爬虫之如何找js入口(一)
目标网页:https://m.gojoy.cn/pages/login/ 将我删除i ndex?from=%2Fpages%2Fuser%2Findex
需要工具:chrome和油猴
油猴代码:
// ==UserScript==
// @name Json.stringify
// @namespace http://tampermonkey.net/
// @version 0.1
// @description try to take over the world!
// @author You
// @include *
// @grant none
// ==/UserScript== (function(){
"use strict";
var rstringify = JSON.stringify;
JSON.stringify = function(a){
console.log("Detect Json.stringify", a);
return rstringify(a);
}
})();
第一步,F12,在第三行数字上,右键选择 Add conditional breakpoint, 用于越过反调试
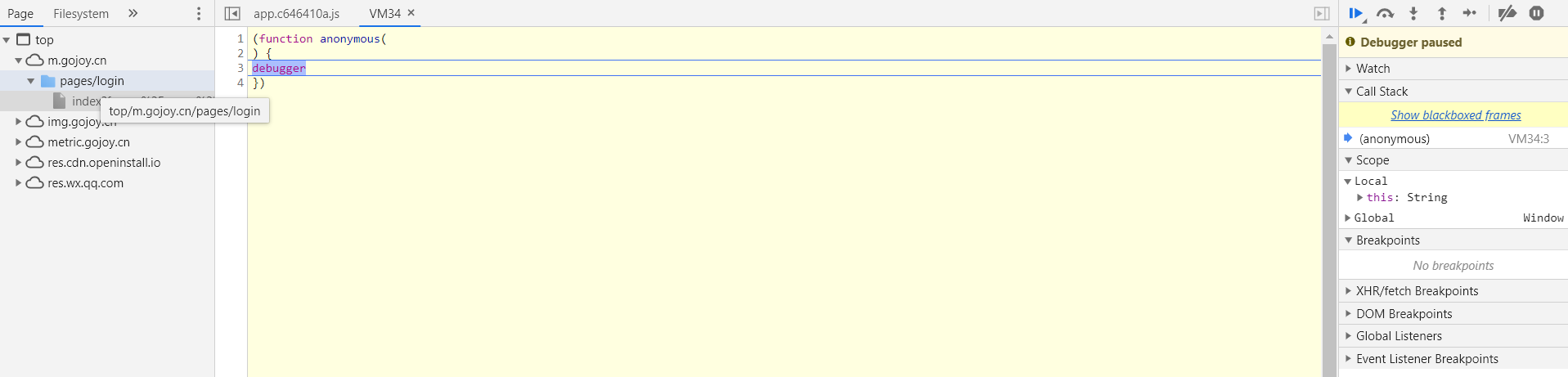
如果还是卡住那么,点击这个,变成蓝色

然后点击 
第二步,如果已经加载完成了, 随便输入账号密码,点击登录,查看Network里的新url。发现是login为登录请求
点击查看,发现下面有一串看不懂的参数,猜测这就是将账号密码等东西进行加密得出来的

尝试一、全文搜索username , password 以找不到,失败告终
尝试二、查看以什么格式加载的
首先看到Response Headers中有个Access-Control-Allow-Credentials:true 说明这个是个跨域请求
关掉详细信息后看到是 xhr 方式加载

打 XHR断点,输入 相应的字串,进行HOOK
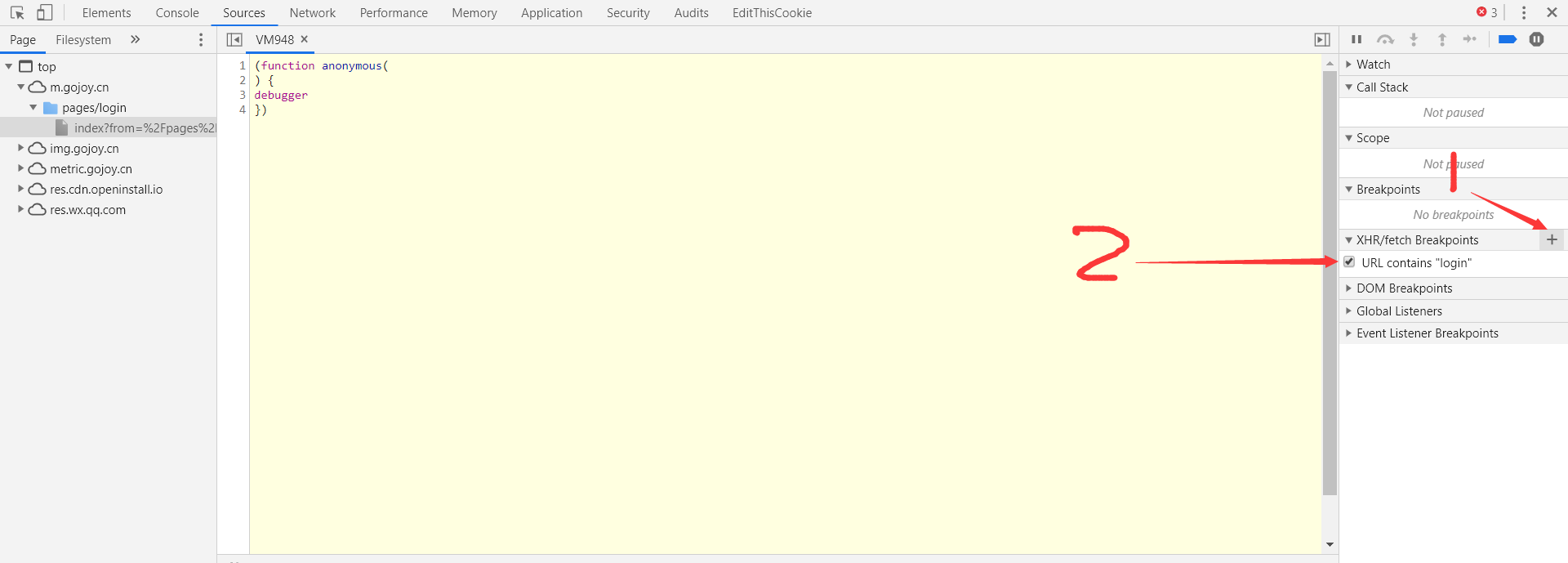
上述完成后,再次输入好账号密码,登录
如果没问题的话就会停在
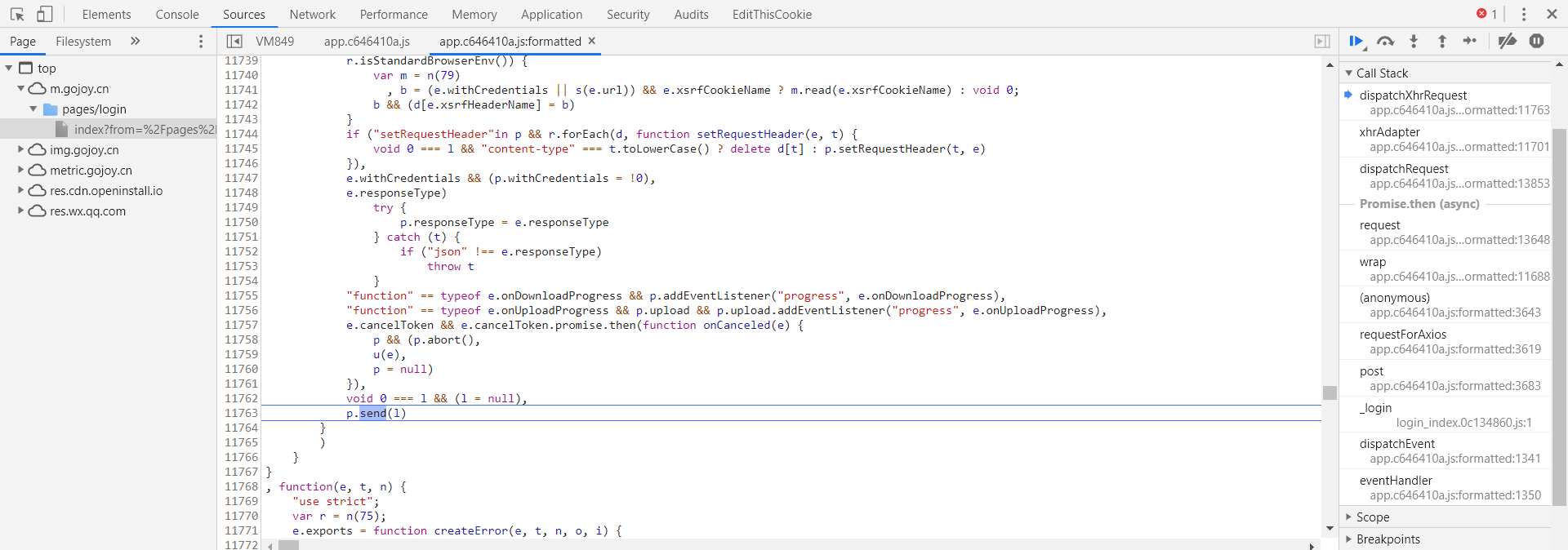
call stack(回调调用栈)中,一个个往下点击,直到看到类似于ajax加载的格式代码
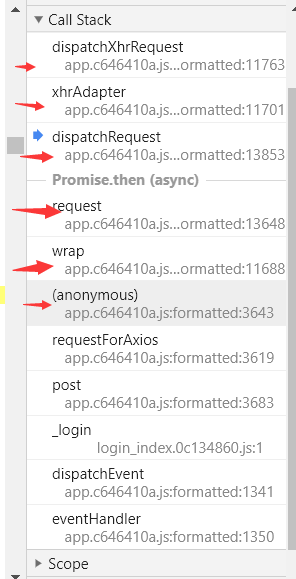
so,找到了s这个位置就很像ajax,然后在3643那个位置点击左键,设置断点
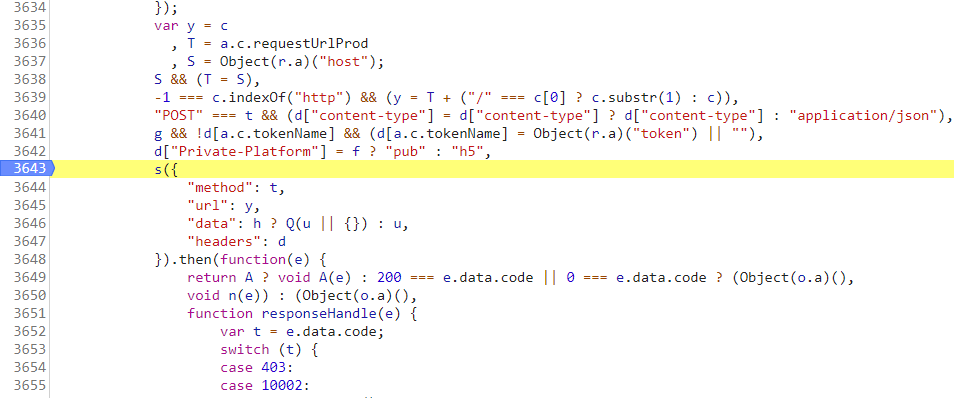
先点击 让当前代码先执行完毕,重新点击页面的登录按钮
让当前代码先执行完毕,重新点击页面的登录按钮
没什么意外就会停在s这个位置,从上到下将t,y,h,Q,u,d,全部在console中打印出来
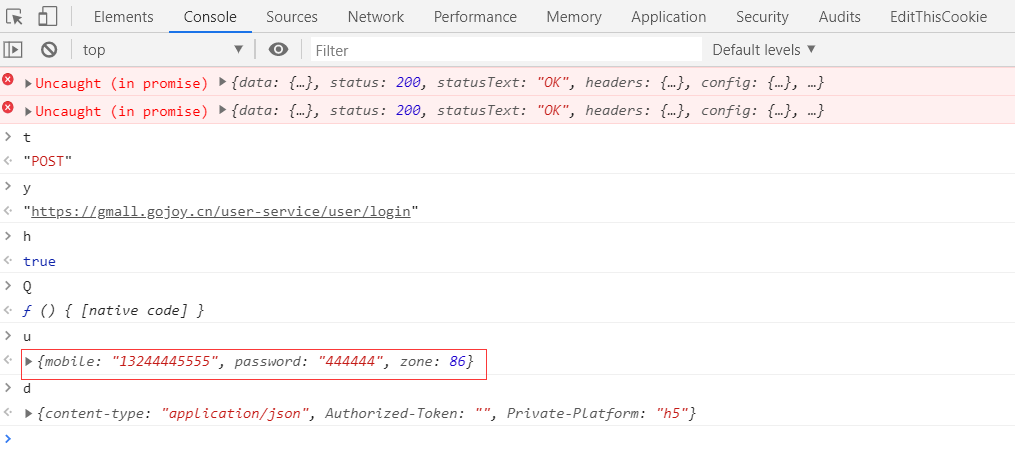
看到u的值证明没找错!!!说明就是通过这里进行与后端的通信,且根据Q这个函数进行的将u内容进行不知名的操作
所以可以猜测应该是这里得出了上面request中那一串很长的参数
双击上面输出内容中native code 就会跳转到函数定义 (一般而言,natvie code是跟不进去的)
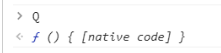
跳转后,找到这个函数return,所以点击 { ,找到对应的 } ,找到返回值位置return a[o.m[[o.m.i[";"]]].q](o.m[[o.m.i[";"]]].x),给其打上断点

然后,还是先让当前跑完,重新点击登录,然后就会停在新增加的断点位置

接下来,在console打印出返回值

出现个与login网页中很相似的参数值,那么还是让当前跑完,然后点击Network查看最新的login的详细信息,看看是不是一样的

然而很显然一模一样!!!!
所以说这个函数 , 对username和password操作后的出来的

那么此时入口发现了,之后只需要execjs包执行或者,将js代码翻译为python代码放进爬虫中操作就可以了
上面为最常用的操作
============================================================================
接下来油猴脚本操作方式效果一样,但是更快速定位!!!!
建好脚本后开启,如何使用脚本,写脚本这里暂不论述
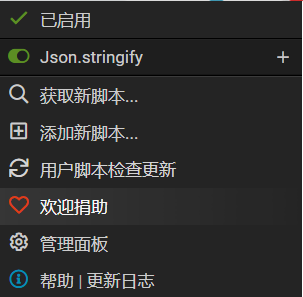
输入好账密后点击登录,console就会打印出下图 ,然后点击红框位置,跳转后打上断点

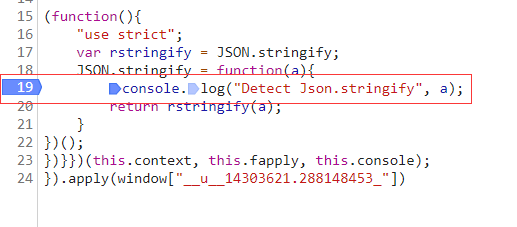
先执行完毕后,再重新点击登录,查看调用栈,点击s
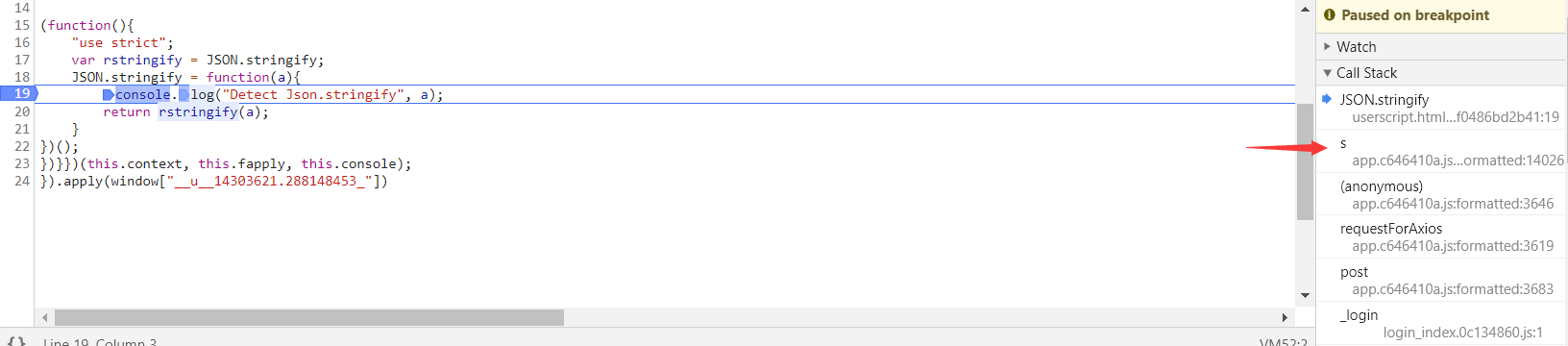
跳转后,拖动滑动条到最左边,看到位置2就和上面的所找到的js函数一摸一样,方便很多对吧!!!!
爬虫之如何找js入口(一)的更多相关文章
- python爬虫之快速对js内容进行破解
python爬虫之快速对js内容进行破解 今天介绍下数据被js加密后的破解方法.距离上次发文已经过去半个多月了,我写文章的主要目的是把从其它地方学到的东西做个记录顺便分享给大家,我承认自己是个懒猪.不 ...
- [Python爬虫笔记][随意找个博客入门(一)]
[Python爬虫笔记][随意找个博客入门(一)] 标签(空格分隔): Python 爬虫 2016年暑假 来源博客:挣脱不足与蒙昧 1.简单的爬取特定url的html代码 import urllib ...
- Python爬虫教程-16-破解js加密实例(有道在线翻译)
python爬虫教程-16-破解js加密实例(有道在线翻译) 在爬虫爬取网站的时候,经常遇到一些反爬虫技术,比如: 加cookie,身份验证UserAgent 图形验证,还有很难破解的滑动验证 js签 ...
- 爬虫之抓取js生成的数据
有很多页面,当我们用request发送请求,返回的内容里面并没有页面上显示的数据,主要有两种情况,一是通过ajax异步发送请求,得到响应把数据放入页面中,对于这种情况,我们可以查看关于ajax的请求, ...
- python爬虫破解带有RSA.js的RSA加密数据的反爬机制
前言 同上一篇的aes加密一样,也是偶然发现这个rsa加密的,目标网站我就不说了,保密. 当我发现这个网站是ajax加载时: 我已经习以为常,正在进行爬取时,发现返回为空,我开始用findler抓包, ...
- 《剑指offer》-链表找环入口
题目描述 一个链表中包含环,请找出该链表的环的入口结点. 初步想法是每个节点做几个标记,表示是否被访问过,那么遍历链表的时候就知道哪个被访问到了.但是不会实现. 另一个直觉是判断链表有环的算法中出现过 ...
- JS入口函数和JQuery入口函数
首先,讲一下它们的区别: (1)JS的window.onload事件必须要等到所有内容,以及外部图片之类的文件加载完之后,才会去执行. (2)JQuery入口函数是在所有标签加载完之后,就会去执行. ...
- java_爬虫_获取经过js渲染后的网页源码
md 弄了一天了……(这个月不会在摸爬虫了,浪费生命) 进入正题: 起初是想写一个爬虫来爬一个网站的视频,但是怎么爬取都爬取不到,分析了下源代码之后,发现源代码中并没有视频的dom 但是在浏览器检查元 ...
- 笔试算法题(27):判断单向链表是否有环并找出环入口节点 & 判断两棵二元树是否相等
出题:判断一个单向链表是否有环,如果有环则找到环入口节点: 分析: 第一个问题:使用快慢指针(fast指针一次走两步,slow指针一次走一步,并判断是否到达NULL,如果fast==slow成立,则说 ...
随机推荐
- shell做成csv文件
echo a,b,c,d >aa.csv 其实就是用逗号做分隔符
- spring整合mybatis(非代理方式)【我】
首先创建要给 maven 的war项目 不用代理的方式: 如果不适用Mapper代理的方式,配置就非常简单: 首先是pom文件(以下配置文件包含其他多余内容,仅供参考): <project xm ...
- Ubuntu16.04使用apt安装完nginx常见问题
1.安装完并remove掉后重新install后没nginx.conf文件 解决办法: apt-get -y --purge remove nginx* apt-get -y autoremove a ...
- ListView中用鼠标拖动各项上下移动的问题。(100分)
在OnDragDrop事件中處理:以下是delphi的例子 procedure TForm1.ListBox1DragOver(Sender, Source: TObject; X, Y: Integ ...
- 生成iOS-Xcode技术文档
从源码中抽取注释生成文档的专用工具: [doxygen](http://www.stack.nl/~dimitri/doxygen/index.html):适于生成html文档与pdf文档. 支持的语 ...
- Swift3.0基础语法学习<一>
// // ViewController.swift // SwiftBasicDemo // // Created by 思 彭 on 16/11/15. // Copyright © 2016年 ...
- Samba简单应用
一.Samba 简介 1.介绍 Samba(SMB是其缩写) 是一个网络服务器,用于Linux和Windows共享文件之用:Samba 即可以用于Windows和Linux之间的共享文件,也一样用于L ...
- 登录进入Mysql数据库的几种方式
前提:连接进入mysql数据库 本机安装的myslq基础信息: host= "localhost", # 数据库主机地址:127.0.0.1 port=3306, # 端口号 us ...
- java开发性能调优
从总体上来看,对于大型网站,比如门户网站,在面对大量用户访问.高并发请求方面,基本的解决方案集中在这样几个环节:1.首先需要解决网络带宽和Web请求的高并发,需要合理的加大服务器和带宽的投入,并且需要 ...
- 面试35-删除字符串重复字符-删除出现在第二个字符串中的字符-第一个只出现一次的字符-hash表计数
#include<iostream>#include<algorithm>#include<functional>using namespace std;char ...