python 爬虫 urllib模块 反爬虫机制UA
方法: 使用urlencode函数
urllib.request.urlopen()
import urllib.request
import urllib.parse
url = 'https://www.sogou.com/web?'
#将get请求中url携带的参数封装至字典中
param = {
'query':'周杰伦'
}
#对url中的非ascii进行编码
param = urllib.parse.urlencode(param)
#将编码后的数据值拼接回url中
url += param
response = urllib.request.urlopen(url=url)
data = response.read()
with open('./周杰伦1.html','wb') as fp:
fp.write(data)
print('写入文件完毕')
开发者工具浏览器按F12或者右键按检查 ,有个抓包工具network,刷新页面,可以看到网页资源,可以看到请求头信息,UA
在抓包工具点击任意请求,可以看到所有请求信息,向应信息,
主要用到headers,response,response headers存放响应头信息,request headers 存放请求信息
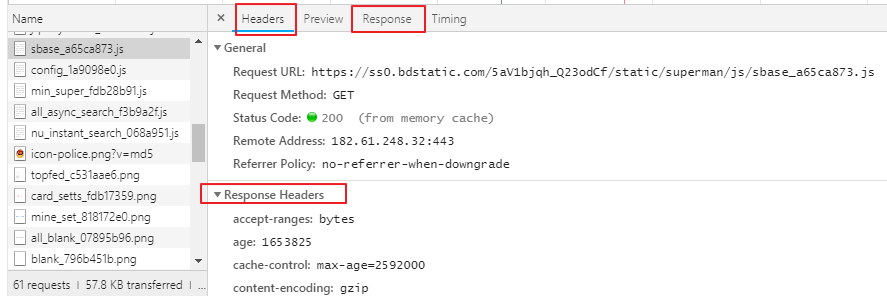

反爬出机制:网站会检查请求的UA,如果发现UA是爬虫程序,会拒绝提供网站页面数据。
如果网站检查发现请求UA是基于某一款浏览器标识(浏览器发起的请求),网站会认为请求是正常请求,会把页面数据响应信息给客户端
User-Agent(UA):请求载体的身份标识
反反爬虫机制:
伪造爬虫程序的请求的UA,把爬虫程序的请求UA伪造成谷歌标识,火狐标识
通过自定义请求对象,用于伪装爬虫程序请求的身份。
User-Agent参数,简称为UA,该参数的作用是用于表明本次请求载体的身份标识。如果我们通过浏览器发起的请求,则该请求的载体为当前浏览器,则UA参数的值表明的是当前浏览器的身份标识表示的一串数据。如果我们使用爬虫程序发起的一个请求,则该请求的载体为爬虫程序,那么该请求的UA为爬虫程序的身份标识表示的一串数据。有些网站会通过辨别请求的UA来判别该请求的载体是否为爬虫程序,如果为爬虫程序,则不会给该请求返回响应,那么我们的爬虫程序则也无法通过请求爬取到该网站中的数据值,这也是反爬虫的一种初级技术手段。那么为了防止该问题的出现,则我们可以给爬虫程序的UA进行伪装,伪装成某款浏览器的身份标识。
上述案例中,我们是通过request模块中的urlopen发起的请求,该请求对象为urllib中内置的默认请求对象,我们无法对其进行UA进行更改操作。urllib还为我们提供了一种自定义请求对象的方式,我们可以通过自定义请求对象的方式,给该请求对象中的UA进行伪装(更改)操作。
自定义请求头信息字典可以添加谷歌浏览器的UA标识,自定义请求对象来伪装成谷歌UA
1.封装自定义的请求头信息的字典,
2.注意:在headers字典中可以封装任意的请求头信息
3.将浏览器的UA数据获取,封装到一个字典中。该UA值可以通过抓包工具或者浏览器自带的开发者工具中获取某请求,
从中获取UA的值
import urllib.request
import urllib.parse url = 'https://www.sogou.com/web?query=' # url的特性:url不可以存在非ASCII编码字符数据
word = urllib.parse.quote("周杰伦") # 将编码后的数据值拼接回url中
url = url+word # 有效url # 发请求之前对请求的UA进行伪造,伪造完再对请求url发起请求
# UA伪造 # 1 子制定一个请求对象,headers是请求头信息,字典形式
# 封装自定义的请求头信息的字典,
# 注意:在headers字典中可以封装任意的请求头信息
headers = {
# 存储任意的请求头信息
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36' } # 该请求对象的UA进行了成功的伪装
request = urllib.request.Request(url=url, headers=headers) # 2.针对自定义请求对象发起请求
response = urllib.request.urlopen(request) # 3.获取响应对象中的页面数据:read函数可以获取响应对象中存储的页面数据(byte类型的数据值)
page_text = response.read() # 4.持久化存储:将爬取的页面数据写入文件进行保存
with open("周杰伦.html","wb") as f:
f.write(page_text)
print("写入数据成功")
这样就可以突破网站的反爬机制
python 爬虫 urllib模块 反爬虫机制UA的更多相关文章
- python 爬虫 urllib模块 目录
python 爬虫 urllib模块介绍 python 爬虫 urllib模块 url编码处理 python 爬虫 urllib模块 反爬虫机制UA python 爬虫 urllib模块 发起post ...
- python爬虫 urllib模块url编码处理
案例:爬取使用搜狗根据指定词条搜索到的页面数据(例如爬取词条为‘周杰伦'的页面数据) import urllib.request # 1.指定url url = 'https://www.sogou. ...
- 爬虫(Spider),反爬虫(Anti-Spider),反反爬虫(Anti-Anti-Spider)
爬虫(Spider),反爬虫(Anti-Spider),反反爬虫(Anti-Anti-Spider),这之间的斗争恢宏壮阔... Day 1小莫想要某站上所有的电影,写了标准的爬虫(基于HttpCli ...
- 定义一个方法get_page(url),url参数是需要获取网页内容的网址,返回网页的内容。提示(可以了解python的urllib模块)
定义一个方法get_page(url),url参数是需要获取网页内容的网址,返回网页的内容.提示(可以了解python的urllib模块) import urllib.request def get_ ...
- python爬虫-urllib模块
urllib 模块是一个高级的 web 交流库,其核心功能就是模仿web浏览器等客户端,去请求相应的资源,并返回一个类文件对象.urllib 支持各种 web 协议,例如:HTTP.FTP.Gophe ...
- Python爬虫urllib模块
Python爬虫练习(urllib模块) 关注公众号"轻松学编程"了解更多. 1.获取百度首页数据 流程:a.设置请求地址 b.设置请求时间 c.获取响应(对响应进行解码) ''' ...
- python 爬虫 urllib模块 发起post请求
urllib模块发起的POST请求 案例:爬取百度翻译的翻译结果 1.通过浏览器捉包工具,找到POST请求的url 针对ajax页面请求的所对应url获取,需要用到浏览器的捉包工具.查看百度翻译针对某 ...
- 爬虫--urllib模块
一.urllib库 概念:urllib是Python自带的一个用于爬虫的库,其主要作用就是可以通过代码模拟浏览器发送请求.其常被用到的子模块在Python3中的为urllib.request和urll ...
- Python爬虫开发:反爬虫措施以及爬虫编写注意事项
随机推荐
- vue 手机物理返回键关闭弹框
1.打开弹窗调用 window.history.pishState() 函数 2.关闭弹框 3.mounted 生命周期 监听popstate 事件 4.beforeDestroy 生命周期 移除po ...
- Confluence 6 上传一个附加文件的新版本
有下面 2 种方法来上传一个附加文件的新版本,你可以: 上传与已有附件具有相同文件名的版本. 使用 上传一个新版本(Upload a new version) 按钮来进行上传(这个在文件预览界面中 ...
- Qbxt AH d4 && day-6
/* 这两天考试直接呵呵了. 赶脚对qbxt的题目无感. 同时也发现了自己的一些问题. 一些思路题总是自己傻逼的挖个坑跳进去. 这两天场场倒数ORZ. 始终是最弱的.... 然后NOIP光荣三等奖了吧 ...
- AtCoder AGC007E Shik and Travel (二分、DP、启发式合并)
题目链接 https://atcoder.jp/contests/agc007/tasks/agc007_e 题解 首先有个很朴素的想法是,二分答案\(mid\)后使用可行性DP, 设\(dp[u][ ...
- [转]java常量池理解总结
一.相关概念 什么是常量用final修饰的成员变量表示常量,值一旦给定就无法改变!final修饰的变量有三种:静态变量.实例变量和局部变量,分别表示三种类型的常量. Class文件中的常量池在Clas ...
- koa 基础(二十五)数据库 与 art-template 模板 联动 --- 新增数据
1.视图层 根目录/views/index.html <!DOCTYPE html> <html lang="en"> <head> <m ...
- spring boot知识清单
https://mp.weixin.qq.com/s/q8OI2Ou8-gYP-usjToBbkQ
- add_header 'Cache-Control' 'no-store, no-cache, must-revalidate, proxy-revalidate, max-age=0'
发送一个报头,告诉浏览器当前页面不进行缓存,每次访问的时间必须从服务器上读取最新的数据 一般情况下,浏览器为了加快浏览速度会对网页进行缓存,在一定时间内再次访问同一页面的时候会有缓存里面读取而不是从服 ...
- numpy之填充为nan的数据为该列平均值
# coding=utf-8 import numpy as np ''' 填充nan的数据,为该列的平均值 ''' def fill_ndarray(t1): for i in range(t1.s ...
- mongdb group聚合操作
1.数据准备 [{"goods_id":1,"cat_id":4,"goods_name":"KD876"," ...