谈谈Netty内存管理
前言
正是Netty的易用性和高性能成就了Netty,让其能够如此流行。
而作为一款通信框架,首当其冲的便是对IO性能的高要求。
不少读者都知道Netty底层通过使用Direct Memory,减少了内核态与系统态之间的内存拷贝,加快了IO速率。但是频繁的向系统申请Direct Memory,并在使用完成后释放本身就是一件影响性能的事情。为此,Netty内部实现了一套自己的内存管理机制,在申请时,Netty会一次性向操作系统申请较大的一块内存,然后再将大内存进行管理,按需拆分成小块分配。而释放时,Netty并不着急直接释放内存,而是将内存回收以待下次使用。
这套内存管理机制不仅可以管理Directory Memory,同样可以管理Heap Memory。
内存的终端消费者——ByteBuf
这里,我想向读者们强调一点,ByteBuf和内存其实是两个概念,要区分理解。
ByteBuf是一个对象,需要给他分配一块内存,它才能正常工作。
而内存可以通俗的理解成我们操作系统的内存,虽然申请到的内存也是需要依赖载体存储的:堆内存时,通过byte[], 而Direct内存,则是Nio的ByteBuffer(因此Java使用Direct Memory的能力是JDK中Nio包提供的)。
为什么要强调这两个概念,是因为Netty的内存池(或者称内存管理机制)涉及的是针对内存的分配和回收,而Netty的ByteBuf的回收则是另一种叫做对象池的技术(通过Recycler实现)。
虽然这两者总是伴随着一起使用,但这二者是独立的两套机制。可能存在着某次创建ByteBuf时,ByteBuf是回收使用的,而内存确实新向操作系统申请的。也可能存在某次创建ByteBuf时,ByteBuf是新创建的,而内存确实回收使用的。
因为对于一次创建过程而言,可以分成三个步骤:
- 获取ByteBuf实例(可能新建,也可能是之间缓存的)
- 向Netty内存管理机制申请内存(可能新向操作系统申请,也可能是之前回收的)
- 将申请到的内存分配给ByteBuf使用
本文只关注内存的管理机制,因此不会过多的对对象回收机制做解释。
Netty中内存管理的相关类
Netty中与内存管理相关的类有很多。框架内部提供了PoolArena,PoolChunkList,PoolChunk,Subpage等用来管理一块或一组内存。
而对外,提供了ByteBufAllocator供用户进行操作。
接下来,我们会先对这几个类做一定程度的介绍,在通过ByteBufAllocator了解内存分配和回收的流程。
为了篇幅和可读性考虑,本文不会涉及到大量很详细的代码说明,而主要是通过图辅之必要的代码进行介绍。
针对代码的注解,可以见我GitHub上的netty项目。
PoolChunck——Netty向OS申请的最小内存
上文已经介绍了,为了减少频繁的向操作系统申请内存的情况,Netty会一次性申请一块较大的内存。而后对这块内存进行管理,每次按需将其中的一部分分配给内存使用者(即ByteBuf)。这里的内存就是PoolChunk,其大小由ChunkSize决定(默认为16M,即一次向OS申请16M的内存)。
Page——PoolChunck所管理的最小内存单位
PoolChunk所能管理的最小内存叫做Page,大小由PageSize(默认为8K),即一次向PoolChunk申请的内存都要以Page为单位(一个或多个Page)。
当需要由PoolChunk分配内存时,PoolChunk会查看通过内部记录的信息找出满足此次内存分配的Page的位置,分配给使用者。
PoolChunck如何管理Page
我们已经知道PoolChunk内部会以Page为单位组织内存,同样以Page为单位分配内存。
那么PoolChunk要如何管理才能兼顾分配效率(指尽可能快的找出可分配的内存且保证此次分配的内存是连续的)和使用效率(尽可能少的避免内存浪费,做到物尽其用)的?
Netty采用了Jemalloc的想法。
首先PoolChunk通过一个完全二叉树来组织内部的内存。以默认的ChunkSize为16M, PageSize为8K为例,一个PoolChunk可以划分成2048个Page。将这2048个Page看作是叶子节点的宽度,可以得到一棵深度为11的树(2^11=2048)。
我们让每个叶子节点管理一个Page,那么其父节点管理的内存即为两个Page(其父节点有左右两个叶子节点),以此类推,树的根节点管理了这个PoolChunk所有的Page(因为所有的叶子结点都是其子节点),而树中某个节点所管理的内存大小即是以该节点作为根的子树所包含的叶子节点管理的全部Page。
这样做的好处就是当你需要内存时,很快可以找到从何处分配内存(你只需要从上往下找到所管理的内存为你需要的内存的节点,然后将该节点所管理的内存分配出去即可),并且所分配的内存还是连续的(只要保证相邻叶子节点对应的Page是连续的即可)。
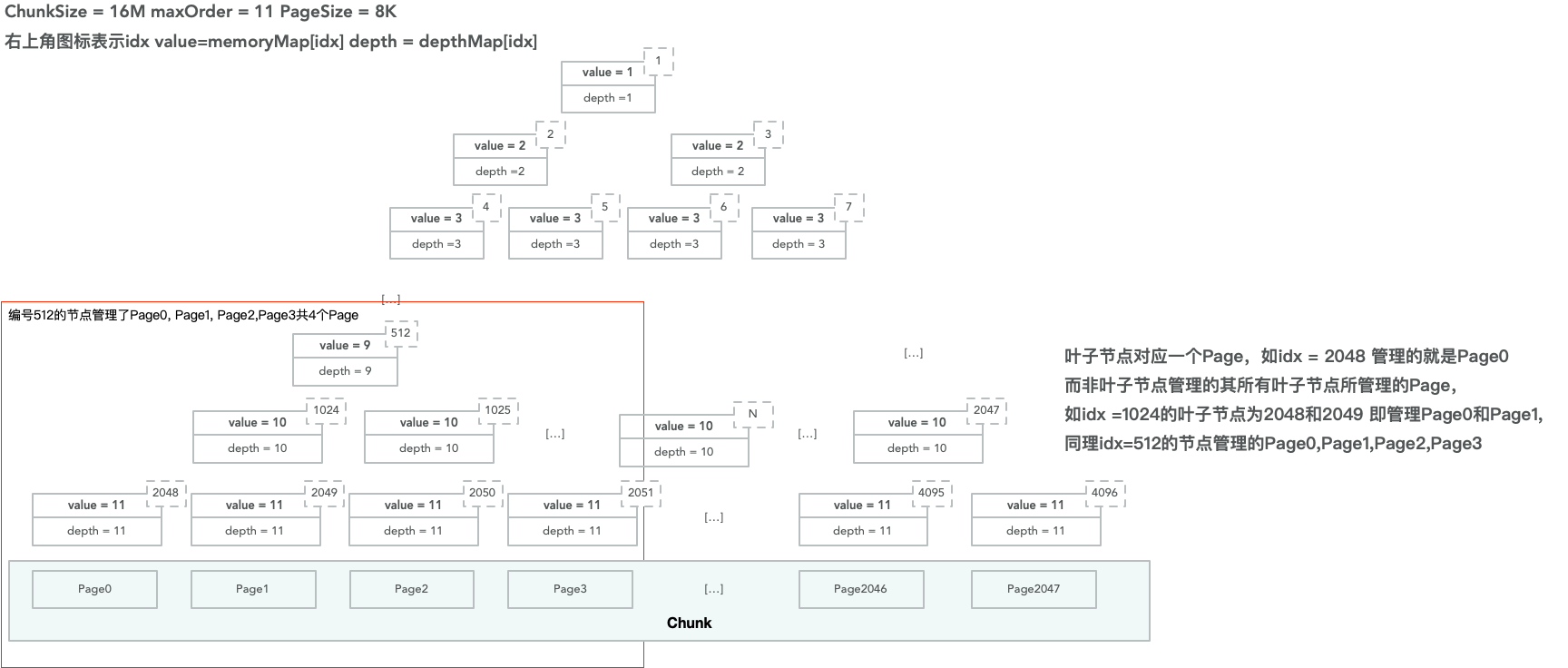
上图中编号为512的节点管理了4个Page,为Page0, Page1, Page2, Page3(因为其下面有四个叶子节点2048,2049,2050, 2051)。
而编号为1024的节点管理了2个Page,为Page0和Page1(其对应的叶子节点为Page0和Page1)。
当需要分配32K的内存时,只需要将编号512的节点分配出去即可(512分配出去后会默认其下所有子节点都不能分配)。而当需要分配16K的内存时,只需要将编号1024的节点分配出去即可(统计,一旦1024被分配,下面的2048和2049都不允许再被分配)。
了解了PoolChunk内部的内存管理机制后,读者可能会产生几个问题:
- PoolChunk内部如何标记某个节点已经被分配?
- 当某个节点被分配后,其父节点所能分配的内存如何更新?即一旦节点2048被分配后,当你再需要16K的内存时,就不能从节点1024分配,因为现在节点1024可用的内存仅有8K。
为了解决以上这两点问题,PoolChunk都是内部维护了的byte[] memeoryMap和byte[] depthMap两个变量。
这两个数组的长度是相同的,长度等于树的节点数+1。因为它们把根节点放在了idx + 1的位置上。而数组中父节点与子节点的位置关系为:
假设parnet的下标为i,则子节点的下标为2i和2i+1
用数组表示一颗二叉树,你们是不是想到了堆这个数据结构。
已经知道了两个数组都是表示二叉树,且数组中的每个元素可以看成二叉树的节点。那么再来看看元素的值分别代码什么意思。
对于depthMap而言,该值就代表该节点所处的树的层数。例如:depthMap[1] == 1,因为它是根节点,而depthMap[2] = depthMap[3] = 2,表示这两个节点均在第二层。由于树一旦确定后,结构就不在发生改变,因为depthMap在初始化后,各元素的值也就不发生变化了。
而对于memoryMap而言,其值表示该节点下可用于完整内存分配的最小层数(或者说最靠近根节点的层数)。
这话理解起来可能有点别扭,还是用上文的例子为例 。
首先在内存都未分配的情况下,每个节点所能分配的内存大小就是该层最初始的状态(即memoryMap的初始状态和depthMap的一致的)。而一旦其有个子节点被分配出后去,父节点所能分配的完整内存(完整内存是指该节点所管理的连续的内存块,而非该节点剩余的内存大小)就减小了(内存的分配和回收会修改关联的mermoryMap中相关节点的值)。
譬如,节点2048被分配后,那么对于节点1024来说,能完整分配的内存(原先为16K)就已经和编号2049节点(其右子节点)相同(减为了8K),换句话说节点1024的能力已经退化到了2049节点所在的层节点所拥有的能力。
这一退化可能会影响所有的父节点。
而此时,512节点能分配的完整内存是16K,而非24K(因为内存分配都是按2的幂进行分配,尽管一个消费者真实需要的内存可能是21K,但是Netty的内存管理机制会直接分配32K的内存)。
但是这并不是说节点512管理的另一个8K内存就浪费了,8K内存还可以用来在申请内存为8K的时候分配。
用图片演示PoolChunk内存分配的过程。其中value表示该节点在memoeryMap的值,而depth表示该节点在depthMap的值。
第一次内存分配,申请者实际需要6K的内存:
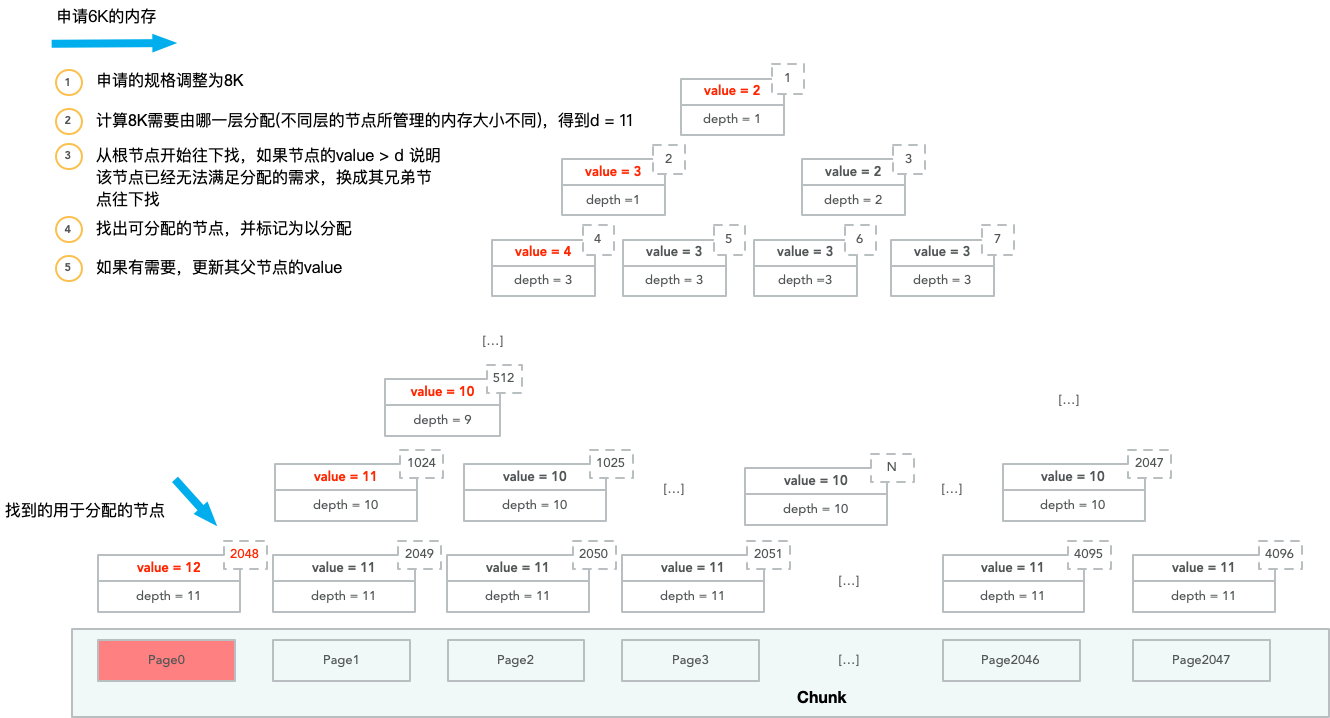
这次分配造成的后果是其所有父节点的memoryMap的值都往下加了一层。
之后申请者需要申请12K的内存:

由于节点1024已经无法分配所需的内存,而节点512还能够分配,因此节点512让其右节点再尝试。
上述介绍的是内存分配的过程,而内存回收的过程就是上述过程的逆过程——回收后将对应节点的memoryMap的值修改回去。这里不过多介绍。
PoolChunkList——对PoolChunk的管理
PoolChunkList内部有一个PoolChunk组成的链表。通常一个PoolChunkList中的所有PoolChunk使用率(已分配内存/ChunkSize)都在相同的范围内。
每个PoolChunkList有自己的最小使用率或者最大使用率的范围,PoolChunkList与PoolChunkList之间又会形成链表,并且使用率范围小的PoolChunkList会在链表中更加靠前。
而随着PoolChunk的内存分配和使用,其使用率发生变化后,PoolChunk会在PoolChunkList的链表中,前后调整,移动到合适范围的PoolChunkList内。
这样做的好处是,使用率的小的PoolChunk可以先被用于内存分配,从而维持PoolChunk的利用率都在一个较高的水平,避免内存浪费。
PoolSubpage——小内存的管理者
PoolChunk管理的最小内存是一个Page(默认8K),而当我们需要的内存比较小时,直接分配一个Page无疑会造成内存浪费。
PoolSubPage就是用来管理这类细小内存的管理者。
小内存是指小于一个Page的内存,可以分为Tiny和Smalll,Tiny是小于512B的内存,而Small则是512到4096B的内存。如果内存块大于等于一个Page,称之为Normal,而大于一个Chunk的内存块称之为Huge。
而Tiny和Small内部又会按具体内存的大小进行细分。
对Tiny而言,会分成16,32,48...496(以16的倍数递增),共31种情况。
对Small而言,会分成512,1024,2048,4096四种情况。
PoolSubpage会先向PoolChunk申请一个Page的内存,然后将这个page按规格划分成相等的若干个内存块(一个PoolSubpage仅会管理一种规格的内存块,例如仅管理16B,就将一个Page的内存分成512个16B大小的内存块)。
每个PoolSubpage仅会选一种规格的内存管理,因此处理相同规格的PoolSubpage往往是通过链表的方式组织在一起,不同的规格则分开存放在不同的地方。
并且总是管理一个规格的特性,让PoolSubpage在内存管理时不需要使用PoolChunk的完全二叉树方式来管理内存(例如,管理16B的PoolSubpage只需要考虑分配16B的内存,当申请32B的内存时,必须交给管理32B的内存来处理),仅用 long[] bitmap (可以看成是位数组)来记录所管理的内存块中哪些已经被分配(第几位就表示第几个内存块)。
实现方式要简单很多。
PoolArena——内存管理的统筹者
PoolArena是内存管理的统筹者。
它内部有一个PoolChunkList组成的链表(上文已经介绍过了,链表是按PoolChunkList所管理的使用率划分)。
此外,它还有两个PoolSubpage的数组,PoolSubpage[] tinySubpagePools 和 PoolSubpage[] smallSubpagePools。
默认情况下,tinySubpagePools的长度为31,即存放16,32,48...496这31种规格的PoolSubpage(不同规格的PoolSubpage存放在对应的数组下标中,相同规格的PoolSubpage在同一个数组下标中形成链表)。
同理,默认情况下,smallSubpagePools的长度为4,存放512,1024,2048,4096这四种规格的PoolSubpage。
PoolArena会根据所申请的内存大小决定是找PoolChunk还是找对应规格的PoolSubpage来分配。
值得注意的是,PoolArena在分配内存时,是会存在竞争的,因此在关键的地方,PoolArena会通过sychronize来保证线程的安全。
Netty对这种竞争做了一定程度的优化,它会分配多个PoolArena,让线程尽量使用不同的PoolArena,减少出现竞争的情况。
PoolThreadCache——线程本地缓存,减少内存分配时的竞争
PoolArena免不了产生竞争,Netty除了创建多个PoolArena减少竞争外,还让线程在释放内存时缓存已经申请过的内存,而不立即归还给PoolArena。
缓存的内存被存放在PoolThreadCache内,它是一个线程本地变量,因此是线程安全的,对它的访问也不需要上锁。
PoolThreadCache内部是由MemeoryRegionCache的缓存池(数组),同样按等级可以分为Tiny,Small和Normal(并不缓存Huge,因为Huge效益不高)。
其中Tiny和Small这两个等级下的划分方式和PoolSubpage的划分方式相同,而Normal因为组合太多,会有一个参数控制缓存哪些规格(例如,一个Page, 两个Page和四个Page等...),不在Normal缓存规格内的内存块讲不会被缓存,直接还给PoolArena。
再看MemoryRegionCache, 它内部是一个队列,同一队列内的所有节点可以看成是该线程使用过的同一规格的内存块。同时,它还有个size属性控制队列过长(队列满后,将不在缓存该规格的内存块,而是直接还给PoolArena)。
当线程需要内存时,会先从自己的PoolThreadCache中找对应等级的缓存池(对应的数组)。然后再从数组中找出对应规格的MemoryRegionCache。最后从其队列中取出内存块进行分配。
Netty内存机构总览和PooledByteBufAllocator申请内存步骤
在了解了上述这么多概念后,通过一张图给读者加深下印象。
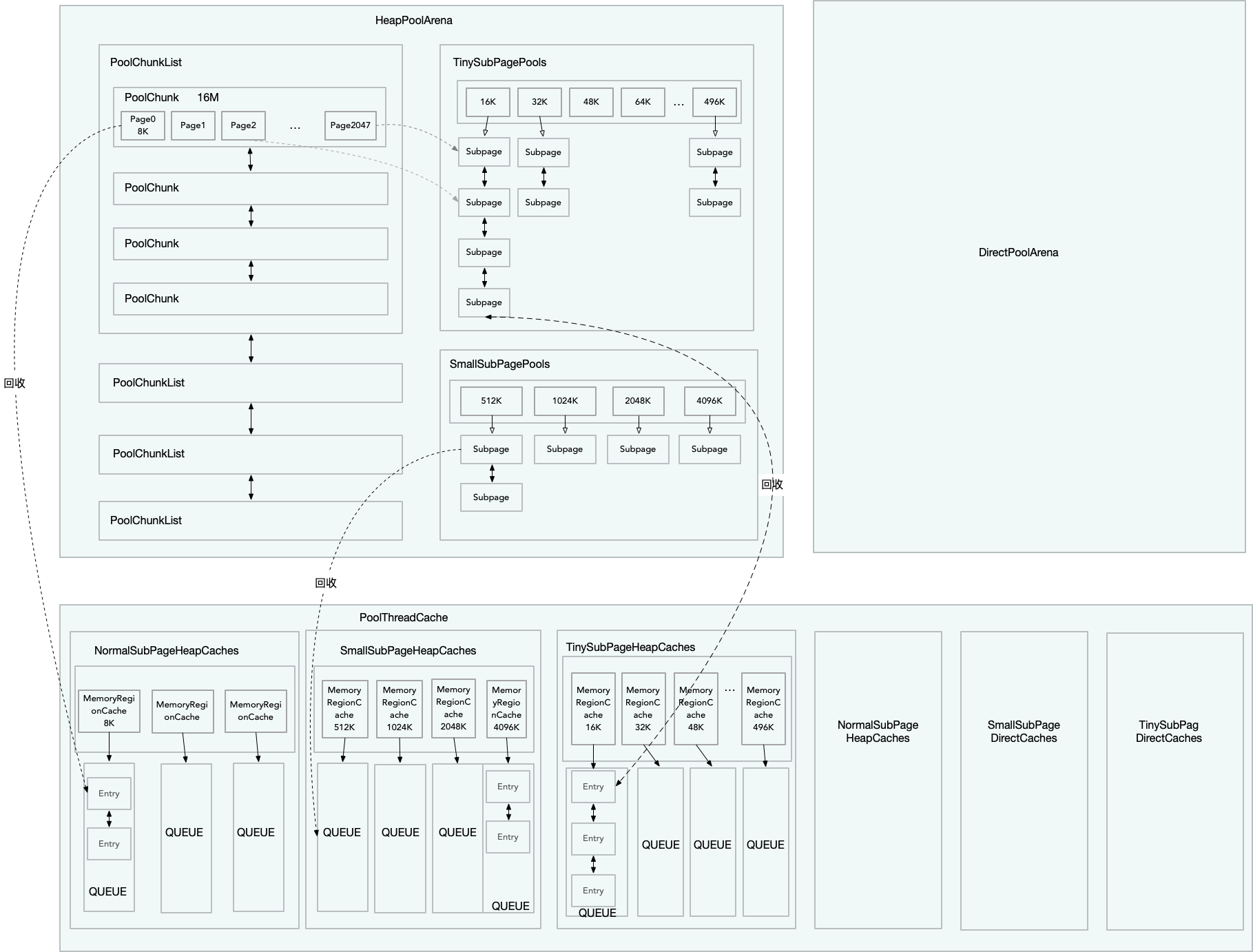
上图仅详细画了针对Heap Memory的部分,Directory Memory也是类似的。
最后在由PooledByteBufAllocator作为入口,重头梳理一遍内存申请的过程:
- PooledByteBufAllocator.newHeapBuffer()开始申请内存
- 获取线程本地的变量PoolThreadCache以及和线程绑定的PoolArena
- 通过PoolArena分配内存,先获取ByteBuf对象(可能是对象池回收的也可能是创建的),在开始内存分配
- 分配前先判断此次内存的等级,尝试从PoolThreadCache的找相同规格的缓存内存块使用,没有则从PoolArena中分配内存
- 对于Normal等级内存而言,从PoolChunkList的链表中找合适的PoolChunk来分配内存,如果没有则先像OS申请一个PoolChunk,在由PoolChunk分配相应的Page
- 对于Tiny和Small等级的内存而言,从对应的PoolSubpage缓存池中找内存分配,如果没有PoolSubpage,线会到第5步,先分配PoolChunk,再由PoolChunk分配Page给PoolSubpage使用
- 对于Huge等级的内存而言,不会缓存,会在用的时候申请,释放的时候直接回收。
总结
Netty的内存管理机制还是很巧妙的,但是介绍起来难免有点晦涩。本想尽量通俗易懂的撇开源码和大家讲讲原理,但是不知不觉也写了一大段的文字。希望上文的几幅图能帮助读者理解。
另外,本文也没有介绍内存释放的过程。释放其实就是申请的逆过程,有兴趣的读者可以自己跟一下源码,或者是文章开头的项目中找源码注释。
谈谈Netty内存管理的更多相关文章
- java基础(一):谈谈java内存管理与垃圾回收机制
看了很多java内存管理的文章或者博客,写的要么笼统,要么划分的不正确,且很多文章都千篇一律.例如部分地方将jvm笼统的分为堆.栈.程序计数器,这么分太过于笼统,无法清晰的阐述java的内存管理模型: ...
- Netty内存管理器ByteBufAllocator及内存分配
ByteBufAllocator 内存管理器: Netty 中内存分配有一个最顶层的抽象就是ByteBufAllocator,负责分配所有ByteBuf 类型的内存.功能其实不是很多,主要有以下几个重 ...
- 7.netty内存管理-ByteBuf
ByteBuf ByteBuf是什么 ByteBuf重要API read.write.set.skipBytes mark和reset duplicate.slice.copy retain.rele ...
- 《从HBase offheap到Netty的内存管理》
JVM中的堆外内存(off-heap memory)与堆内内存(on-heap memory) 1. 堆内内存(on-heap memory) 1.1 什么是堆内内存 Java 虚拟机在执行Jav ...
- Linux内存管理 【转】
转自:http://blog.chinaunix.net/uid-25909619-id-4491368.html Linux内存管理 摘要:本章首先以应用程序开发者的角度审视Linux的进程内存管理 ...
- Linux内存管理【转】
转自:http://www.cnblogs.com/wuchanming/p/4360264.html 转载:http://www.kerneltravel.net/journal/v/mem.htm ...
- Linux内存管理(最透彻的一篇)【转】
转自:https://www.cnblogs.com/ralap7/p/9184773.html 摘要:本章首先以应用程序开发者的角度审视Linux的进程内存管理,在此基础上逐步深入到内核中讨论系统物 ...
- 【转】Linux内存管理(最透彻的一篇)
摘要:本章首先以应用程序开发者的角度审视Linux的进程内存管理,在此基础上逐步深入到内核中讨论系统物理内存管理和内核内存的使用方法.力求从外到内.水到渠成地引导网友分析Linux的内存管理与使用.在 ...
- Linux内存管理—详细讲解
摘要:本章首先以应用程序开发者的角度审视Linux的进程内存管理,在此基础上逐步深入到内核中讨论系统物理内存管理和内核内存的使用方法.力求从外到内.水到渠成地引导网友分析Linux的内存管理与使用.在 ...
随机推荐
- php 解决表单重复提交实现方法介绍
重复提交是我们开发中会常碰到的一个问题,除了我们使用js来防止表单的重复提交,同时还可以使用php来防止重复提交哦. 例1 代码如下 复制代码 <?php/* * php中如何防止表单的重复提 ...
- JavaFX桌面应用-SpringBoot + JavaFX
SpringBoot对于Java程序员来说可以是一个福音,它让程序员在开发的时候,大大简化了各种spring的xml配置. 那么在JavaFX项目使用SpringBoot会是怎么样的体验呢? 这次使用 ...
- Dubbo详解
什么是DubboDubbo是一个分布式服务框架,致力于提供高性能和透明化的远程服务调用方案,这容易和负载均衡弄混,负载均衡是对外提供一个公共地址,请求过来时通过轮询.随机等,路由到不同server.目 ...
- 学习lammps 对in文件的一个概述性心得(转载)
转载自:http://muchong.com/html/201411/8149677.html 写在开头:1.尽量列举了大部分(几乎)的命令2.带星号命令非常重要,大家在看mannual中命令的解释的 ...
- Linux环境编程进程间通信机制理解
一.Linux系统调用主要函数 二.创建进程 1.创建子进程系统调用fork() 2.验证fork()创建子进程效果 3.系统调用fork()与挂起系统调用wait() 三.模拟进程管道通信 四.pi ...
- 用maven整合SSM中jsp运行报404和500问题解决方案
如果代码检查没有错误,建议更改maven版本,可以改为maven-3.6.1 网址:https://archive.apache.org/dist/maven/maven-3/ 选择3.6.1 再点击 ...
- Labview学习之路(二)截屏时弹出来的窗口总是关闭
当屏幕上存在一些弹出来的窗口时,总是会出现一按下截图快捷键那些窗口就关闭的情况,开始我也很苦恼,后来我发现,只要按顺序按下 Ctrl Alt A 就可以让那些窗口不关闭,记住一定 ...
- Linux文件描述符与重定向
文件描述符可以理解为linux跟踪打开文件,而分配的一个数字,这个数字有点类似c语言操作文件时候的句柄,通过句柄就可以实现文件的读写操作. 当Linux启动的时候会默认打开三个文件描述符,分别是: 标 ...
- python笔记-标准库unittest
unittest核心工作原理 unittest中最核心的四个概念是:test case, test suite, test runner, test fixture. 一个TestCase的实例就是一 ...
- Selenium学习整理(Python)
1 准备软件 Selenium IDE firebug-2.0.19.xpi firepath-0.9.7-fx.xpi Firefox_46.0.1.5966_setup.exe 由于火狐浏览器高版 ...