Apache Pulsar 在腾讯 Angel PowerFL 联邦学习平台上的实践
腾讯 Angel PowerFL 联邦学习平台
联邦学习作为新一代人工智能基础技术,通过解决数据隐私与数据孤岛问题,重塑金融、医疗、城市安防等领域。
腾讯 Angel PowerFL 联邦学习平台构建在 Angel 机器学习平台上,利用 Angel-PS 支持万亿级模型训练的能力,将很多在 Worker 上的计算提升到 PS(参数服务器) 端;Angel PowerFL 为联邦学习算法提供了计算、加密、存储、状态同步等基本操作接口,通过流程调度模块协调参与方任务执行状态,而通信模块完成了任务训练过程中所有数据的传输。Angel PowerFL 联邦学习已经在腾讯金融云、腾讯广告联合建模等业务中开始落地,并取得初步的效果。
Angel 机器学习平台:https://github.com/Angel-ML
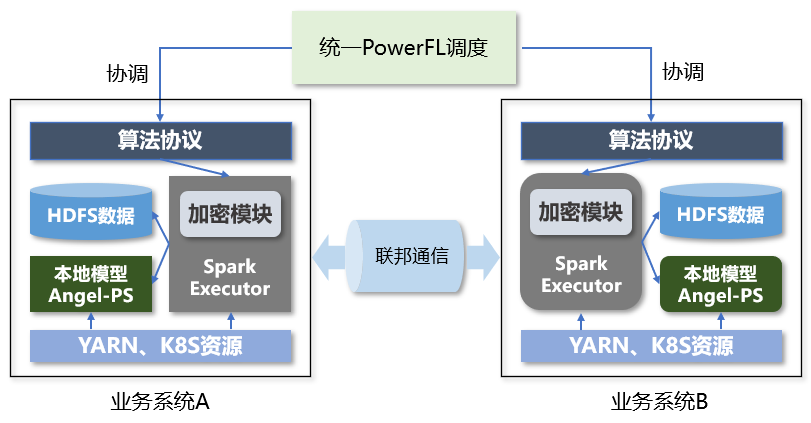
Angel PowerFL 对联邦通信服务的要求
Angel PowerFL 联邦学习平台在训练任务过程当中,对参与方之间的消息通信要求极高,要求消息系统必须稳定可靠、保持高性能且能保证数据安全。Angel PowerFL 的学习任务在训练过程当中,参与方之间会有大量的加密数据通过通信模块传输,Angel PowerFL 对通信服务有以下需求:
️ 稳定可靠
Angel PowerFL 的学习任务时长从几分钟到几小时,算法执行对数据的准确性要求很高,不同算法的数据传输峰值也不一样,这需要通信模块的服务足够稳定,并且不能丢数据。
️ 高性能传输
Angel PowerFL 底层通过 Spark 进行计算,Executor 并发执行会产生很多待传输的中间数据,通信模块需要将这些加密后的数据及时传输给对方,这就要求通信服务做到低延时、高吞吐量。
️ 数据安全
虽然 Angel PowerFL 所有数据都通过加密模块进行了加密,但参与联邦学习的业务可能分布在不同公司;跨公网进行传输,需要通信模块足够安全,不易被攻击。
为什么选择 Pulsar
联邦通信服务在做技术预研的时候,考虑过 RPC 直连、HDFS 同步、MQ 同步三种技术方案。考虑到对安全和性能的要求比较高,排除了 RPC 直连和 HDFS 同步方案,确定采用 MQ 同步方案。
MQ 可选的服务很多,比如 Pulsar、Kafka、RabbitMQ、TubeMQ 等。考虑到 Angel PowerFL 对稳定性、可靠性、高性能传输和数据安全有很高的需求,我们咨询了腾讯数据平台部 MQ 团队,他们向我们推荐了 Pulsar。
随后,我们对 Pulsar 开展了深入调研,发现 Pulsar 内置的诸多特性,正好满足了我们对消息系统的要求。Pulsar broker 和 bookie 采用了计算存储分层架构,保证了数据稳定可靠,性能良好;Pulsar 支持跨地域复制(geo-replication),解决了 PowerFL 跨联邦同步 MQ 问题;而 Pulsar 的验证和授权模式也能保证传输安全。
云原生的计算与存储分层架构
Apache Pulsar 是下一代云原生分布式消息和事件流平台,采用了计算和存储分层的架构:在 Broker 上进行 Pub/Sub 相关的计算,在 Apache BookKeeper 上存储数据。
和传统的消息平台(如 Kafka)相比,这种架构有明显的优势:
Broker 和 bookie 相互独立,可以独立扩展和容错,提升系统的可用性。
分区存储不受单个节点存储容量的限制,数据分布更均匀。
BookKeeper 存储安全可靠,保证消息不丢失,同时支持批量刷盘以获得更高吞吐量。
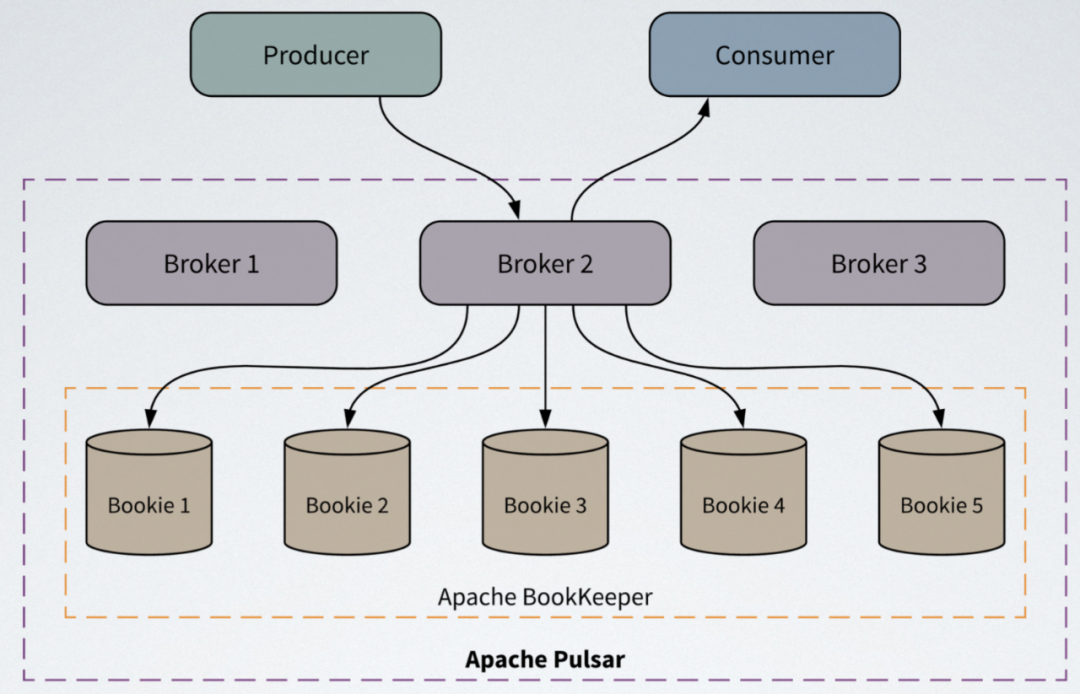
Pulsar Geo-replication
Pulsar 原生支持跨地域复制(Geo-replication),可以在多个数据中心的多个 Pulsar 集群中同时同步/异步复制数据。还可以在消息级别,通过 setReplicationClusters 控制消息复制到哪些集群。
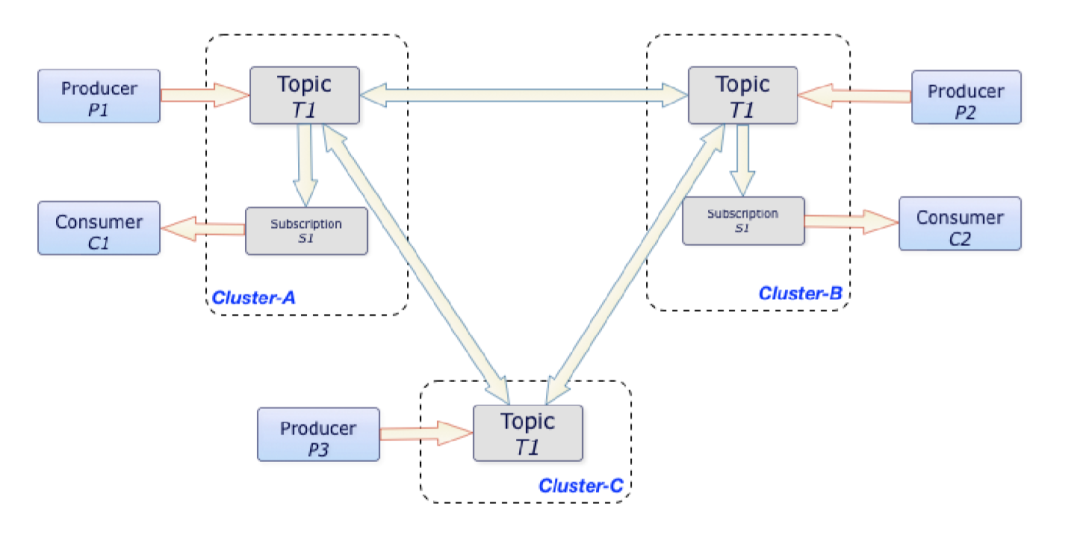
在上图中,无论 Producer P1、P2 和 P3 在什么时候分别将消息发布给 Cluster A、Cluster B 和 Cluster C 中的 topic T1,这些消息均会立刻复制到整个集群。一旦完成复制,Consumer C1 和 C2 即可从自己所在的集群消费这些消息。
水平扩展
由于 Pulsar 的存储设计基于分片,Pulsar 把主题分区划分为更小的块,称其为分片。每个分片都作为 Apache BookKeeper ledger 来存储,这样构成分区的分片集合分布在 Apache BookKeeper 集群中。这样设计方便我们管理容量和水平扩展,并且满足高吞吐量的需求。
容量管理简单:主题分区的容量可以扩展至整个 BookKeeper 集群的容量,不受单个节点容量的限制。
扩容简单:扩容无需重新平衡或复制数据。添加新存储节点时,新节点仅用于新分片或其副本,Pulsar 自动平衡分片分布和集群中的流量。
高吞吐量:写入流量分布在存储层中,不会出现分区写入争用单个节点资源的情况。
经过深入调研后,我们决定在腾讯 Angel PowerFL 联邦学习平台上使用 Apache Pulsar。
基于 Apache Pulsar 的联邦通信方案
联邦学习的各个业务(Angel PowerFL 称之为 Party,每个 Party 有不同的 ID,如 10000/20000),可能分布在同个公司的不同部门(无网络隔离),也可能分布在不同公司(跨公网),各个 Party 之间通过 Pulsar 跨地域复制功能进行同步复制,总体设计方案如下:

联邦学习的每个训练任务,通过消息的 producer 和 consumer 连接所在 Party 的 Pulsar 集群,集群名以 fl-pulsar-[partyID] 进行区分,训练任务产生需要传输的中间数据后,生产者将这些数据发送给本地 Pulsar 集群。
Pulsar 集群收到数据后,通过 Pulsar proxy 建立的同步复制网络通道,将数据发送给使用方 Party。而使用方 Party 的消费者,会一直监听该训练任务对应的 topic,当有数据到达后,直接消费数据进行下一步的计算。
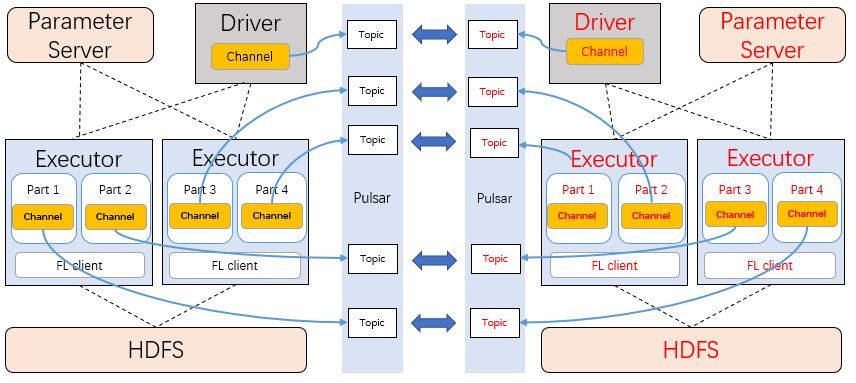
在 Angel PowerFL 执行训练任务时,driver 和每个 partition 会创建一个 channel 类型变量,该变量和 Pulsar 当中具体的 topic 一一对应,需要交换的数据都会经过生产者发送到这个 topic。
Angel PowerFL 支持多方联邦,因此会有 2+ 个 Pulsar 集群需要同步复制数据。每个联邦学习任务通过各自的 parties 任务参数指定了参与方,生产者在发送消息时调用 setReplicationClusters 接口,确保数据只在参与 Party 之间传输。
在 Angel PowerFL 的通信模块中,我们充分利用了 Pulsar 的 geo-replication、topic 限流、Token Authentication 等功能。下面我来详细介绍如何在 Angel PowerFL 联邦学习平台中使用 Pulsar。
Geo-replication 去掉Global ZooKeeper 依赖
在 Angel PowerFL 联邦学习平台上,部署一套完整的 Pulsar 依赖两个 ZooKeeper 集群,分别是 Local ZooKeeper 和 Global ZooKeeper。Local ZooKeeper 和 Kafka 中的 ZooKeeper 作用类似,用来存储元数据。而 Global ZooKeeper 则在 Pulsar 多个集群间中共享配置信息。
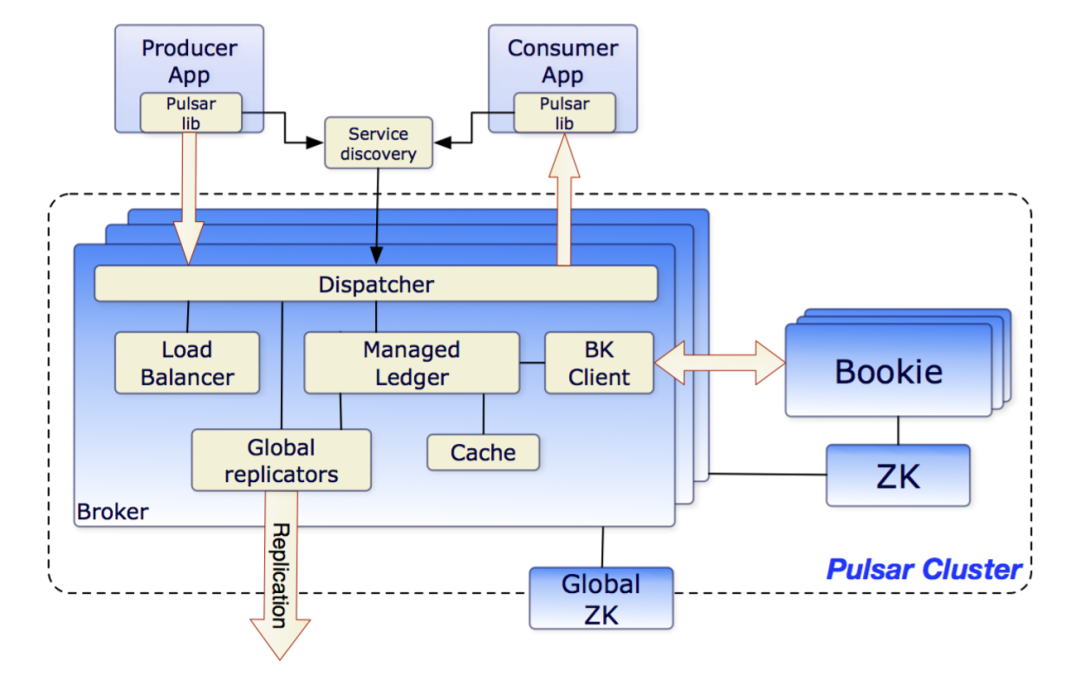
在 Angel PowerFL 场景中,每个 Party 加入前,都要先部署一个 Global ZooKeeper 的子节点,或者共用一套跨公司或跨地域的公共 ZooKeeper,这样不仅会增加部署的难度,也会增加被攻击的风险,不利于新 Party 加入。
Global ZooKeeper 中存储的元数据,主要是集群名/服务地址/namespace 权限等信息。Pulsar 支持创建和加入新集群。我们通过以下两个步骤注册联邦 Pulsar 集群的信息到 local ZooKeeper,就去除了对 Global ZooKeeper 的依赖:
步骤 1: 注册新加入 Party 的 Pulsar 集群
# OTHER_CLUSTER_NAME 为待注册 Party 的 Pulsar 集群名
# OTHER_CLUSTER_BROKER_URL为 Pulsar 集群对应的 broker 地址
./bin/pulsar-admin clusters create ${OTHER_CLUSTER_NAME}
--url http://${OTHER_CLUSTER_HTTP_URL}
--broker-url pulsar://${OTHER_CLUSTER_BROKER_URL}
步骤 2: 授予训练用到的 namespace 访问集群权限
./bin/pulsar-admin namespaces set-clusters fl-tenant/${namespace}
-clusters ${LOCAL_CLUSTR_NAME},${OTHER_CLUSTER_NAME}
对于新加入的 Party,只用提供与其对应的 Pulsar 的集群名/服务地址即可完成注册,geo-replication 就可以通过注册信息同步复制数据。
Client 增加 Token 认证
Pulsar 作为 Angel PowerFL 的通信模块,没有加入用户级别的权限控制。为了进一步保证 client 生产和消费数据的安全,我们参考 Pulsar Client authentication using tokens based on JSON Web Tokens 增加了 token 认证,Angel PowerFL 的训练任务除了配置当前 Party 使用的服务地址外,还需要配置 admin token。
https://pulsar.apache.org/docs/en/security-jwt/#token-authentication-overview
由于 Angel PowerFL 整套系统部署在 Kubernetes 上,我们通过容器准备 Pulsar 集群需要的 Public/Private keys 等文件,然后注册到 K8S secret 中。
# 生成 fl-private.key 和 fl-public.key
docker run --rm -v "$(pwd)":/tmp
apachepulsar/pulsar-all:2.5.2
/pulsar/bin/pulsar tokens create-key-pair --output-private-key
/tmp/fl-private.key --output-public-key /tmp/fl-public.key
# 生成 admin-token.txt token 文件
echo -n `docker run --rm -v
"$(pwd)":/tmp apachepulsar/pulsar-all:2.5.2
/pulsar/bin/pulsar tokens create --private-key
file:///tmp/fl-private.key --subject admin`
# 将认证相关的文件注册到 K8S
kubectl create secret generic token-symmetric-key
--from-file=TOKEN=admin-token.txt
--from-file=PUBLICKEY=fl-public.key -n ${PARTY_NAME}
开启多集群 topic 自动回收
Pulsar 集群开启了 geo-replication 功能后,无法通过命令直接删除用过的 topic,而 Angel PowerFL 训练任务每次使用的任务是一次性的,任务结束后这些 topic 就没用了,如果不及时删除会出现大量累积。
对于通过 geo-replication 开启复制的 topic,可以配置 brokerDeleteInactivetopicsEnabled 参数,开启 topic 自动回收。自动回收无用的 topic,需满足以下几个条件:
- 当前 topic 没有生产者( producer)或者消费者(consumer)连接
- 当前 topic 没有被订阅
- 当前 topic 没有需要保留的信息
Angel PowerFL 部署的 Pulsar 集群,通过 brokerDeleteInactivetopicsEnabled 开启 topic 自动回收。在执行训练任务的过程中,使用后对每个 topic 按回收条件进行处理。同时,我们增加了
brokerDeleteInactivetopicsFrequencySeconds 配置,将回收的频率设置为 3 小时。
优化 topic 限流
Angel PowerFL 中的训练任务,在不同的数据集/算法/执行阶段,生产数据的流量峰值也不同。目前生产环境中单个任务最大的数据量超过 200G/小时。训练过程中,如果 Pulsar 连接中断或者生产和消费过程出现异常,需要重新开始整个训练任务。
为了规避 Pulsar 集群被单个训练任务冲垮的风险,我们使用了 Pulsar 的限流功能。Pulsar 支持 message-rate 和 byte-rate 两种生产限流策略,前者限制每秒生产消息的数量,后者限制每秒生产消息的大小。Angel PowerFL 将数据切分成多个 4M 的消息,通过 message-rate 限制生产消息的数量。在 Angel PowerFL 中,我们将 namespace 的消息限制为 30 条(小于<30*4=120M/s):
./bin/pulsar-admin namespaces set-publish-rate fl-tenant/${namespace} -m 30
刚开始测试 message-rate 的限流功能时,出现了限不住的情况(限流设置失效)。腾讯数据平台部 MQ 团队负责 Pulsar 的同事帮忙一起排查,发现设置 topicPublisherThrottlingTickTimeMillis 参数后,限制不能生效。
因此我们想办法在 broker 端启用了精确的 topic 发布频率限制,优化了限流功能并贡献回社区,详情见 PR-7078: introduce precise topic publish rate limiting。
https://github.com/apache/pulsar/pull/7078
优化 topic unloading 配置
Pulsar 根据 broker 集群负载状况,可以将 topic 动态分配到 broker上。如果拥有该 topic 的broker 宕机,或者拥有该 topic 的 broker 负载过大,则该 topic 会立即重新分配给另一个 broker ;而重新分配的过程就是 topic 的 unloading,该操作意味着关闭 topic,释放所有者(owner)。
理论上,topic unloading 由负载均衡调整,客户端将经历极小的延迟抖动,通常耗时 10ms 左右。但 Angel PowerFL 初期在执行训练任务时,日志爆出大量因为 unloading topic 导致的连接异常。日志显示 topic unloading 在不断的重试,但都不成功:
[sub] Could not get connection to broker: topic is temporarily unavailable -- Will try again in 0.1 s
先来看 broker/namespace/bundle/topic 这四者的关系。Bundle 是 Pulsar namespace 的一个分片机制,namespace 被分片为 bundle 列表,每个 bundle 包含 namespace 的整个哈希范围的一部分。Topic 不直接分配给 broker,而是通过计算 topic 的哈希码将 topic 分配给特定的 bundle;每个 bundle 互相独立,再被分配到不同的 broker 上。
Angel PowerFL 早期的任务 topic 没有复用,一个 LR 算法训练任务创建了 2000 多个 topic,每个 topic 生产的数据负载也不同,我们判断上述断连问题是由于短时间内(最小任务十分钟内能结束,同时会有多个任务在运行)大量创建和使用 topic,导致负载不均衡,topic unloading 频繁发生。为了降低 topic unloading 的频率,我们调整了 Pulsar Bundle 的相关参数:
# 增加 broker 可最大分配 topic 数量
loadBalancerBrokerMaxTopics=500000
# 启用自动拆分namespace bundle
loadBalancerAutoBundleSplitEnabled=true
# 增加触发拆分 bundle 的 topic 数量
loadBalancerNamespaceBundleMaxTopics=10000
# 增加触发拆分 bundle 的消息数
loadBalancerNamespaceBundleMaxMsgRate=10000
同时,在创建 namespace 时,把 bundle 数量默认设置为 64。
./bin/pulsar-admin namespaces create fl-tenant/${namespace} --bundles 64
经过以上调整,Angel PowerFL 在任务执行期间没有再出现过由于 topic unloading 导致的断连。
Pulsar on Kubernetes
Angel PowerFL 的所有服务均通过 Helm 部署在 Kubernetes 上。Pulsar 作为其中的一个 chart,可以很好的利用 K8S 的资源隔离、快速扩缩容等特性。在 Angel PowerFL 使用 Helm 部署 Pulsar 的实践中,我们总结了以下经验:
背景 在人工智能技术的支持下,BIGO 基于视频的产品和服务受到广泛欢迎,在 150 多个国家/地区拥有用户,其中包括 Bigo Live(直播)和 Likee(短视频).Bigo Live 在 15 ... 关于 Apache Pulsar Apache Pulsar 是 Apache 软件基金会顶级项目,是下一代云原生分布式消息流平台,集消息.存储.轻量化函数式计算为一体,采用计算与存储分离架构设计,支 ... 关于 Apache Pulsar Apache Pulsar 是 Apache 软件基金会顶级项目,是下一代云原生分布式消息流平台,集消息.存储.轻量化函数式计算为一体,采用计算与存储分离架构设计,支 ... 关于 Apache Pulsar Apache Pulsar 是 Apache 软件基金会顶级项目,是下一代云原生分布式消息流平台,集消息.存储.轻量化函数式计算为一体,采用计算与存储分离架构设计,支 ... 导语 Apache Pulsar 是一个多租户.高性能的服务间消息传输解决方案,支持多租户.低延时.读写分离.跨地域复制.快速扩容.灵活容错等特性.腾讯云内部 Pulsar工作组对 Pulsar 做了 ... Apache Pulsar Summit 是 Apache Pulsar 社区年度盛会,它将分布在世界各地的 Apache Pulsar 项目 Contributor.Commiter 和各企业 CT ... Apache Pulsar What is Pulsar "Pulsar is a distributed pub-sub messaging platform with a very fl ... 0x01 简介 Apache Pulsar是一个开源的分布式发布-订阅消息系统,与Kafka类似,但比后者更加强大.Pulsar最初由Yahoo开发并维护,目前已经成为Apache软件组织的一个孵化子 ... Apache Pulsar是一款由雅虎开发的类似于Kafka的企业级消息订阅系统,在2016将其开源,由Apach基金会孵化,现在已经成长为Apache基金会的顶级项目.Pulsar在雅虎内部已经运行 ... 该博客以Web为基础 一.引入依赖 shiro-all包含shiro所有的包.shiro-core是核心包.shiro-web是与web整合.shiro-spring是与spring整合.shiro- ... 连接进入MySQL服务, 使用source ${文件名}执行. 末尾不能带分号. 本文源码:GitHub·点这里 || GitEE·点这里 一.Fork/Join框架 Java提供Fork/Join框架用于并行执行任务,核心的思想就是将一个大任务切分成多个小任务,然后汇总每个小任务 ... ES6--变量的解构赋值 引言 正文 一.数组的解构赋值 解构失败 不完全解构 默认值 二.对象的解构赋值 三.字符串的解构赋值 结束语 引言 变量的解构赋值, 听起来很复杂, 简单点说可以理解成批量 ... 在vue2版本中响应式使用的是ES5对象的操作,通过遍历对象Object.defineProperty属性值的变化,实现监听数据 在3.0中使用的ES6版本的Proxy代理对象方式来实现数据的监听,省 ... String str = "i.like.cat"; System.out.println(str.replace(".", "!")); ... 在讲解命令模式之前我们先来了解一个生活中的命令模式场景: 场景1: 医院看病抓药: 当你因为肾虚到医院看医生,医生一番操作之后得出结论:要吃个疗程[夏桑菊].[小柴胡](药名纯属虚构,真的肾虚就找医生 ... 原文链接: python基础-文件读写'r' 和 'rb'区别 一.Python文件读写的几种模式: r,rb,w,wb 那么在读写文件时,有无b标识的的主要区别在哪里呢? 1.文件使用方式标识 'r ... [centos] name=centos baseurl=http://mirrors.aliyun.com/centos/7/os/x86_64/ enabled= gpgcheck= [epel] ... 登录系统 # include <stdio.h> //头文件 # include <string.h> //字符串头文件 # include <stdlib.h> ...Apache Pulsar 在腾讯 Angel PowerFL 联邦学习平台上的实践的更多相关文章
随机推荐