技术应用丨DWS 空间释放(vacuum full) 最佳实践
摘要:本文主要介绍如何进行正常的VACUUM FULL 维护,及时释放磁盘存储。
1、背景
目前根据某项目情况,其DWS的磁盘IO性能低、库内数据量大、对象多、数据膨胀严重。若毫无目的性的进行空间释放,一方面对IO压力很大,严重影响当前DWS任务运行,同时预计每次执行VACUUM FULL 时间已超过运行间隔,导致维护任务无法开展;若依据脏页率进行磁盘空间维护,每次脏页统计花费1天之多且有极高概率出现异常,频繁进行脏页统计也一定程度上影响DWS运行。
本文档主要介绍如何进行正常的VACUUM FULL 维护,及时释放磁盘存储。
2、说明
2.1 VACUUM FULL介绍
VACUUM FULL一方面可以及时回收空间,一方面可以一定程度上提升数据库性能。
VACUUM FULL回收表中已经删除的行所占据的存储空间。在一般的数据库操作里,那些已经DELETE的行并没有从它们所属的表中物理删除,因此有必要周期地运行VACUUM FULL,特别是在经常更新的表上。
2.2 VACUUM FULL使用建议
VACUUM FULL 对现有DWS任务运行具有一定影响。建议从以下几个角度考虑:
系统表
针对系统表的操作比较危险,往往伴随着阻塞DWS正常任务或链接接入。附录的函数中已排除掉系统表的脏页统计。
建议:根据系统表大小(参考附录5.3章节),半年~一年时间进行统计,若发现膨胀情况可协调窗口期做好业务暂停准备并进行释放。这里不做特别说明。
普通表
可单纯根据脏页率进行评估,决定是否需要进行释放;或通过脏页率+表大小配合方式评估,更有目的性进行释放。
建议:
1、首先建议确定系统运行压力较低的时间段,在该时间段内进行脏页统计,并根据脏页统计效果进行VACUUM FULL 维护操作。
2、其次建议根据系统数据更新频度,选取1~2月进行一次脏页统计。然后根据统计结果对这些表进行VACUUM FULL 操作。
3、最后建议获取系统脏页时配合表大小,规则自行拟定。如:脏页率超过20%、表大小*脏页率释放空间达到20GB 等等。
4、补充建议依照函数说明(附录5.1章节),对视图数据进行固化(创建对应表)。这样可避免二次筛选时耗时过长,只需要对表进行筛选即可。
5、VACUUM FULL 操作建议根据系统压力进行调整,压力中等情况下可使用1~2个并发。无压力情况下可适当提升并发度。
索引
针对索引需要进行重建,这里不做过多说明。附录的函数中已排除掉索引统计。
2.3 新版脏页率函数使用说明
1、创建函数及视图
DWS中根据附录脚本,创建funckang_get_dirty_tuples函数及v_get_dirty_tuples视图。需要注意视图中注释部分,自行决定是否保留。
2、对结果进行二次分析
使用step3步骤,将视图内容映射成物理表。然后对物理表进行规则筛选,参考2.2章节建议部分。
3、执行vacuum full
根据筛选出的schema名、table名 ,进行vacuum full 语句拼接,写入SQL文件。
4、执行vacuum full
确定时间时间段与并发度,通过 \parallel on ${number} 方式利用客户端并发执行。
2.4 改进后脏页统计方式比较
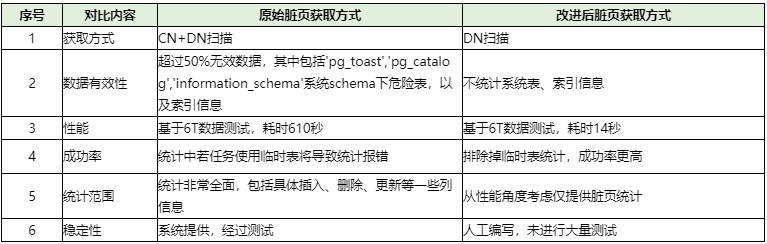
3 原有脏页统计方式说明
1. 查询 pgxc_get_stat_all_tables (viw1)
注:视图可以获取脏页率。但其中包括插入、更新删除等许多统计信息,同时还需要与pg_namespace 关联。
2. pgxc_stat_all_tables(func1) 函数
注:函数自身循环遍历各个CN与DN上的信息,是个无法下推函数。
3. pg_catalog.pg_stat_all_tables(view2)
注:试图自身需要三个系统表关联,统计了很多无用信息。
4 新版脏页统计方式说明
1、 funckang_get_dirty_tuples
注:函数自身只遍历DN上的表,同时去掉冗余信息 。通过v_get_dirty_tuples 视图计算表脏页信息,提供脏页率及表大小统计。
2、funckang_get_dirty_tuples_from_name
注:提供根据具体schemaname、tablename 方式返回具体的表的脏页信息。
可根据提供的SQL进行查询。
5 附录
5.1 统计全库表脏页率
step1 :创建获取脏页的函数
CREATE OR REPLACE function public.funckang_get_dirty_tuples(out v_oid oid,out v_nspname text ,out v_relname text ,out v_livetup float8 ,out v_deadtup float8) returns setof record
LANGUAGE plpgsql
NOT FENCED NOT SHIPPABLE
AS $function$
DECLARE
/*
-- =============================================================================
-- Program Name: 获取数据脏页率
-- Program ID: funckang_get_dirty_tuples
-- Revision:1.0
-- Author: by kanghaifeng
-- Create date: 2020/11/04
-- =============================================================================
*/
row_data record;
dn_name record;
query_str text;
query_str_nodes text;
BEGIN
--Get all the node names
query_str_nodes := 'SELECT node_name FROM pgxc_node WHERE node_type = ''D''';
FOR dn_name IN EXECUTE(query_str_nodes) LOOP
query_str := 'EXECUTE DIRECT ON (' || dn_name.node_name || ') ''SELECT c.oid AS relid, n.nspname AS schemaname, c.relname, pg_stat_get_live_tuples(c.oid) AS n_live_tup,pg_stat_get_dead_tuples(c.oid) AS n_dead_tup
FROM pg_class c
LEFT JOIN pg_namespace n ON n.oid = c.relnamespace
WHERE n.nspname not in (''''pg_catalog'''',''''information_schema'''',''''sys'''',''''cstore'''',''''pmk'''')
and n.nspname not like ''''pg_temp%''''
AND n.nspname !~ ''''^pg_toast''''
and c.relkind=''''r''''
GROUP BY c.oid, n.nspname, c.relname'' ';
FOR row_data IN EXECUTE(query_str) LOOP
--insert into kang_tup values(row_data.relid,row_data.schemaname,row_data.relname,row_data.n_live_tup,row_data.n_dead_tup);
v_oid :=row_data.relid;
v_nspname:=row_data.schemaname;
v_relname:=row_data.relname;
v_livetup:=row_data.n_live_tup;
v_deadtup:=row_data.n_dead_tup;
return next ;
END LOOP;
END LOOP;
return;
END;
$function$
/
step2: 创建获取脏页信息的视图,注释部分为表大小信息,可根据需要决定是否需要。
drop view if exists public.v_get_dirty_tuples;
create view public.v_get_dirty_tuples as
SELECT
funckang_get_dirty_tuples.nspname,
funckang_get_dirty_tuples.relname,
-- pg_table_size(funckang_get_dirty_tuples.nspname||'.'||funckang_get_dirty_tuples.relname),
sum(funckang_get_dirty_tuples.n_live_tup) AS n_live_tup,
sum(funckang_get_dirty_tuples.n_dead_tup) AS n_dead_tup,
(sum(funckang_get_dirty_tuples.n_dead_tup) / sum((funckang_get_dirty_tuples.n_dead_tup + funckang_get_dirty_tuples.n_live_tup)::numeric + .0001) * 100::numeric)::numeric(5,2) AS dirty_page_rate
FROM public.funckang_get_dirty_tuples() funckang_get_dirty_tuples(oid,nspname,relname,n_live_tup,n_dead_tup)
GROUP BY funckang_get_dirty_tuples.nspname,funckang_get_dirty_tuples.relname;
step3: 因视图查询耗时,建议创建一个表将视图内容固话下来做进一步分析。
create table public.zangye as select * from public.v_get_dirty_tuples;
5.2 根据给定表返回脏页率
step1 :创建获取脏页的函数
CREATE OR REPLACE function public.funckang_get_dirty_tuples_from_name(in out schemaname text,in out tablename text ,out v_livetup float8 ,out v_deadtup float8) returns setof record
LANGUAGE plpgsql
NOT FENCED NOT SHIPPABLE
AS $function$
DECLARE
/*
-- =============================================================================
-- Program Name: 根据schemaname,tablename获取数据脏页率
-- Program ID: funckang_get_dirty_tuples_from_name
-- Revision:1.0
-- Author: by kanghaifeng
-- Create date: 2020/11/04
-- =============================================================================
*/
row_data record;
dn_name record;
query_str text;
query_str_nodes text;
BEGIN
--Get all the node names
query_str_nodes := 'SELECT node_name FROM pgxc_node WHERE node_type = ''D''';
FOR dn_name IN EXECUTE(query_str_nodes) LOOP
query_str := 'EXECUTE DIRECT ON (' || dn_name.node_name || ') ''SELECT c.oid AS relid, n.nspname AS schemaname, c.relname, pg_stat_get_live_tuples(c.oid) AS n_live_tup,pg_stat_get_dead_tuples(c.oid) AS n_dead_tup
FROM pg_class c
LEFT JOIN pg_namespace n ON n.oid = c.relnamespace
WHERE n.nspname not in (''''pg_catalog'''',''''information_schema'''',''''sys'''',''''cstore'''',''''pmk'''')
and n.nspname not like ''''pg_temp%''''
AND n.nspname !~ ''''^pg_toast''''
and c.relkind=''''r''''
and n.nspname='''''||schemaname||'''''
and c.relname='''''||tablename||'''''
GROUP BY c.oid, n.nspname, c.relname'' ';
DBMS_OUTPUT.PUT_LINE(query_str); FOR row_data IN EXECUTE(query_str) LOOP
--insert into kang_tup values(row_data.relid,row_data.schemaname,row_data.relname,row_data.n_live_tup,row_data.n_dead_tup);
--v_oid :=row_data.relid;
schemaname:=row_data.schemaname;
tablename:=row_data.relname;
v_livetup:=row_data.n_live_tup;
v_deadtup:=row_data.n_dead_tup;
return next ;
END LOOP;
END LOOP;
return;
END;
$function$
/
step2 :查询给出表的脏页信息。下面为dbadmin.hedi2 示例。注释部分为大小信息,可根据需要决定是否使用
SELECT
funckang_get_dirty_tuples_from_name.schemaname,
funckang_get_dirty_tuples_from_name.tablename,
-- pg_table_size(funckang_get_dirty_tuples_from_name.schemaname||'.'||funckang_get_dirty_tuples_from_name.tablename),
sum(funckang_get_dirty_tuples_from_name.n_live_tup) AS n_live_tup,
sum(funckang_get_dirty_tuples_from_name.n_dead_tup) AS n_dead_tup,
(sum(funckang_get_dirty_tuples_from_name.n_dead_tup) / sum((funckang_get_dirty_tuples_from_name.n_dead_tup + funckang_get_dirty_tuples_from_name.n_live_tup)::numeric + .0001) * 100::numeric)::numeric(5,2) AS dirty_page_rate
FROM public.funckang_get_dirty_tuples_from_name('dbadmin','hedi2') funckang_get_dirty_tuples_from_name(schemaname,tablename,n_live_tup,n_dead_tup)
GROUP BY funckang_get_dirty_tuples_from_name.schemaname,funckang_get_dirty_tuples_from_name.tablename;
5.3 系统表大小统计
select
pt.schemaname
,pt.tablename
,getdistributekey(pt.schemaname||'."'||pt.tablename||'"') as distribute_key
,pg_size_pretty(pg_relation_size(pt.schemaname||'."'||pt.tablename||'"')) as tablesize
,case when pt.hasindexes = 't' then pg_size_pretty(pg_indexes_size(pt.schemaname||'."'||pt.tablename||'"')) else '' end as indexsize
,pc.reloptions
,pg_stat_get_last_analyze_time(pc.oid) as lastanalyze
,pg_stat_get_last_vacuum_time(pc.oid) as lastvacuum
,pc.parttype
from
pg_tables pt
,pg_class pc
where
(pt.schemaname||'."'||pt.tablename||'"')::regclass::oid=pc.oid and pt.schemaname not in ('mppdbpermission','information_schema','cstore','pg_catalog','pmk')
order by
pg_relation_size((pt.schemaname||'."'||pt.tablename||'"')) desc;
本文分享自华为云社区《关于DWS 空间释放(vacuum full) 最佳实践》,原文作者: 独孤求败马? 。
技术应用丨DWS 空间释放(vacuum full) 最佳实践的更多相关文章
- sql server 2008空间释放
今天一原来的同事打电话说他们两个表加起来1.2t(每个表都有三四十个字段,6亿条记录),创建了索引之后空间增长到了2.2t,然后没有执行成功.问题在于虽然没执行成功,可是空间没有释放,整个系统只有2. ...
- linux 空间释放,mysql数据库空间释放
测试告急,服务器不行了.down了…… 1.linux如何查看磁盘剩余空间: [root@XXX~]# df -lhFilesystem Size Used Avai ...
- [z]分区truncate操作的介绍及对全局索引和空间释放影响的案例解析
[z]https://www.2cto.com/database/201301/181226.html 环境: [sql] [oracle@localhost ~]$ uname -r 2.6.18- ...
- [磁盘空间]lsof处理文件恢复、句柄以及空间释放问题
曾经在生产上遇到过一个df 和 du出现的结果不一致的问题,为了排查到底是哪个进程占用了文件句柄,导致空间未释放,首先在linux上面,一切皆文件,这个问题可以使用lsof这个BT的命令来处理(这个哈 ...
- 【linux】lsof命令和{Linux下文件删除、句柄与空间释放问题}
导读: 一.用事实说话 二.关于LSOF命令的其它用法: 三.参考文档: 正文: lsof:Finding open files with lsof 作用:查看文件被哪些进程打开 一.用事实说 ...
- 技术干货丨如何在VIPKID中构建MQ服务
小结: 1. https://mp.weixin.qq.com/s/FQ-DKvQZSP061kqG_qeRjA 文 |李伟 VIPKID数据中间件架构师 交流微信 | datapipeline201 ...
- [转载]再谈PostgreSQL的膨胀和vacuum机制及最佳实践
本文转载自 www.postgres.cn 下的文章: 再谈PostgreSQL的膨胀和vacuum机制及最佳实践http://www.postgres.cn/news/viewone/1/390 还 ...
- 基于华为云IOT及无线RFID技术的智慧仓储解决方案最佳实践系列一
[摘要]仓储管理存在四大细分场景:出入库管理.盘点.分拣和货物跟踪.本系列将介绍利用华为云IOT全栈云服务,端侧采用华为收发分离式RFID解决方案,打造端到端到IOT智慧仓储解决方案的最佳实践. 仓储 ...
- Atitit.log日志技术的最佳实践attilax总结
Atitit.log日志技术的最佳实践attilax总结 1. 日志的意义与作用1 1.1. 日志系统是一种不可或缺的单元测试,跟踪调试工具1 2. 俩种实现[1]日志系统作为一种服务进程存在 [2] ...
随机推荐
- python爬虫爬取策略
爬取策略 关注公众号"轻松学编程"了解更多. 在爬虫系统中,待抓取URL队列是很重要的一部分.待抓取URL队列中的URL以什么样的顺序排列也是一个很重要的问题,因为这涉及到先抓取那 ...
- yython爬虫基础知识入门
Python爬虫 关注公众号"轻松学编程"了解更多. 大纲: 1.获取响应 urllib(python3)/urllib2-urllib(python2) requests(url ...
- vue踩坑
1. 双向绑定的对象 改变或新增其属性 DOM不刷新问题 var obj = { "attr1": "1", "attr2": [2] }; ...
- SpringBoot的外部化配置最全解析!
目录 SpringBoot中的配置解析[Externalized Configuration] 本篇要点 一.SpringBoot官方文档对于外部化配置的介绍及作用顺序 二.各种外部化配置举例 1.随 ...
- 看得见的成本!1款工具实现K8S资源成本监控可视化
本文来自Rancher Labs 关注我们,第一时间获取技术干货 计算Kubernetes成本的复杂性 采用Kubernetes和基于服务的架构可以为企业带来诸多好处,如团队可以更快地迁移以及应用程序 ...
- LOJ #6029. 「雅礼集训 2017 Day1」市场 线段树维护区间除法
题目描述 从前有一个贸易市场,在一位执政官到来之前都是非常繁荣的,自从他来了之后,发布了一系列奇怪的政令,导致贸易市场的衰落. 有 \(n\) 个商贩,从\(0 \sim n - 1\) 编号,每个商 ...
- Spider_实践_beautifulsoup静态网页爬取所有网页链接
# 获取百度网站首页上的所有a标签里的 href属性值: # import requests # from bs4 import BeautifulSoup # # html = requests.g ...
- VMware虚拟机 - 解决 Vmware 启动虚拟机报:该虚拟机似乎正在使用中。 如果该虚拟机未在使用,请按“获取所有权(T)”按钮获取它的所有权。否则,请按“取消(C)”按钮以防损坏的问题
问题背景 当虚拟机仍然在运行时,直接关闭电脑,下次重开电脑并想重新启动虚拟机时报了下图问题 解决方案 进入虚拟机所在目录,把 .lck 后缀的文件都删完 Vmware 重新启动虚拟机 成功!!
- linux域名解析引起登陆慢
linux域名解析引起登陆慢的问题在于,ssh去登录这个台机器的时候,本机会去通过域名解析获取登录主机的主机名,所有一旦域名解析是无效的,需要等待较长时间 解决办法一: 将域名解析指到127.0.0. ...
- 文本多行省略号(CSS最优方案)
Float定位溢出隐藏 优点: 纯CSS实现,性能好,不用js调优 兼容性高 多行省略,自动显示 缺点: 单词截断 代码如下: <div class="ellipses-div&quo ...