《Hadoop》大数据技术开发实战学习笔记(二)
搭建Hadoop 2.x分布式集群
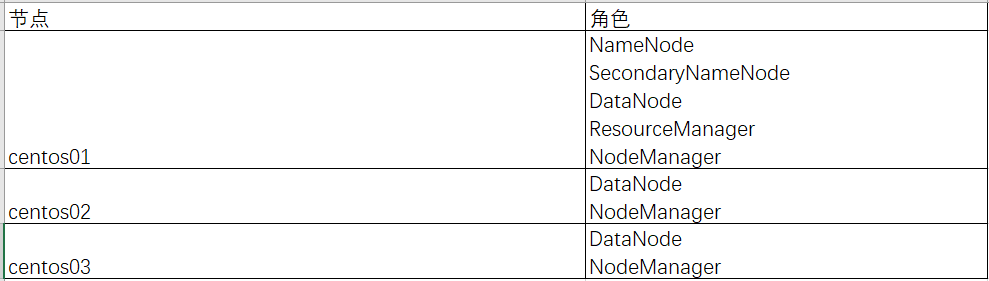
1、Hadoop集群角色分配
2、上传Hadoop并解压
在centos01中,将安装文件上传到/opt/softwares/目录,然后解压安装文件到/opt/modules/
cd /opt/softwares/tar -zxf hadoop-2.9.2.tar.gz -C /opt/modules/
3、配置环境变量
只需配置centos01节点即可,后续可通过远程复制。
a、修改文件/etc/profile
sudo nano /etc/profile
在文件末尾加入以下内容
export HADOOP_HOME=/opt/modules/hadoop-2.9.2export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
刷新profile文件,使修改生效
source /etc/profile
执行hadoop命令,若能成功输出信息,说明配置生效。
4、配置Hadoop环境变量
在安装目录下的etc/hadoop目录中,修改配置文件:
hadoop_env.shmapred-env.shyarn-env.sh
在以上的三个文件中加入JAVE_HOME环境变量
export JAVE_HOME=/opt/modules/jdk1.8.0_144
5、配置HDFS(略)
6、配置YARN(略)
7、复制Hadoop文件到其他主机
8、格式化NameNode
hadoop namenode -format
9、启动Hadoop
start-all.sh
(之后的笔记需要JAVA和SCALA基础,暂时弃坑)
《Hadoop》大数据技术开发实战学习笔记(二)的更多相关文章
- 《Hadoop大数据技术开发实战》学习笔记(一)
基于CentOS7系统 新建用户 1.使用"su-"命令切换到root用户,然后执行命令: adduser zonkidd 2.执行以下命令,设置用户zonkidd的密码: pas ...
- 超人学院Hadoop大数据技术资源分享
超人学院Hadoop大数据技术资源分享 http://bbs.superwu.cn/forum.php?mod=viewthread&tid=807&fromuid=645 很多其它精 ...
- java大数据最全课程学习笔记(1)--Hadoop简介和安装及伪分布式
Hadoop简介和安装及伪分布式 大数据概念 大数据概论 大数据(Big Data): 指无法在一定时间范围内用常规软件工具进行捕捉,管理和处理的数据集合,是需要新处理模式才能具有更强的决策力,洞察发 ...
- hadoop大数据技术架构详解
大数据的时代已经来了,信息的爆炸式增长使得越来越多的行业面临这大量数据需要存储和分析的挑战.Hadoop作为一个开源的分布式并行处理平台,以其高拓展.高效率.高可靠等优点越来越受到欢迎.这同时也带动了 ...
- 除Hadoop大数据技术外,还需了解的九大技术
除Hadoop外的9个大数据技术: 1.Apache Flink 2.Apache Samza 3.Google Cloud Data Flow 4.StreamSets 5.Tensor Flow ...
- 大数据技术之_09_Flume学习_Flume概述+Flume快速入门+Flume企业开发案例+Flume监控之Ganglia+Flume高级之自定义MySQLSource+Flume企业真实面试题(重点)
第1章 Flume概述1.1 Flume定义1.2 Flume组成架构1.2.1 Agent1.2.2 Source1.2.3 Channel1.2.4 Sink1.2.5 Event1.3 Flum ...
- 大数据技术之_19_Spark学习_01_Spark 基础解析 + Spark 概述 + Spark 集群安装 + 执行 Spark 程序
第1章 Spark 概述1.1 什么是 Spark1.2 Spark 特点1.3 Spark 的用户和用途第2章 Spark 集群安装2.1 集群角色2.2 机器准备2.3 下载 Spark 安装包2 ...
- 大数据技术之_16_Scala学习_01_Scala 语言概述
第一章 Scala 语言概述1.1 why is Scala 语言?1.2 Scala 语言诞生小故事1.3 Scala 和 Java 以及 jvm 的关系分析图1.4 Scala 语言的特点1.5 ...
- 大数据技术之_16_Scala学习_04_函数式编程-基础+面向对象编程-基础
第五章 函数式编程-基础5.1 函数式编程内容说明5.1.1 函数式编程内容5.1.2 函数式编程授课顺序5.2 函数式编程介绍5.2.1 几个概念的说明5.2.2 方法.函数.函数式编程和面向对象编 ...
随机推荐
- [USACO]骑马修栅栏 Riding the Fences
题目链接 题目简述:欧拉回路,字典序最小.没什么好说的. 解题思路:插入边的时候,使用multiset来保证遍历出出答案的字典序最小. 算法模板:for(枚举边) 删边(无向图删两次) 遍历到那个点 ...
- js图片上传 的方法
先规划出框架 <div id="AQA" style="width:300px; height:200px; background-color:aquamarine ...
- kubernetes 部署metricserver
本篇适用于kubeadm部署的k8s的集群 安装环境:首先要部署好k8s的集群,版本是1.11.1,我的虚拟机部署的,一个master节点,一个node节点.笔记本性能有限 下载metrics-ser ...
- linux系列(十八):locate命令
1.命令格式: locate [选择参数] [样式] 2.命令功能: locate指令和find找寻档案的功能类似,但locate是透过update程序将硬盘中的所有档案和目录资料先建立一个索引数据库 ...
- C++标准库分析总结(七)——<Hashtable、Hash_set、Hash_multiset、unordered容器设计原则>
编译器对关联容器的实现有两个版本,上一节总结了以红黑树做为基础的实现版本,这一节总结以哈希表(hash table,散列表)为底部结构的实现版本. 一.Hashtable简单介绍 Hashtable相 ...
- Java学习日记——基础篇(二)基本语法
变量 变量和常量是程序处理的两种基本数据对象,变量是程序的基本组成单位 变量的目的就是确定目标并提供存放空间 public class Hello { public static void main( ...
- 数据结构——KMP算法
算法介绍 KMP算法是一种改进的字符串匹配算法,由D.E.Knuth,J.H.Morris和V.R.Pratt提出的,因此人们称它为克努特—莫里斯—普拉特操作(简称KMP算法).KMP算法的核心是利用 ...
- 个人学习分布式专题(二)分布式服务治理之Dubbo框架
目录 Dubbo框架 1.1 Dubbo是什么 1.2 Dubbo企业级应用示例(略) 1.3 Dubbo实现原理及架构剖析 1.4 Dubbo+Spring集成 Dubbo框架 1.1 Dubbo是 ...
- 数据库——JavaWEB数据库连接
一.数据库连接的发展 1.数据库连接 用户每次请求都需要向数据库获得链接,而数据库创建连接通常需要消耗相对较大的资源,创建时间也较长.假设网站一天10万访问量,数据库服务器就需要创建10万次连接,极大 ...
- android: Context引起的内存泄露问题
错误的使用Context可能会导致内存泄漏,典型的例子就是单例模式时引用不合适的Context. public class SingleInstance { private static Single ...