5分钟了解图数据库Neo4j的使用
1.图数据库安装与配置
1.1安装与配置
1.2权限管理
2.从csv导入数据
3.常见的CQL命令
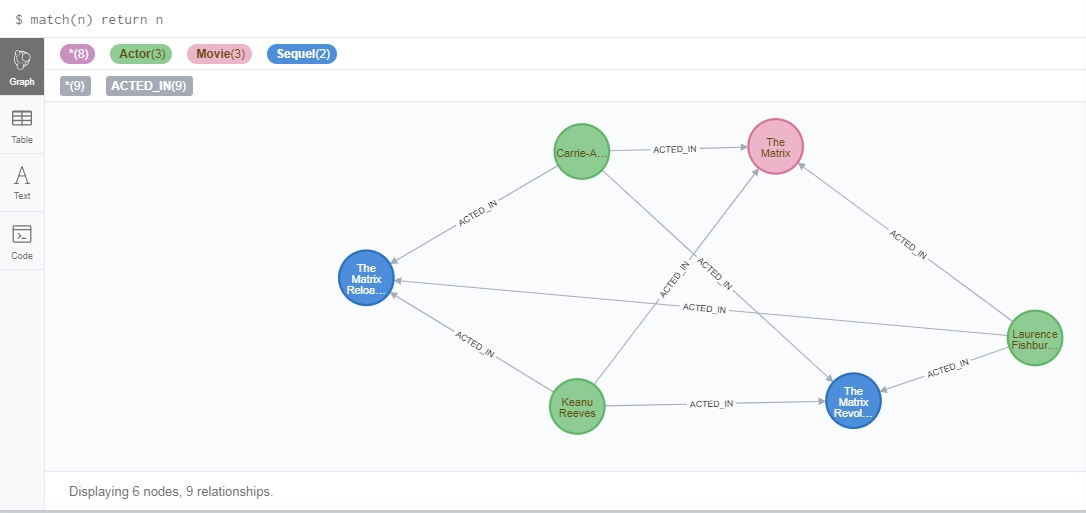
3.1查询
- 查询整个图形
- 查询year小于2000的电影
- 查询带有movie标签的节点
- 查询名字叫Keanu Reeves的演员
- 查询与带Movie标签的节点相关的所有节点
- 查询“Keanu Reeves”所有参演过的电影
- 查询与“Keanu Reeves”同演过的人
3.2.创建
- 增加拍摄于2010年名叫“super man”的电影
- 增加名叫“Jone”的演员
- 增加“Jone”和“super man”之间类型为ACTED_IN的关系
3.3更新
- 给“Jone”增加属性age = 40
- 给“super man”增加description = “Hot”
- 给“Jone”和“super man”之间的关系增加description=“first”
3.4删除
- 删除id不同,名字相同的重复的演员实体
3.5函数
- 查询name=“Jone”的节点的ID
- 查询“Jone”和“super man”之间关系类型
- 查询name=“Jone”的节点的所有属性名
- 查询name=“Jone”的节点的所有属性名及值
- 统计带标签“Movie”的节点数量
- 给所有节点增加时间戳
3.6路径
- 查询与“Keanu Reeves”距离1-3度的节点
- 查询“Laurence Fishburne”和“Keanu Reeves”的最短路径
4.Python实现neo4j的访问
from py2neo import Database, Graph, Node, Relationship # 建立连接
db = Database("http://127.0.0.1:7474")
graph = Graph("bolt://127.0.0.1:7687", username="neo4j", password="") try:
for node in graph.nodes:
print(node)
except:
print("key error!") # 匹配
n = graph.nodes.match("Keanu Reeves")
for i in n:
print(i)
try:
for r in graph.relationships:
print(r)
except:
print("key error!") # 提交任务
tx = graph.begin()
a = Node("Actor", name="张鹤伦")
tx.create(a)
b = Node("Actor", name="杨九郎")
ab = Relationship(a, "师兄弟", b)
tx.create(ab)
tx.commit() # 判断是否存在
isExists = graph.exists(ab)
print("is Exists=" + str(isExists)) # 执行CQL命令
graph.run('create(p:Actor{name:"周九良"})')
ans = graph.run('match(p:Actor) return p.name,p.born').to_ndarray()
print(ans)
5分钟了解图数据库Neo4j的使用的更多相关文章
- 10分钟上手图数据库Neo4j
随着互联网不断的发展,传统的关系型数据库如oracle,mysql已经难以支撑现下大数据量,高并发的场景了.于是,NoSQL横空出世,有像cassandra这样的column-based,像Mongo ...
- 开源软件:NoSql数据库 - 图数据库 Neo4j
转载自原文地址:http://www.cnblogs.com/loveis715/p/5277051.html 最近我在用图形数据库来完成对一个初创项目的支持.在使用过程中觉得这种图形数据库实际上挺有 ...
- 图数据库Neo4j简介
图数据库Neo4j简介 转自: 图形数据库Neo4J简介 - loveis715 - 博客园https://www.cnblogs.com/loveis715/p/5277051.html 最近我在用 ...
- 基于Java图片数据库Neo4j 3.0.0发布 全新的内部架构
基于Java图片数据库Neo4j 3.0.0发布 全新的内部架构 Neo4j 3.0.0 正式发布,这是 Neo4j 3.0 系列的第一个版本.此版本对内部架构进行了全新的设计;提供给开发者更强大的生 ...
- 图数据库Neo4j
官网下载:https://neo4j.com/download/ 图数据库Neo4j入门:https://blog.csdn.net/gobitan/article/details/68929118 ...
- 主流图数据库Neo4J、ArangoDB、OrientDB综合对比:架构分析
主流图数据库Neo4J.ArangoDB.OrientDB综合对比:架构分析 YOTOY 关注 0.4 2017.06.15 15:11* 字数 3733 阅读 16430评论 2喜欢 18 1: 本 ...
- Hello World 之Spring Boot 调用图数据库Neo4j
明日歌 [清]钱鹤滩 明日复明日,明日何其多! 我生待明日,万事成蹉跎 1. 图数据库Neo4j之爱的初体验 ----与君初相识,犹似故人归 在如今大数据(big data)横行的时代,传统的关系型数 ...
- 第一款支持容器和云部署的开源数据库Neo4j 3.0
导读 Neo4j 3.0.0 正式发布,这是 Neo4j 3.0 系列的第一个版本.此版本对内部架构进行了全新的设计:提供给开发者更强大的生产力:提供更广阔的部署选择.Neo4j 3.0 被认为是世界 ...
- 十分钟学会mysql数据库操作
Part1:写在最前 MySQL安装的方式有三种: ①rpm包安装 ②二进制包安装 ③源码安装 这里我们推荐二进制包安装,无论从安装速度还是用于生产库安装环境来说,都是没问题的.现在生产库一般采用My ...
随机推荐
- Hibernate的CRUD配置及简单使用
参考博客:https://blog.csdn.net/qq_38977097/article/details/81326503 1.首先是jar包,可以在官网下载. 或者点击下面链接下载 链接:htt ...
- 一键生成 dao service serverImpl controller 层
package com.nf147.policy_publishing_platform.util.auto; import java.io.File; import java.io.FileWrit ...
- 初识 MQTT——IBM
为什么 MQTT 是最适合物联网的网络协议 官方网址: http://mqtt.org/ Michael Yuan2017 年 6 月 14 日发布 WeiboGoogle+用电子邮件发送本页面 0 ...
- Pandas中DataFrame数据合并、连接(concat、merge、join)之join
pandas.DataFrame.join 自己弄了很久,一看官网.感觉自己宛如智障.不要脸了,直接抄 DataFrame.join(other, on=None, how='left', lsuff ...
- mongodb多条件分页查询的三种方法(转)
一.使用limit和skip进行分页查询 public List<User> pageList(int pageNum ,int pageSize){ List<User> u ...
- AJAX 请求完成时执行函数。Ajax 事件。
ajaxComplete(callback) 概述 AJAX 请求完成时执行函数.Ajax 事件. XMLHttpRequest 对象和设置作为参数传递给回调函数.大理石直角尺 参数 callback ...
- Spring——代理工厂实现增强
借助Spring IOC的机制,为ProxyFactory代理工厂的属性实现依赖注入,这样做的优点是可配置型高,易用性好. 1.创建抽象主题 public interface ProService { ...
- Jmeter(九)参数化
参数化是自动化测试脚本的一种常用技巧.简单来说,参数化的一般用法就是将脚本中的某些输入使用参数来代替,在脚本运行时指定参数的取值范围和规则: 这样,脚本在运行时就可以根据需要选取不同的参数值作为输入. ...
- fatal error C1189: #error: "Oops: min() and/or max() are defined as preprocessor macros. Define NOMINMAX macro before including any system headers!"
1.问题描述 vs2015 使用pg数据库的C++库文件4.0.1版本libpqxx.dll,包含头文件#include "pqxx\pqxx" 出现这个错误: fatal err ...
- Python - 工具:将大图切片成小图,将小图组合成大图
训练keras时遇到了一个问题,就是内存不足,将 .fit 改成 .fit_generator以后还是放不下一张图(我的图片是8192×8192的大图==64M).于是解决方法是将大图切成小图,把小图 ...