Scrapy - 小说爬虫
实例解析 - 小说爬虫
页面分析
共有三级页面
一级页面 大目录
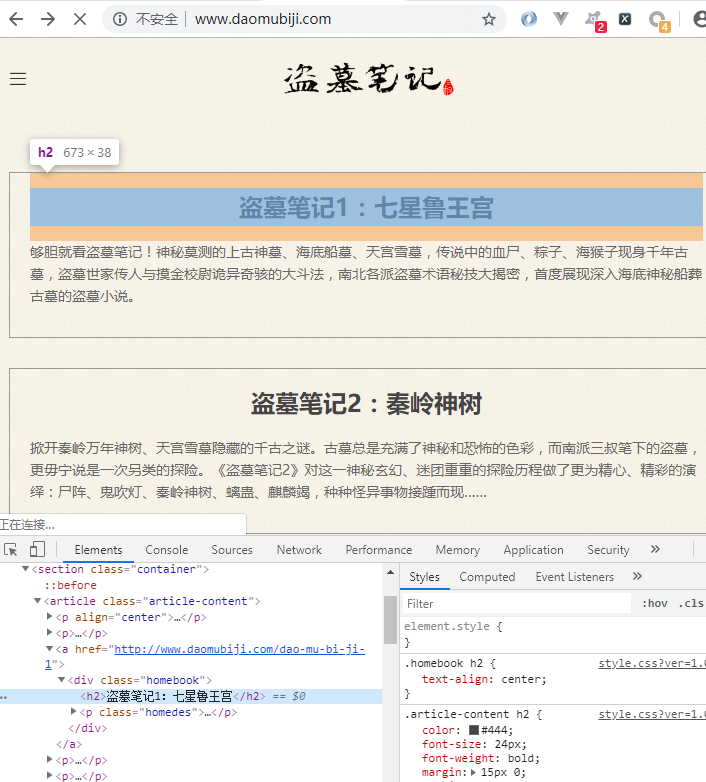
二级页面 章节目录
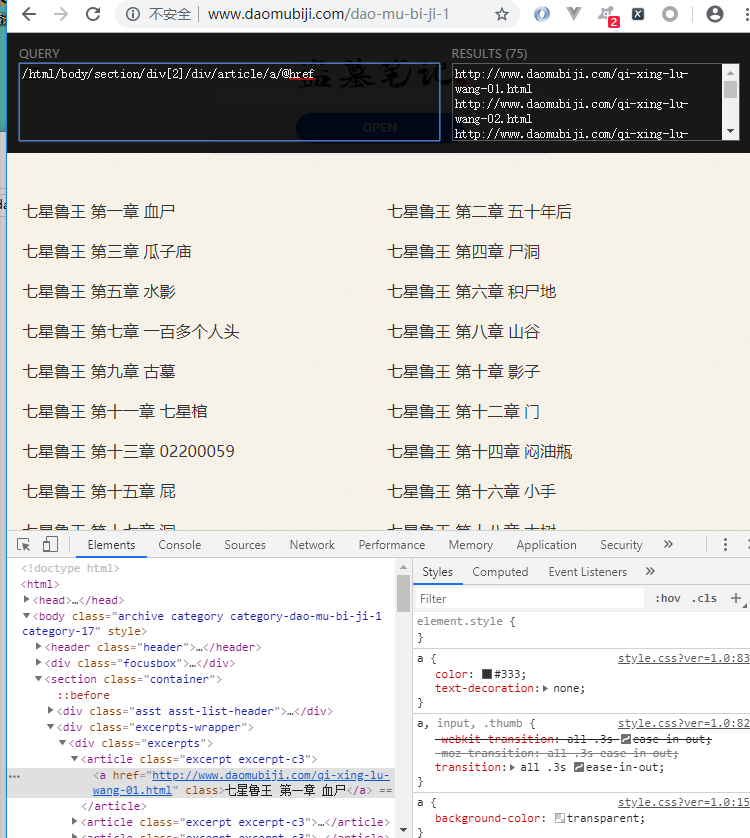
三级界面 章节内容
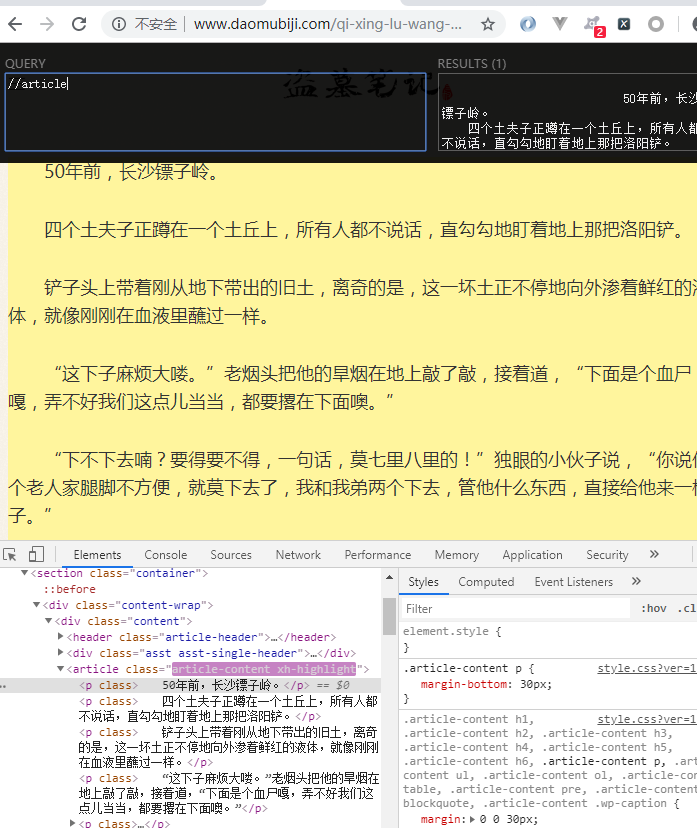
爬取准备
一级界面
http://www.daomubiji.com/
二级页面xpath
直接复制的 xpath
/html/body/section/article/a/@href
这里存在着反爬虫机制, 改变了页面结构
在返回的数据改变了页面结构, 需要换为下面的 xpath 才可以
//ul[@class="sub-menu"]/li/a/@href
三级页面xpath
//article
项目准备
begin.py
pycharm 启动文件,方便操作
from scrapy import cmdline
cmdline.execute('scrapy crawl daomu --nolog'.split())
settings.py
相关的参数配置
BOT_NAME = 'Daomu'
SPIDER_MODULES = ['Daomu.spiders']
NEWSPIDER_MODULE = 'Daomu.spiders'
ROBOTSTXT_OBEY = False LOG_LEVEL = 'WARNING'
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36',
}
ITEM_PIPELINES = {
'Daomu.pipelines.DaomuPipeline': 300,
}
逻辑代码
items.py
指定相关期望数据
-*- coding: utf-8 -*- # Define here the models for your scraped items
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/items.html import scrapy class DaomuItem(scrapy.Item):
# define the fields for your item here like:
# 卷名
juan_name = scrapy.Field()
# 章节数
zh_num = scrapy.Field()
# 章节名
zh_name = scrapy.Field()
# 章节链接
zh_link = scrapy.Field()
# 小说内容
zh_content = scrapy.Field()
daomu.py
爬虫文件
# -*- coding: utf-8 -*-
import scrapy
from ..items import DaomuItem class DaomuSpider(scrapy.Spider):
name = 'daomu'
allowed_domains = ['www.daomubiji.com']
start_urls = ['http://www.daomubiji.com/'] # 解析一级页面,提取 盗墓笔记1 2 3 ... 链接
def parse(self, response):
# print(response.text)
one_link_list = response.xpath(
'//ul[@class="sub-menu"]/li/a/@href'
).extract()
# print('*' * 50)
# print(one_link_list)
# 把链接交给调度器入队列
for one_link in one_link_list:
yield scrapy.Request(
url=one_link,
callback=self.parse_two_link
) # 解析二级页面
def parse_two_link(self, response):
# 基准xpath,匹配所有章节对象列表
article_list = response.xpath('//article')
# print(article_list)
# 依次获取每个章节信息
for article in article_list:
# 创建item对象
item = DaomuItem()
info = article.xpath('./a/text()'). \
extract_first().split()
print(info) # ['秦岭神树篇', '第一章', '老痒出狱']
item['juan_name'] = info[0]
item['zh_num'] = info[1]
item['zh_name'] = info[2]
item['zh_link'] = article.xpath('./a/@href').extract_first()
# 把章节链接交给调度器 yield scrapy.Request(
url=item['zh_link'],
# 把item传递到下一个解析函数
meta={'item': item},
callback=self.parse_three_link
) # 解析三级页面
def parse_three_link(self, response):
item = response.meta['item']
# 获取小说内容
item['zh_content'] = '\n'.join(response.xpath(
'//article[@class="article-content"]'
'//p/text()'
).extract()) yield item # '\n'.join(['第一段','第二段','第三段'])
pipelines.py
持久化处理
# -*- coding: utf-8 -*- # Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html class DaomuPipeline(object):
def process_item(self, item, spider): filename = 'downloads/{}-{}-{}.txt'.format(
item['juan_name'],
item['zh_num'],
item['zh_name']
) f = open(filename,'w')
f.write(item['zh_content'])
f.close() return item
Scrapy - 小说爬虫的更多相关文章
- 使用scrapy制作的小说爬虫
使用scrapy制作的小说爬虫 爬虫配套的django网站 https://www.zybuluo.com/xuemy268/note/63660 首先是安装scrapy,在Windows下的安装比 ...
- 爬虫(十八):Scrapy框架(五) Scrapy通用爬虫
1. Scrapy通用爬虫 通过Scrapy,我们可以轻松地完成一个站点爬虫的编写.但如果抓取的站点量非常大,比如爬取各大媒体的新闻信息,多个Spider则可能包含很多重复代码. 如果我们将各个站点的 ...
- 爬虫学习之基于Scrapy的爬虫自动登录
###概述 在前面两篇(爬虫学习之基于Scrapy的网络爬虫和爬虫学习之简单的网络爬虫)文章中我们通过两个实际的案例,采用不同的方式进行了内容提取.我们对网络爬虫有了一个比较初级的认识,只要发起请求获 ...
- C#最基本的小说爬虫
新手学习C#,自己折腾弄了个简单的小说爬虫,实现了把小说内容爬下来写入txt,还只能爬指定网站. 第一次搞爬虫,涉及到了网络协议,正则表达式,弄得手忙脚乱跑起来效率还差劲,慢慢改吧. 爬的目标:htt ...
- scrapy爬虫学习系列二:scrapy简单爬虫样例学习
系列文章列表: scrapy爬虫学习系列一:scrapy爬虫环境的准备: http://www.cnblogs.com/zhaojiedi1992/p/zhaojiedi_python_00 ...
- Scrapy框架-----爬虫
说明:文章是本人读了崔庆才的Python3---网络爬虫开发实战,做的简单整理,希望能帮助正在学习的小伙伴~~ 1. 准备工作: 安装Scrapy框架.MongoDB和PyMongo库,如果没有安装, ...
- Scrapy创建爬虫项目
1.打开cmd命令行工具,输入scrapy startproject 项目名称 2.使用pycharm打开项目,查看项目目录 3.创建爬虫,打开CMD,cd命令进入到爬虫项目文件夹,输入scrapy ...
- Scrapy - CrawlSpider爬虫
crawlSpider 爬虫 思路: 从response中提取满足某个条件的url地址,发送给引擎,同时能够指定callback函数. 1. 创建项目 scrapy startproject mysp ...
- 第三百五十六节,Python分布式爬虫打造搜索引擎Scrapy精讲—scrapy分布式爬虫要点
第三百五十六节,Python分布式爬虫打造搜索引擎Scrapy精讲—scrapy分布式爬虫要点 1.分布式爬虫原理 2.分布式爬虫优点 3.分布式爬虫需要解决的问题
随机推荐
- http上传txt文件
http通过post方式上传txt文件 可以参考 https://www.cnblogs.com/s0611163/p/4071210.html /// <summary> /// Htt ...
- Computer Vision_18_Image Stitching: Image Alignment and Stitching——2006
此部分是计算机视觉部分,主要侧重在底层特征提取,视频分析,跟踪,目标检测和识别方面等方面.对于自己不太熟悉的领域比如摄像机标定和立体视觉,仅仅列出上google上引用次数比较多的文献.有一些刚刚出版的 ...
- python之分支和循环
Day 1-night 三元操作符 语法:a=x if 条件 else y 即:当条件为True时,a的值赋值为x,否则赋值为y eg:small=x if x<y else y <=& ...
- python 并发编程-- 多进程
一 multiprocessing 模块介绍 python中的多线程无法利用多核优势,如果想要充分地使用多核CPU的资源(os.cpu_count()查看),在python中大部分情况需要使用多进程 ...
- MySQL进阶 9: 联合查询 - 查询语句1 union 查询语句2 union ...
#进阶 : 联合查询 /* union 联合 合并: 将多条查询语句的结果合并成一个结果 语法: 查询语句1 union 查询语句2 union ... 应用语境: 要查询的结果来自多个表,但查询的列 ...
- vs2008重置方法
开始->Microsoft Visual Studio 2008->Visual Studio Tools->Visual Studio 2008 命令提示 然后依次键入如下命令: ...
- 分布式可扩展存储系统 BaikalDB
BaikalDB是一个分布式可扩展的存储系统,支持PB级结构化数据的随机实时读写. 提供MySQL接口,支持常用的SELECT,UPDATE,INSERT,DELETE语法.提供各种WHERE过滤.G ...
- JS 框架安全报告:jQuery 下载次数超过 1.2 亿次
尽管 JavaScript 库 jQuery 仍被使用,但它已不再像以前那样流行.根据开源安全平台 Snyk 统计,目前至少十分之六的网站受到 jQuery XSS 漏洞的影响,甚至用于扩展 jQue ...
- P4149 [IOI2011]Race 点分治
思路: 点分治 提交:5次 题解: 刚开始用排序+双指针写的,但是调了一晚上,总是有两个点过不了,第二天发现原因是排序时的\(cmp\)函数写错了:如果对于路径长度相同的,我们从小往大按边数排序,当双 ...
- Emacs:十六进制模式下跳转到特定地址
造冰箱的大熊猫@cnblogs 2019/9/18 Emacs提供的十六进制模式(M-x hexl-mode)以十六进制格式显示文件内容,对于分析图像等二进制数据文件非常方便.在此模式下,我们可以使用 ...