python常用模块介绍
关于if __name__ == "__main__":
若执行文件为bin,调用文件为cal;
- 若在执行文件bin中执行print(__name__)
- 输出:__main__
- 当print(__name__)在调用文件中被调用执行则
- 输出当前调用文件的路径:lesson.web.web1.web2.cal
也就是说只有在执行文件中__name__才等于__main__
if __name__ == "__main__": 作用
- 用于执行文件时(#不想让其他人来调用)
- 用于调用文件时(#用于调用文件的测试)
time模块
- import time
- #----时间戳----
- print(time.time()) #时间戳:1542779690.9086285,用于计算
- #----当地时间----
- print(time.localtime(9999999999)) #结构化时间struct_time,默认参数是当前时间time.time()
- print(time.localtime().tm_year) #只打印年
- #----国际标准时间----UTC
- print(time.gmtime()) #按英国的算差8个小时
- #--------------------------------------------------------
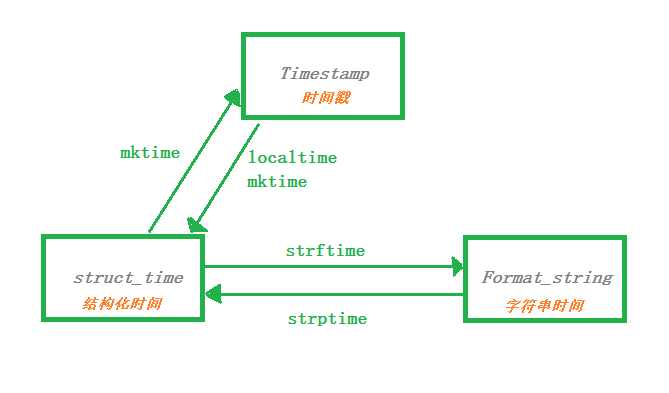
- #----将时间戳转换为结构化时间---- #Timestamp--->>>struct_time
- print(time.localtime(9999999999))
- #----将结构化时间转换为时间戳---- #struct_time--->>>Timestamp
- print(time.mktime(time.localtime()))
- #----将结构化时间转换成字符串时间---- #struct_time--->>>Formait_string
- print(time.strftime("%Y-%m-%d-%X",time.localtime())) #第一个参数是字符串时间的排布,第二个参数是结构化时间
- #----将字符串时间转换成结构化时间---- #Format_string--->>>struct_time
- print(time.strptime("2018-11-21-14:16:08","%Y-%m-%d-%X"))#第一个参数是字符串时间,第二个参数是时间排布,必须和第一个参数一一对应
- #直接看一个时间,不需要排布(固定)
- print(time.asctime()) #Wed Nov 21 14:24:48 2018,把一个结构化时间转换成固定的字符串表达形式
- print(time.ctime()) #Wed Nov 21 14:25:51 2018,把一个时间戳转换成固定格式的字符串
时间转换:
random模块
- import random
- print(random.random()) #随机取[0,1)的浮点数
- print(random.randint(1,5)) #随机取[1,5]的整数
- print(random.randrange(1,5)) #随机取[1,5)的整数
- print(random.choice([55,8,6,[11,22,33]])) #随机取出列表中的一个元素
- print(random.sample([55,8,6],2))#随机取出列表中的2个元素
- print(random.uniform(0,9))#随机取出任意范围的浮点型[0,9)
- #打乱顺序
- item = [1,3,5,7,9]
- random.shuffle(item)
- print(item)
- def inner():
- res = ""
- for i in range(4): #几位验证码就做几次循环
- num = random.randint(0,9) #随机生成0,9的数字
- alf = chr(random.randint(65,122)) #将随机生成的数字,用chr()转换成字母
- s = str(random.choice([num,alf])) #随机取出数字或字母
- res += s #拼接
- return res
- print(inner())
验证码
os模块
- import os
- print(os.getcwd()) #获取当前工作目录,即python脚本工作的路径
- print(os.chdir("lesson")) #改变当前脚本工作目录,相当于shell下的cd,返回上一级目录参数为("..")
- print(os.curdir) #返回当前目录:(".")
- print(os.pardir) #返回当前目录的父目录字符串名:("..")
- os.makedirs("dirname1/dirname2") #生成多层递归目录
- os.removedirs("dirname1/dirname2") #删除目录,若目录为空则删除,并递归到上级目录,如若也为空也删除,以此类推
- os.mkdir("dirname1") #生成单级目录,相当于shell中的mkdir dirname
- os.rmdir("dirname1") #删除单级空目录,若目录不为空则无法删除,报错,相当于shell中的 rmdir dirname
- print(os.listdir("lesson")) #列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印
- os.remove("lesson/__init__.py") #删除一个文件
- os.rename("test.py","dirname.py") #重命名文件/目录
- print(os.stat("bin.py"))#获取文件/目录信息,st_size=字节,st_atime=访问时间, st_mtime=修改时间, st_ctime=创建时间
- print(os.sep) #输出操作系统特定的分隔符,win下为"\",linux下为"/"
- print(os.linesep) #输出当前平台使用的行终止符(换行符),win下为"\r\n",Linux下为"\n"
- print(os.pathsep) #输出用于分割文件路径的字符串 win下为; linux下为:
- print(os.name) #输出字符串指示当前使用平台,win->"nt";linux->"posix"
- print(os.environ) #获取系统环境变量
- --------------------------------------------------------------------
- print(os.path.abspath("dirname.py")) #获取lesson的绝对路径
- print(os.path.split("D:\Python\小游戏\demo\lesson\")) #将dirname.py的绝对路径分割成目录和文件名按元祖返回
- print(os.path.dirname("D:\Python\小游戏\demo\lesson\dirname.py"))# 取路径
- print(os.path.basename("D:\Python\小游戏\demo\lesson\dirname.py")) #取文件名
- print(os.path.exists("lesson/dirname.py")) #判断文件存不存在,返回布尔值
- print(os.path.isabs("lesson\dirname.py")) #判断是否是绝对路径,返回布尔值
- print(os.path.isfile("lesson\dirname.py")) #判断dirname.py是否是一个存在的文件,返回布尔值
- print(os.path.isdir("lesson")) #判断lesson是否是一个存在的目录,返回布尔值
- a = "D:\Python\小游戏\demo"
- b = "lesson\dirname.py"
- print(os.path.join(a,b)) #路径拼接
- print(os.path.getatime("lesson")) #返回文件/目录的最后访问时间
- print(os.path.getmtime("lesson")) #返回文件/目录的最后修改时间
- print(os.path.getctime("lesson")) #返回文件/目录的最后创建时间
sys模块
- import sys
sys.exit(0) 退出程序- sys.version #获取python解释器程序的版本信息
- sys.maxint #最大int值
- sys.path #返回模块的搜索路径,初始化时使用PYTHONPATH环境变量的值
- print(sys.platform) #返回操作系统平台名称
- sys.argv #命令行参数list,第一个元素是程序本身路径
- import sys,time
- for i in range(100):
- sys.stdout.write("=") #屏幕打印
- time.sleep(0.1)
- sys.stdout.flush() #刷新,目的是不需要等到结果全部都拿到缓存在打印到屏幕上,而是拿到一个刷新缓存,打印一次;
进度条
引用: https://www.cnblogs.com/aland-1415/p/6613449.html
Python中 sys.argv[]的用法简明解释
sys.argv[]说白了就是一个从程序外部获取参数的桥梁,这个“外部”很关键,所以那些试图从代码来说明它作用的解释一直没看明白。因为我们从外部取得的参数可以是多个,所以获得的是一个列表(list),也就是说sys.argv其实可以看作是一个列表,所以才能用[]提取其中的元素。其第一个元素是程序本身,随后才依次是外部给予的参数。
下面我们通过一个极简单的test.py程序的运行结果来说明它的用法。
- 1 #test.py
- 2
- 3 import sys
- 4 a=sys.argv[0]
- 5 print(a)
将test.py保存在c盘的根目录下。
在程序中找到 ‘运行’->点击->输入"cmd"->回车键 进入控制台命令窗口(如下图),先输入cd c:\ (作用是将命令路径改到c盘根目录),然后输入test.py运行我们刚刚写的程序:
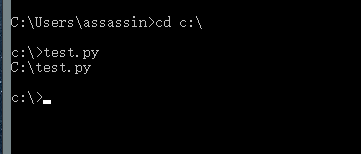
得到的结果是C:\test.py,这就是0指代码(即此.py程序)本身的意思。
然后我们将代码中0改为1 :
a=sys.argv[1]
保存后,再从控制台窗口运行,这次我们加上一个参数,输入:test.py what
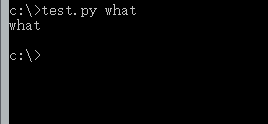
得到的结果就是我们输入的参数what,看到这里你是不是开始明白了呢。
那我们再把代码修改一下:
a=sys.argv[2:]
保存后,再从控制台窗台运行程序,这次多加几个参数,以空格隔开:
test.py a b c d e f
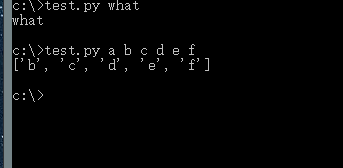
得到的结果为[‘b’, ’c’, ’d’, ’e’, ’f’]
应该大彻大悟了吧。Sys.argv[ ]其实就是一个列表,里边的项为用户输入的参数,关键就是要明白这参数是从程序外部输入的,而非代码本身的什么地方,要想看到它的效果就应该将程序保存了,从外部来运行程序并给出参数。
什么是序列化?
序列化 (Serialization)是指将对象、数据结构的状态信息转换为可以存储或传输的形式的过程。在序列化期间,对象将其当前状态写入到临时或持久性存储区。以后,可以通过从存储区中读取或反序列化对象的状态,重新创建该对象。
我们编写的程序,会涉及到各种各样的对象、数据结构,它们通常是以变量的形式在内存中存在着。当程序运行结束后,这些变量也就会被清理。但我们有时希望能够在下一次编写程序时恢复上一次的某个对象(如机器学习中的到结果,需要程序运行较长时间,多次运行时间成本太大),这就需要我们将变量进行持久化的存储。一种方式是利用文件读写的方式将变量转化为某种形式的字符串写入文件内,但需要自己控制存储格式显得十分笨拙。更好的方式是通过序列化的方式将变量持久化至本地。以下介绍json、pickle两种序列化方法;
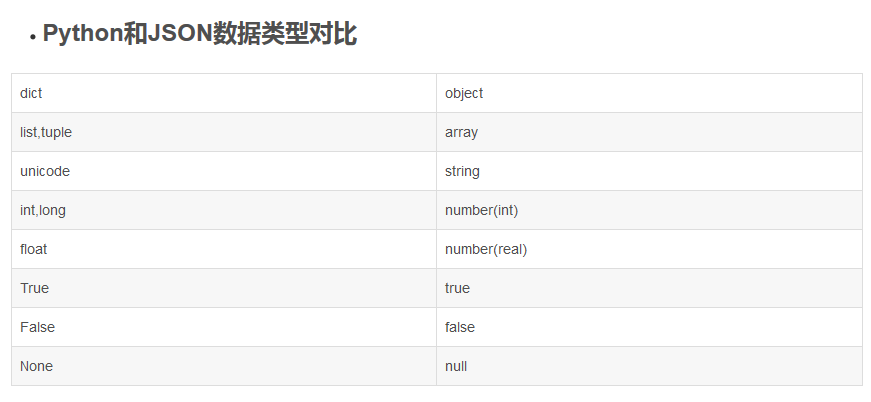
json模块
如果我们要在不同的编程语言之间传递对象,就必须把对象序列化为标准格式,比如XML,但更好的方法是json,因为json表示出来的就是字符串,可以被所有语言读取,也可以方便地存储到磁盘或者通过网络传输,json不仅是标准格式,并且比XML更快,而且可以直接在web页面中读取,非常方便;
- import json
- res = {"name":"szx"}
- with open("dict","w") as f:
- data = json.dumps(res) #将res转换成字符串,转换前的数据类型无论是单引号还是双引号,都会被转换成双引号;
- f.write(data) #将转换后的字符串写入文件
- print(data)
- print(type(data))
- with open("dict","r") as f:
- response = f.read() #将读取的结果保存
- s = json.loads(response) #将读取的结果恢复成之前的数据结构
- print(s)
- print(type(s))
- # {"name": "szx"}
- # <class 'str'>
- # {'name': 'szx'}
- # <class 'dict'>
#只要符合json的规范,文件中是双引号,就可以直接loads
pickle模块
注意:json与pickle最大的区别在于json转换后是str,pickle转换后是bytes;
- import pickle
- res = {"name":"szx","age":""}
- with open("dict","wb") as f:
- data = pickle.dumps(res) #将res转换成bytes类型
- f.write(data) #将转换后的字节写入文件,注意w是写入str,wb是写入bytes,data是bytes类型
- print(data)
- print(type(data))
- with open("dict","rb") as f:
- response = f.read() #将读取的结果保存
- s = pickle.loads(response) #将读取的结果恢复成之前的数据结构
- print(s)
- print(type(s))
- # b'\x80\x03}q\x00(X\x04\x00\x00\x00nameq\x01X\x03\x00\x00\x00szxq\x02X\x03\x00\x00\x00ageq\x03X\x02\x00\x00\x0018q\x04u.'
- # <class 'bytes'>
- # {'name': 'szx', 'age': '18'}
- # <class 'dict'>
XML模块
xml是实现不同语言或程序之间进行数据交换的协议,跟json差不多,但json使用起来更简单,不过,古时候,在json还没诞生的黑暗年代,大家只能选择用xml呀,至今很多传统公司如金融行业的很多系统的接口还主要是xml。
xml的格式如下,就是通过<>节点来区别数据结构的:
- <?xml version="1.0"?>
- <data>
- <country name="Liechtenstein">
- <rank updated="yes">2</rank>
- <year>2008</year>
- <gdppc>141100</gdppc>
- <neighbor name="Austria" direction="E"/>
- <neighbor name="Switzerland" direction="W"/>
- </country>
- <country name="Singapore">
- <rank updated="yes">5</rank>
- <year>2011</year>
- <gdppc>59900</gdppc>
- <neighbor name="Malaysia" direction="N"/>
- </country>
- <country name="Panama">
- <rank updated="yes">69</rank>
- <year>2011</year>
- <gdppc>13600</gdppc>
- <neighbor name="Costa Rica" direction="W"/>
- <neighbor name="Colombia" direction="E"/>
- </country>
- </data>
- xml数据
xml协议在各个语言里的都 是支持的,在python中可以用以下模块操作xml:
- for i in root:
- # print(i.tag)
- for j in i:
- #print(j.tag) #查看标签名
- #print(j.attrib) #打印标签属性
- #print(j.text) #查看标签内容
- # print(root.iter('year')) #全文搜索
- # print(root.find('country')) #在root的子节点找,只找一个
- # print(root.findall('country')) #在root的子节点找,找所有
- import xml.etree.ElementTree as ET
- tree = ET.parse("xmltest.xml")
- root = tree.getroot()
- print(root.tag)
- #遍历xml文档
- for child in root:
- print('========>',child.tag,child.attrib,child.attrib['name'])
- for i in child:
- print(i.tag,i.attrib,i.text)
- #只遍历year 节点
- for node in root.iter('year'):
- print(node.tag,node.text)
- #---------------------------------------
- import xml.etree.ElementTree as ET
- tree = ET.parse("xmltest.xml")
- root = tree.getroot()
- #修改
- for node in root.iter('year'):
- new_year=int(node.text)+1
- node.text=str(new_year)
- node.set('updated','yes')
- node.set('version','1.0')
- tree.write('test.xml')
- #删除node
- for country in root.findall('country'):
- rank = int(country.find('rank').text)
- if rank > 50:
- root.remove(country)
- tree.write('output.xml')
- #在country内添加(append)节点year2
- import xml.etree.ElementTree as ET
- tree = ET.parse("a.xml")
- root=tree.getroot()
- for country in root.findall('country'):
- for year in country.findall('year'):
- if int(year.text) > 2000:
- year2=ET.Element('year2')
- year2.text='新年'
- year2.attrib={'update':'yes'}
- country.append(year2) #往country节点下添加子节点
- tree.write('a.xml.swap')
自己创建XML文件
- import xml.etree.ElementTree as ET
- new_xml = ET.Element("namelist")
- name = ET.SubElement(new_xml,"name",attrib={"enrolled":"yes"})
- age = ET.SubElement(name,"age",attrib={"checked":"no"})
- sex = ET.SubElement(name,"sex")
- sex.text = ''
- name2 = ET.SubElement(new_xml,"name",attrib={"enrolled":"no"})
- age = ET.SubElement(name2,"age")
- age.text = ''
- et = ET.ElementTree(new_xml) #生成文档对象
- et.write("test.xml", encoding="utf-8",xml_declaration=True)
- ET.dump(new_xml) #打印生成的格式
logging模块
一 (简单应用)
- import logging
- logging.debug('debug message')
- logging.info('info message')
- logging.warning('warning message')
- logging.error('error message')
- logging.critical('critical message')
输出:
WARNING:root:warning message
ERROR:root:error message
CRITICAL:root:critical message
可见,默认情况下Python的logging模块将日志打印到了标准输出中,且只显示了大于等于WARNING级别的日志,这说明默认的日志级别设置为WARNING(日志级别等级CRITICAL
> ERROR > WARNING > INFO > DEBUG >
NOTSET),默认的日志格式为日志级别:Logger名称:用户输出消息。
二 灵活配置日志级别,日志格式,输出位置
- import logging
- logging.basicConfig(level=logging.DEBUG,
- format='%(asctime)s %(filename)s[line:%(lineno)d] %(levelname)s %(message)s',
- datefmt='%a, %d %b %Y %H:%M:%S',
- filename='/tmp/test.log',
- filemode='w')
- logging.debug('debug message')
- logging.info('info message')
- logging.warning('warning message')
- logging.error('error message')
- logging.critical('critical message')
查看输出:
cat /tmp/test.log
Mon, 05 May 2014 16:29:53 test_logging.py[line:9] DEBUG debug message
Mon, 05 May 2014 16:29:53 test_logging.py[line:10] INFO info message
Mon, 05 May 2014 16:29:53 test_logging.py[line:11] WARNING warning message
Mon, 05 May 2014 16:29:53 test_logging.py[line:12] ERROR error message
Mon, 05 May 2014 16:29:53 test_logging.py[line:13] CRITICAL critical message
可见在logging.basicConfig()函数中可通过具体参数来更改logging模块默认行为,可用参数有
filename:用指定的文件名创建FiledHandler(后边会具体讲解handler的概念),这样日志会被存储在指定的文件中。
filemode:文件打开方式,在指定了filename时使用这个参数,默认值为“a”还可指定为“w”。
format:指定handler使用的日志显示格式。
datefmt:指定日期时间格式。
level:设置rootlogger(后边会讲解具体概念)的日志级别
stream:用指定的stream创建StreamHandler。可以指定输出到sys.stderr,sys.stdout或者文件(f=open('test.log','w')),默认为sys.stderr。若同时列出了filename和stream两个参数,则stream参数会被忽略。
format参数中可能用到的格式化串:
%(name)s Logger的名字
%(levelno)s 数字形式的日志级别
%(levelname)s 文本形式的日志级别
%(pathname)s 调用日志输出函数的模块的完整路径名,可能没有
%(filename)s 调用日志输出函数的模块的文件名
%(module)s 调用日志输出函数的模块名
%(funcName)s 调用日志输出函数的函数名
%(lineno)d 调用日志输出函数的语句所在的代码行
%(created)f 当前时间,用UNIX标准的表示时间的浮 点数表示
%(relativeCreated)d 输出日志信息时的,自Logger创建以 来的毫秒数
%(asctime)s 字符串形式的当前时间。默认格式是 “2003-07-08 16:49:45,896”。逗号后面的是毫秒
%(thread)d 线程ID。可能没有
%(threadName)s 线程名。可能没有
%(process)d 进程ID。可能没有
%(message)s用户输出的消息
三 logger对象
上述几个例子中我们了解到了logging.debug()、logging.info()、logging.warning()、logging.error()、logging.critical()(分别用以记录不同级别的日志信息),logging.basicConfig()(用默认日志格式(Formatter)为日志系统建立一个默认的流处理器(StreamHandler),设置基础配置(如日志级别等)并加到root
logger(根Logger)中)这几个logging模块级别的函数,另外还有一个模块级别的函数是logging.getLogger([name])(返回一个logger对象,如果没有指定名字将返回root
logger)
先看一个最简单的过程:
- import logging
- logger = logging.getLogger()
- # 创建一个handler,用于写入日志文件
- fh = logging.FileHandler('test.log')
- # 再创建一个handler,用于输出到控制台
- ch = logging.StreamHandler()
- formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s')
- fh.setFormatter(formatter)
- ch.setFormatter(formatter)
- logger.addHandler(fh) #logger对象可以添加多个fh和ch对象
- logger.addHandler(ch)
- logger.debug('logger debug message')
- logger.info('logger info message')
- logger.warning('logger warning message')
- logger.error('logger error message')
- logger.critical('logger critical message')
先简单介绍一下,logging库提供了多个组件:Logger、Handler、Filter、Formatter。Logger对象提供应用程序可直接使用的接口,Handler发送日志到适当的目的地,Filter提供了过滤日志信息的方法,Formatter指定日志显示格式。
(1)
Logger是一个树形层级结构,输出信息之前都要获得一个Logger(如果没有显示的获取则自动创建并使用root Logger,如第一个例子所示)。
logger = logging.getLogger()返回一个默认的Logger也即root Logger,并应用默认的日志级别、Handler和Formatter设置。
当然也可以通过Logger.setLevel(lel)指定最低的日志级别,可用的日志级别有logging.DEBUG、logging.INFO、logging.WARNING、logging.ERROR、logging.CRITICAL。
Logger.debug()、Logger.info()、Logger.warning()、Logger.error()、Logger.critical()输出不同级别的日志,只有日志等级大于或等于设置的日志级别的日志才会被输出。
- logger.debug('logger debug message')
- logger.info('logger info message')
- logger.warning('logger warning message')
- logger.error('logger error message')
- logger.critical('logger critical message')
只输出了
2014-05-06 12:54:43,222 - root - WARNING - logger warning message
2014-05-06 12:54:43,223 - root - ERROR - logger error message
2014-05-06 12:54:43,224 - root - CRITICAL - logger critical message
从这个输出可以看出logger = logging.getLogger()返回的Logger名为root。这里没有用logger.setLevel(logging.Debug)显示的为logger设置日志级别,所以使用默认的日志级别WARNIING,故结果只输出了大于等于WARNIING级别的信息。
(2) 如果我们再创建两个logger对象:
- ##################################################
- logger1 = logging.getLogger('mylogger')
- logger1.setLevel(logging.DEBUG)
- logger2 = logging.getLogger('mylogger')
- logger2.setLevel(logging.INFO)
- logger1.addHandler(fh)
- logger1.addHandler(ch)
- logger2.addHandler(fh)
- logger2.addHandler(ch)
- logger1.debug('logger1 debug message')
- logger1.info('logger1 info message')
- logger1.warning('logger1 warning message')
- logger1.error('logger1 error message')
- logger1.critical('logger1 critical message')
- logger2.debug('logger2 debug message')
- logger2.info('logger2 info message')
- logger2.warning('logger2 warning message')
- logger2.error('logger2 error message')
- logger2.critical('logger2 critical message')
结果:

这里有两个个问题:
<1>我们明明通过logger1.setLevel(logging.DEBUG)将logger1的日志级别设置为了DEBUG,为何显示的时候没有显示出DEBUG级别的日志信息,而是从INFO级别的日志开始显示呢?
原来logger1和logger2对应的是同一个Logger实例,只要logging.getLogger(name)中名称参数name相同则返回的Logger实例就是同一个,且仅有一个,也即name与Logger实例一一对应。在logger2实例中通过logger2.setLevel(logging.INFO)设置mylogger的日志级别为logging.INFO,所以最后logger1的输出遵从了后来设置的日志级别。
<2>为什么logger1、logger2对应的每个输出分别显示两次?
这是因为我们通过logger = logging.getLogger()显示的创建了root Logger,而logger1 =
logging.getLogger('mylogger')创建了root
Logger的孩子(root.)mylogger,logger2同样。而孩子,孙子,重孙……既会将消息分发给他的handler进行处理也会传递给所有的祖先Logger处理。
ok,那么现在我们把
# logger.addHandler(fh)
# logger.addHandler(ch) 注释掉,我们再来看效果:
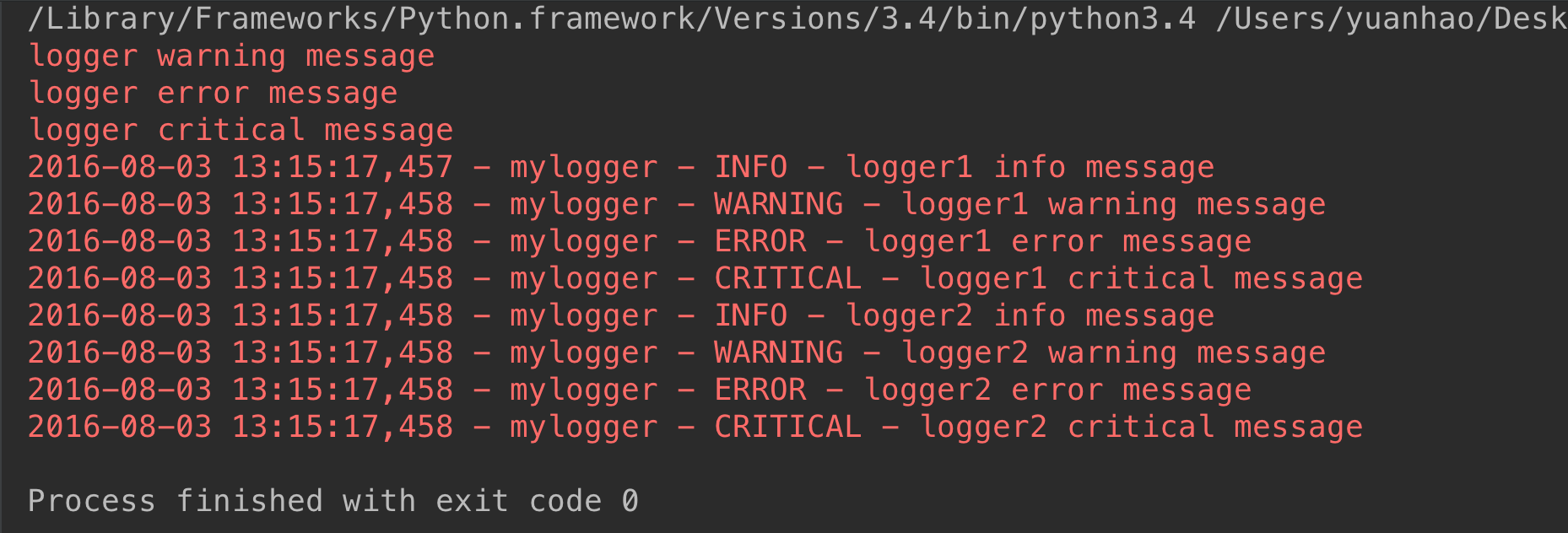
因为我们注释了logger对象显示的位置,所以才用了默认方式,即标准输出方式。因为它的父级没有设置文件显示方式,所以在这里只打印了一次。
孩子,孙子,重孙……可逐层继承来自祖先的日志级别、Handler、Filter设置,也可以通过Logger.setLevel(lel)、Logger.addHandler(hdlr)、Logger.removeHandler(hdlr)、Logger.addFilter(filt)、Logger.removeFilter(filt)。设置自己特别的日志级别、Handler、Filter。若不设置则使用继承来的值。
<3>Filter
限制只有满足过滤规则的日志才会输出。
比如我们定义了filter = logging.Filter('a.b.c'),并将这个Filter添加到了一个Handler上,则使用该Handler的Logger中只有名字带 a.b.c前缀的Logger才能输出其日志。
filter = logging.Filter('mylogger')
logger.addFilter(filter)
这是只对logger这个对象进行筛选
如果想对所有的对象进行筛选,则:
filter = logging.Filter('mylogger')
fh.addFilter(filter)
ch.addFilter(filter)
这样,所有添加fh或者ch的logger对象都会进行筛选。
完整代码1:
- import logging
- logger = logging.getLogger()
- # 创建一个handler,用于写入日志文件
- fh = logging.FileHandler('test.log')
- # 再创建一个handler,用于输出到控制台
- ch = logging.StreamHandler()
- formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s')
- fh.setFormatter(formatter)
- ch.setFormatter(formatter)
- # 定义一个filter
- filter = logging.Filter('mylogger')
- fh.addFilter(filter)
- ch.addFilter(filter)
- # logger.addFilter(filter)
- logger.addHandler(fh)
- logger.addHandler(ch)
- logger.setLevel(logging.DEBUG)
- logger.debug('logger debug message')
- logger.info('logger info message')
- logger.warning('logger warning message')
- logger.error('logger error message')
- logger.critical('logger critical message')
- ##################################################
- logger1 = logging.getLogger('mylogger')
- logger1.setLevel(logging.DEBUG)
- logger2 = logging.getLogger('mylogger')
- logger2.setLevel(logging.INFO)
- logger1.addHandler(fh)
- logger1.addHandler(ch)
- logger2.addHandler(fh)
- logger2.addHandler(ch)
- logger1.debug('logger1 debug message')
- logger1.info('logger1 info message')
- logger1.warning('logger1 warning message')
- logger1.error('logger1 error message')
- logger1.critical('logger1 critical message')
- logger2.debug('logger2 debug message')
- logger2.info('logger2 info message')
- logger2.warning('logger2 warning message')
- logger2.error('logger2 error message')
- logger2.critical('logger2 critical message')
完整代码2:
- #coding:utf-8
- import logging
- # 创建一个logger
- logger = logging.getLogger()
- logger1 = logging.getLogger('mylogger')
- logger1.setLevel(logging.DEBUG)
- logger2 = logging.getLogger('mylogger')
- logger2.setLevel(logging.INFO)
- logger3 = logging.getLogger('mylogger.child1')
- logger3.setLevel(logging.WARNING)
- logger4 = logging.getLogger('mylogger.child1.child2')
- logger4.setLevel(logging.DEBUG)
- logger5 = logging.getLogger('mylogger.child1.child2.child3')
- logger5.setLevel(logging.DEBUG)
- # 创建一个handler,用于写入日志文件
- fh = logging.FileHandler('/tmp/test.log')
- # 再创建一个handler,用于输出到控制台
- ch = logging.StreamHandler()
- # 定义handler的输出格式formatter
- formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s')
- fh.setFormatter(formatter)
- ch.setFormatter(formatter)
- #定义一个filter
- #filter = logging.Filter('mylogger.child1.child2')
- #fh.addFilter(filter)
- # 给logger添加handler
- #logger.addFilter(filter)
- logger.addHandler(fh)
- logger.addHandler(ch)
- #logger1.addFilter(filter)
- logger1.addHandler(fh)
- logger1.addHandler(ch)
- logger2.addHandler(fh)
- logger2.addHandler(ch)
- #logger3.addFilter(filter)
- logger3.addHandler(fh)
- logger3.addHandler(ch)
- #logger4.addFilter(filter)
- logger4.addHandler(fh)
- logger4.addHandler(ch)
- logger5.addHandler(fh)
- logger5.addHandler(ch)
- # 记录一条日志
- logger.debug('logger debug message')
- logger.info('logger info message')
- logger.warning('logger warning message')
- logger.error('logger error message')
- logger.critical('logger critical message')
- logger1.debug('logger1 debug message')
- logger1.info('logger1 info message')
- logger1.warning('logger1 warning message')
- logger1.error('logger1 error message')
- logger1.critical('logger1 critical message')
- logger2.debug('logger2 debug message')
- logger2.info('logger2 info message')
- logger2.warning('logger2 warning message')
- logger2.error('logger2 error message')
- logger2.critical('logger2 critical message')
- logger3.debug('logger3 debug message')
- logger3.info('logger3 info message')
- logger3.warning('logger3 warning message')
- logger3.error('logger3 error message')
- logger3.critical('logger3 critical message')
- logger4.debug('logger4 debug message')
- logger4.info('logger4 info message')
- logger4.warning('logger4 warning message')
- logger4.error('logger4 error message')
- logger4.critical('logger4 critical message')
- logger5.debug('logger5 debug message')
- logger5.info('logger5 info message')
- logger5.warning('logger5 warning message')
- logger5.error('logger5 error message')
- logger5.critical('logger5 critical message')
应用:
- import os
- import time
- import logging
- from config import settings
- def get_logger(card_num, struct_time):
- if struct_time.tm_mday < 23:
- file_name = "%s_%s_%d" %(struct_time.tm_year, struct_time.tm_mon, 22)
- else:
- file_name = "%s_%s_%d" %(struct_time.tm_year, struct_time.tm_mon+1, 22)
- file_handler = logging.FileHandler(
- os.path.join(settings.USER_DIR_FOLDER, card_num, 'record', file_name),
- encoding='utf-8'
- )
- fmt = logging.Formatter(fmt="%(asctime)s : %(message)s")
- file_handler.setFormatter(fmt)
- logger1 = logging.Logger('user_logger', level=logging.INFO)
- logger1.addHandler(file_handler)
- return logger1
python常用模块介绍的更多相关文章
- python 常用模块介绍
1.定义 模块:用来从逻辑上组织python代码(变量.函数.类,逻辑),本质就是.py结尾的python文件(文件名:test.py,对应的模块名:test). 包:用来从逻辑上组织模块的,本质就是 ...
- Python常用模块中常用内置函数的具体介绍
Python作为计算机语言中常用的语言,它具有十分强大的功能,但是你知道Python常用模块I的内置模块中常用内置函数都包括哪些具体的函数吗?以下的文章就是对Python常用模块I的内置模块的常用内置 ...
- python基础31[常用模块介绍]
python基础31[常用模块介绍] python除了关键字(keywords)和内置的类型和函数(builtins),更多的功能是通过libraries(即modules)来提供的. 常用的li ...
- python——常用模块
python--常用模块 1 什么是模块: 模块就是py文件 2 import time #导入时间模块 在Python中,通常有这三种方式来表示时间:时间戳.元组(struct_time).格式化的 ...
- python常用模块之subprocess
python常用模块之subprocess python2有个模块commands,执行命令的模块,在python3中已经废弃,使用subprocess模块来替代commands. 介绍一下:comm ...
- Python常用模块-时间模块(time&datetime)
Python常用模块-时间模块(time & datetime) 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.初始time模块 #!/usr/bin/env pyth ...
- python常用模块之time&datetime模块
python常用模块之time&datetime模块 在平常的代码中,我们经常要与时间打交道.在python中,与时间处理有关的模块就包括:time和datetime,下面分别来介绍: 在开始 ...
- python 常用模块 time random os模块 sys模块 json & pickle shelve模块 xml模块 configparser hashlib subprocess logging re正则
python 常用模块 time random os模块 sys模块 json & pickle shelve模块 xml模块 configparser hashlib subprocess ...
- Python常用模块之hashlib(加密)
Python常用模块之hashlib(加密) Python里面的hashlib模块提供了很多加密的算法,这里介绍一下hashlib的简单使用事例,用hashlib的md5算法加密数据import ha ...
随机推荐
- 怎样获取当前对象的原型对象prototype
1. 使用 Object.getPrototypeOf(); function Person(name){ this.name = name; } var lilei = new Person(&qu ...
- pickle 和 base64 模块的使用
pickle pickle模块是python的标准模块,提供了对于python数据的序列化操作,可以将数据转换为bytes类型,其序列化速度比json模块要高. pickle.dumps() 将pyt ...
- BufferInputStream、BufferOutputStream、BufferedReader、BufferedWriter、Java代码使用BufferedReader和BufferedWriter实现文本文件的拷贝
BufferInputStream和BufferOutputStream的特点: 缓冲字节输入输出流,缓冲流是处理流,它不直接连接数据源/目的地,而是以一个字节流为参数,在节点流的基础上提供一些简单操 ...
- vue嵌套数据多层级里面的数据不自动更新渲染dom
可以尝试手动调用更新 主要代码: vm.$forceUpdate() 官网
- 【Distributed】分布式系统中遇到的问题
一.概述  大型互联网公司公司一般都采用服务器集群,这样就要实现多个服务器之间的通讯,在nginx实现负载均衡(分布式解决方案)服务器集群会产生那些问题? 分布式锁(基本)单纯的Lock锁或者syn ...
- linux下setsockopt函数的使用
1.closesocket(一般不会立即关闭而经历TIME_WAIT的过程)后想继续重用该socket:BOOL bReuseaddr=TRUE;setsockopt(s,SOL_SOCKET ,SO ...
- rsync备份案例
客户端需求 1.客户端提前准备存放的备份的目录,目录规则如下:/backup/nfs_172.16.1.31_2018-09-02 2.客户端在本地打包备份(系统配置文件.应用配置等)拷贝至/back ...
- 安装mysql 好不容易成功了 却连不上
[mysqld] skip-grant-tables datadir=/var/lib/mysql socket=/var/lib/mysql/mysql.sock # Disabling symbo ...
- CentOs Linux 对于Django uwsgi + Nginx 的安装与部署
Django Nginx+uWSGI 安装配置 链接:
- webpack中shimming的概念
在webpack打包过程中会去做一些代码上的兼容,或者打包过程的兼容,比如之前使用过的babel-polyfill这个工具,他解决了es6代码在低版本浏览器的兼容.这就是webpack中的垫片.他解决 ...