Bloom Filter布隆过滤器原理和实现(1)
引子
《数学之美》介绍布隆过滤器非常经典:
在日常生活中,包括设计计算机软件时,经常要判断一个元素是否在一个集合中。比如:
- 在字处理软件中,需要检查一个英语单词是否拼写正确(也就是要判断它是否在已知的字典中);
- 在FBI,一个嫌疑人的名字是否已经在嫌疑犯的名单上;
- 在网络爬虫里,一个网站是否已访问过;
- yahoo, gmail等邮箱垃圾邮件过滤功能,等等 ...
以上场景需要解决的共同问题是:如何查看一件事物是否在有大量数据的集合里。
通常的做法有以下几种思路:
- 数组、
- 链表、
- 树、平衡二叉树、Trie
- map (红黑树)
- 哈希表
上面这几种数据结构配合一些搜索算法是可以解决数据量不大的问题,但当集合里面的数据量非常大的时候,就会出现问题。比如:有500万条记录甚至1亿条记录?这个时候常规的数据结构的问题就凸显出来了。数组、链表、树等数据结构会存储元素的内容,一旦数据量过大,消耗的内存也会呈现线性增长,最终达到瓶颈。哈希表查询效率可以达到O(1)。但是哈希表需要消耗的内存依然很高。使用哈希表存储一亿 个垃圾 email 地址的消耗?哈希表的做法:首先,哈希函数将一个email地址映射成8字节信息指纹;考虑到哈希表存储效率通常小于50%(哈希冲突);因此消耗的内存:8 * 2 * 1亿 字节 = 1.6GB 内存。因此,存储几十亿个邮件地址就可能需要上百GB的内存。除非是超级计算机,一般服务器是无法存储的。这个时候,布隆过滤器(Bloom Filter)就应运而生。
布隆过滤器
Bloom Filter是由伯顿 · 布隆(Burton Bloom)于1970年提出的。它实际上是一个很长的二进制向量和一系列随机映射函数。我们由上面的例子来说明其工作原理。
假定存储一亿个电子邮件地址,先建立一个16亿二进制(比特),即两亿字节的向量,然后将这个16亿二进制位全部清零。对于每一个电子邮件地址X,用8个不同的随机数产生器(F1,F2,...,F8)产生8个信息指纹(f1,f2,...,f8)。再用一个随机产生器G把这8个信息指纹映射到1-16亿中的8个自然数g1,g2,...,g8(其实就是8个哈希函数)。现在把这8个位置的二进制全部设置为1。对这一亿个电子邮件地址都进行这样的处理后,一个针对这些电子邮件地址的布隆过滤器就建成了。如下图。另外,上面为何一亿个电子邮件地址需要建16亿二进制位和取8个哈希函数。这里推荐一篇非常有名的博文,地址为:https://blog.csdn.net/jiaomeng/article/details/1495500,里面有证明一个结论:想要保持错误率低,最好让位数组有一半还空着。即16亿个二进制位最多有8亿个二进制位被置为1,误识别率就会降到很低。
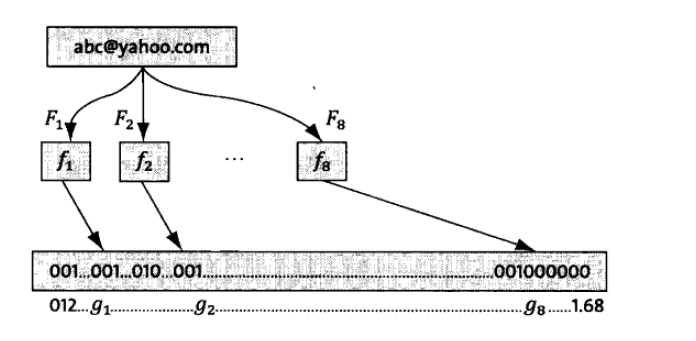
现在,让我们看看如何用布隆过滤器来监测一个可疑的电子邮件地址Y是否在黑名单中。用相同的8个随机产生器(F1,F2,...,F8)产生这个地址的8个信息指纹s1,s2,...,s8,然后将这个8个指纹对应到布隆过滤器的8个二进制位,分别为t1,t2,...,t8。如果Y在黑名单中,显然,t1,t2,...,t8对应的二进制数一定是1。这样,再遇到任何在黑名单中的电子邮件地址都能准确发现。布隆过滤器绝不会漏掉黑名单中的任何一个可疑地址。但是,它有一个不足之处。也就是它有极小的可能将一个不在黑名单中的电子邮件地址也判定为黑名单中,因为有可能某个好的邮件地址在布隆过滤器中对应的8个位置“恰巧”被(其他地址)设置为1。好在这种可能性很小。我们称之为误识别率。在上面的例子中,误识别率在万分之一以下。布隆过滤器的好处在于快速、省时间,但是有一定的误识别率。常见的补救办法是再建立一个小的白名单,存储那些可能被误判的邮件地址。
代码简单实现
#include <iostream>
#include <vector> using namespace std; class Bitmap {
public:
Bitmap(size_t size) : size_(size) {
bitVec_.resize((size_ >> ) + ); //多开辟一个空间,原因是数组只能表示区间[0,size)
}
void bitmapSet(int val) {
int index = val >> ; //相当于除以32,用移位操作可提高性能
int offset = val % ;
bitVec_[index] |= ( << offset);
}
bool bitmapGet(int val) {
int index = val >> ;
int offset = val % ;
return bitVec_[index] & ( << offset);
}
private:
size_t size_;
vector<unsigned int> bitVec_;
}; class BloomFilter {
private:
struct SimpleHash {
SimpleHash() {}
SimpleHash(size_t cap, size_t seed)
: cap_(cap), seed_(seed) {}
int hash(const std::string& s) {
int result = ;
for (auto c : s) {
result = result * seed_ + c;
}
return (cap_ - ) & result;
}
private:
size_t cap_;
size_t seed_;
}; enum { defaultSize = * }; //16亿 public:
BloomFilter() {
bitmap_ = new Bitmap(defaultSize);
hashs_.reserve(seeds_.size());
for (int i = ; i < seeds_.size(); ++i) {
SimpleHash* hash = new SimpleHash(defaultSize, seeds_[i]);
hashs_.push_back(hash);
}
}
~BloomFilter() {
delete bitmap_;
for (auto h : hashs_) {
delete h;
}
}
void add(const string& s) {
for (auto h : hashs_) {
bitmap_->bitmapSet(h->hash(s));
}
}
bool contain(const string& s) {
bool ret = true;
for (auto h : hashs_) {
ret = ret && bitmap_->bitmapGet(h->hash(s));
}
return ret;
} private:
std::vector<int> seeds_ = { , , , , , , , }; //还不是随机生成
std::vector<SimpleHash*> hashs_;
Bitmap* bitmap_;
}; void bloomFilterTest() {
std::string email = "1293173298@qq.com";
BloomFilter bf;
bf.add(email);
bool ret1 = bf.contain(email);
bool ret2 = bf.contain("even.com");
} int main() {
bloomFilterTest(); system("pause");
return ;
}
Bloom Filter布隆过滤器原理和实现(1)的更多相关文章
- 【转】Bloom Filter布隆过滤器的概念和原理
转自:http://blog.csdn.net/jiaomeng/article/details/1495500 之前看数学之美丽,里面有提到布隆过滤器的过滤垃圾邮件,感觉到何其的牛,竟然有这么高效的 ...
- 硬核 | Redis 布隆(Bloom Filter)过滤器原理与实战
在Redis 缓存击穿(失效).缓存穿透.缓存雪崩怎么解决?中我们说到可以使用布隆过滤器避免「缓存穿透」. 码哥,布隆过滤器还能在哪些场景使用呀? 比如我们使用「码哥跳动」开发的「明日头条」APP 看 ...
- Bloom Filter(布隆过滤器)的概念和原理
Bloom filter 适用范围:可以用来实现数据字典,进行数据的判重,或者集合求交集 基本原理及要点: 对于原理来说很简单,位数组+k个独立hash函数.将hash函数对应的值的位数组置1,查找时 ...
- Bloom Filter 布隆过滤器
Bloom Filter 是由伯顿.布隆(Burton Bloom)在1970年提出的一种多hash函数映射的快速查找算法.它实际上是一个很长的二进制向量和一些列随机映射函数.应用在数据量很大的情况下 ...
- 海量信息库,查找是否存在(bloom filter布隆过滤器)
Bloom Filter(布隆过滤器) 布隆过滤器用于测试某一元素是否存在于给定的集合中,是一种空间利用率很高的随机数据结构(probabilistic data structure),存在一定的误识 ...
- Bloom Filter概念和原理【转】
Bloom Filter概念和原理 Bloom Filter是一种空间效率很高的随机数据结构,它利用位数组很简洁地表示一个集合,并能判断一个元素是否属于这个集合.Bloom Filter的这种高效是有 ...
- 大数据处理算法--Bloom Filter布隆过滤
1. Bloom-Filter算法简介 Bloom-Filter,即布隆过滤器,1970年由Bloom中提出.它可以用于检索一个元素是否在一个集合中. Bloom Filter(BF)是一种空间效率很 ...
- Bloom Filter 概念和原理
Bloom filter 是由 Howard Bloom 在 1970 年提出的二进制向量数据结构,它具有很好的空间和时间效率,被用来检测一个元素是不是集合中的一个成员.如果检测结果为是,该元素不一定 ...
- Bloom Filter概念和原理
Bloom Filter是一种空间效率很高的随机数据结构,它利用位数组很简洁地表示一个集合,并能判断一个元素是否属于这个集合.Bloom Filter的这种高效是有一定代价的:在判断一个元素是否属于某 ...
随机推荐
- luogu 2331
给出 $n * 1$ 的矩阵,选出 $k$ 个互不重叠的子矩阵,使得其最大$sum[i]$ 为列的前缀和设 $f[i][j]$ 表示前 $i$ 个数选出 $j$ 个互不重叠的子矩阵的最大价值若第 $i ...
- windows平台下MySQl的安装、破解和使用
#1.下载:MySQL Community Server 5.7.16 http://dev.mysql.com/downloads/mysql/ #2.解压 如果想要让MySQL安装在指定目录,那么 ...
- SpringMVC配置 事务管理
1.确保持久层配置完毕 2.pom.xml里追加spring-tx 3.application-context.xml追加 <bean id="transactionManager&q ...
- 内存管理2-@class关键字
Review: 给对象发送消息,进行相应的计数器操作. Retain消息:使计数器+1,改方法返回对象本身 Release消息:使计数器-1(并不代表释放对象) retainCount消息:获得对象当 ...
- shell uniq 统计,计数
uniq选项与参数-i:忽略大小写-c:进行计数[zhang@localhost ~]$ cat 2.txt helloHelloWOrldabcabcABChello1 对2.txt进行sort后, ...
- HDU 1114 Piggy-Bank ——(完全背包)
差不多是一个裸的完全背包,只是要求满容量的最小值而已.那么dp值全部初始化为inf,并且初始化一下dp[0]即可.代码如下: #include <stdio.h> #include < ...
- oracle查找表索引信息
select owner,index_name,index_type from all_indexes where owner='xxxx' and table_name='xxx' select * ...
- 从 10.x 到 ArcGIS Pro 的 Python 迁移
与 ArcGIS Pro 结合使用 Python 的方式与包括 ArcGIS Desktop.ArcGIS Server 以及 ArcGIS Engine 在内的其他 ArcGIS 产品不同. 地理处 ...
- Memcache启动停止
启动Memcached root -P /var/run/memcached.pid 1)启动参数说明: -d 选项是启动一个守护进程, -l 是监听的服务器IP地址,默认为所有网卡. -p 是设置M ...
- SpringBoot之HandlerInterceptor拦截器的使用 ——(一)
HandlerInterceptor简介拦截器我想大家都并不陌生,最常用的登录拦截.或是权限校验.或是防重复提交.或是根据业务像12306去校验购票时间,总之可以去做很多的事情.我仔细想了想这里我分三 ...