Presto在滴滴的探索与实践

桔妹导读:Presto在滴滴内部发展三年,已经成为滴滴内部Ad-Hoc和Hive SQL加速的首选引擎。目前服务6K+用户,每天读取2PB ~ 3PB HDFS数据,处理30万亿~35万亿条记录,为了承接业务及丰富使用场景,滴滴Presto需要解决稳定性、易用性、性能、成本等诸多问题。我们在3年多的时间里,做了大量优化和二次开发,积攒了非常丰富的经验。本文分享了滴滴对Presto引擎的改进和优化,同时也提供了大量稳定性建设经验。
1. Presto简介
▍1.1 简介
Presto是Facebook开源的MPP(Massive Parallel Processing)SQL引擎,其理念来源于一个叫Volcano的并行数据库,该数据库提出了一个并行执行SQL的模型,它被设计为用来专门进行高速、实时的数据分析。Presto是一个SQL计算引擎,分离计算层和存储层,其不存储数据,通过Connector SPI实现对各种数据源(Storage)的访问。
▍1.2 架构
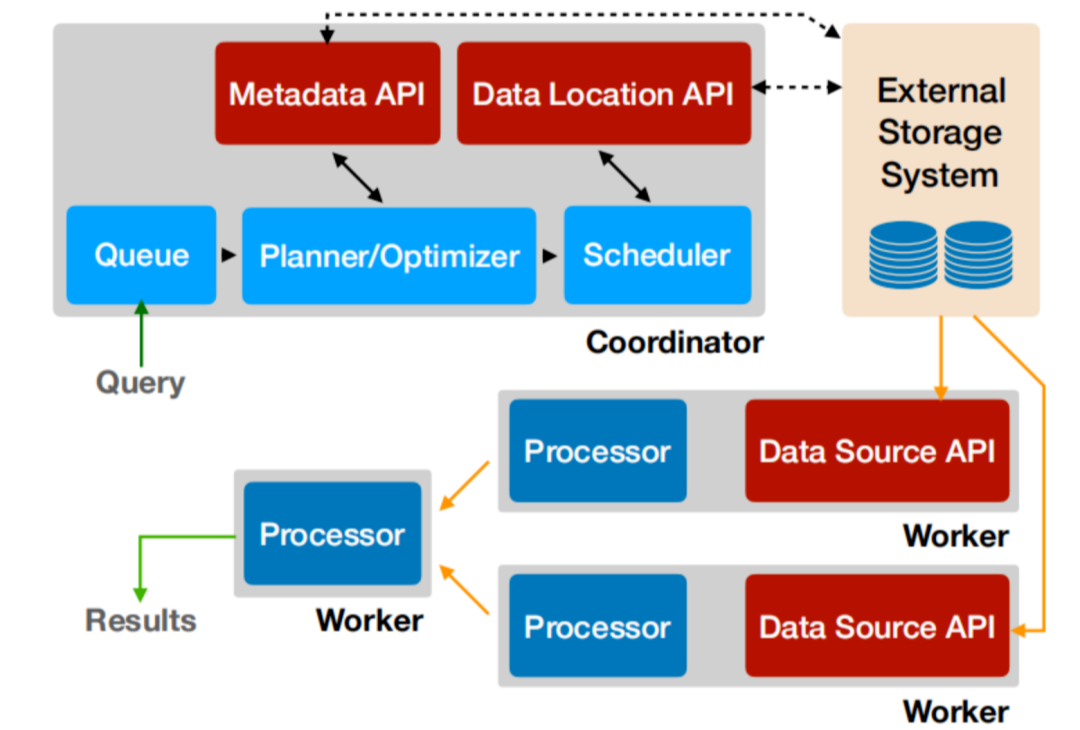
Presto沿用了通用的Master-Slave架构,一个Coordinator,多个Worker。Coordinator负责解析SQL语句,生成执行计划,分发执行任务给Worker节点执行;Worker节点负责实际执行查询任务。Presto提供了一套Connector接口,用于读取元信息和原始数据,Presto 内置有多种数据源,如 Hive、MySQL、Kudu、Kafka 等。同时,Presto 的扩展机制允许自定义 Connector,从而实现对定制数据源的查询。假如配置了Hive Connector,需要配置一个Hive MetaStore服务为Presto提供Hive元信息,Worker节点通过Hive Connector与HDFS交互,读取原始数据。
▍1.3
实现低延时原理**Presto是一个交互式查询引擎,我们最关心的是Presto实现低延时查询的原理,以下几点是其性能脱颖而出的主要原因:
- 完全基于内存的并行计算
- 流水线
- 本地化计算
- 动态编译执行计划
- 小心使用内存和数据结构
- GC控制
- 无容错
2. Presto在滴滴的应用
▍2.1 业务场景
- Hive SQL查询加速
- 数据平台Ad-Hoc查询
- 报表(BI报表、自定义报表)
- 活动营销
- 数据质量检测
- 资产管理
- 固定数据产品

▍2.2 业务规模

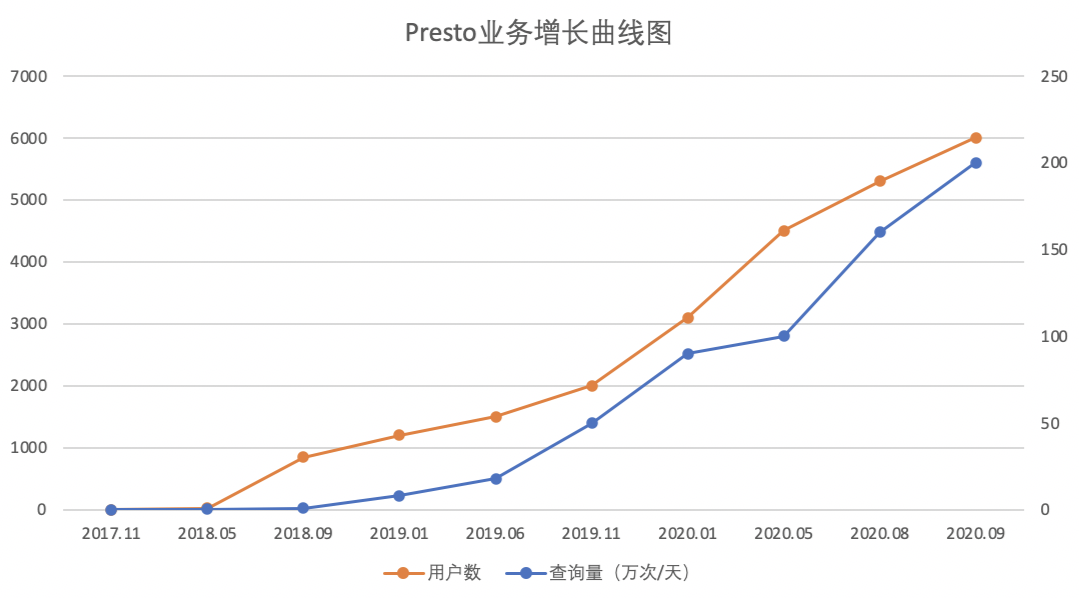
▍2.3 业务增长
▍2.4 集群部署

目前Presto分为混合集群和高性能集群,如上图所示,混合集群共用HDFS集群,与离线Hadoop大集群混合部署,为了防止集群内大查询影响小查询, 而单独搭建集群会导致集群太多,维护成本太高,我们通过指定Label来做到物理集群隔离(详细后文会讲到)。而高性能集群,HDFS是单独部署的,且可以访问Druid, 使Presto 具备查询实时数据和离线数据能力。
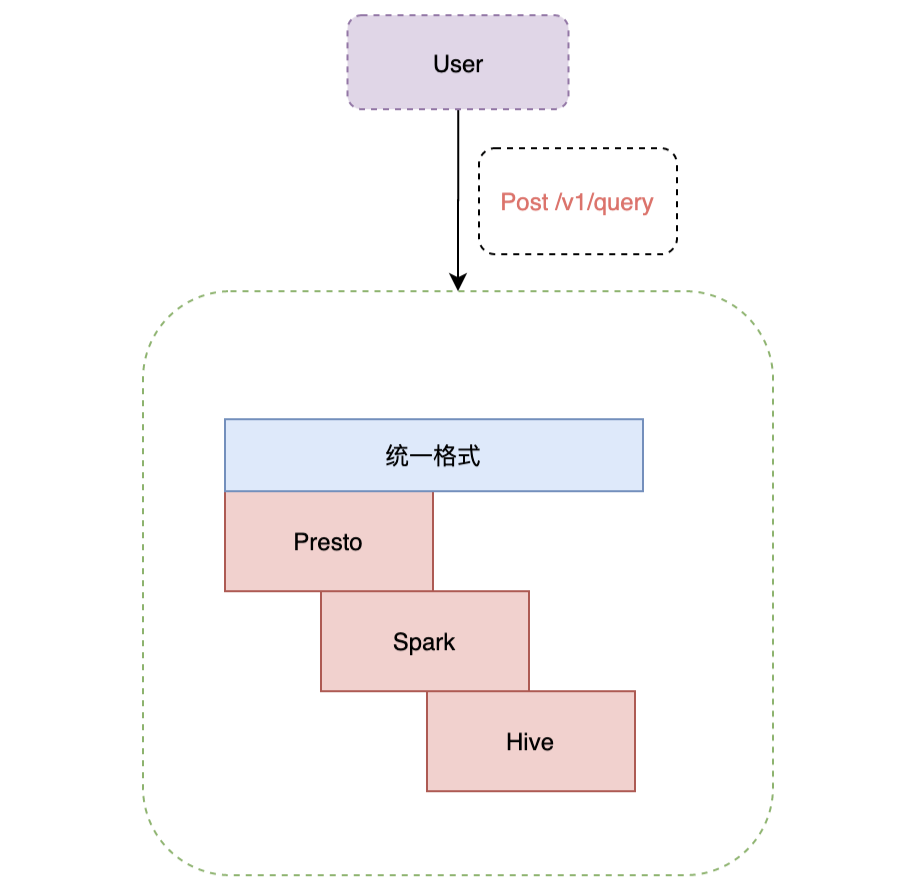
▍2.5 接入方式
二次开发了JDBC、Go、Python、Cli、R、NodeJs 、HTTP等多种接入方式,打通了公司内部权限体系,让业务方方便快捷的接入 Presto 的,满足了业务方多种技术栈的接入需求。Presto 接入了查询路由 Gateway,Gateway会智能选择合适的引擎,用户查询优先请求Presto,如果查询失败,会使用Spark查询,如果依然失败,最后会请求Hive。在Gateway层,我们做了一些优化来区分大查询、中查询及小查询,对于查询时间小于3分钟的,我们即认为适合Presto查询,比如通过HBO(基于历史的统计信息)及JOIN数量来区分查询大小,架构图见:
3. 引擎迭代
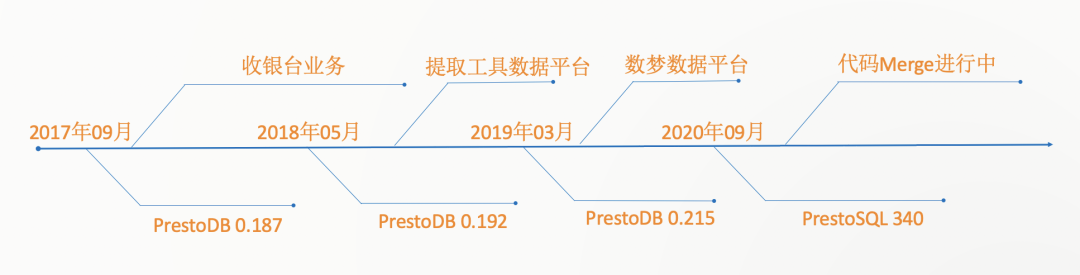
我们从2017年09月份开始调研Presto,经历过0.192、0.215,共发布56次版本。而在19年初(0.215版本是社区分家版本),Presto社区分家,分为两个项目,叫PrestoDB和PrestoSQL,两者都成立了自己的基金会。我们决定升级到PrestoSQL 最新版本(340版本)原因是:
- PrestoSQL社区活跃度更高,PR和用户问题能够及时回复
- PrestoDB主要主力还是Facebook维护,以其内部需求为主
- PrestoDB未来方向主要是ETL相关的,我们有Spark兜底,ETL功能依赖Spark、Hive
4. 引擎改进
在滴滴内部,Presto主要用于Ad-Hoc查询及Hive SQL查询加速,为了方便用户能尽快将SQL迁移到Presto引擎上,且提高Presto引擎查询性能,我们对Presto做了大量二次开发。同时,因为使用Gateway,即使SQL查询出错,SQL也会转发到Spark及Hive上,所以我们没有使用Presto的Spill to Disk功能。这样一个纯内存SQL引擎在使用过程中会遇到很多稳定问题,我们在解决这些问题时,也积累了很多经验,下面将一一介绍:
▍4.1 Hive SQL兼容
18年上半年,Presto刚起步,滴滴内部很多用户不愿意迁移业务,主要是因为Presto是ANSI SQL,与HiveQL差距较大,且查询结果也会出现结果不一致问题,迁移成本比较高,为了方便Hive用户能顺利迁移业务,我们对Presto做了Hive SQL兼容。而在技术选型时,我们没有在Presto上层,即没有在Gateway这层做SQL兼容,主要是因为开发量较大,且UDF相关的开发和转换成本太高,另外就是需要多做一次SQL解析,查询性能会受到影响,同时增加了Hive Metastore的请求次数,当时Hive Metastore的压力比较大,考虑到成本和稳定性,我们最后选择在Presto引擎层上兼容。
主要工作:
- 隐式类型转换
- 语义兼容
- 语法兼容
- 支持Hive视图
- Parquet HDFS文件读取支持
- 大量UDF支持
- 其他
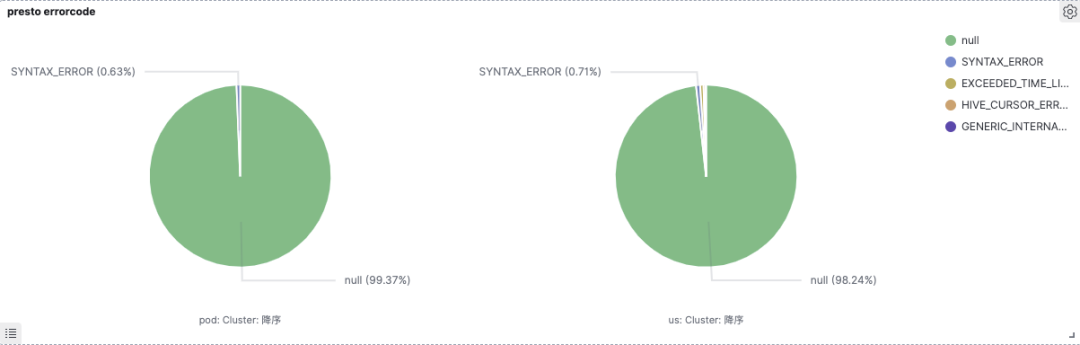
Hive SQL兼容,我们迭代了三个大版本,目前线上SQL通过率9799%。而业务从Spark/Hive迁移到Presto后,查询性能平均提升30%50%,甚至一些场景提升10倍,Ad-Hoc场景共节省80%机器资源。下图是线上Presto集群的SQL查询通过率及失败原因占比,'null' 表示查询成功的SQL,其他表示错误原因:
▍4.2 物理资源隔离
上文说到,对性能要求高的业务与大查询业务方混合跑,查询性能容易受到影响,只有单独搭建集群。而单独搭建集群导致Presto集群太多,维护成本太高。因为目前我们Presto Coordinator还没有遇到瓶颈,大查询主要影响Worker性能,比如一条大SQL导致Worker CPU打满,导致其他业务方SQL查询变慢。所以我们修改调度模块,让Presto支持可以动态打Label,动态调度指定的 Label 机器。如下图所示:
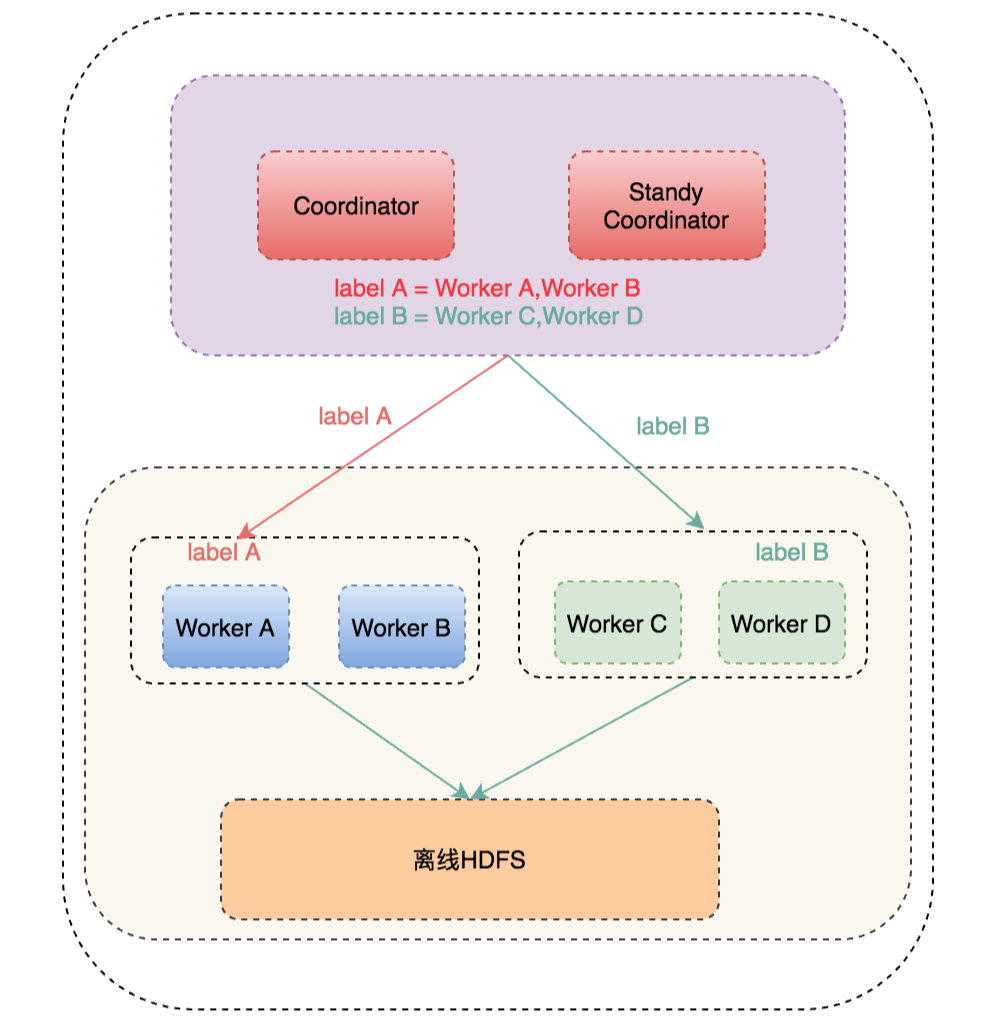
根据不同的业务划分不同的label,通过配置文件配置业务方指定的label和其对应的机器列表,Coordinator会加载配置,在内存里维护集群label信息,同时如果配置文件里label信息变动,Coordinator会定时更新label信息,这样调度时根据SQL指定的label信息来获取对应的Worker机器,如指定label A时,那调度机器里只选择Worker A 和 Worker B 即可。这样就可以做到让机器物理隔离了,对性能要求高的业务查询既有保障了。
▍4.3 Druid Connector
使用 Presto + HDFS 有一些痛点:
- latency高,QPS较低
- 不能查实时数据,如果有实时数据需求,需要再构建一条实时数据链路,增加了系统的复杂性
- 要想获得极限性能,必须与HDFS DataNode 混部,且DataNode使用高级硬件,有自建HDFS的需求,增加了运维的负担
所以我们在0.215版本实现了Presto on Druid Connector,此插件有如下优点:
- 结合 Druid 的预聚合、计算能力(过滤聚合)、Cache能力,提升Presto性能(RT与QPS)
- 让 Presto 具备查询 Druid 实时数据能力
- 为Druid提供全面的SQL能力支持,扩展Druid数据的应用场景
- 通过Druid Broker获取Druid元数据信息
- 从Druid Historical直接获取数据
- 实现了Limit下推、Filter下推、Project下推及Agg下推
在PrestoSQL 340版本,社区也实现了Presto on Druid Connector,但是此Connector是通过JDBC实现的,缺点比较明显:
- 无法划分多个Split,查询性能差
- 请求查询Broker,之后再查询Historical,多一次网络通信
- 对于一些场景,如大量Scan场景,会导致Broker OOM
- Project及Agg下推支持不完善
详细架构图见:
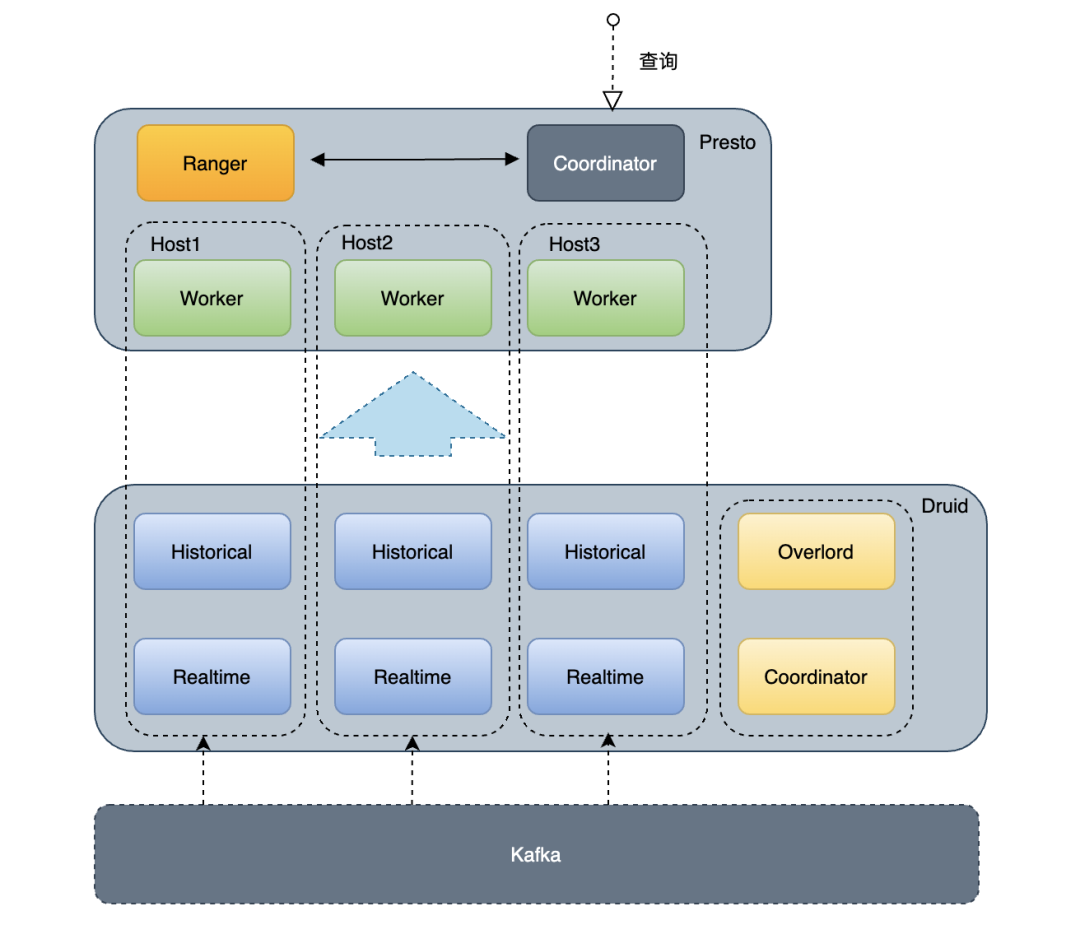
使用了Presto on Druid后,一些场景,性能提升4~5倍。▍4.4 易用性建设为了支持公司的几个核心数据平台,包括:数梦、提取工具、数易及特征加速及各种散户,我们对Presto做了很多二次开发,包括权限管理、语法支持等,保证了业务的快速接入。主要工作:
- 租户与权限
- 与内部Hadoop打通,使用HDFS SIMPLE协议做认证
- 使用Ranger做鉴权,解析SQL使Presto拥有将列信息传递给下游的能力,提供用户名+数据库名/表名/列名,四元组的鉴权能力,同时提供多表同时鉴权的能力
- 用户指定用户名做鉴权和认证,大账号用于读写HDFS数据
- 支持视图、表别名鉴权
- 语法拓展
- 支持add partition
- 支持数字开头的表
- 支持数字开头的字段
- 特性增强
- insert数据时,将插入数据的总行数写入HMS,为业务方提供毫秒级的元数据感知能力
- 支持查询进度滚动更新,提升了用户体验
- 支持查询可以指定优先级,为用户不同等级的业务提供了优先级控制的能力
- 修改通信协议,支持业务方可以传达自定义信息,满足了用户的日志审计需要等
- 支持DeprecatedLzoTextInputFormat格式
- 支持读HDFS Parquet文件路径
▍4.5 稳定性建设
Presto在使用过程中会遇到很多稳定性问题,比如Coordinator OOM,Worker Full GC等,为了解决和方便定位这些问题,首先我们做了监控体系建设,主要包括:
- 通过Presto Plugin实现日志审计功能
- 通过JMX获取引擎指标将监控信息写入Ganglia
- 将日志审计采集到HDFS和ES;统一接入运维监控体系,将所有指标发到 Kafka;
- Presto UI改进:可以查看Worker信息,可以查看Worker死活信息
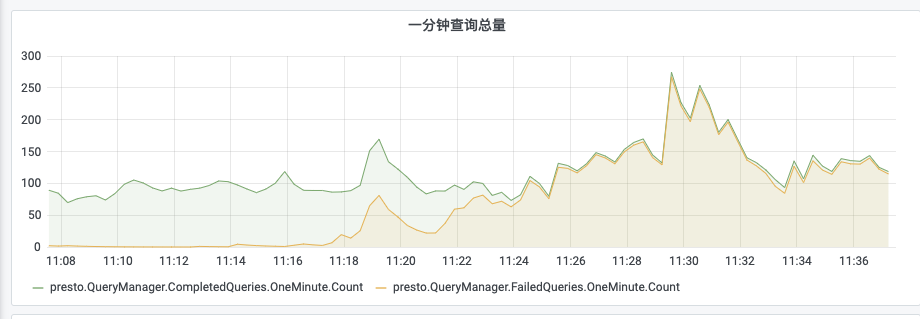
通过以上功能,在每次出现稳定性问题时,方便我们及时定位问题,包括指标查看及SQL回放等,如下图所示,可以查看某集群的成功及失败SQL数,我们可以通过定义查询失败率来触发报警:
在Presto交流社区,Presto的稳定性问题困扰了很多Presto使用者,包括Coordinator和Worker挂掉,集群运行一段时间后查询性能变慢等。我们在解决这些问题时积累了很多经验,这里说下解决思路和方法。
根据职责划分,Presto分为Coordinator和Worker模块,Coordinator主要负责SQL解析、生成查询计划、Split调度及查询状态管理等,所以当Coordinator遇到OOM或者Coredump时,获取元信息及生成Splits是重点怀疑的地方。而内存问题,推荐使用MAT分析具体原因。如下图是通过MAT分析,得出开启了FileSystem Cache,内存泄漏导致OOM。
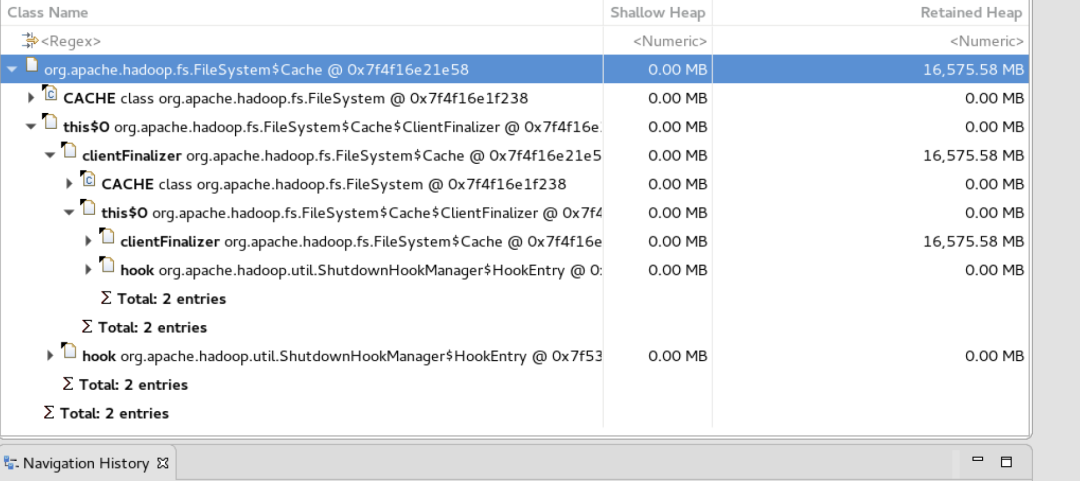
这里我们总结了Coordinator常见的问题和解决方法:
- 使用HDFS FileSystem Cache导致内存泄漏,解决方法禁止FileSystem Cache,后续Presto自己维护了FileSystem Cache
- Jetty导致堆外内存泄漏,原因是Gzip导致了堆外内存泄漏,升级Jetty版本解决
- Splits太多,无可用端口,TIME_WAIT太高,修改TCP参数解决
- JVM Coredump,显示"unable to create new native thread",通过修改pid_max及max_map_count解决
- Presto内核Bug,查询失败的SQL太多,导致Coordinator内存泄漏,社区已修复
而Presto Worker主要用于计算,性能瓶颈点主要是内存和CPU。内存方面通过三种方法来保障和查找问题:
- 通过Resource Group控制业务并发,防止严重超卖
- 通过JVM调优,解决一些常见内存问题,如Young GC Exhausted
- 善用MAT工具,发现内存瓶颈
而Presto Worker常会遇到查询变慢问题,两方面原因,一是确定是否开启了Swap内存,当Free内存不足时,使用Swap会严重影响查询性能。第二是CPU问题,解决此类问题,要善用Perf工具,多做Perf来分析CPU为什么不在干活,看CPU主要在做什么,是GC问题还是JVM Bug。如下图所示,为线上Presto集群触发了JVM Bug,导致运行一段时间后查询变慢,重启后恢复,Perf后找到原因,分析JVM代码,可通过JVM调优或升级JVM版本解决:

这里我们也总结了Worker常见的问题和解决方法:
- Sys load过高,导致业务查询性能影响很大,研究jvm原理,通过参数(-XX:PerMethodRecompilationCutoff=10000 及 -XX:PerBytecodeRecompilationCutoff=10000)解决,也可升级最新JVM解决
- Worker查询hang住问题,原因HDFS客户端存在bug,当Presto与HDFS混部署,数据和客户端在同一台机器上时,短路读时一直wait锁,导致查询Hang住超时,Hadoop社区已解决
- 超卖导致Worker Young GC Exhausted,优化GC参数,如设置-XX:G1ReservePercent=25 及 -XX:InitiatingHeapOccupancyPercent=15
- ORC太大,导致Presto读取ORC Stripe Statistics出现OOM,解决方法是限制ProtoBuf报文大小,同时协助业务方合理数据治理
- 修改Presto内存管理逻辑,优化Kill策略,保障当内存不够时,Presto Worker不会OOM,只需要将大查询Kill掉,后续熔断机制会改为基于JVM,类似ES的熔断器,比如95% JVM 内存时,Kill掉最大SQL
▍4.6 引擎优化及调研
作为一个Ad-Hoc引擎,Presto查询性能越快,用户体验越好,为了提高Presto的查询性能,在Presto on Hive场景,我们做了很多引擎优化工作,主要工作:
- 某业务集群进行了JVM调优,将Ref Proc由单线程改为并行执行,普通查询由30S~1分钟降低为3-4S,性能提升10倍+
- ORC数据优化,将指定string字段添加了布隆过滤器,查询性能提升20-30%,针对一些业务做了调优
- 数据治理和小文件合并,某业务方查询性能由20S降低为10S,性能提升一倍,且查询性能稳定
- ORC格式性能优化,查询耗时减少5%
- 分区裁剪优化,解决指定分区但获取所有分区元信息问题,减少了HMS的压力
- 下推优化,实现了Limit、Filter、Project、Agg下推到存储层
18年我们为了提高Presto查询性能,也调研了一些技术方案,包括Presto on Alluxio和Presto on Carbondata,但是这2种方案最后都被舍弃了,原因是:
- Presto on Alluxio查询性能提升35%,但是内存占用和性能提升不成正比,所以我们放弃了Presto on Alluxio,后续可能会对一些性能要求敏感的业务使用
- Presto on Carbondata是在18年8月份测试的,当时的版本,Carbondata稳定性较差,性能没有明显优势,一些场景ORC更快,所以我们没有再继续跟踪调研Presto on Carbondata。因为滴滴有专门维护Druid的团队,所以我们对接了Presto on Druid,一些场景性能提升4~5倍,后续我们会更多关注Presto on Clickhouse及Presto on Elasticsearch
5. 总结
通过以上工作,滴滴Presto逐渐接入公司各大数据平台,并成为了公司首选Ad-Hoc查询引擎及Hive SQL加速引擎,下图可以看到某产品接入后的性能提升:
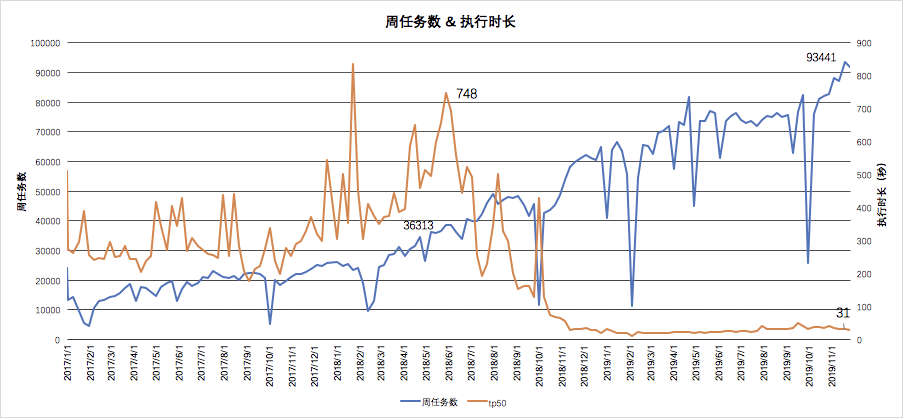
上图可以看到大约2018年10月该平台开始接入Presto,查询耗时TP50性能提升了10+倍,由400S降低到31S。且在任务数逐渐增长的情况下,查询耗时保证稳定不变。
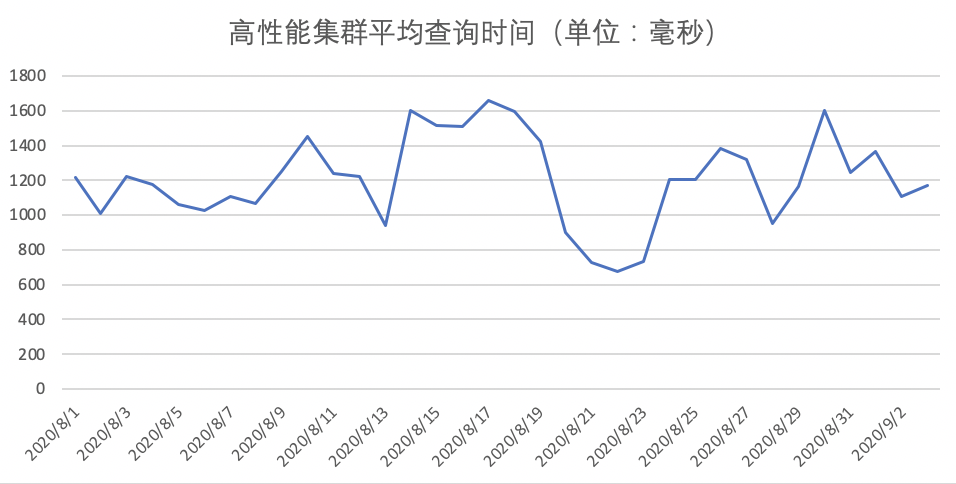
而高性能集群,我们做了很多稳定性和性能优化工作,保证了平均查询时间小于2S。如下图所示:
6. 展望
Presto主要应用场景是Ad-Hoc查询,所以其高峰期主要在白天,如下图所示,是网约车业务下午12-16点的查询,可以看到平均CPU使用率在40%以上。

但是如果看最近一个月的CPU使用率会发现,平均CPU使用率比较低,且波峰在白天10~18点,晚上基本上没有查询,CPU使用率不到5%。如下图所示:
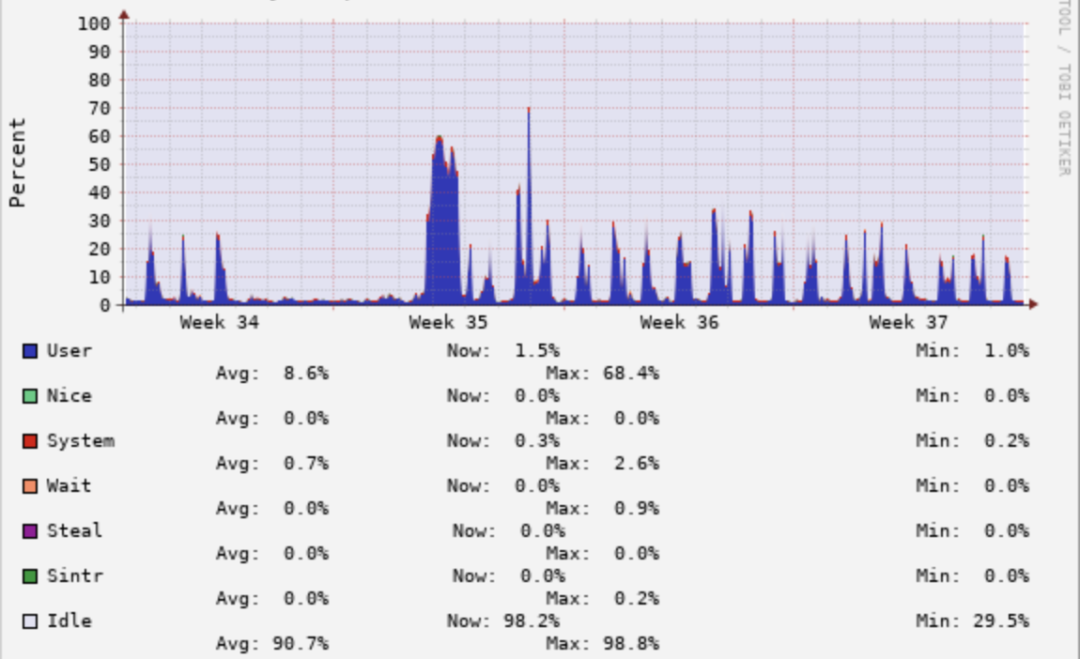
所以,解决晚上资源浪费问题是我们今后需要解决的难题。
同时,为了不与开源社区脱节,我们打算升级PrestoDB 0.215到PrestoSQL 340版本,届时会把我们的Presto on Druid代码开源出来,回馈社区。
本文作者

滴滴Presto引擎负责人,负责带领引擎团队深入Presto内核,解决在海量数据规模下Presto遇到的稳定性、性能、成本方面的问题。搜索引擎及OLAP引擎爱好者,公众号:FFCompute
关于团队
滴滴大数据架构部 OLAP & 检索平台组负责以 Elasticsearch、Clickhouse、Presto 及 Druid 为代表的 OLAP 引擎的内核级极致优化,为滴滴各个产品线提供稳定可靠的 PB 级海量数据的实时数据分析、日志检索、监控及即席查询服务。
博闻强识,招贤纳士,滴滴用广阔的舞台,在这里,等待你!

延伸阅读



内容编辑 | Charlotte
联系我们 | DiDiTech@didiglobal.com

滴滴技术 出品
Presto在滴滴的探索与实践的更多相关文章
- NSIS:应用软件自动升级功能的探索与实践
原文 NSIS:应用软件自动升级功能的探索与实践 记得以前轻狂曾分享过使用第三方软件实现应用软件自动升级功能 (详细http://www.flighty.cn/html/soft/20110106_1 ...
- FFM及DeepFFM模型在推荐系统的探索及实践
12月20日至23日,全球人工智能与机器学习技术大会 AiCon 2018 在北京国际会议中心盛大举行,新浪微博AI Lab 的资深算法专家 张俊林@张俊林say 主持了大会的 搜索推荐与算法专题,并 ...
- FPGA加速:面向数据中心和云服务的探索和实践
欢迎大家前往腾讯云+社区,获取更多腾讯海量技术实践干货哦~ 本文由columneditor 发表于云+社区专栏 作者介绍:章恒--腾讯云FPGA专家,目前在腾讯架构平台部负责FPGA云的研发工作,探索 ...
- 从C10K到C10M高性能网络的探索与实践
在高性能网络的场景下,C10K是一个具有里程碑意义的场景,15年前它给互联网领域带来了非常大的挑战.发展至今,我们已经进入C10M的场景进行网络性能优化. 这期间有怎样的发展和趋势?环绕着各类指标分别 ...
- zz深度学习在美团配送 ETA 预估中的探索与实践
深度学习在美团配送 ETA 预估中的探索与实践 比前一版本有改进: 基泽 周越 显杰 阅读数:32952019 年 4 月 20 日 1. 背景 ETA(Estimated Time of A ...
- 深度学习在高德ETA应用的探索与实践
1.导读 驾车导航是数字地图的核心用户场景,用户在进行导航规划时,高德地图会提供给用户3条路线选择,由用户根据自身情况来决定按照哪条路线行驶. 同时各路线的ETA(estimated time of ...
- 国产开源数据库:腾讯云TBase在分布式HTAP领域的探索与实践
导语 | TBase 是腾讯TEG数据平台团队在开源 PostgreSQL 的基础上研发的企业级分布式 HTAP 数据库系统,可在同一数据库集群中同时为客户提供强一致高并发的分布式在线事务能力以及高 ...
- 网络Devops探索与实践 流程管理分析师
https://mp.weixin.qq.com/s/OKLiDi78uB8ZkPG2kUVxvA 网络Devops探索与实践 王镇 鹅厂网事 2020-09-23 9月16日举办的2020 ODC ...
- 涂鸦基于OAuth2在开发者平台上的探索与实践
前言 开发授权(OAuth2)是一个开放标准,允许用户让第三方应用访问该用户在某一网站上存储的私密的资料(如照片.视频.联系人列表),而无需将用户名和密码提供给第三方应用. OAuth2允许用户提供一 ...
随机推荐
- 20190923-01Linux帮助命令 000 009
man 获得帮助信息 1. 基本语法 man [命令或配置文件] (功能描述:获得帮助信息) 2.显示说明 表1-6 信息 功能 NAME 命令的名称和单行描述 SYNOPSIS 怎样使用命令 DES ...
- 10行实现最短路算法——Dijkstra
今天是算法数据结构专题的第34篇文章,我们来继续聊聊最短路算法. 在上一篇文章当中我们讲解了bellman-ford算法和spfa算法,其中spfa算法是我个人比较常用的算法,比赛当中几乎没有用过其他 ...
- 7.SwrContext音频重采样使用
头文件位于#include <libswresample/swresample.h> SwrContext常用函数如下所示 SwrContext *swr_alloc(void); / ...
- git多账号使用
1 背 景 在公司上班的员工会同时拥有两个git账号, 一个是公司内部的, 仅允许工作时使用; 另一个是个人的, 常用于日常的学习记录. 此时, 面临的问题是如何在一台电脑(客户端)上正常使用两个账号 ...
- css3 压缩及验证工具
1.css w3c统一验证工具 网址:http://www.csstats.com/ 如果你想要更全面的,这个神奇,你值得拥有: w3c统一验证工具:http://validator.w3.org/u ...
- vue项目Windows Server服务器部署IIS设置Url重写
1.将vue项目使用npm run build命令打包后将dist文件夹内的文件全部拷贝到服务器. 2.IIS添加应用程序池,.NET CLR版本选择无托管代码 3.添加网站,应用程序池选择刚刚添加的 ...
- 典藏版Web功能测试用例库
界面显示 初始界面元素:title.内容,默认值.必填项(红*) 样式美观 排版规范 字体统一 编辑页面有光标,定位在第一个可编辑文本框 内容过多时,滚动条 loading ...
- Arnold变换(猫脸变换)
Arnold变换是Arnold在遍历理论研究中提出的一种变换.由于Arnold本人最初对一张猫的图片进行了此种变换,因此它又被称为猫脸变换.Arnold变换可以对图像进行置乱,使得原本有意义的图像变成 ...
- Python爬虫开发者工具介绍
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,如有问题请及时联系我们以作处理. chrome 开发者工具 当我们爬取不同的网站时,每个网站页面的实现方式各不相同,我们需要对 ...
- 灵活使用 SQLAlchemy 中的 ORM 查询
之前做查询一直觉得直接拼 SQL 比较方便,用了 SQLAlchemy 的 ORM 查询之后,发现也还可以,还提高了可读性. 这篇文章主要说说 SQLAlchemy 常用的 ORM 查询方式,偏实践. ...