The Data Warehouse Toolkit 阅读笔记
前言
这篇笔记的主要内容来至于The Data Warehouse Toolkit,该书可以称为数仓建模的圣经
什么是星型模型
以一个业务实时为主表。比如一笔订单就是一个业务事实。订单有商品的SKU信息,销售市场信息,日期信息 ,这些基本属性,叫做维度。

雪花
一个产品维度,本身还有分类、包装等信息,也独立做成表,围绕在事实表身边,就像一片雪花。
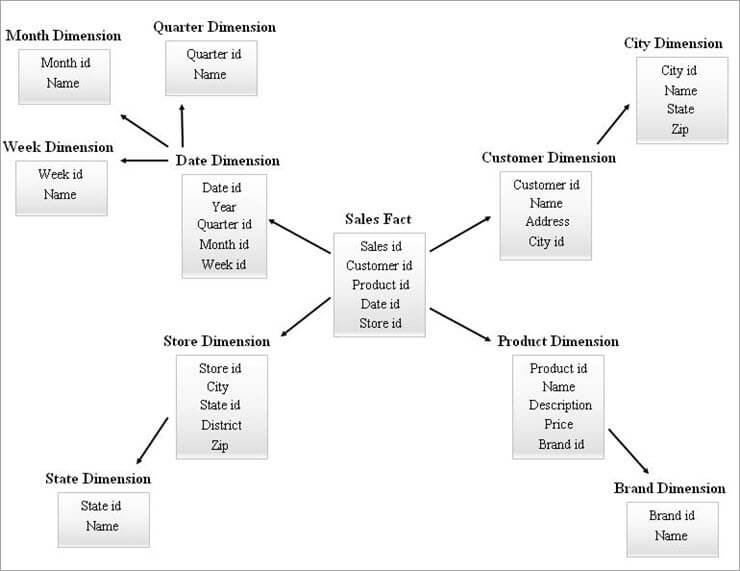
为什么要用星型模型
- OLTP是增对的事务,写的场景,所以粒度要细。数仓模型的应用场景是数据分析,涉及大量查询,所以要少关联,多整合
- 降低业务理解难度和复杂性,有些业务事实,跨了很多表,甚至跨了很库,比如一个订单的生命周期,牵扯订单团队、仓储团队、物流团队。如果不建模,则需要所有使用数据的人员明白对应的业务细节,表的数据结构
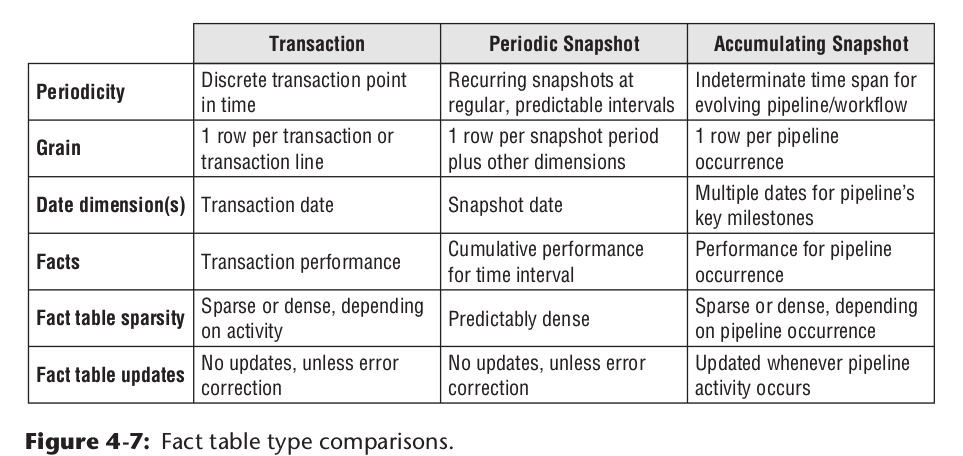
三种模型类型
总结来看,事实表分为三种类型。
- 事务事实表,比如一次商品销售记录
- 周期快照表。按一定时间周期记录业务实体快照。比如记录每天的促销商品销售情况
- 累计快照表,记录业务实体一些列业务流程变更的事实表
数仓的数据模型,为了应对不同的OLAP场景,往往三者皆有之。他们三者之间的区别如下
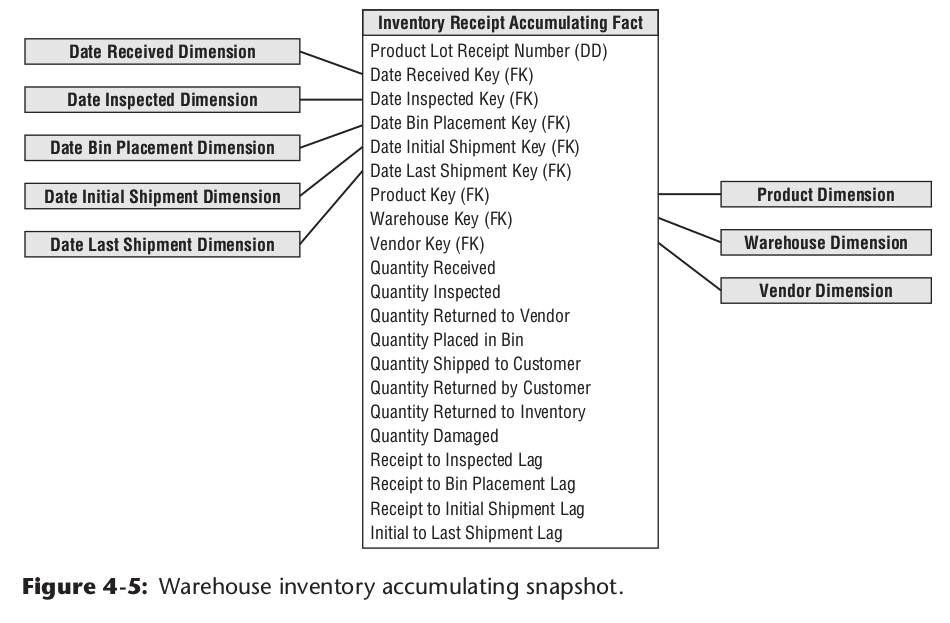
累计事实模型
有些业务实体,会发生一系列的业务流程变更,在事实表中,使用一条记录,记录该业务实体各关键流程的所有信息,并随各业务事件的发生来更新这条记录,也就是一条记录会累计各种变化,叫做累计快照表。比如一个商品进入仓库的的整个流程可能有,收货,验货,装箱,运输等。其模型设计示例如下:
一行数据的变更示例如下:
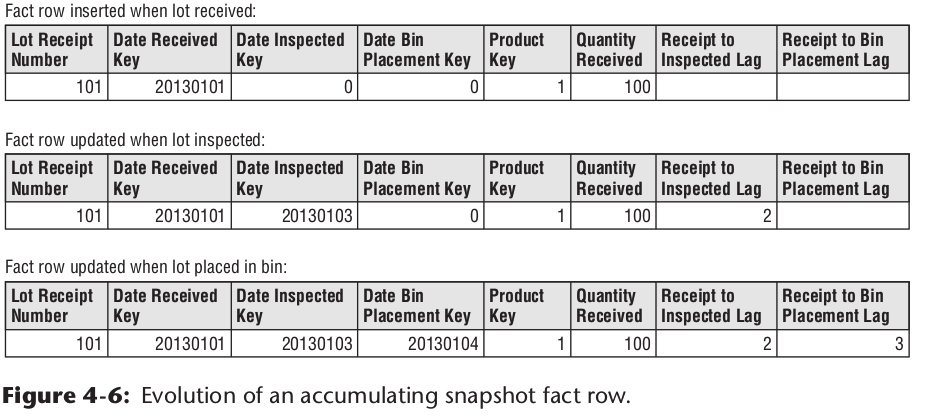
累计快照事实表要保证流程节点个数确定有限。动态任意多个流程,不适合做成累计快照事实表,因为变化太频繁。
一个模型怎么定义
- 选定业务事实 ,一条事实一定能回答谁、何时、何地、做了什么事,为什么要这么做,怎么做的?(who, when, where, what, why, and how)
- 定义数据粒度,事实表的粒度一定要细,才能灵活承载更上层的各种逻辑口径的指标计算。
- 标识维度表
- 标识事实表
如何响应维度表的变化
维度表相对比较稳定,但也不是完全不会变化。比如用户的信息维度表,就可以变更用户的年龄,地址等。那如何应付这些变化?主要有以下几种
- 保留原值
- 改维度表属性值
- 拉链表
- 添加新字段记录老数据
- 迷你维度表(Mini-Dimension)
- 混合
保留原值
事实表存储原值,而不是关联维度表。这样当相关属性变化时,新的事实表记录对应的值就是新属性值。
比如,商品当时的价格,就可以直接存储到事实表上
修改维度表属性值
直接将维度表对应变化字段的值进行修改。这会导致事实表中的老数据,关联维度表,也获取到了新值,使得报表结果出现变化,已经预计算的OLAP Cube需要重新计算等问题。所以慎用这种方式。举例如下:
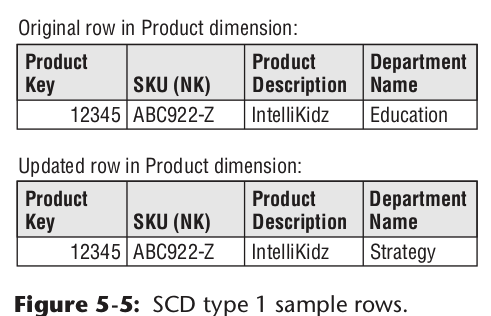
拉链表
给维度表加上数据有效时间字段,将维度表变成拉链表,使得维度表不光能体现当前的值,还能记录历史的信息。示例如下:
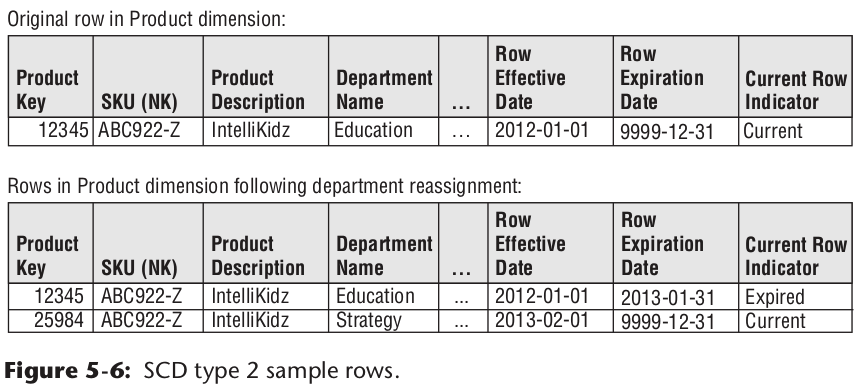
每个记录都有一个id,事实表关联当时的维度id。
添加新字段记录老数据
有的报表场景,可能就是需要根据新的维度信息,去关联老的的事实表记录,且变化不会太频繁。可以通过在维度表加字段,记录老数据,这样新老数据都存在,即可满足这种需求。示例如下:
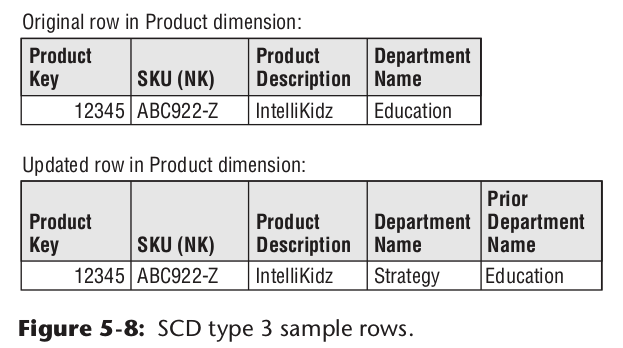
迷你维度表(Mini-Dimension)
有些维度表的数据字段较多,且部分字段数据变更较为频繁,如果采用拉链表的方式设计,那维度表的数据,将会快速增加。所以拉链表不是一个好的设计。比如用户信息中,籍贯、民族等信息变化较少。但用户的收入等级、位置范围却会频繁的变化。所以可以将这些变化项抽出来,做成一个迷你维度表。同时为了减少迷你维度表的数据条数。可以使用范围做字段值,比如一张可能的用户迷你维度表表示例如下:
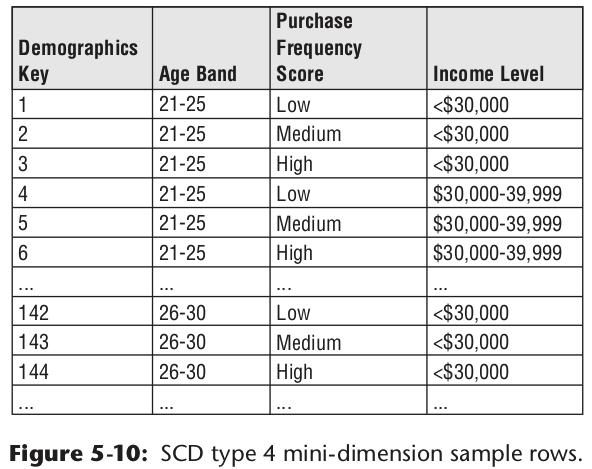
最终的模型设计如下:
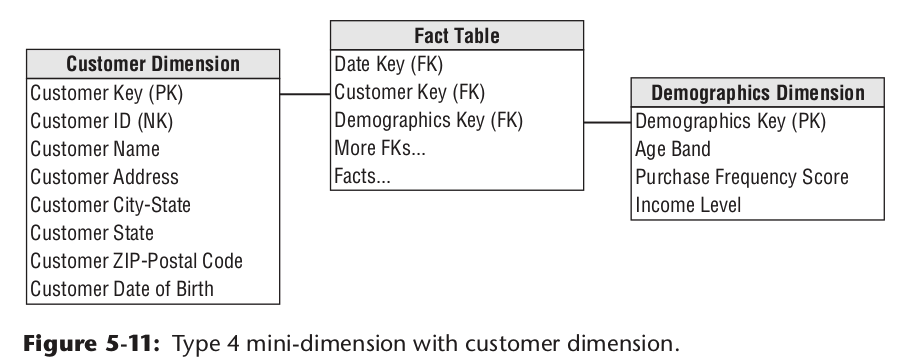
迷你维度记录了那些变化频繁的属性值所有可能的组合。事实表关联迷你维度表,即可覆盖每一种变化需求。由于迷你维度表,使用了范围值。所以如果想要获取某个具体属性值是不可能的。所以针对这种变化频繁,数据量大的业务数据,可以想办法做成事实表,而不是维度表。
层级维度如何处理
比如一个部门,有自己的父部门,还有自己的子部门。这种层级维度,怎么在维度表中体现?分为有限层级和无限层级。
层级是少量有限
层级少量有限,比如省、市、区、县,最多到村,不可可能无限。对于这种层级,可以在一行中,加如多个字段来显示。
| Province | city | zone | county |
|---|
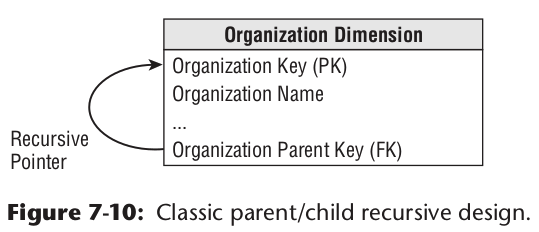
不固定的层级
比如部门这种实体,其层级是不固定的。那通过上述一行中加字段来应对就不现实。这个时候需要通过更抽象的父子关系,来指定两行记录的关系。比如加上parent key:
一些建模规范
打平所有的层级
有些维度信息,本身是多层级,比如产品术语某个品牌,某个品牌属于某个分类。他们都是多对一的关系。我们建一张产品表,不应该也按事务型数据库中的范式来建多张表,而是应该打平层级。方便查询,提高性能,因为维度表数据量一般都很小,不用担心冗余情况。比如一个产品维度表示例如下:
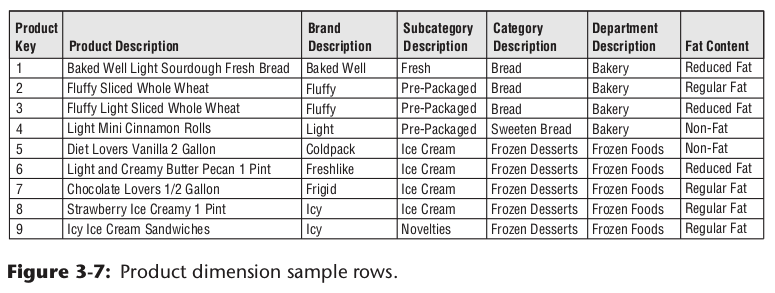
将编码中隐含的信息抽出
有些业务会有业务编码。一个业务编码含有多种信息,比如前2位代表大区,中间2位代表省份等。这种数据,我们除了要存储业务编码外,还要将编码中隐含的信息,分别用字段存放。所有的目的,都是细粒度并且直观的存放各种数据,方便报表的计算,以及提升计算性能。
避免字段为null
如果一个字段,特别是会用作关联的字段,应该尽量避免为Null。因为null会导致表关联,或数据统计,展示时出现一些问题。所以当确实缺失值时,使用一些特殊的值作为替代,比如-1,或则一个文本去填充对应字段。具体到维度字段的null,可以在维度表中创建一条专门用来解释为空的记录,同样用描述性文本填充这条记录。然后在事实表中关联这个id.
退化维度(Degenerate Dimensions)
事实表中的字段,除了存放普通维度表主键外,还可以存放退化维度主键。比如事实表中有一个productId资源,对应的维度表为product表。而事实表中的一条记录对应的业务事件,其在关系型数据库中的的id,或则发票编号等,对报表后需计算依然是有意义的。这种字段我们依然会存放到事实表中,作为一个维度,但它不像产品id一样,有一个标准的维度表,我们称这种情叫退化维度。
没有发生的事实表(Factless Fact Tables)
正常情况下,我们会按实际发生的业务事件来建模,比如有实际购买行为的促销商品记录。其数据模型设计如下:
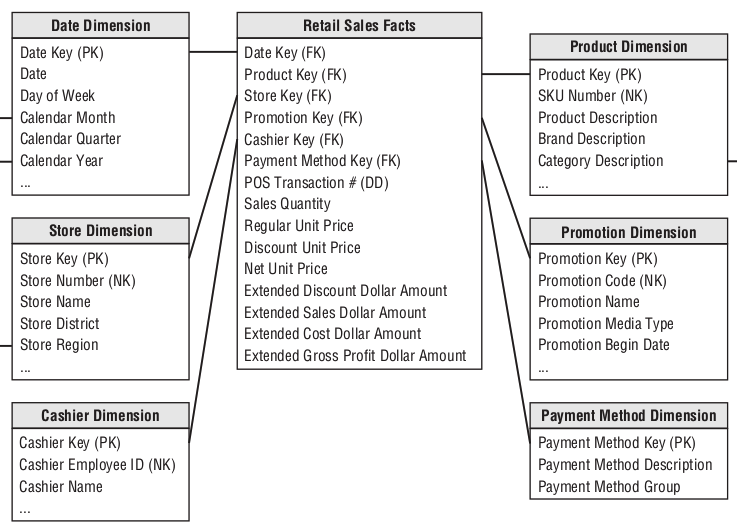
但这种方式的数据模型,但该事实模型无法回答哪一个促销商品在指定日期没有被购买的记录。因为没有被购买,就没有零售记录发生,数据库中根本就没有信息,也就无从统计。这个时候,我们可以增加另外一个事实表,只记录每天参与促销商品的信息。同时再建一个促销维度表,去描述具体的促销信息。模型设计如下:
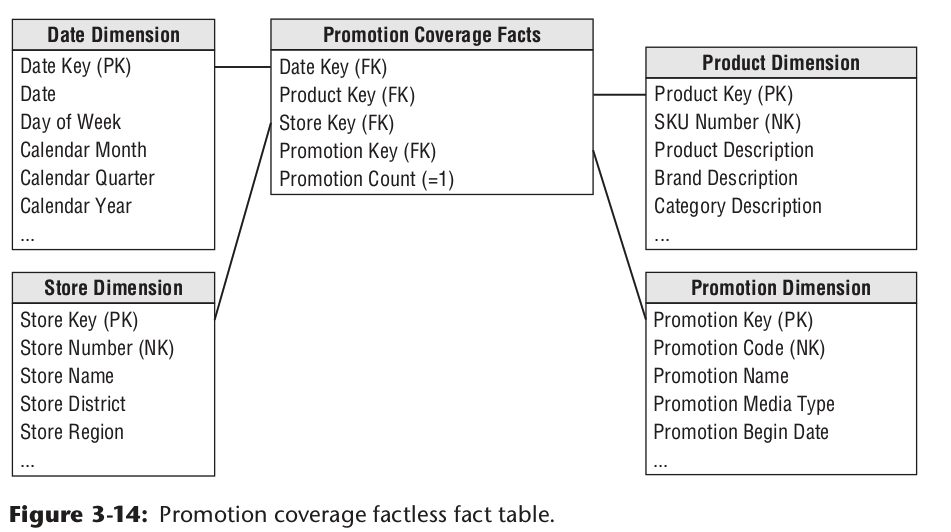
这样为了回答前面的问题,第一步根据日期查询某天去促销事实表中找出当天参与消息的商品。第二步,从最开始建立的实际销售事实表中找出那天实际售卖的商品。这两部数据做一个外关联,就可以解答该问题。
维度表主键(Surrogate Keys)
维度表不要使用操作性数据库中对应的ID,也即不要使用OLTP对应表的id,而要自己生成int类型的id.原因有以下几点。
- OLTP库主要对应线上业务的处理,其中的表结构和业务数据新增、更新频繁,原始OLTP的表可能随着业务量增加而分库分表
- 维度表的数据来源,可能是OLTP中的好几个表,本来就没有一个固定的主键
- 提升性能,维度表的数据本来就不会很多,所以使用int绰绰有余。维度表的id,会被事实表做为外键存储,事实表的数据量往往会很大,选用更小的存储类型更节省存储空间
- 方便做一些OLTP库中不存在的业务记录,比如记录促销维度表,记录一个No Promotion的记录。方便事实表关联。
事实表主键
虽然事实表一条记录可以通过其存储的各维度外键组合一起来唯一确定,但最好还是想维度表主键一样,单独设一个事实表主键,有以下好处:
- 一些处理恢复时,可以记录断点处的主键id来判断恢复量,因为主键一般是有序的
- 快速唯一定位一条事实表记录
- 在多个事实表有父子关系时,可以作为关联键使用
多角色维度表
事实表中可能有多个字段,使用同一个维度表。那最后基于事实表做报表计算将会出现问题。因为不可能join同一张维度表两次。解决办法是基于公用维度表,建不同的维度表,让事实表关联这些新建的维度表,新建的维度表可以是实体表,也可以视图。假设一个事实表有多个字段关联时间维度表,按照这种处理方式的建模示例如下:
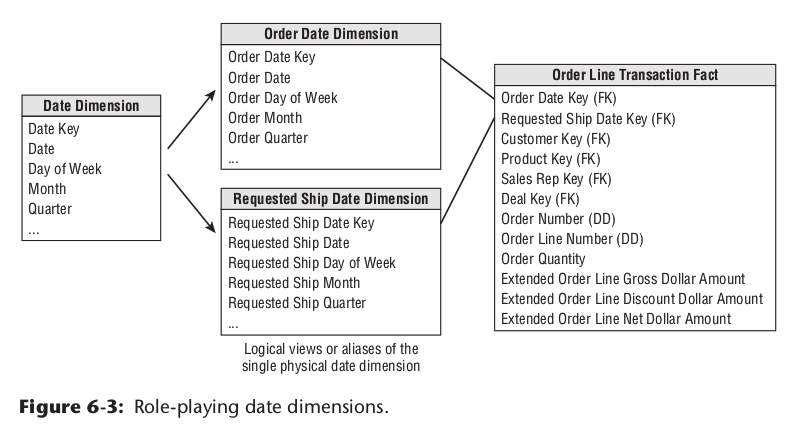
事实表中有多个extend指标属性,其作用是将一些可以提前计算的指标,提前计算出来,提升报表性能,统一计算口径。 前提是这些指标毫无争议,能被广泛使用
事实表泛型粒度
比如订单有订单明细这个业务。
我们可以基于订单明细事实建模型。但订单的总金额怎么分摊到订单明细上,按什么规则分摊?如果不分摊,直接将订单总金额冗余在订单明细上,在有些场景做聚合计算时,会多算金额。
所以最好订单主表事实和明细表事实都做,再将其用主外键关联。同时为了性能考虑,一些不参与计算的订单属性,可以冗余到订单明细,如果只使用订单明细事实表时,不至于关联太多表。下面是一个坏案例,订单的主表的客户信息,没有冗余到明细表
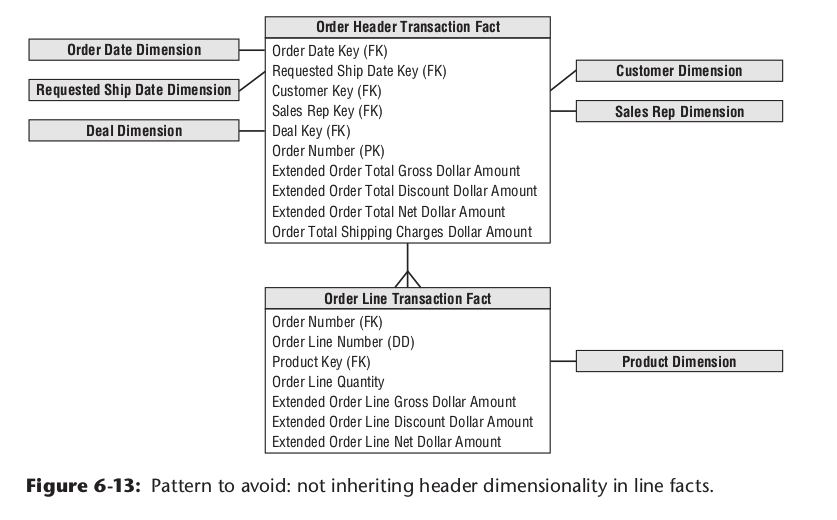
实时计算与数仓
通常数据仓库的数据都是T+1的。但有些业务场景需要实时数据。实时数据又分两种:
- 瞬时(Instantaneous),一般数据数据应用直接接入源数据的变化数据。为了减少数据延迟,中间不经过etl处理。
- 日内(Intra-Day),同普通的T+1数据处理方式一样,只是一天之内多次去源数据拉取,然后走完整的etl流程
对于第二种,也需要建模,但其相关的维度表需要实时响应当天的数据变化
宏观流程
启动会议,确立相关人员职责
包括,业务负责人,业务驱动人员,项目管理人员,数据架构,系统架构,业务用户,开发人员。其中,懂业务的权利负责人确立是非常重要的。因为数仓系统的核心目的,便在于满足业务方的需求。这需要大量了解和梳理业务,需要极富能力和全力的业务负责人。
宏观模型梳理
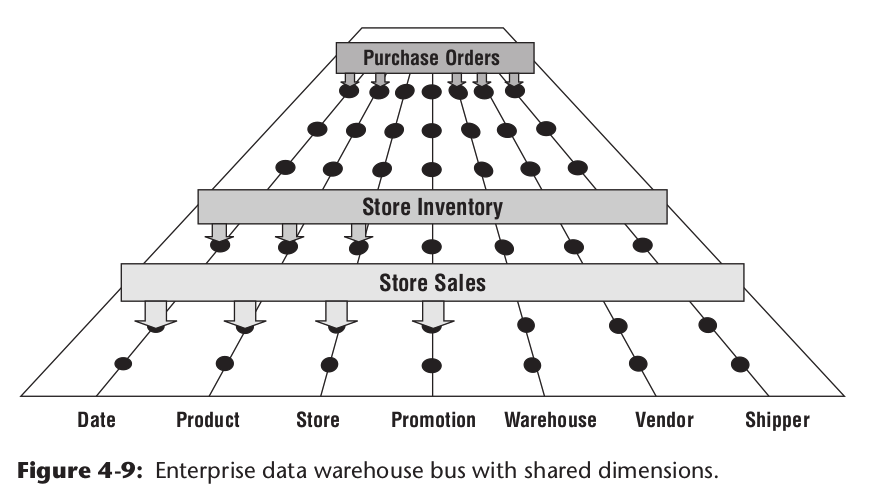
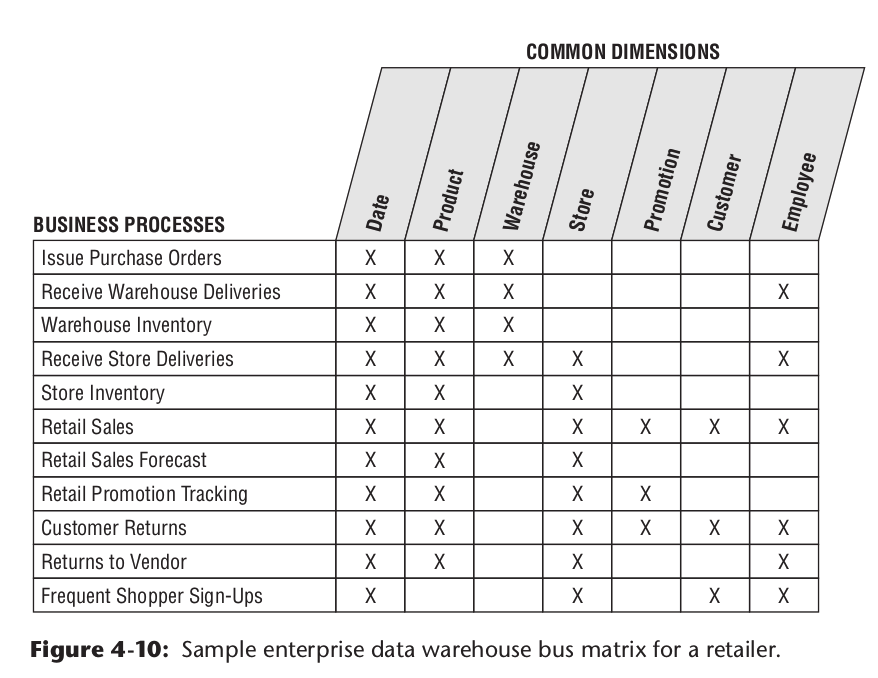
使用矩阵图,对公司的整体业务建模,找出公共维表,统一各种业务术语。
- 如果术语不统一
数仓最终计算出的报表,可能不同团队的名称都不一致,出现歧义,互相不能理解,增加使用者的门槛 - 如果不统一维度
比如时间维度的不一致,比如两个时间维度中的环比时间段不一致,可能导致最终两张报表的同一个指标产出了不同的值。反之,同一了时间维度,使得使用相同维度表的两个事实模型可以join分析
计算选型和建模
培训使用,后期维护升级
统一各种术语
培训各类业务人员相关系统知识,减少信息不对称,并时刻听取他们的难点、痛点、进行系统迭代,升级。
数据质量把控
数据的清洗,数据质量的校验,尽量放到数据架构初始阶段,及早发现问题。
数据质量问题检查主要分为三个部分(Quality Screens):
1、字段质量检查,检查非空字段是否有空值,检查字段数据的格式是否满足要求
2、数据结构检查,比如某两个表有父子关系,需要检查这种父子关系是否存在
3、业务规则检查,比如航空业务,检查源系统给的白金用户,是否飞行里程都达标?
对问题数据的处理有如下几种:
1、中断etl处理进程,不推荐,需要立刻介入解决问题,然后重启
2、记录问题数据和其对应的执行条件,并继续走完etl流程,推荐,可以方便重现问题
对于错误数据的记录
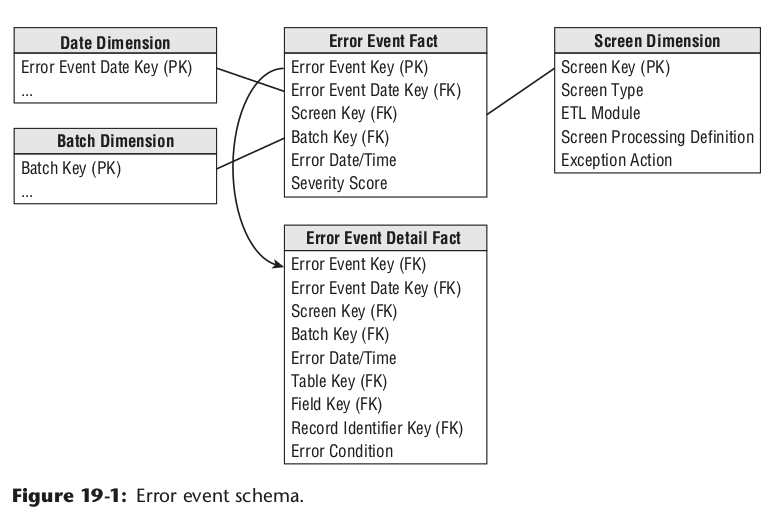
一些踩坑最佳实践

- 基础打牢,我们一般把星型模型放在DWD层,一定要把DWD建好,万丈高楼平地起,后续DWD模型一定要有设计,评审的流程。
- 建设数据质量系统,对数仓各层的数据质量进行监控,及时报警,数据质量管理系统应该嵌入到数仓的每一层
- 建设元数据管理系统,这个是数仓的地图。
- 所有报表开发,原则上,不允许直接使用ODS层的表,这样会导致数据烟囱
如果没有质量管理系统
- 报表质量在用户侧才发现问题,排查需要整条链路去做,排查耗时
- 排查出问题后,重跑数据,重跑耗时
如果没有元数据管理系统
- 没有地图数仓建设会失控,会失控,会抓瞎
- 数仓能力,口口相传,离职就失传
- 无法回答领导的灵魂拷问,做了多少报表? 做了什么报表?数仓有哪些资产?
The Data Warehouse Toolkit 阅读笔记的更多相关文章
- Mongodb Manual阅读笔记:CH3 数据模型(Data Models)
3数据模型(Data Models) Mongodb Manual阅读笔记:CH2 Mongodb CRUD 操作Mongodb Manual阅读笔记:CH3 数据模型(Data Models)Mon ...
- 论文阅读笔记 - Mesos: A Platform for Fine-Grained ResourceSharing in the Data Center
作者:刘旭晖 Raymond 转载请注明出处 Email:colorant at 163.com BLOG:http://blog.csdn.net/colorant/ 更多论文阅读笔记 http:/ ...
- Hadoop阅读笔记(六)——洞悉Hadoop序列化机制Writable
酒,是个好东西,前提要适量.今天参加了公司的年会,主题就是吃.喝.吹,除了那些天生话唠外,大部分人需要加点酒来作催化剂,让一个平时沉默寡言的码农也能成为一个喷子!在大家推杯换盏之际,难免一些画面浮现脑 ...
- Hadoop阅读笔记(三)——深入MapReduce排序和单表连接
继上篇了解了使用MapReduce计算平均数以及去重后,我们再来一探MapReduce在排序以及单表关联上的处理方法.在MapReduce系列的第一篇就有说过,MapReduce不仅是一种分布式的计算 ...
- Hadoop阅读笔记(二)——利用MapReduce求平均数和去重
前言:圣诞节来了,我怎么能虚度光阴呢?!依稀记得,那一年,大家互赠贺卡,短短几行字,字字融化在心里:那一年,大家在水果市场,寻找那些最能代表自己心意的苹果香蕉梨,摸着冰冷的水果外皮,内心早已滚烫.这一 ...
- Hadoop阅读笔记(一)——强大的MapReduce
前言:来园子已经有8个月了,当初入园凭着满腔热血和一脑门子冲动,给自己起了个响亮的旗号“大数据 小世界”,顿时有了种世界都是我的,世界都在我手中的赶脚.可是......时光飞逝,岁月如梭~~~随手一翻 ...
- Mongodb Manual阅读笔记:CH9 Sharding
9.分片(Sharding) Mongodb Manual阅读笔记:CH2 Mongodb CRUD 操作Mongodb Manual阅读笔记:CH3 数据模型(Data Models)Mongodb ...
- Mongodb Manual阅读笔记:CH8 复制集
8 复制 Mongodb Manual阅读笔记:CH2 Mongodb CRUD 操作Mongodb Manual阅读笔记:CH3 数据模型(Data Models)Mongodb Manual阅读笔 ...
- Mongodb Manual阅读笔记:CH7 索引
7索引 Mongodb Manual阅读笔记:CH2 Mongodb CRUD 操作Mongodb Manual阅读笔记:CH3 数据模型(Data Models)Mongodb Manual阅读笔记 ...
随机推荐
- [转]为什么阿里巴巴要禁用Executors创建线程池?
作者:何甜甜在吗 链接:https://juejin.im/post/5dc41c165188257bad4d9e69 来源:掘金 看阿里巴巴开发手册并发编程这块有一条:线程池不允许使用Executo ...
- (恐怕是)写得最通俗易懂的一篇关于HashMap的文章——xx大佬这样说
先看再点赞,给自己一点思考的时间,微信搜索[沉默王二]关注这个有颜值却假装靠才华苟且的程序员. 本文 GitHub github.com/itwanger 已收录,里面还有一线大厂整理的面试题,以及我 ...
- Android 的重要控件 ListView (听说是最难最常用的控件)
这个打字有点慢了,左手受伤了,不过很幸运,左手小拇指没事(这就可以愉快地使用快捷键啦!),虽然有伤,但还是得坚持总结,不只是为自己,还为未来的你们铺路,希望我写的,对你们有帮助. 提前给自己一个祝福: ...
- myBatis源码解析-数据源篇(3)
前言:我们使用mybatis时,关于数据源的配置多使用如c3p0,druid等第三方的数据源.其实mybatis内置了数据源的实现,提供了连接数据库,池的功能.在分析了缓存和日志包的源码后,接下来分析 ...
- WebMvcConfigurerAdapter在2.x向上过时问题
在spring boot2.x向上,书写配置类时集成的WebMvcConfigurerAdapter会显示此类已经过时. 解决:不继承WebMvcConfigurerAdapter类,该实现WebMv ...
- 4、Java基本数据类型
一.基本数据类型 1.基本数据类型 JAVA中一共有八种基本数据类型,他们分别是 byte.short.int.long.float.double.char.boolean 类型 型别 字节 取值范围 ...
- 聊聊Java内省Introspector
前提 这篇文章主要分析一下Introspector(内省,应该读xing第三声,没有找到很好的翻译,下文暂且这样称呼)的用法.Introspector是一个专门处理JavaBean的工具类,用来获取J ...
- golang的树结构三种遍历方式
package main import "log" type node struct { Item string Left *node Right *node } type bst ...
- three.js 制作机房(下)
这一篇书接上文,说一说剩下的一些模块. 1. 机箱存储占用比率 机箱存储占用比其实很简单,就是在机箱上新加一个组即可,然后根据比率值来设置颜色,这个颜色我们去HSL(0.4,0.8,0.5) ~ HS ...
- s2-001漏洞复现
struts2-001 该漏洞因为用户提交表单数据并且验证失败时,后端会将用户之前提交的参数值使用 OGNL 表达式 %{value} 进行解析,然后重新填充到对应的表单数据中.例如注册或登录页面,提 ...