SQLSERVER大批量数据快速导入Redis
目的
把单表近5千万的某单个字段导入到Redis,作为一个list存储。
方案一: 使用sqlcmd工具(sqlserver自带),直接生成命令在Redis-cli中执行。
方案一. 使用sqlcmd把打印结果输出在文本中,然后用redis-cli逐行执行文本中的命令。
redis写入list的命令。
LPUSH openids xxxx
- 用sqlserver拼接处这个结果
SET NOCOUNT ON;
SELECT 'LPUSH openids ' +'"' + openID +'"'
FROM [dbo].[table1]
- 使用sqlcmd,推送到redis-cli执行
# -S:服务器地址,-U:账号名 -P:密码 -d:数据库 -h:列标题之间打印的行数
sqlcmd -S . -U sa -P xxxx -d DataImport -h -1 -i d:\openid.sql | redis-cli -h 192.168.xx.xx -a xxxx -p 6379
结论
- 能勉强成功。
- 导入速度慢,大概2w/s ~ 3w/s。远低于Redis的写入理想值。
- 容易出错,如果value中含有意外字符,会导致命令执行失败,结束任务。
- 别用这个方法。
官网支撑:
Redis is a TCP server using the client-server model and what is called a Request/Response protocol.
This means that usually a request is accomplished with the following steps:
The client sends a query to the server, and reads from the socket, usually in a blocking way, for the server response.
The server processes the command and sends the response back to the client.
方案二: 使用sqlcmd工具(sqlserver自带),直接生成redis协议在Redis-cli中执行。(可以直接看这个方案)
使用sqlserver直接生成协议命令
--*3:由三个参数组成:LPUSH,key,value。
--$5: 'LPUSH'的字符串长度。
--$7: 'openids'的字符串长度。
--$n: {value}的长度
--char(13): /r
--char(10): /n
SET NOCOUNT ON;
SELECT '*3'+char(13)+CHAR(10) + '$5'+char(13)+CHAR(10) + 'LPUSH'+char(13)+CHAR(10) + '$7'+char(13)+CHAR(10)
+ 'openids'+char(13)+CHAR(10) +'$'+ CAST(DATALENGTH(openID) as varchar(255)) +char(13)+CHAR(10)+openID+char(13)+CHAR(10)
FROM [dbo].[table1]
# --pipe 使用管道模式
sqlcmd -S . -U sa -P xxxx -d DataImport -h -1 -i d:\openid.sql | redis-cli -h 192.168.xx.xx -a xxxx -p 6379 --pipe
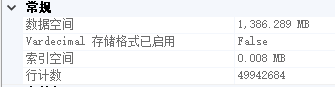
执行效果:

(为什么只有2660万条呢?因为我分两次运行了)

结论:
- 不会受value的影响,中断运行。
- 运行速度快,差不多13w/s。接近理想值。
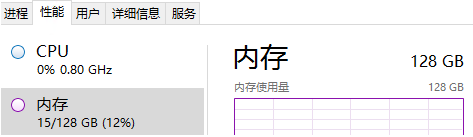
- 亲测,第一次在写入2800万的时候,我的128G内存撑不住了,Redis直接崩了。所以,我选择rownumber() over()从中断的地方,继续写入。
官网支撑:
Using a normal Redis client to perform mass insertion is not a good idea for a few reasons: the naive approach of sending one command after the other is slow because you have to pay for the round trip time for every command. It is possible to use pipelining, but for mass insertion of many records you need to write new commands while you read replies at the same time to make sure you are inserting as fast as possible.
Only a small percentage of clients support non-blocking I/O, and not all the clients are able to parse the replies in an efficient way in order to maximize throughput. For all this reasons the preferred way to mass import data into Redis is to generate a text file containing the Redis protocol, in raw format, in order to call the commands needed to insert the required data.
附:
# sqlcmd导出到文本
sqlcmd -S . -U sa -P xxx -d DataImport -h -1 -i d:\openid.sql > d:\tt.txt
# 从文本推到redis-cli执行。
type protocol-commands.txt | redis-cli -h 192.168.xx.xx -a xxxx -p 6379 --pipe
把redis的正常命令转成协议格式的批处理脚本
亲测,近5千万数据的文本,是动都动不了。
while read CMD; do
# each command begins with *{number arguments in command}\r\nW
XS=($CMD); printf "*${#XS[@]}\r\n"WWW
# for each argument, we append ${length}\r\n{argument}\r\n
for X in $CMD; do printf "\$${#X}\r\n$X\r\n"; done
done < origin-commands.txt
协议样本:
*3
$5
LPUSH
$3
arr
$4
AAAA
*3
$5
LPUSH
$3
arr
$4
BBBB
SQLSERVER大批量数据快速导入Redis的更多相关文章
- Mysql百万数据量级数据快速导入Redis
前言 随着系统的运行,数据量变得越来越大,单纯的将数据存储在mysql中,已然不能满足查询要求了,此时我们引入Redis作为查询的缓存层,将业务中的热数据保存到Redis,扩展传统关系型数据库的服务能 ...
- 54.超大数据快速导入MySQL
超大数据快速导入MySQL ----千万级数据只需几十分钟本地测试方法1.首先需要修改本地mysql的编码和路径,找到my.ini.2.在里面添加或修改 character-set-server=u ...
- [DJANGO] excel十几万行数据快速导入数据库研究
先贴原来的导入数据代码: 8 import os os.environ.setdefault("DJANGO_SETTINGS_MODULE", "www.setting ...
- excel十几万行数据快速导入数据库研究(转,下面那个方法看看还是可以的)
先贴原来的导入数据代码: 8 import os os.environ.setdefault("DJANGO_SETTINGS_MODULE", "www.setting ...
- 将mysql表数据批量导入redis zset结构中
工作中有这样一个需求,要将用户的魅力值数据做排行,生成榜单展示前40名,每隔5分钟刷新一次榜单.这样的需求用redis的zset是很方便实现的.但是数据存在mysql的表中,有400多万条,怎么将其快 ...
- Mysql --学习:大量数据快速导入导出
声明:此文供学习使用,原文:https://blog.csdn.net/xiaobaismiley/article/details/41015783 [实验背景] 项目中需要对数据库中一张表进行重新设 ...
- HBase数据快速导入之ImportTsv&Bulkload
导入数据最快的方式,可以略过WAL直接生产底层HFile文件 (环境:centos6.5.Hadoop2.6.0.HBase0.98.9) 1.SHELL方式 1.1 ImportTsv直接导入 命令 ...
- Mysql 千万数据快速导入
最近碰到个项目,需要 千万条数据入库的问题,有原本的 类 csv 文件导入, 统计了下 数据行大概有 1400W 行之多 二话不说, 建表,直接 load LOAD DATA LOCAL INFIL ...
- 使用MySQL的SELECT INTO OUTFILE ,Load data file,Mysql 大量数据快速导入导出
使用MySQL的SELECT INTO OUTFILE .Load data file LOAD DATA INFILE语句从一个文本文件中以很高的速度读入一个表中.当用户一前一后地使用SELECT ...
随机推荐
- OSI七层协议模型、TCP/IP四层模型
OSI七层协议模型 TCP/IP四层模型 首先我们梳理一下每层模型的职责: 链路层:对0和1进行分组,定义数据帧,确认主机的物理地址,传输数据: 网络层:定义IP地址,确认主机所在的网络位置,并通过I ...
- libusb传输endpoint描述符
至于endpoint描述符,它是属于设置的,每个设置都会有endpoint描述符,也就是每个接口的设置都表示一种功能,既然是实现了功能,那就必须通过endpoint来传输数据,那到底是用到了几个end ...
- XMLHttpRequest status为0
//创建XMLHttpRequest()对象 var request = new XMLHttpRequest(); ...... 今天写一个ajax , 明明是有结果返回的,但得到的request ...
- maven命令创建web骨架项目
maven命令创建web骨架项目有以下两种方式: mvn archetype:create -DgroupId=org.seckill -DartifactId=seckill -Darchetype ...
- MySQL Audit日志审计
一.简介 数据库审计能够实时记录网络上的数据库活动,对数据库操作进行细粒度审计的合规性管理,对数据库受到的风险行为进行告警,对攻击行为进行阻断,它通过对用户访问数据库行为的记录.分析和汇报,用来帮助用 ...
- union共同体
定义: union 共用体名{ 成员列表}: 与结构体不同的是,共用体的所有成员占用同一段内存,修改一个成员会影响其余成员.但是结构体的各个成员会占不同的内存. 结构体占用的内存大于等于所有成员占用的 ...
- js中for..of..和迭代器
for..of是ES6中引入的新特性,它主要的作用是:循环一个可迭代的对象. 它可以循环遍历,数组.字符串.Set对象等等 示例一: let str = 'hello' for (item of st ...
- POJ 2142 - The Balance [ 扩展欧几里得 ]
题意: 给定 a b n找到满足ax+by=n 的x,y 令|x|+|y|最小(等时令a|x|+b|y|最小) 分析: 算法一定是扩展欧几里得. 最小的时候一定是 x 是最小正值 或者 y 是最小正值 ...
- 钉钉报警-prometheus-alertmanager
alertmanager alertmanager可以放在远程服务器上 报警机制 在 prometheus 中定义你的监控规则,即配置一个触发器,某个值超过了设置的阈值就触发告警, prometheu ...
- DataGrid控件的列
四种列(局限性较大)https://www.cnblogs.com/lonelyxmas/p/9442604.html 更强大的模板列(如控件居中等)https://www.cnblogs.com/l ...