each client d ...
- 联邦学习(Federated Learning)
联邦学习简介 联邦学习(Federated Learning)是一种新兴的人工智能基础技术,在 2016 年由谷歌最先提出,原本用于解决安卓手机终端用户在本地更新模型的问题,其设计目标是 ...
- 联邦学习 Federated Learning 相关资料整理
本文链接:https://blog.csdn.net/Sinsa110/article/details/90697728代码微众银行+杨强教授团队的联邦学习FATE框架代码:https://githu ...
- Advances and Open Problems in Federated Learning
挖个大坑,等有空了再回来填.心心念念的大综述呀(吐血三升)! 郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布! 项目地址:https://github.com/open-intellige ...
- Federated Learning: Challenges, Methods, and Future Directions
郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布! arXiv:1908.07873v1 [cs.LG] 21 Aug 2019 Abstract 联邦学习包括通过远程设备或孤立的数据中心( ...
- Overcoming Forgetting in Federated Learning on Non-IID Data
郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布! 以下是对本文关键部分的摘抄翻译,详情请参见原文. NeurIPS 2019 Workshop on Federated Learning ...
随机推荐
- Spring学习之——手写Mini版Spring源码
前言 Sping的生态圈已经非常大了,很多时候对Spring的理解都是在会用的阶段,想要理解其设计思想却无从下手.前些天看了某某学院的关于Spring学习的相关视频,有几篇讲到手写Spring源码,感 ...
- MacOS下smartSVN使用教程
摘要: 本文介绍smartSVN使用教程,以及如何切换smartSVN的用户账号,如何显示远程服务器内容. 1.下载安装smartSVN 我共享一个我的百度云链接 链接:https://pan.bai ...
- PHP imagecolorclosestalpha - 取得与指定的颜色加透明度最接近的颜色的索引
imagecolorclosestalpha — 取得与指定的颜色加透明度最接近的颜色的索引.高佣联盟 www.cgewang.com 语法 int imagecolorclosestalpha ( ...
- 一本通 高手训练 1781 死亡之树 状态压缩dp
LINK:死亡之树 关于去重 还是有讲究的. 题目求本质不同的 具有k个叶子节点的树的个数 不能上矩阵树. 点数很少容易想到装压dp 考虑如何刻画树的形状 发现一个维度做不了 所以. 设状态 f[i] ...
- JS——变量提升和函数提升
一.引入 在了解这个知识点之前,我们先来看看下面的代码,控制台都会输出什么 var foo = 1; function bar() { if (!foo) { var foo = 10; } aler ...
- 比PS还好用!Python 20行代码批量抠图
你是否曾经想将某张照片中的人物抠出来,然后拼接到其他图片上去,从而可以即使你在天涯海角,我也可以到此一游? 很多人学习python,不知道从何学起.很多人学习python,掌握了基本语法过后,不知道在 ...
- U盘数据泄露,用不到30行的Python代码就能盗走
今天跟大家分享下一段简单的代码,希望能给经常用U盘的人警戒,提高信息安全意识. 很多人学习python,不知道从何学起.很多人学习python,掌握了基本语法过后,不知道在哪里寻找案例上手.很多已经做 ...
- canvas小画板——(2)荧光笔效果
我们在上一篇文章中讲了如何绘制平滑曲线 canvas小画板——(1)平滑曲线. 透明度实现荧光笔 现在我们需要加另外一种画笔效果,带透明度的荧光笔.那可能会觉得绘制画笔的时候加上透明度就可以了.我们来 ...
- java验证输入是否为三阶幻方
问题描述: 小明最近在教邻居家的小朋友小学奥数,而最近正好讲述到了三阶幻方这个部分,三阶幻方指的是将1~9不重复的填入一个3*3的矩阵当中,使得每一行.每一列和每一条对角线的和都是相同的. 三阶幻方又 ...
- Secure CRT连接VMware虚拟机中的CentOS 7
操作步骤: 1.安装Centos 7 虚拟机设置==>NetworkAdapter===>选择NAT(共享主机的IP地址), CTRL+ALT+F1切换到图形界面 选择右上角以太网打开 ...