solrcloud集群版的搭建
说在前面的话
之前我们了解到了solr的搭建,我们的solr是搭建在tomcat上面的,由于tomcat并不能过多的承受访问的压力,因此就带来了solrcloud的时代。也就是solr集群。
本次配置solrCloud需要的环境:
配置好的单机solr(更方便)
已安装jdk的linux服务器一台
下载链接
一、什么是SolrCloud
SolrCloud(solr 云)是Solr提供的分布式搜索方案,当你需要大规模,容错,分布式索引和检索能力时使用 SolrCloud。当一个系统的索引数据量少的时候是不需要使用SolrCloud的,当索引量很大,搜索请求并发很高,这时需要使用SolrCloud来满足这些需求。
SolrCloud是基于Solr和Zookeeper的分布式搜索方案,它的主要思想是使用Zookeeper作为集群的配置信息中心。
它有几个特色功能:
1)集中式的配置信息
2)自动容错
3)近实时搜索
4)查询时自动负载均衡

结构解析:
从物理结构上解析:
配置一个SolrCloud集群(实际上就是多个solr),图上是3个solr服务器,然后每个solr服务里面都有一个core(就是collection1(默认)、collection2、),我们用它去存放一部分数据(也就是把数据分片),此时我们不把它叫做collection,而叫做core,因为collection一般表示总的索引库。而我们在里面存放的是部分数据。因此为了不让我们概念混淆,起名为core,(在单机版因为一个collection就是i一个索引库,所以就很正常了)。三个solr服务,每个服务上有2个core,因此一共有6个core。
从逻辑结构解析:
一个大大的索引库,也就是一个大的collection。我们把其中的数据分成2片,分为起名为:shard1、shard2。其中的数据不同。每一个shard有三个core,这三个core实现了一主两备,数据都是一样的。充分的解决了高并发的问题
上图解析完了,那么我们再来看看词汇解释:
物理结构
三个Solr实例( 每个实例包括两个Core),组成一个SolrCloud。
逻辑结构
索引集合包括两个Shard(shard1和shard2),shard1和shard2分别由三个Core组成,其中一个Leader两个Replication,Leader是由zookeeper选举产生,zookeeper控制每个shard上三个Core的索引数据一致,解决高可用问题。
用户发起索引请求分别从shard1和shard2上获取,解决高并发问题。
collection
Collection在SolrCloud集群中是一个逻辑意义上的完整的索引结构。它常常被划分为一个或多个Shard(分片),它们使用相同的配置信息。
比如:针对商品信息搜索可以创建一个collection。
collection=shard1+shard2+…+shardX
Core
每个Core是Solr中一个独立运行单位,提供 索引和搜索服务。一个shard需要由一个Core或多个Core组成。由于collection由多个shard组成所以collection一般由多个core组成。
Master或Slave
Master是master-slave结构中的主结点(通常说主服务器),Slave是master-slave结构中的从结点(通常说从服务器或备服务器)。同一个Shard下master和slave存储的数据是一致的,这是为了达到高可用目的。
Shard
Collection的逻辑分片。每个Shard被化成一个或者多个replication,通过选举确定哪个是Leader。
看完上面的结构图了之后,自己的心中是不是有点收获呢,那么我们再来看看项目中的架构图吧。希望大家看图之后就能明白其中的原理

正如上面所说,我们不可能直接与solrcloud相连接,必须通过一个桥梁去管理他。这里我们用的是zookeeper,对于zookeeper,我们大家可能都不陌生了,因为我们在说dubbo的时候,zookeeper当时在dubbo作为注册中心,那时候我们就了解了一下他的搭建和应用。**这里我们主要是利用zookeeper管理我们solr的集群。**那时候我们用的是单机版,这里呢我们的solr服务都用集群版了,万一zookeeper挂了,那不也没用了么?因此我们这里把zookeeper也搭建成集群版。
估计小伙伴们都看出来了,此时我们需要7台服务器,4台服务器安装solr,3台安装zookeeper,充分的解决高并发的问题。
我们把索引库分成两片,然后每片对应着两台solr服务器。实现了一主一备。
二、搭建SolrCloud
正如小伙伴们看到需要7台服务器,可是我们没有7台服务器怎么办呢,有的小伙伴说用虚拟机。好,行我们用7台虚拟机,行了,那你搭建吧。我电脑配置不行,运行不了7台、、、
所以就搭建一台伪服务器,把所有的zookeeper和solr都搭建到一台服务器上,利用端口的不同进行通信连接。
a、搭建zookeeper集群
首先我们需要先搭建zookeeper集群,我们先把zookeeper上传到服务器上。
Zookeeper作为集群的管理工具。
1、集群管理:容错、负载均衡。
2、配置文件的集中管理
3、集群的入口
需要实现zookeeper 高可用。需要搭建集群。建议是奇数节点。需要三个zookeeper服务器。
因为zookeeper是利用投票选举的方式选择leader和
第一步:需要安装jdk环境。

第二步:把zookeeper的压缩包上传到服务器。
第三步:解压缩。
第四步:把zookeeper复制三份。
[root@localhost ~]# mkdir /usr/local/solr-cloud
[root@localhost ~]# cp -r zookeeper-3.4.6 /usr/local/solrcloud/zookeeper01
[root@localhost ~]# cp -r zookeeper-3.4.6 /usr/local/solrcloud/zookeeper02
[root@localhost ~]# cp -r zookeeper-3.4.6 /usr/local/solrcloud/zookeeper03

第五步:在每个zookeeper目录下创建一个data目录。
第六步:在data目录下创建一个myid文件,文件名就叫做“myid”。内容就是每个实例的id。例如1、2、3
[root@localhost data]# echo 1 >> myid
[root@localhost data]# ll
total 4
-rw-r–r--. 1 root root 2 Apr 7 18:23 myid
[root@localhost data]# cat myid

第七步:修改配置文件。把conf目录下的zoo_sample.cfg文件改名为zoo.cfg
1、datadir=你设置的myid所在的文件夹
2、端口号修改(伪分布式才需要改)
3、集群的ip地址
server.1=192.168.25.111:2881:3881
server.2=192.168.25.111:2882:3882
server.3=192.168.25.111:2883:3883
:2881代表投票发送信息的.
:3881代表投票接收信息的.
vim zoo.conf(1)2182,
vim zoo.conf(2)2183,
vim zoo.conf(3)2184,

…
第八步:启动每个zookeeper实例。
启动bin/zkServer.sh start
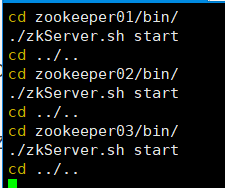
可以使用 批处理文件开启zookeeper
cd zookeeper01/bin/
./zkServer.sh start
cd ../..
cd zookeeper02/bin/
./zkServer.sh start
cd ../..
cd zookeeper03/bin/
./zkServer.sh start
cd ../..
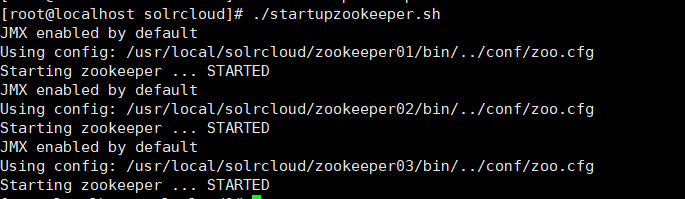
查看zookeeper的状态:
bin/zkServer.sh status

三、Solr集群的搭建
第一步:创建四个tomcat实例。每个tomcat运行在不同的端口。
配置tomcat的端口号8180、8280、8380、8480


启动端口 8081 8082 8083 8084
第二步:部署solr的war包。把单机版的solr工程复制到集群中的tomcat中。

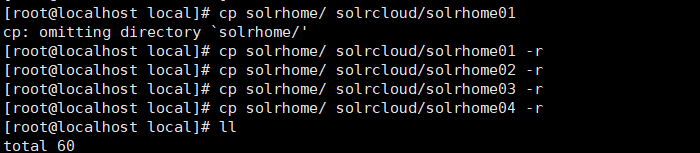
第三步:为每个solr实例创建一个对应的solrhome。使用单机版的solrhome复制四份。
第四步:需要修改solr的web.xml文件。把solrhome关联起来。


第五步:配置solrCloud相关的配置。每个solrhome下都有一个solr.xml,把其中的ip及端口号配置好。


第六步:修改tomcat/bin目录下的catalina.sh 文件,关联solr和zookeeper。
把此配置添加到配置文件中:
2182 8183 8184是zookeeper的配置文件zoo.conf里面配置的。表示连接zookeeper的端口号
JAVA_OPTS="-DzkHost=192.168.25.111:2182,192.168.25.111:2183,192.168.25.111:2184"


第七步:让zookeeper统一管理配置文件。需要把solrhome/collection1/conf目录上传到zookeeper。上传任意solrhome中的配置文件即可。
使用工具上传配置文件:/root/solr-4.10.3/example/scripts/cloud-scripts/zkcli.sh
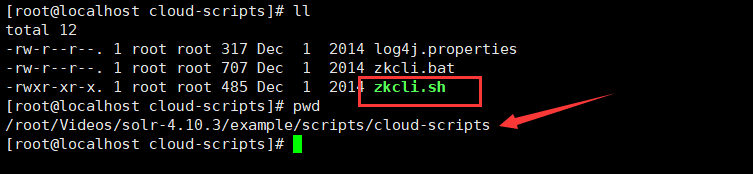
./zkcli.sh -zkhost 192.168.25.111:2182,192.168.25.111:2183,192.168.25.111:2184 -cmd upconfig -confdir /usr/local/solrcloud/solrhome01/collection1/conf -confname myconf

查看zookeeper上的配置文件:
使用zookeeper目录下的bin/zkCli.sh命令查看zookeeper上的配置文件:

[root@localhost bin]#
使用以下命令连接指定的zookeeper服务:
./zkCli.sh -server 192.168.25.111:2183


如上图,把solrhome中的collection1里的conf上传到zookeeper中了
第八步:启动每个tomcat实例。要包装zookeeper集群是启动状态。
使用批处理文件启动每一个tomcat实例。
cd tomcat8081/bin/
./startup.sh
cd ../..
cd tomcat8082/bin/
./startup.sh
cd ../..
cd tomcat8083/bin/
./startup.sh
cd ../..
cd tomcat8084/bin/
./startup.sh
cd ../..

第九步:访问集群
192.168.25.111:8081/solr

刚搭建好的collection索引库是一片,也就是一主三备

然后我们通过在浏览器上输入URL地址进行创建新的索引库(符合我们项目要求的.)
创建新的Collection进行分片处理。
http://192.168.25.111:8081/solr/admin/collections?action=CREATE&name=collection2&numShards=2&replicationFactor=2
删除不用的Collection。
http://192.168.25.111:8081/solr/admin/collections?action=DELETE&name=collection1
我们先把collection1删除,然后再添加新的索引库collection1.



到这里我们的solr集群版就搭建完成了.
本文讲解的很详细,希望可以给您带来不同之处,如果您有问题,欢迎下方评论,博主看到后会第一时间回复大家.
solrcloud集群版的搭建的更多相关文章
- 搭建集群版Eureka Server
注册中心作为微服务架构中的核心功能,其重要性不言而喻.所以单机版的Eureka Server在可靠性上并不符合现在的互联网开发环境.集群版的Eureka Server才是商业开发中的选择. Eurek ...
- JAVAEE——宜立方商城08:Zookeeper+SolrCloud集群搭建、搜索功能切换到集群版、Activemq消息队列搭建与使用
1. 学习计划 1.solr集群搭建 2.使用solrj管理solr集群 3.把搜索功能切换到集群版 4.添加商品同步索引库. a) Activemq b) 发送消息 c) 接收消息 2. 什么是So ...
- Redis单机版以及集群版的安装搭建以及使用
1,redis单机版 1.1 安装redis n 版本说明 本教程使用redis3.0版本.3.0版本主要增加了redis集群功能. 安装的前提条件: 需要安装gcc:yum install g ...
- solrcloud(solr集群版)安装与配置
1 Solr集群 1.1 什么是SolrCloud SolrCloud(solr 云)是Solr提供的分布式搜索方案,当你需要大规模,容错,分布式索引和检索能力时使用 SolrCloud.当一个系统的 ...
- SolrCloud集群搭建(基于zookeeper)
1. 环境准备 1.1 三台Linux机器,x64系统 1.2 jdk1.8 1.3 Solr5.5 2. 安装zookeeper集群 2.1 分别在三台机器上创建目录 mkdir /usr/hdp/ ...
- docker下搭建fastfds集群版
搭建过程参考 作者 https://me.csdn.net/feng_qi_1984 的课程视频 声明:集群版是在我之前写的单机版基础之上进行搭建的,我将安装了fastfds单机版的docker打包成 ...
- 11.SolrCloud集群环境搭建
转载请出自出处:http://www.cnblogs.com/hd3013779515/ 我们基于Solr4.10.3版本进行安装配置SolrCloud集群,通过实践来实现索引数据的分布存储和检索. ...
- ubuntu14.04环境下利用docker搭建solrCloud集群
在Ubuntu14.04操作系统的宿主机中,安装docker17.06.3,将宿主机的操作系统制作成docker基础镜像,之后使用自制的基础镜像在docker中启动3个容器,分配固定IP,再在3个容器 ...
- 快速搭建redis单机版和redis集群版
单机版 第一步:需要安装redis所需的C语言环境,若虚拟机联网,则执行 yum install gcc-c++ 第二步:redis的源码包上传到linux系统 第三步:解压缩redis tar ...
随机推荐
- OKHttp 官方文档【一】
最近工作比较忙,文章更新出现了延时.虽说写技术博客最初主要是写给自己,但随着文章越写越多,现在更多的是写给关注我技术文章的小伙伴们.最近一段时间没有更新文章,虽有工作生活孩子占用了大部分时间的原因,但 ...
- 正确的使用HttpClient
快捷的网络请求,多用HttpClient 但是常规的写法会一大片的TIME_OUT 比如这样的例子 static async Task<string> TestHttpClient(str ...
- 记一次TOMCAT一段时间自动关闭
最近同事开发的一个项目部署上线后用过几天就TOMCAT自动关闭,并且该项目没有开通对外访问.通过阿里云监控台查看,从升级后系统内存占用上升趋势,CPU等信息没有太大变化. 打印服务器日志后发现全是线程 ...
- Django 1.8.11 查询数据库返回JSON格式数据
Django 1.8.11 查询数据库返回JSON格式数据 和前端交互全部使用JSON,如何将数据库查询结果转换成JSON格式 环境 Win10 Python2.7 Django 1.8.11 返回多 ...
- Arm pwn学习
本文首发于“合天智汇”公众号 作者:s0xzOrln 声明:笔者初衷用于分享与普及网络知识,若读者因此作出任何危害网络安全行为后果自负,与合天智汇及原作者无关! 刚刚开始学习ARM pwn,下面如有错 ...
- 2020-04-11:A系统联机同步调用B系统(A和B不是同一公司系统,不能用分布式事务),如何保证系统间数据准实时一致性(设计思路即可)?提醒:需要考虑调用超时、并发、幂等、反交易先到等问题
福哥答案2020-04-12: 可参考微信支付和支付宝支付.
- C#LeetCode刷题之#225-用队列实现栈(Implement Stack using Queues)
问题 该文章的最新版本已迁移至个人博客[比特飞],单击链接 https://www.byteflying.com/archives/4106 访问. 使用队列实现栈的下列操作: push(x) -- ...
- Hexo博客中插入 Chart 动态图表
该文基本(全部)来自于chatjs中文文档 由于使用pjax,导致页面需要二次刷新才会显示表格,故引入了自动刷新的JS,但这样会导致回退标签失效 背景 今天在谷歌上逛博客时,突然发现shen-yu大佬 ...
- flask_restful实现文件下载功能
环境:前后端完全分离,后端flask_restful,前端vue from flask_restful import reqparse, Resource from flask import send ...
- Revit二次开发——非模态窗口的事件处理
一.起因 自己在写revit二开时,有一个Winform窗体按钮点击事件需要 触发调用事务进行处理,结果出现“异常“Starting a transaction from an external ...