【JAVA并发编程实战】5、构建高效且可伸缩的结果缓存
首先创建一个借口,用来表示耗费资源的计算
package cn.xf.cp.ch05; public interface Computable<A, V>
{
V compute(A arg) throws Exception;
}
实现接口,实现计算过程
package cn.xf.cp.ch05; import java.io.BufferedReader;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.math.BigInteger; public class ExpensiveFunction implements Computable<String, BigInteger>
{ @Override
public BigInteger compute(String arg) throws InterruptedException
{
//读取10个文件的和
BigInteger count = new BigInteger("0");
File file = null;
InputStreamReader is = null;
BufferedReader br = null;
try
{
file = new File(String.valueOf(arg));
is = new InputStreamReader(new FileInputStream(file));
br = new BufferedReader(is);
String line = "";
while((line = br.readLine()) != null)
{
String longdata[] = line.split(" ");
for(int j = 0; j < longdata.length; ++j)
{
//统计和
String temp = longdata[j];
BigInteger bitemp = new BigInteger(temp);
count = count.add(bitemp);
}
}
}
catch (Exception e)
{
e.printStackTrace();
}
finally
{
try
{
br.close();
is.close();
}
catch (IOException e)
{
e.printStackTrace();
}
}
//返回统计结果
return count;
} @org.junit.Test
public void test()
{
String s = "132456789123456789326549873218746132165432176134653216874649761";
BigInteger bi = new BigInteger("0"); System.out.println(bi.add(new BigInteger("1")).toString());
}
}
功能实现1,这个不是现场安全的,就是一个简单的缓存机制,如果有就直接从缓存中获取,没有的话就添加到缓存中
package cn.xf.cp.ch05; import java.util.HashMap;
import java.util.Map; public class Memoizer1<A, V> implements Computable<A, V>
{
/**
* 这里使用hashmap来作为缓存对象,其实并不是一个好的选择,hashmap并不是一个线程安全的类
*/
private final Map<A, V> cache = new HashMap<A, V>();
private final Computable<A, V> c; public Memoizer1(Computable<A, V> c)
{
//初始化C的值
this.c = c;
} /**
* 由于hashmap并不是一个线程安全的,所以我们队这个操作加锁,避免意外
* 但是如果有一个问题,如果一个线程阻塞了这个方法,那么其他线程就无法通过这个方法获取到对应的缓存
* 那么就可能会造成使用缓存的结果却比不使用缓存更慢,性能并不会得到任何的提升
* @param arg
* @return
* @throws InterruptedException
*/
@Override
public synchronized V compute(A arg) throws Exception
{
V result = cache.get(arg);
if(result == null)
{
result = c.compute(arg);
//如果没有的话,那么就放到对应的缓存对象中
cache.put(arg, result);
}
return result;
} }
功能实现2:添加一个future进行异步处理,就是把原来的数据计量分化到异步处理中,这样就不会产生阻塞在一个地方,造成其他线程等待很耗费资源的计算产生结果的问题
package cn.xf.cp.ch05; import java.util.Map;
import java.util.concurrent.Callable;
import java.util.concurrent.ConcurrentHashMap;
import java.util.concurrent.Future;
import java.util.concurrent.FutureTask; public class Memoizer2<A, V> implements Computable<A, V>
{
private final Map<A, Future<V>> cache = new ConcurrentHashMap<A, Future<V>>();
private final Computable<A, V> c; public Memoizer2(Computable<A, V> c)
{
this.c = c;
} /**
* 这个里面的复合操作,没有就添加future,是在底层的MAP对象上执行的,而map无法通过加锁来确定原子性
*/
@Override
public V compute(final A arg) throws Exception
{
Future<V> f = cache.get(arg);
if (f == null)
{
Callable<V> eval = new Callable<V>()
{
public V call() throws Exception
{
return c.compute(arg);
}
};
FutureTask<V> ft = new FutureTask<V>(eval);
f = ft;
cache.put(arg, ft);
ft.run(); // call to c.compute happens here
}
return f.get();
} }
功能实现3:避免底层map的操作有影响,并防止缓存污染
package cn.xf.cp.ch05; import java.util.concurrent.Callable;
import java.util.concurrent.ConcurrentHashMap;
import java.util.concurrent.ConcurrentMap;
import java.util.concurrent.Future;
import java.util.concurrent.FutureTask; public class Memoizer3<A, V> implements Computable<A, V>
{ private final ConcurrentMap<A, Future<V>> cache = new ConcurrentHashMap<A, Future<V>>();
private final Computable<A, V> c; public Memoizer3(Computable<A, V> c)
{
this.c = c;
} @Override
public V compute(final A arg) throws Exception
{
//不断循环,直到return
while (true)
{
Future<V> f = cache.get(arg);
if (f == null)
{
Callable<V> eval = new Callable<V>()
{
public V call() throws Exception
{
return c.compute(arg);
}
};
FutureTask<V> ft = new FutureTask<V>(eval);
/*
* 确定使用,这个避免重复添加
* 如果包含arg就返回,否则就把ft放入进去
*/
f = cache.putIfAbsent(arg, ft);
if (f == null)
{
f = ft;
ft.run();
}
}
try
{
//返回计算结果
return f.get();
}
catch (Exception e)
{
//计算失败,从缓存中移除,避免缓存污染,就是一个key返回一个空值,并返回从新运算
cache.remove(arg, f);
}
}
} }
测试结果:
package cn.xf.cp.ch05; import java.math.BigInteger; public class MemeryTest
{
public static void main(String[] args) throws Exception
{
ExpensiveFunction ef = new ExpensiveFunction();
Memoizer1<String, BigInteger> m = new Memoizer1<String, BigInteger>(ef);
BigInteger bresult1 = new BigInteger("0");
BigInteger bresult2 = new BigInteger("0");
//比较不同方式统计10次1文件的时间比较
long start1 = System.nanoTime();
for(int i = 1; i <= 10; ++i)
{
bresult1 = bresult1.add(ef.compute(String.valueOf(1)));
}
long end1 = System.nanoTime(); long start2 = System.nanoTime();
for(int i = 1; i <= 10; ++i)
{
bresult2 = bresult2.add(m.compute(String.valueOf(1)));
}
long end2 = System.nanoTime(); System.out.println("统计文件1~10使用时间" + (end1 - start1) + " 大小是:" + bresult1.toString()); System.out.println("统计文件1,10次使用时间" + (end2 - start2) + " 大小是:" + bresult2.toString());
} @org.junit.Test
public void test2() throws Exception
{
ExpensiveFunction ef = new ExpensiveFunction();
Memoizer2<String, BigInteger> m = new Memoizer2<String, BigInteger>(ef);
BigInteger bresult1 = new BigInteger("0");
BigInteger bresult2 = new BigInteger("0");
//比较不同方式统计10次1文件的时间比较
long start1 = System.nanoTime();
for(int i = 1; i <= 10; ++i)
{
bresult1 = bresult1.add(ef.compute(String.valueOf(1)));
}
long end1 = System.nanoTime(); long start2 = System.nanoTime();
for(int i = 1; i <= 10; ++i)
{
bresult2 = bresult2.add(m.compute(String.valueOf(1)));
}
long end2 = System.nanoTime(); System.out.println("统计文件1~10使用时间" + (end1 - start1) + " 大小是:" + bresult1.toString()); System.out.println("统计文件1,10次使用时间" + (end2 - start2) + " 大小是:" + bresult2.toString()); } @org.junit.Test
public void test3() throws Exception
{ ExpensiveFunction ef = new ExpensiveFunction();
Memoizer3<String, BigInteger> m = new Memoizer3<String, BigInteger>(ef);
BigInteger bresult1 = new BigInteger("0");
BigInteger bresult2 = new BigInteger("0");
//比较不同方式统计10次1文件的时间比较
long start1 = System.nanoTime();
for(int i = 1; i <= 10; ++i)
{
bresult1 = bresult1.add(ef.compute(String.valueOf(1)));
}
long end1 = System.nanoTime(); long start2 = System.nanoTime();
for(int i = 1; i <= 10; ++i)
{
bresult2 = bresult2.add(m.compute(String.valueOf(1)));
}
long end2 = System.nanoTime(); System.out.println("统计文件1~10使用时间" + (end1 - start1) + " 大小是:" + bresult1.toString()); System.out.println("统计文件1,10次使用时间" + (end2 - start2) + " 大小是:" + bresult2.toString()); }
}
结果就是使用了缓存的话,速度会快10倍,这个决定于循环的次数
文件的话,就是简单的循环生成数据

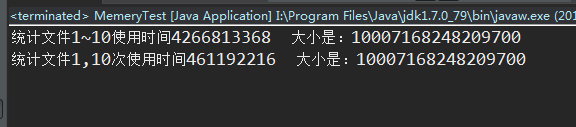
三种测试结果,差不多,因为这里并没有使用到多线程进行测试,结果和单线程是一样的。
【JAVA并发编程实战】5、构建高效且可伸缩的结果缓存的更多相关文章
- java并发编程实战学习(3)--基础构建模块
转自:java并发编程实战 5.3阻塞队列和生产者-消费者模式 BlockingQueue阻塞队列提供可阻塞的put和take方法,以及支持定时的offer和poll方法.如果队列已经满了,那么put ...
- 《java并发编程实战》读书笔记4--基础构建模块,java中的同步容器类&并发容器类&同步工具类,消费者模式
上一章说道委托是创建线程安全类的一个最有效策略,只需让现有的线程安全的类管理所有的状态即可.那么这章便说的是怎么利用java平台类库的并发基础构建模块呢? 5.1 同步容器类 包括Vector和Has ...
- Java并发编程实战 第5章 构建基础模块
同步容器类 Vector和HashTable和Collections.synchronizedXXX 都是使用监视器模式实现的. 暂且不考虑性能问题,使用同步容器类要注意: 只能保证单个操作的同步. ...
- java并发编程实战笔记---(第五章)基础构建模块
. 5.1同步容器类 1.同步容器类的问题 复合操作,加容器内置锁 2.迭代器与concurrentModificationException 迭代容器用iterator, 迭代过程中,如果有其他线程 ...
- 《Java并发编程实战》读书笔记-第5章 基础构建模块
同步容器类 同步容器类实现线程安全的方式:将所有状态封装起来,对每个公有方法使用同步,使得每一次只有一个线程可以访问.同步容器类包含:Vector.Hashtable.Collections.sync ...
- 《Java并发编程实战》/童云兰译【PDF】下载
<Java并发编程实战>/童云兰译[PDF]下载链接: https://u253469.pipipan.com/fs/253469-230062521 内容简介 本书深入浅出地介绍了Jav ...
- Java并发(具体实例)—— 构建高效且可伸缩的结果缓存
这个例子来自<Java并发编程实战>第五章.本文将开发一个高效且可伸缩的缓存,文章首先从最简单的HashMap开始构建,然后分析它的并发缺陷,并一步一步修复. hashMap版本 ...
- Java并发编程实战——读后感
未完待续. 阅读帮助 本文运用<如何阅读一本书>的学习方法进行学习. P15 表示对于书的第15页. Java并发编程实战简称为并发书或者该书之类的. 熟能生巧,不断地去理解,就像欣赏一部 ...
- 【java并发编程实战】-----线程基本概念
学习Java并发已经有一个多月了,感觉有些东西学习一会儿了就会忘记,做了一些笔记但是不系统,对于Java并发这么大的"系统",需要自己好好总结.整理才能征服它.希望同仁们一起来学习 ...
- 《java并发编程实战》笔记
<java并发编程实战>这本书配合并发编程网中的并发系列文章一起看,效果会好很多. 并发系列的文章链接为: Java并发性和多线程介绍目录 建议: <java并发编程实战>第 ...
随机推荐
- 每天一个linux命令(49):at命令
在windows系统中,windows提供了计划任务这一功能,在控制面板 -> 性能与维护 -> 任务计划, 它的功能就是安排自动运行的任务. 通过'添加任务计划'的一步步引导,则可建立一 ...
- Java接口总结
接口的定义: 使用interface来定义一个接口.接口定义与类的定义类似,也是分为接口的声明和接口体,其中接口体由变量定义和方法定义两部分组成,定义接口的基本语法如下: [修饰符] interfac ...
- 如何用注解简化SSH框架
一.简化代码第一步,删除映射文件,给实体类加上注解 @Entity //声明当前类为hibernate映射到数据库中的实体类 @Table(name="news") //声明tab ...
- FreeBSD_11-系统管理——{Part_7 - AUDIT}
相关概念 EVENT 事件,审计系统计录的对象,包括用户登陆.网络与文件操作等各方面 CLASS 类,对具有相同或类似属性的事件的分組 RECORD 记录,审计系统生成的日志中的每一条信息 TRAIL ...
- SQL 笔记 By 华仔
-------------------------------------读书笔记------------------------------- 笔记1-徐 最常用的几种备份方法 笔记2-徐 收缩数据 ...
- Sql Server系列:Select基本语句
1 T-SQL中SELECT语法结构 <SELECT statement> ::= [WITH <common_table_expression> [,...n]] <q ...
- ios语音输入崩溃
游戏中任何可以输入的地方,只要调用语音输入,必然会导致app崩溃,解决方法如下: ok, so essentially the gist of it is that siri wants gl con ...
- String,StringBuffer与StringBuilder的区别??
转自http://blog.csdn.net/rmn190/article/details/1492013 String 字符串常量 StringBuffer 字符串变量(线程安全) StringBu ...
- react-native 学习之TextInput组件篇
/** * Sample React Native App * https://github.com/facebook/react-native */ 'use strict'; import Rea ...
- 响应式web布局中iframe的自适应
困境 在响应式布局中,我们应该小心对待iframe元素,iframe元素的width和height属性设置了其宽度和高度,但是当包含块的宽度或高度小于iframe的宽度或高度时,会出现iframe元素 ...