pandas聚合和分组运算之groupby
pandas提供了一个灵活高效的groupby功能,它使你能以一种自然的方式对数据集进行切片、切块、摘要等操作。根据一个或多个键(可以是函数、数组或DataFrame列名)拆分pandas对象。计算分组摘要统计,如计数、平均值、标准差,或用户自定义函数。对DataFrame的列应用各种各样的函数。应用组内转换或其他运算,如规格化、线性回归、排名或选取子集等。计算透视表或交叉表。执行分位数分析以及其他分组分析。
1、首先来看看下面这个非常简单的表格型数据集(以DataFrame的形式):
import pandas as pd
import numpy as np
df = pd.DataFrame({'key1':['a', 'a', 'b', 'b', 'a'],
'key2':['one', 'two', 'one', 'two', 'one'],
'data1':np.random.randn(5),
'data2':np.random.randn(5)})
df

2.按key1进行分组,并计算data1列的平均值,我们可以访问data1,并根据key1调用groupby:
grouped = df['data1'].groupby(df['key1'])
grouped
变量grouped是一个GroupBy对象,它实际上还没有进行任何计算,只是含有一些有关分组键df['key1']的中间数据而已,然后我们可以调用GroupBy的mean方法来计算分组平均值:
grouped.mean()
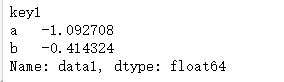
说明:数据(Series)根据分组键进行了聚合,产生了一个新的Series,其索引为key1列中的唯一值。之所以结果中索引的名称为key1,是因为原始DataFrame的列df['key1']就叫这个名字
3、如果我们一次传入多个数组,就会得到不同的结果:
means = df['data1'].groupby([df['key1'], df['key2']]).mean()
means

通过两个键对数据进行了分组,得到的Series具有一个层次化索引(由唯一的键对组成):
然后我用unstack 把他的二阶索引摊开:

在上面这些示例中,分组键均为Series。实际上,分组键可以是任何长度适当的数组:
states = np.array(['Ohio', 'California', 'California', 'Ohio', 'Ohio'])
years = np.array([2005, 2005, 2006, 2005, 2006])
df['data1'].groupby([states, years]).mean() 结果:
California 2005 -2.120793
2006 0.642216
Ohio 2005 0.282230
2006 -1.017495
dtype: float64
4、还可以将列名(可以是字符串、数字或其他Python对象)用作分组将:
df.groupby('key1').mean()

df.groupby(['key1', 'key2']).mean()
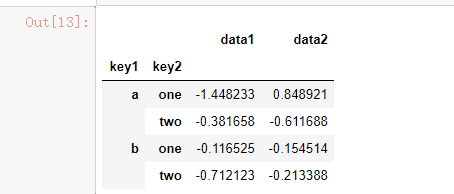
说明:在执行df.groupby('key1').mean()时,结果中没有key2列。这是因为df['key2']不是数值数据,所以被从结果中排除了。
默认情况下,所有数值列都会被聚合,虽然有时可能会被过滤为一个子集。
无论你准备拿groupby做什么,都有可能会用到GroupBy的size方法,它可以返回一个含有分组大小的Series:
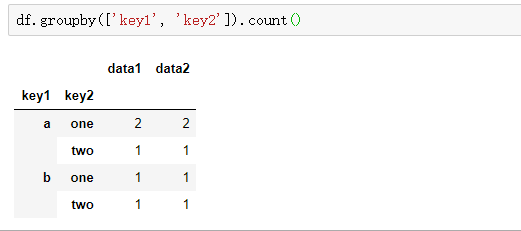
df1=df.groupby(['key1', 'key2']).size()
print(df1)
print(type(df1))

注意:分组键中的任何缺失值都会被排除在结果之外。
区别于:
5、对分组进行迭代
GroupBy对象支持迭代,可以产生一组二元元组(由分组名和数据块组成)。看看下面这个简单的数据集:
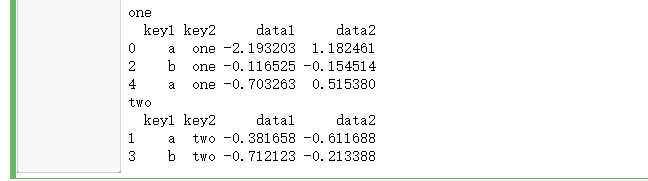
for name, group in df.groupby('key2'):
print(name)
print(group)
对于多重键的情况,元组的第一个元素将会是由键值组成的元组:
for (k1, k2), group in df.groupby(['key1', 'key2']):
print(k1, k2)
print(group)

当然,你可以对这些数据片段做任何操作。有一个你可能会觉得有用的运算:将这些数据片段做成一个字典:
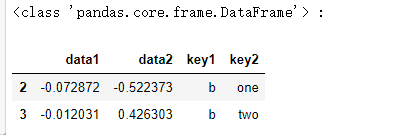
pieces = dict(list(df.groupby('key1')))
print(type(pieces['b']),':')
pieces['b']
l1=list(df.groupby('key1'))
print("l1:","\n",l1)
print(type(l1[][]))
l1[][]
groupby默认是在axis=0上进行分组的,通过设置也可以在其他任何轴上进行分组。
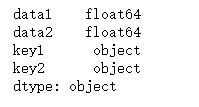
那上面例子中的df来说,我们可以根据dtype对列进行分组:
df.dtypes
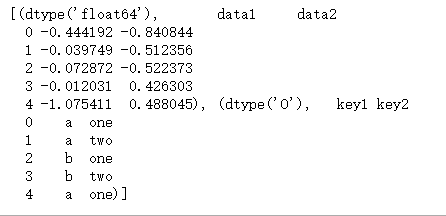
grouped = df.groupby(df.dtypes, axis=1)
dict(list(grouped))

list(grouped)
6、选取一个或一组列
对于由DataFrame产生的GroupBy对象,如果用一个(单个字符串)或一组(字符串数组)列名对其进行索引,就能实现选取部分列进行聚合的目的,即:
df['data1'].groupby([df['key1']]) df[['data2']].groupby([df['key1']]) df['data2'].groupby([df['key1']])
和以下代码是等效的:
df['data1'].groupby([df['key1']]) df[['data2']].groupby([df['key1']]) df['data2'].groupby([df['key1']])
尤其对于大数据集,很可能只需要对部分列进行聚合。
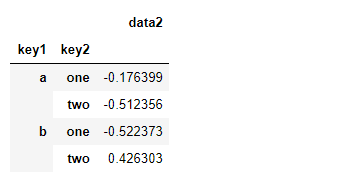
例如,在前面那个数据集中,如果只需计算data2列的平均值并以DataFrame形式得到结果,代码如下:
df.groupby(['key1', 'key2'])[['data2']].mean()
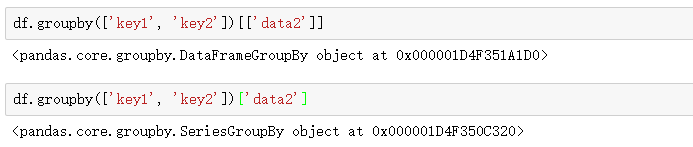
df.groupby(['key1', 'key2'])['data2'].mean()

这种索引操作所返回的对象是一个已分组的DataFrame(如果传入的是列表或数组)或已分组的Series(如果传入的是标量形式的单个列明):
7、通过字典或Series进行分组
除数组以外,分组信息还可以其他形式存在,来看一个DataFrame示例:
people = pd.DataFrame(np.random.randn(5, 5),
columns=['a', 'b', 'c', 'd', 'e'],
index=['Joe', 'Steve', 'Wes', 'Jim', 'Travis']
)
people

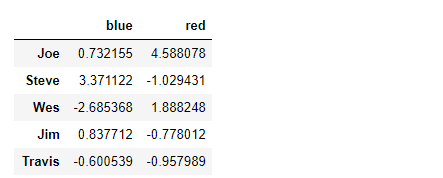
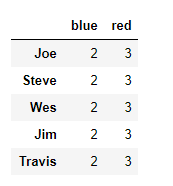
mapping = {'a':'red', 'b':'red', 'c':'blue', 'd':'blue', 'e':'red', 'f':'orange'}
by_column = people.groupby(mapping, axis=1)
by_column
by_column.sum()
Series也有同样的功能,它可以被看做一个固定大小的映射。对于上面那个例子,如果用Series作为分组键,则pandas会检查Series以确保其索引跟分组轴是对齐的:
map_series = pd.Series(mapping)

people.groupby(map_series, axis=1).count()
8、通过函数进行分组
相较于字典或Series,Python函数在定义分组映射关系时可以更有创意且更为抽象。任何被当做分组键的函数都会在各个索引值上被调用一次,其返回值就会被用作分组名称。
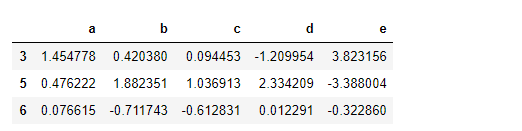
具体点说,以DataFrame为例,其索引值为人的名字。假设你希望根据人名的长度进行分组,虽然可以求取一个字符串长度数组,但其实仅仅传入len函数即可:
people.groupby(len).sum()
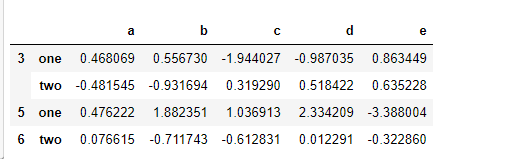
将函数跟数组、列表、字典、Series混合使用也不是问题,因为任何东西最终都会被转换为数组:
key_list = ['one', 'one', 'one', 'two', 'two']
people.groupby([len, key_list]).min()
9、根据索引级别分组
层次化索引数据集最方便的地方在于它能够根据索引级别进行聚合。要实现该目的,通过level关键字传入级别编号或名称即可:
columns = pd.MultiIndex.from_arrays(
[['US', 'US', 'US', 'JP', 'JP'],
[1 , 3, 5, 1, 3]],
names=['cty', 'tenor'])
columns

hier_df = pd.DataFrame(np.random.randn(4, 5), columns=columns)
hier_df
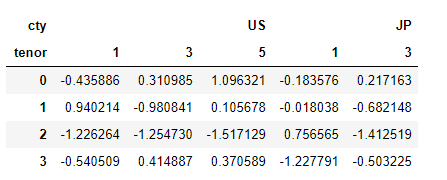
hier_df.groupby(level='cty', axis=1).count()
pandas聚合和分组运算之groupby的更多相关文章
- pandas聚合和分组运算——GroupBy技术(1)
数据聚合与分组运算——GroupBy技术(1),有需要的朋友可以参考下. pandas提供了一个灵活高效的groupby功能,它使你能以一种自然的方式对数据集进行切片.切块.摘要等操作.根据一个或多个 ...
- Python数据聚合和分组运算(1)-GroupBy Mechanics
前言 Python的pandas包提供的数据聚合与分组运算功能很强大,也很灵活.<Python for Data Analysis>这本书第9章详细的介绍了这方面的用法,但是有些细节不常用 ...
- 【学习】数据聚合和分组运算【groupby】
分组键可以有多种方式,且类型不必相同 列表或数组, 某长度与待分组的轴一样 表示DataFrame某个列名的值 字典或Series,给出待分组轴上的值与分组名之间的对应关系 函数用于处理轴索引或索引中 ...
- Pandas分组运算(groupby)修炼
Pandas分组运算(groupby)修炼 Pandas的groupby()功能很强大,用好了可以方便的解决很多问题,在数据处理以及日常工作中经常能施展拳脚. 今天,我们一起来领略下groupby() ...
- 《利用python进行数据分析》读书笔记--第九章 数据聚合与分组运算(一)
http://www.cnblogs.com/batteryhp/p/5046450.html 对数据进行分组并对各组应用一个函数,是数据分析的重要环节.数据准备好之后,通常的任务就是计算分组统计或生 ...
- Python 数据分析(二 本实验将学习利用 Python 数据聚合与分组运算,时间序列,金融与经济数据应用等相关知识
Python 数据分析(二) 本实验将学习利用 Python 数据聚合与分组运算,时间序列,金融与经济数据应用等相关知识 第1节 groupby 技术 第2节 数据聚合 第3节 分组级运算和转换 第4 ...
- 《python for data analysis》第九章,数据聚合与分组运算
# -*- coding:utf-8 -*-# <python for data analysis>第九章# 数据聚合与分组运算import pandas as pdimport nump ...
- Python之数据聚合与分组运算
Python之数据聚合与分组运算 1. 关系型数据库方便对数据进行连接.过滤.转换和聚合. 2. Hadley Wickham创建了用于表示分组运算术语"split-apply-combin ...
- Python 数据分析—第九章 数据聚合与分组运算
打算从后往前来做笔记 第九章 数据聚合与分组运算 分组 #生成数据,五行四列 df = pd.DataFrame({'key1':['a','a','b','b','a'], 'key2':['one ...
随机推荐
- SpringBoot中使用aop-测试
面向切面编程(AOP),该种方式主要是为了弥补面向对象编程(OOP)的不足,通过配置切面以及关注点.通知等我们可以在程序的任意位置对我们的代码进行增强(执行一些代码),AOP是Spring的特性之一, ...
- 多边形求重心 HDU1115
http://acm.hdu.edu.cn/showproblem.php?pid=1115 引用博客:https://blog.csdn.net/ysc504/article/details/881 ...
- ArrayList类的set()方法
ArrayList类的set()方法用于更新指定位置的内容,若内容是new出来的,则需要调用该set()方法:否则,不需要调用该set()方法,示例如下 User.java public class ...
- T100——修改单身栏位,开窗,当前行
PRIVATE FUNCTION axmt500_update_xmdc028() ###更改出货库位 DEFINE l_i INT DEFINE l_index INT DIALOG ATTRIBU ...
- asp.net练习①——Application聊天室
已经好几年没写过代码,重新练习起代码,在这做做笔记备忘. aspx页面js代码: <script type="text/javascript"> function sh ...
- 带坑使用微信小程序框架WePY组件化开发项目,附带第三方插件使用坑
纯粹用来记录wepy及相关联内容,以防再犯~ 1. 接手的wepy项目版本是 1.7.2 ,so我没有初始化的过程.... 2. 安装wepy命令工具,npm install wepy-cli -g ...
- java——ArrayList中remove()方法疑问总结
其实remove方法和contains方法大同小异,它的原理和contains方法相同https://www.cnblogs.com/lyxcode/p/9453213.html在这篇博客里面有详细说 ...
- C#求1-100的质数,100-1000的水仙花数,1-100所有的平方和平方平方根
//你们的鼓励是我最大的动力 大家可以多留言评论 在接下来很长一段时间我会从初级到高级每天更新 大家有想学习的内容也可以留言哦 //现在是我做C#老师的第28天,希望和大家一起努力 加油 using ...
- .NET CORE API 使用Postman中Post请求获取不到传参问题
开发中遇到个坑 记录下. 使用Postman请求core api 接口时,按之前的使用方法(form-data , x-www-form-urlencoded)怎么设置都无法访问. 最后采用raw写入 ...
- base64编码处理大文件
在做项目的时候遇到需要将文件转为base64编码,并存储在文件中. 在将文件转为base64编码是会将文件读入内存,进行base64编码,输出到文件中.代码入下: FileInputStream st ...