数据分析之 pandas
pandas的拼接操作
pandas的拼接分为两种:
- 级联:pd.concat, pd.append
- 合并:pd.merge, pd.join
1. 使用pd.concat()级联
pandas使用pd.concat函数,与np.concatenate函数类似,只是多了一些参数:
objs
axis=0
keys
join='outer' / 'inner':表示的是级联的方式,outer会将所有的项进行级联(忽略匹配和不匹配),而inner只会将匹配的项级联到一起,不匹配的不级联
ignore_index=False
1.1 匹配级联
import numpy as np
import pandas as pd
from pandas import Series,DataFrame
df1 = DataFrame(data=np.random.randint(0,100,size=(3,4)),index=['A','B','C'],columns=['a','b','c','d'])
df2 = DataFrame(data=np.random.randint(0,100,size=(3,4)),index=['A','D','C'],columns=['a','b','e','d'])
display(df1,df2)
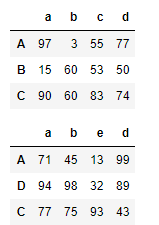
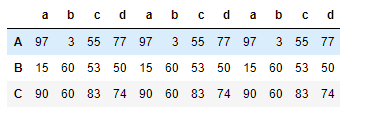
pd.concat((df1,df1,df1),axis=1,join='inner') #将df1 进行行的拼接
2 不匹配的级联
不匹配指的是级联的维度的索引不一致。例如纵向级联时列索引不一致,横向级联时行索引不一致
有2种连接方式:
- 外连接:补NaN(默认模式)
- 内连接:只连接匹配的项
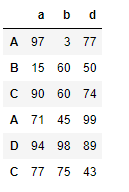
pd.concat((df1,df2),axis=0,join='inner') # 将列进行拼接,内连接
使用pd.merge()合并
merge与concat的区别在于,merge需要依据某一共同的列来进行合并
使用pd.merge()合并时,会自动根据两者相同column名称的那一列,作为key来进行合并。
注意每一列元素的顺序不要求一致
参数:
- how:out取并集 inner取交集
- on:当有多列相同的时候,可以使用on来指定使用那一列进行合并,on的值为一个列表
1) 一对一的合并
创建数据
df1 = DataFrame({'employee':['Bob','Jake','Lisa'],
'group':['Accounting','Engineering','Engineering'],
})
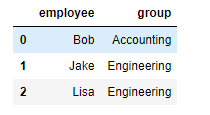
df2 = DataFrame({'employee':['Lisa','Bob','Jake'],
'hire_date':[2004,2008,2012],
})

pd.merge(df1,df2) # 合并 默认根据相同的字段合并

2)多对一合并
# 创建数据
df3 = DataFrame({
'employee':['Lisa','Jake'],
'group':['Accounting','Engineering'],
'hire_date':[2004,2016]})

df4 = DataFrame({'group':['Accounting','Engineering','Engineering'],
'supervisor':['Carly','Guido','Steve']
})
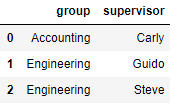
pd.merge(df3,df4) # 合并数据

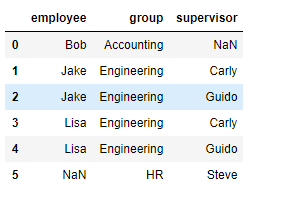
3) 多对多合并
df1 = DataFrame({'employee':['Bob','Jake','Lisa'],
'group':['Accounting','Engineering','Engineering']})
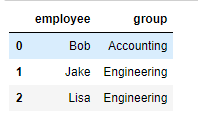
df5 = DataFrame({'group':['Engineering','Engineering','HR'],
'supervisor':['Carly','Guido','Steve']
})

pd.merge(df1,df5,how='outer') # 合并外连接
4) key的规范化
- 当列冲突时,即有多个列名称相同时,需要使用on=来指定哪一个列作为key,配合suffixes指定冲突列名
df1 = DataFrame({'employee':['Jack',"Summer","Steve"],
'group':['Accounting','Finance','Marketing']})

df2 = DataFrame({'employee':['Jack','Bob',"Jake"],
'hire_date':[2003,2009,2012],
'group':['Accounting','sell','ceo']})
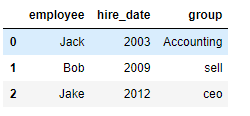
pd.merge(df1,df2,on='employee') #合并 指定固定的列
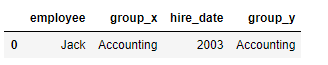
- 当两张表没有可进行连接的列时,可使用left_on和right_on手动指定merge中左右两边的哪一列列作为连接的列
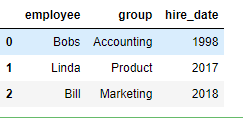
df1 = DataFrame({'employee':['Bobs','Linda','Bill'],
'group':['Accounting','Product','Marketing'],
'hire_date':[1998,2017,2018]})
df5 = DataFrame({'name':['Lisa','Bobs','Bill'],
'hire_dates':[1998,2016,2007]})
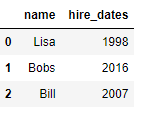
pd.merge(df1,df5,left_on='employee',right_on='name') # 指定左右合并的列
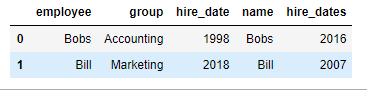
5) 内合并与外合并:out取并集 inner取交集
df6 = DataFrame({'name':['Peter','Paul','Mary'],
'food':['fish','beans','bread']}
)
df7 = DataFrame({'name':['Mary','Joseph'],
'drink':['wine','beer']})
外合并 how='outer':补NaN
df6 = DataFrame({'name':['Peter','Paul','Mary'],
'food':['fish','beans','bread']}
)
df7 = DataFrame({'name':['Mary','Joseph'],
'drink':['wine','beer']})
删除重复元素
使用duplicated()函数检测重复的行,返回元素为布尔类型的Series对象,每个元素对应一行,如果该行不是第一次出现,则元素为True
- keep参数:指定保留哪一重复的行数据
- 创建具有重复元素行的DataFrame
import numpy as np
from pandas import DataFrame,Series
import pandas as pd
# 创建数据
df = DataFrame(data=np.random.randint(0,100,size=(9,5)))
df.iloc[1] = [6,6,6,6,6] # 将第一行的数据赋值
df.iloc[3] = [6,6,6,6,6]
df.iloc[5] = [6,6,6,6,6]
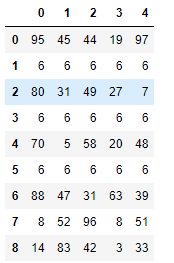
使用drop_duplicates()函数删除重复的行
- drop_duplicates(keep='first/last'/False)
first只留下第一行的重复的值
last 只留下最后一行的重复的值
False全部重复的值都删除
df.drop_duplicates(keep='first')
映射
replace()函数:替换元素
DataFrame替换操作
- 单值替换
- 普通替换: 替换所有符合要求的元素:to_replace=15,value='e'
- 按列指定单值替换: to_replace={列标签:替换值} value='value'
- 多值替换
- 列表替换: to_replace=[] value=[]
- 字典替换(推荐) to_replace={to_replace:value,to_replace:value}
df.replace(to_replace=6,value='six') 将值是6的元素,替换成six
df.replace(to_replace={3:'three'}) 将值是3的元素,替换成three
df.replace(to_replace={3:6},value='six') 索引是3列的所有的6都替换six
map()函数:新建一列 , map函数并不是df的方法,而是series的方法
- map()可以映射新一列数据
- map()中可以使用lambd表达式
map()中可以使用方法,可以是自定义的方法
eg:map({to_replace:value})
- 注意 map()中不能使用sum之类的函数,for循环
- 新增一列:给df中,添加一列,该列的值为中文名对应的英文名
dic = {
'name':['jay','tom','jay'],
'salary':[9999,5000,9999]
}
df = DataFrame(data=dic)
dic = {
'jay':'周杰伦',
'tom':'张三'
}
# 将name 循环给dic函数
df['c_name'] = df['name'].map(dic) # 根据键值替换,键是元数据 值是替换后的数据
map当做一种运算工具,至于执行何种运算,是由map函数的参数决定的(参数:lambda,函数)
- 使用自定义函数
def after_sal(s):
return s - (s-3000)*0.5
#超过3000部分的钱缴纳50%的税
df['after_sal'] = df['salary'].map(after_sal)
df
#超过3000部分的钱缴纳50%的税
def after_sal(s):
return s - (s-3000)*0.5
df['salary'].apply(after_sal) #
注意:并不是任何形式的函数都可以作为map的参数。只有当一个函数具有一个参数且有返回值,那么该函数才可以作为map的参数
使用聚合操作对数据异常值检测和过滤
使用df.std()函数可以求得DataFrame对象每一列的标准差
- 创建一个1000行3列的df 范围(0-1),求其每一列的标准差
df = DataFrame(data=np.random.random(size=(1000,3)),columns=['A','B','C'])
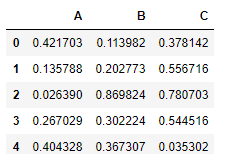
对df应用筛选条件,去除标准差太大的数据:假设过滤条件为 C列数据大于两倍的C列标准差
std_twice = df['C'].std() * 2
0.5809347094044642
df['C'] > std_twice
#异常值对应的行数据
df.loc[df['C'] > std_twice]
indexs = df.loc[df['C'] > std_twice].index
df.drop(labels=indexs,axis=0,inplace=True)
数据清洗
- 清洗空值
- dropna fillna isnull notnull any all
- 清洗重复值
- drop_duplicates(keep)
- 清洗异常值
- 异常值监测的结果(布尔值),作为清洗的过滤的条件
4. 排序
使用.take()函数排序
- take()函数接受一个索引列表,用数字表示,使得df根据列表中索引的顺序进行排序
- eg:df.take([1,3,4,2,5])
可以借助np.random.permutation()函数随机排序
df.take([2,1,0],axis=1).take(np.random.permutation(500),axis=0)
#随机取20行
df.take([2,1,0],axis=1).take(np.random.permutation(500),axis=0)[0:20]
- np.random.permutation(x)可以生成x个从0-(x-1)的随机数列
随机抽样
当DataFrame规模足够大时,直接使用np.random.permutation(x)函数,就配合take()函数实现随机抽样
5. 数据分类处理【重点】
数据聚合是数据处理的最后一步,通常是要使每一个数组生成一个单一的数值。
数据分类处理:
- 分组:先把数据分为几组
- 用函数处理:为不同组的数据应用不同的函数以转换数据
- 合并:把不同组得到的结果合并起来
数据分类处理的核心:
- groupby()函数
- groups属性查看分组情况
- eg: df.groupby(by='item').groups
分组
from pandas import DataFrame,Series
df = DataFrame({'item':['Apple','Banana','Orange','Banana','Orange','Apple'],
'price':[4,3,3,2.5,4,2],
'color':['red','yellow','yellow','green','green','green'],
'weight':[12,20,50,30,20,44]})
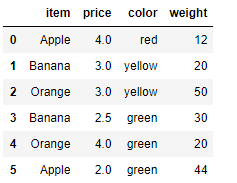
- 使用groupby实现分组
df.groupby(by='item')
- 使用groups查看分组情况
#该函数可以进行数据的分组,但是不显示分组情况
df.groupby(by='item').groups
df.groupby(by='item').mean()['price']
{'Apple': Int64Index([0, 5], dtype='int64'),
'Banana': Int64Index([1, 3], dtype='int64'),
'Orange': Int64Index([2, 4], dtype='int64')}
#给df创建一个新列,内容为各个水果的平均价格
df.groupby(by='item').mean()['price']
item Apple 3.00 Banana 2.75 Orange 3.50 Name: price, dtype: float64、
mean_price_s = df.groupby(by='item')['price'].mean()
mean_price_s
item
Apple 3.00
Banana 2.75
Orange 3.50
Name: price, dtype: float64
dic = mean_price_s.to_dict()
{'Apple': 3.0, 'Banana': 2.75, 'Orange': 3.5}
df['mean_price'] = df['item'].map(dic)
高级数据聚合
使用groupby分组后,也可以使用transform和apply提供自定义函数实现更多的运算
- df.groupby('item')['price'].sum() <==> df.groupby('item')['price'].apply(sum)
- transform和apply都会进行运算,在transform或者apply中传入函数即可
- transform和apply也可以传入一个lambda表达式
def my_mean(s):
sum = 0
for i in s:
sum += i
return sum/s.size
df.groupby(by='item')['price'].transform(my_mean)
df.groupby(by='item')['price'].apply(my_mean)
数据分析之 pandas的更多相关文章
- 利用Python进行数据分析(12) pandas基础: 数据合并
pandas 提供了三种主要方法可以对数据进行合并: pandas.merge()方法:数据库风格的合并: pandas.concat()方法:轴向连接,即沿着一条轴将多个对象堆叠到一起: 实例方法c ...
- 利用Python进行数据分析(9) pandas基础: 汇总统计和计算
pandas 对象拥有一些常用的数学和统计方法. 例如,sum() 方法,进行列小计: sum() 方法传入 axis=1 指定为横向汇总,即行小计: idxmax() 获取最大值对应的索 ...
- 利用Python进行数据分析(8) pandas基础: Series和DataFrame的基本操作
一.reindex() 方法:重新索引 针对 Series 重新索引指的是根据index参数重新进行排序. 如果传入的索引值在数据里不存在,则不会报错,而是添加缺失值的新行. 不想用缺失值,可以用 ...
- 利用Python进行数据分析(7) pandas基础: Series和DataFrame的简单介绍
一.pandas 是什么 pandas 是基于 NumPy 的一个 Python 数据分析包,主要目的是为了数据分析.它提供了大量高级的数据结构和对数据处理的方法. pandas 有两个主要的数据结构 ...
- Python数据分析库pandas基本操作
Python数据分析库pandas基本操作2017年02月20日 17:09:06 birdlove1987 阅读数:22631 标签: python 数据分析 pandas 更多 个人分类: Pyt ...
- Python数据分析之pandas基本数据结构:Series、DataFrame
1引言 本文总结Pandas中两种常用的数据类型: (1)Series是一种一维的带标签数组对象. (2)DataFrame,二维,Series容器 2 Series数组 2.1 Series数组构成 ...
- Python 数据分析:Pandas 缺省值的判断
Python 数据分析:Pandas 缺省值的判断 背景 我们从数据库中取出数据存入 Pandas None 转换成 NaN 或 NaT.但是,我们将 Pandas 数据写入数据库时又需要转换成 No ...
- 数据分析06 /pandas高级操作相关案例:人口案例分析、2012美国大选献金项目数据分析
数据分析06 /pandas高级操作相关案例:人口案例分析.2012美国大选献金项目数据分析 目录 数据分析06 /pandas高级操作相关案例:人口案例分析.2012美国大选献金项目数据分析 1. ...
- 数据分析05 /pandas的高级操作
数据分析05 /pandas的高级操作 目录 数据分析05 /pandas的高级操作 1. 替换操作 2. 映射操作 3. 运算工具 4. 映射索引 / 更改之前索引 5. 排序实现的随机抽样/打乱表 ...
- 数据分析02 /pandas基础
数据分析02 /pandas基础 目录 数据分析02 /pandas基础 1. pandas简介 2. Series 3. DataFrame 4. 总结: 1. pandas简介 numpy能够帮助 ...
随机推荐
- java web 监控cpu、内存等。hyperic-sigar
用到一个插件hyperic-sigar 1:下载hyperic-sigar后解压,把sigar-amd64-winnt.dll(64位机器,32位用sigar-x86-winnt.dll)放到你本机的 ...
- 二:MySQL系列之SQL基本操作(二)
本篇主要介绍SOL语句的基本操作,主要有分为 连接数据库,创建数据库.创建数据表.添加数据记录,基本的查询功能等操作. 一.针对数据库的操作 -- 1.连接数据库 mysql -uroot -p my ...
- mysql安装和遇到的问题处理
遇到需要在新系统上安装MySQL的事情,简单记录一下过程. 声明:最好的文档是官方文档,我也是看的官方文档,只是中间遇到点问题,记录一下出现的问题和处理方式.贴一些官方文档地址. 用tar包的安装方式 ...
- Django:ContentType组件
一.项目背景 二.版本一 三.版本二 三.终极版(使用ContentType) 一.项目背景 luffy项目,有课程有学位课(不同的课程字段不一样),价格策略 问题:1.如何设计表结构,来表示这种规则 ...
- AD19新功能之ActiveRoute
AD19新增了ActiveRoute功能(自动布线功能),强大而实用: 1.河流式布线模式 在PCB面板中选择相应的网络,选中飞线,或者按住 Alt 然后鼠标从右下往左上进行框选,选中对应的飞线 然后 ...
- 安装腾讯QQ问题记录
安装腾讯QQ的时候遇到两个错误,记录一些解决方法 1.安装文件失败,请尝试手动卸载QQ或更改安装目录,再执行安装程序,错误码:0x00008013 问题原因:卸载QQ没有完全卸载,导致文件残留. 如果 ...
- _MyBatis3-topic06.07.08.09_ 全局配置文件_引入dtd约束(xml提示)/ 引入properties引用/ 配置驼峰命名自动匹配 /typeAliases起别名.批量起别名
MyBatis3 的全局配置文件 : Setting -官方文档 笔记要点 出错分析 [Intellij idea配置外部DTD文件] 设置步骤: (同Eclipse中的Catalog设置 ) Fil ...
- Mysql DELETE 不能使用别名? 是我不会用!
今天碰到一个sql问题,就是在delete中加了别名,导致报错了:"[Err] 1064 - You have an error in your SQL syntax; ..." ...
- 解决在macOS下安装了python却没有pip命令的问题【经验总结】
可以使用brew直接安装python,但是安装完成了之后没有pip命令. pip是常用的python包管理工具,类似于java的maven.第一反应brew install pip,却提示没这货. 可 ...
- 基于pg_qualstats和hypopg的自动索引调优
pg-qualstats的安装和配置 1.安装pg-qualstats -pg-qualstats 2.将pg_qualstats和pg_stat_statements添加到shared_preloa ...