2. kafka
目录:
一. kafka是什么
https://www.jianshu.com/p/014af2b34159
Kafka是一个分布式消息队列,它将数据分区保存,并将每个分区保存成多份以提高数据可靠性。Kafka是在大数据背景下产生的,用以应对海量数据的处理场景,具有高性能、良好的扩展性、数据持久性等特点。
Kafka架构由生产者、代理和消费者三类组件构成。生产者将数据推送给代理,消费者从代理商拉取数据进行处理,而代理通过ZooKeeper进行协调和管理。生产者和消费者可根据业务需要自定义开发,多个代理构成一个可靠的分布式消息存储系统,避免数据丢失。代理中的消息被划分成若干个主题,同属于一个主题的的所有数据被分成多个分区,以实现负载分摊和数据并行处理。Kafka基本架构如下:
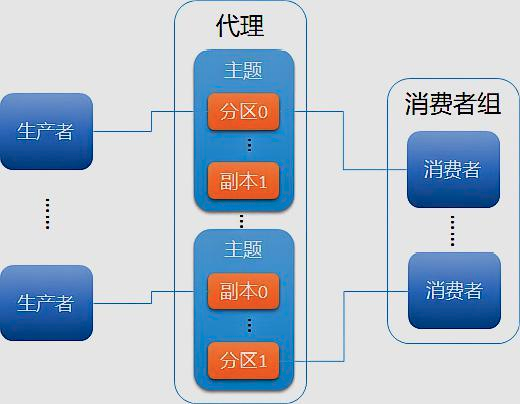
https://segmentfault.com/a/1190000013834998?utm_source=tag-newest
- Kafka是运行在一个集群上,所以它可以拥有一个或多个服务节点;
- Kafka集群将消息存储在特定的文件中,对外表现为Topics;
- 每条消息记录都包含一个key,消息内容以及时间戳;
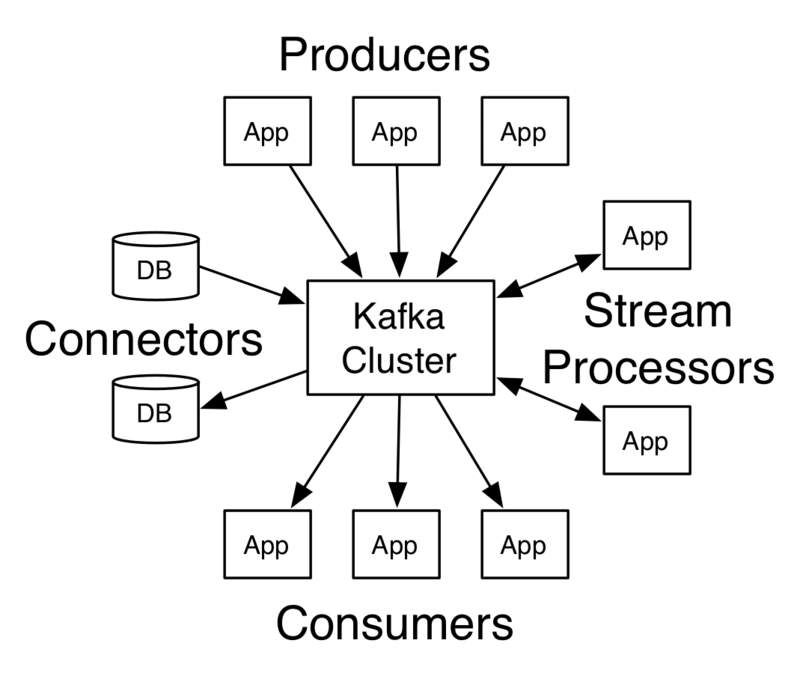
Kafka为了拥有更强大的功能,提供了四大核心接口:
- Producer API允许了应用可以向Kafka中的topics发布消息;
- Consumer API允许了应用可以订阅Kafka中的topics,并消费消息;
- Streams API允许应用可以作为消息流的处理者,比如可以从topicA中消费消息,处理的结果发布到topicB中;
- Connector API提供Kafka与现有的应用或系统适配功能,比如与数据库连接器可以捕获表结构的变化;
它们与Kafka集群的关系可以用下图表示:
二. Kafka的使用场景:
- - 日志收集:一个公司可以用Kafka可以收集各种服务的log,通过kafka以统一接口服务的方式开放给各种consumer,例如hadoop、Hbase、Solr等。
- - 消息系统:解耦和生产者和消费者、缓存消息等。
- - 用户活动跟踪:Kafka经常被用来记录web用户或者app用户的各种活动,如浏览网页、搜索、点击等活动,这些活动信息被各个服务器发布到kafka的topic中,然后订阅者通过订阅这些topic来做实时的监控分析,或者装载到hadoop、数据仓库中做离线分析和挖掘。
- - 运营指标:Kafka也经常用来记录运营监控数据。包括收集各种分布式应用的数据,生产各种操作的集中反馈,比如报警和报告。
- - 流式处理:比如spark streaming和storm
- - 事件源

三.相关术语
https://www.jianshu.com/p/1d496ebd0edf
https://www.jianshu.com/p/446e012a2d3b
- Message(消息):Kafka中的一条记录或数据单位。每条消息都有一个键和对应的一个值,有时还会有可选的消息头。在发送消息时,我们可以省略掉key部分,而直接使用value部分。key的主要作用则是根据一定的策略,将此消息发送到指定的分区中,这样就可以确保包含同一key值的消息全部都写入到同一个分区中。
- Topic(主题):topic是那些被发布的数据记录或消息的一种类别。消费者通过订阅topic,来读取写给它们的数据。首先,主题是一个逻辑上的概念,它用于从逻辑上来归类与存储消息本身。多个生产者可以向一个Topic发送消息,同时也可以有多个消费者消费一个Topic中的消息。Topic还有分区和副本的概念,后续介绍。Topic与消息这两个概念之间密切相关,Kafka中的每一条消息都归属于某一个Topic,而一个Topic下面可以有任意数量的消息。正是借助于Topic这个逻辑上的概念,Kafka将各种各样的消息进行了分门别类,使得不同的消息归属于不同的Topic,这样就可以很好地实现不同系统的生产者可以向同一个Broker发送消息,而不同系统的消费者则可以根据Topic的名字从Broker中拉取消息。Topic是一个字符串。通过Topic这样一个逻辑上的概念,我们就很好地实现了生产者与消费者之间有针对性的发送与拉取。一个topic是对一组消息的归纳。对每个topic,Kafka 对它的日志进行了分区,如下图所示:
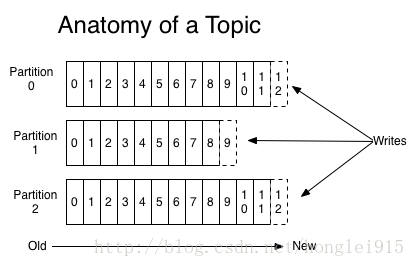
- Topic partition(主题分区):不同的topic被分为不同的分区,而每一条消息都会被分配一个offset,通常每个分区都会被复制至少一到两次。➢ 每一条消息发送到 broker 时,会根据 partition 的规则选择存储到哪一个 partition。如果 partition 规则设置合理,那么所有的消息会均匀的分布在不同的 partition 中, 这样就有点类似数据库的分库分表的概念,把数据做了分片处理。
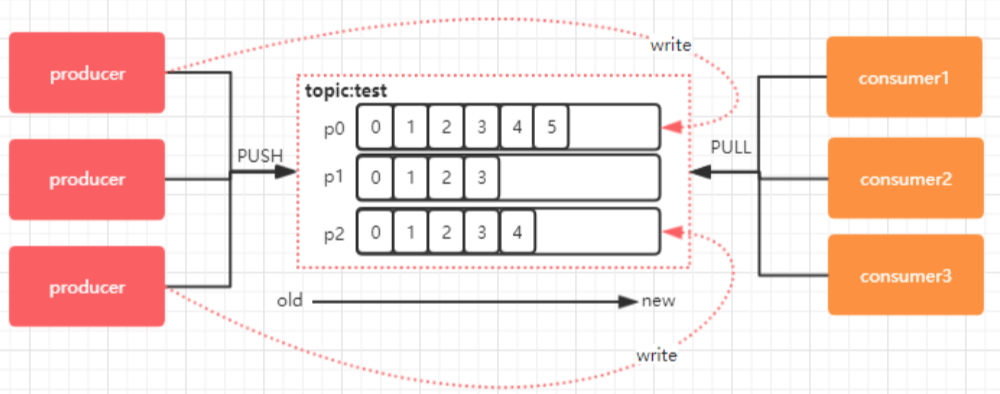
- Offset(偏移量):单个分区中的每一条消息都被分配一个offset,它是一个单调递增的整型数,可用来作为分区中消息的唯一标识符。kafka 通过 offset 保证消息在分区内的顺序,offset 的顺序不跨分区,即 kafka 只保证在
同一个分区内的消息有序。 - Producer(生产者):producer将消息发布到Kafka的topics上。producer决定向topic分区的发布方式,如:轮询的随机方法、或基于消息键(key)的分区算法。
- Broker(代理):Kafka以分布式系统或集群的方式运行。那么群集中的每个节点称为一个broker。在消息队列领域中,它指的其实就是消息队列产品本身,比如说在Kafka这个领域下,Broker其实指的就是一台Kafka Server。换句话说,我们可以将部署的一个Kafka Server看作是一个Broker,就是这样简单。那么从流程上来说,生产者会将消息发送给Broker,然后消费者再从Broker中拉取消息。
- Consumer(消费者):consumer通过订阅topic partition,来读取Kafka的各种topic消息。然后,消费类应用处理会收到消息,以完成指定的工作。
- Consumer group(消费组):在Kafka中,多个消费者可以共同构成一个消费者组,而一个消费者只能从属于一个消费者组。消费者组最为重要的一个功能是实现广播与单播的功能。consumer可以按照consumer group进行逻辑划分。topic partition被均衡地分配给组中的所有consumers。因此,在同一个consumer group中,所有的consumer都以负载均衡的方式运作。换言之,同一组中的每一个consumer都能看到每一条消息。如果某个consumer处于“离线”状态的话,那么该分区将会被分配给同组中的另一个consumer。这就是所谓的“再均衡(rebalance)”。当然,如果组中的consumer多于分区数,则某些consumer将会处于闲置的状态。相反,如果组中的consumer少于分区数,则某些consumer会获得来自一个以上分区的消息。
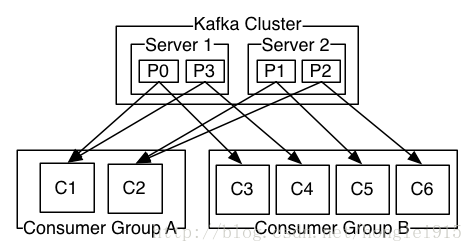
由两个机器组成的集群拥有4个分区 (P0-P3) 2个consumer组. A组有两个consumer, B组有4个. 相比传统的消息系统,Kafka可以很好的保证有序性。
- Lag(延迟):当consumer的速度跟不上消息的产生速度时,consumer就会因为无法从分区中读取消息,而产生延迟。延迟表示为分区头后面的offset数量。从延迟状态(到“追赶上来”)恢复正常所需要的时间,取决于consumer每秒能够应对的消息速度。其公式如下:
time = messages / (consume rate per second - produce rate per second)
四.原理解析
https://www.jianshu.com/p/26d4bf0ccb1d
1. 消息分发
2.1 kafka 消息分发策略
消息是 kafka 中最基本的数据单元.
在 kafka 中,一条消息由 key、value 两部分构成,在发送一条消息时,我们可以指定这个 key,那么 producer 会根据 key 和 partition 机制来判断当前这条消息应该发送并存储到哪个 partition 中.
我们可以根据需要进行扩展 producer 的 partition 机制。
2.2 消息默认的分发机制
默认情况下,kafka 采用的是 hash 取模的分区算法。
如果 Key 为 null,则会随机分配一个分区。这个随机是在这个参 数metadata.max.age.ms的时间范围内随机选择一个。
对于这个时间段内,如果 key 为 null,则只会发送到唯一的分区。该值默认情况下10 分钟更新一次。
关于 Metadata,简单理解就是 Topic/Partition 和 broker 的映射关系,每一个 topic 的每一个
partition,需要知道对应的 broker 列表是什么,leader 是谁、follower 是谁。这些信息都是存储在 Metadata
这个类里面。
2.3 消费端如何消费指定的分区
通过下面的代码,就可以消费指定该 topic 下的 0 号分区。 其他分区的数据就无法接收
//消费指定分区的时候,不需要再订阅
//kafkaConsumer.subscribe(Collections.singleto nList(topic)); //消费指定的分区
TopicPartition topicPartition=new TopicPartition(topic,0);
kafkaConsumer.assign(Arrays.asList(topicPartit ion));
3 消息的消费原理
3.1 kafka 消息消费原理演示
在实际生产过程中,每个 topic 都会有多个 partitions,多 partitions 的好处在于
- 一方面能够对 broker 上的数据进行分片,有效减少了消息的容量从而提升 I/O 性能
- 另外,为了提高消费端的消费能力,一般会通过多个 consumer 去消费同一个 topic ,也就是消费端的负载均衡机制,也就是我们接下来要了解的,在多个 partition 以 及多个 consumer 的情况下,消费者是如何消费消息的
在上文,我们讲了,kafka 存在 consumer group的概念,也就是group.id 一样的 consumer,这些 consumer 属于一个 consumer group.
组内的所有消费者协调在一起来消费订阅主题的所有分区。当然每一个分区只能由同一个消费组内的 consumer 来消费,那么同一个 consumer group 里面的 consumer 是如何分配该消费哪个分区里的数据的呢?
如下图所示,3 个分区,3 个消费者,那么哪个消费者该消费哪个分区呢?
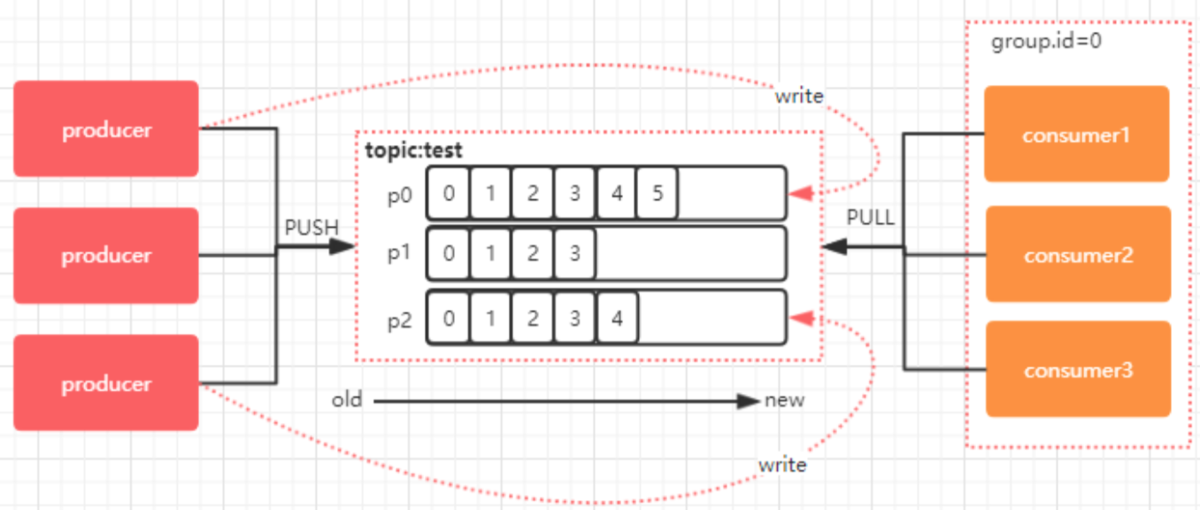
对于上面这个图来说,这 3 个消费者会分别消费 test 这个 topic 的 3 个分区,也就是每个 consumer 消费一个 partition。
五. 项目实战
https://blog.csdn.net/u010343544/article/details/78427345
https://www.jianshu.com/p/a5ef72c91449
https://www.cnblogs.com/biehongli/p/8335538.html
Apache kafka实战.pdf
1.maven依赖
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>0.11.0.0</version>
</dependency>
注意 我这里已经创建了一个叫 test-topic 的主题 如果你们没创建先创建后再执行代码
2. 生产者:
首要功能 : 向某个topic的某个分区发送一条消息,所以它首先需要确认到底要向topic的哪个分区写入消息---这就是分区器(partitooner)要做的.
kafka producer提供了一个默认的分区器. 对于每条待发送的消息, 如果该消息指定了key,那么该partitioner会根据key的哈希值来选择目标分区,若这条消息没有指定key,则partitioner使用轮询的方式确认目标分区-----这样可以最大限度地确保消息在所有分区上的均匀性.
第二件事: 寻找这个分区对应的leader, 也就是该分区leader副本所在的kafka broker.
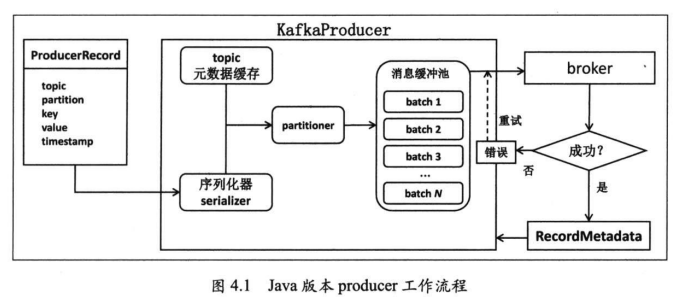

例子1: 实现了构造一条消息,然后发送给kafka.在运行这个producer程序之前,要保证启动一个最小规模的kafka单机或者集群环境.
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.Producer;
import org.apache.kafka.clients.producer.ProducerRecord; import java.util.Properties; public class ProducerTest {
public static void main(String[] args) throws Exception {
Properties props = new Properties();
props.put("bootstrap.servers" , "localhost:9092"); //必须指定
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); //必须指定
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); // 必须指定
props.put("acks","-1");
props.put("retries",3);
props.put("batch.size",323840);
props.put("linger.ms",10);
props.put("buffer.memory",33554432);
props.put("max.block.ms",3000); Producer<String, String> producer = new KafkaProducer<>(props);
for(int i = 0; i < 100; i++)
producer.send(new ProducerRecord<>("my-topic"),Integer.toString(i),Integer.toString(i)); producer.close();
} }

例子2:
public class TestProducter {
public static void main(String[] args) throws Exception{
Properties properties = new Properties();
//指定kafka服务器地址 如果是集群可以指定多个 但是就算只指定一个他也会去集群环境下寻找其他的节点地址
properties.setProperty("bootstrap.servers","127.0.0.1:9092");
//key序列化器
properties.setProperty("key.serializer", StringSerializer.class.getName());
//value序列化器
properties.setProperty("value.serializer",StringSerializer.class.getName());
KafkaProducer<String,String> kafkaProducer = new KafkaProducer<String, String>(properties);
ProducerRecord<String, String> stringStringProducerRecord = new ProducerRecord<String, String>("test-topic",1,"testKey","hello");
Future<RecordMetadata> send = kafkaProducer.send(stringStringProducerRecord);
RecordMetadata recordMetadata = send.get();
System.out.println(recordMetadata);
}
}
3. 消费者:
例子1:
import com.mediav.data.log.unitedlog.UnitedEvent;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.TopicPartition;
import org.apache.thrift.TDeserializer;
import org.apache.thrift.TException;
import org.apache.thrift.protocol.TBinaryProtocol; import java.nio.charset.Charset;
import java.text.ParseException;
import java.text.SimpleDateFormat;
import java.util.*; public class Consumer {
public static void main(String[] args) throws TException, ParseException {
// 构造一个java.util.Properties对象,
// 至少指定bootstrap.servers,key.deserializer,value.deserializer,group.id的值 String topicName = "test-topic";
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("group.id", "test4");
props.put("auto.offset.reset", "latest");
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
//使用上一步创建的Properties实例构造KafkaConsumer对象
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
//调用KafkaConsumer.subscribe方法订阅consumer group感兴趣的topic列表
consumer.subscribe(Arrays.asList(topicName));
//循环调用kafkaConsumer.poll方法获取封装在ConsumerRecord的topic消息
while (true) {
ConsumerRecords<String, String> records = consumer.poll(10000);
// 处理获取到的ConsumerRecord对象
for (ConsumerRecord<String, String> record:
records) {
System.out.println(record.value());
}
} }
}
- 构造Properties对象
构建consumer的第一步.在创建的Properties对象中,必须指定的参数有4个.


- 构造KafkaConsumer对象
KafkaConsumer是consumer的主入口,所有的功能基本上都是由KafakaConsumer类提供的.只需一句代码即可创建:
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
创建KafkaConsumer也可同时指定Key和value的deserializer:
KafkaConsumer consumer = new KafkaConsumer(props , new StringDeserializer(), value.deserializer);
- 订阅topic列表
这一步使用KafkaConsumer.subscribe方法订阅consumer group要消费的topic列表.上面代码中只订阅了一个topic---test-topic.如果要订阅多个topic,可采用:
consumer.subscribe(Arrays.asList("topic1","topic2","topic3"));
该方法还支持正则表达式.假设consumer group要消费所有以kafka开头的topic,则可以如此订阅:
consumer.subscribe(Pattern.compile("kafka.*"),new NoOpConsumerRebalanceListener());
注意: subscribe非增量式,后面调用会完全覆盖之前的订阅语句.
consumer.subscribe(Arrays.asList("topic1","topic2","topic3"));
consumer.subscribe(Arrays.asList("topic4","topic5","topic6"));
- 获取消息

- 处理ConsumerRecord对象

- 关闭consumer

例子2:
public class TestCousmer {
public static void main(String[] args) {
Properties properties = new Properties();
properties.setProperty("bootstrap.servers","127.0.0.1:9092");
properties.setProperty("key.deserializer", StringDeserializer.class.getName());
properties.setProperty("value.deserializer",StringDeserializer.class.getName());
properties.setProperty("group.id","1111");
KafkaConsumer<String,String> consumer = new KafkaConsumer<String, String>(properties);
consumer.subscribe(Collections.singletonList("test-topic"));
while (true){
ConsumerRecords<String, String> poll = consumer.poll(500);
for (ConsumerRecord<String, String> stringStringConsumerRecord : poll) {
System.out.println(stringStringConsumerRecord);
}
}
}
}
2. kafka的更多相关文章
- Spark踩坑记——Spark Streaming+Kafka
[TOC] 前言 在WeTest舆情项目中,需要对每天千万级的游戏评论信息进行词频统计,在生产者一端,我们将数据按照每天的拉取时间存入了Kafka当中,而在消费者一端,我们利用了spark strea ...
- 消息队列 Kafka 的基本知识及 .NET Core 客户端
前言 最新项目中要用到消息队列来做消息的传输,之所以选着 Kafka 是因为要配合其他 java 项目中,所以就对 Kafka 了解了一下,也算是做个笔记吧. 本篇不谈论 Kafka 和其他的一些消息 ...
- kafka学习笔记:知识点整理
一.为什么需要消息系统 1.解耦: 允许你独立的扩展或修改两边的处理过程,只要确保它们遵守同样的接口约束. 2.冗余: 消息队列把数据进行持久化直到它们已经被完全处理,通过这一方式规避了数据丢失风险. ...
- .net windows Kafka 安装与使用入门(入门笔记)
完整解决方案请参考: Setting Up and Running Apache Kafka on Windows OS 在环境搭建过程中遇到两个问题,在这里先列出来,以方便查询: 1. \Jav ...
- kafka配置与使用实例
kafka作为消息队列,在与netty.多线程配合使用时,可以达到高效的消息队列
- kafka源码分析之一server启动分析
0. 关键概念 关键概念 Concepts Function Topic 用于划分Message的逻辑概念,一个Topic可以分布在多个Broker上. Partition 是Kafka中横向扩展和一 ...
- Kafka副本管理—— 为何去掉replica.lag.max.messages参数
今天查看Kafka 0.10.0的官方文档,发现了这样一句话:Configuration parameter replica.lag.max.messages was removed. Partiti ...
- Kafka:主要参数详解(转)
原文地址:http://kafka.apache.org/documentation.html ############################# System ############### ...
- kafka
2016-11-13 20:48:43 简单说明什么是kafka? Apache kafka是消息中间件的一种,我发现很多人不知道消息中间件是什么,在开始学习之前,我这边就先简单的解释一下什么是消息 ...
- Spark Streaming+Kafka
Spark Streaming+Kafka 前言 在WeTest舆情项目中,需要对每天千万级的游戏评论信息进行词频统计,在生产者一端,我们将数据按照每天的拉取时间存入了Kafka当中,而在消费者一端, ...
随机推荐
- 【tensorflow】softmax_cross_entropy_with_logits与sparse_softmax_cross_entropy_with_logits
softmax_cross_entropy_with_logits与sparse_softmax_cross_entropy_with_logits都是对最后的预测结果进行softmax然后求交叉熵 ...
- tomcat 启动闪退解决方法
当我们在windows上面进行项目的部署与启动的时候有的时候tomcat在进行启动的时候会删一下就退了,这个时候一般是里面启动的时候设置的jdk的问题下面咱们来看一下具体解决方案 编辑我们的start ...
- 微信小程序常用控件汇总
1.图片标签: <image src="/images/aaa.png"></image> 2.文本标签: <text>Hello</te ...
- 上传大文件到腾讯云cos遇到的一些问题
讲一个开发遇到的问题. 开发中遇到一个需求,需要在后台表单页面支持上传视频.因为项目中一直用的是腾讯云的COS做第三方存储平台,所以视频也要上传到cos中保存.首先想到的是使用腾讯提供的php的SDK ...
- mysql查看和设置最大连接数
.查看最大连接数 SHOW VARIABLES LIKE '%max_connections%'; .修改最大连接数 ;
- git push时出现大文件的处理方法
最近在提交项目时出现报错 文件限制只能100M,但是里面有个文件202M,超过了码云的限制. 所以顺手就把这个文件删除了 然后发现还是同样的报错,反复检查目录还是不行,找了资料说,需要git rm 命 ...
- 乐字节Java之file、IO流基础知识和操作步骤
嗨喽,小乐又来了,今天要给大家送上的技术文章是Java重点知识-IO流. 先来看看IO流的思维导图吧. 一. File 在Java中,Everything is Object!所以在文件中,也不例外! ...
- go创建模块化项目
比如我要创建一个xxx-system,里面可能有多个子模块,步骤如下: 1.mkdir xxx-system 2.cd xxx-system 3.在xxx-system目录下创建一系列的service ...
- [转帖]新iPhone的黑科技:UWB技术揭秘
新iPhone的黑科技:UWB技术揭秘 http://blog.nsfocus.net/iphone-black-technology-uwb-technology-revealed/ 阅读: ...
- ASP.NET Core依赖注入多个服务实现类
依赖注入在 ASP.NET Core 中起中很重要的作用,也是一种高大上的编程思想,它的总体原则就是:俺要啥,你就给俺送啥过来. 服务类型的实例转由容器自动管理,无需我们在代码中显式处理. 因此,有了 ...