14 Scrapy中selenium的应用
在通过scrapy框架进行某些网站数据爬取的时候,往往会碰到页面动态数据加载的情况发生,如果直接使用scrapy对其url发请求,是绝对获取不到那部分动态加载出来的数据值。但是通过观察我们会发现,通过浏览器进行url请求发送则会加载出对应的动态加载出的数据。那么如果我们想要在scrapy也获取动态加载出的数据,则必须使用selenium创建浏览器对象,然后通过该浏览器对象进行请求发送,获取动态加载的数据值。
1.案例分析:
- 需求:爬取网易新闻的国内板块下的新闻数据
- 需求分析:当点击国内超链进入国内对应的页面时,会发现当前页面展示的新闻数据是被动态加载出来的,如果直接通过程序对url进行请求,是获取不到动态加载出的新闻数据的。则就需要我们使用selenium实例化一个浏览器对象,在该对象中进行url的请求,获取动态加载的新闻数据。
2.selenium在scrapy中使用的原理分析:
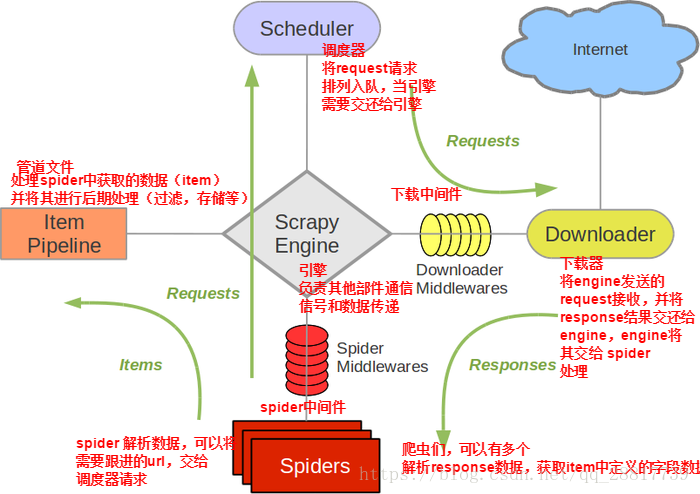
当引擎将国内板块url对应的请求提交给下载器后,下载器进行网页数据的下载,然后将下载到的页面数据,封装到response中,提交给引擎,引擎将response在转交给Spiders。Spiders接受到的response对象中存储的页面数据里是没有动态加载的新闻数据的。要想获取动态加载的新闻数据,则需要在下载中间件中对下载器提交给引擎的response响应对象进行拦截,切对其内部存储的页面数据进行篡改,修改成携带了动态加载出的新闻数据,然后将被篡改的response对象最终交给Spiders进行解析操作。
3.selenium在scrapy中的使用流程:
- 重写爬虫文件的构造方法,在该方法中使用selenium实例化一个浏览器对象(因为浏览器对象只需要被实例化一次)
- 重写爬虫文件的closed(self,spider)方法,在其内部关闭浏览器对象。该方法是在爬虫结束时被调用
- 重写下载中间件的process_response方法,让该方法对响应对象进行拦截,并篡改response中存储的页面数据
- 在配置文件中开启下载中间件
4.代码展示:
- 爬虫文件:
class WangyiSpider(RedisSpider):
name = 'wangyi'
#allowed_domains = ['www.xxxx.com']
start_urls = ['https://news.163.com']
def __init__(self):
#实例化一个浏览器对象(实例化一次)
self.bro = webdriver.Chrome(executable_path='/Users/bobo/Desktop/chromedriver') #必须在整个爬虫结束后,关闭浏览器
def closed(self,spider):
print('爬虫结束')
self.bro.quit()
- 中间件文件:
from scrapy.http import HtmlResponse
#参数介绍:
#拦截到响应对象(下载器传递给Spider的响应对象)
#request:响应对象对应的请求对象
#response:拦截到的响应对象
#spider:爬虫文件中对应的爬虫类的实例
def process_response(self, request, response, spider):
#响应对象中存储页面数据的篡改
if request.url in['http://news.163.com/domestic/','http://news.163.com/world/','http://news.163.com/air/','http://war.163.com/']:
spider.bro.get(url=request.url)
js = 'window.scrollTo(0,document.body.scrollHeight)'
spider.bro.execute_script(js)
time.sleep(2) #一定要给与浏览器一定的缓冲加载数据的时间
#页面数据就是包含了动态加载出来的新闻数据对应的页面数据
page_text = spider.bro.page_source
#篡改响应对象
return HtmlResponse(url=spider.bro.current_url,body=page_text,encoding='utf-8',request=request)
else:
return response
- 配置文件:
DOWNLOADER_MIDDLEWARES = {
'wangyiPro.middlewares.WangyiproDownloaderMiddleware': 543,
}
14 Scrapy中selenium的应用的更多相关文章
- 15.scrapy中selenium的应用
引入 在通过scrapy框架进行某些网站数据爬取的时候,往往会碰到页面动态数据加载的情况发生,如果直接使用scrapy对其url发请求,是绝对获取不到那部分动态加载出来的数据值.但是通过观察我们会发现 ...
- scrapy中selenium的应用
引入 在通过scrapy框架进行某些网站数据爬取的时候,往往会碰到页面动态数据加载的情况发生,如果直接使用scrapy对其url发请求,是绝对获取不到那部分动态加载出来的数据值.但是通过观察我们会发现 ...
- scrapy中 selenium(中间件) + 语言处理 +mysql
在通过scrapy框架进行某些网站数据爬取的时候,往往会碰到页面动态数据加载的情况发生,如果直接使用scrapy对其url发请求,是绝对获取不到那部分动态加载出来的数据值.但是通过观察我们会发现,通过 ...
- 15,scrapy中selenium的应用
引入 在通过scrapy框架进行某些网站数据爬取的时候,往往会碰到页面动态数据加载的情况发生如果直接用scrapy对其url发请求,是获取不到那部分动态加载出来的数据值,但是通过观察会发现,通过浏览器 ...
- selenium在scrapy中的使用、UA池、IP池的构建
selenium在scrapy中的使用流程 重写爬虫文件的构造方法__init__,在该方法中使用selenium实例化一个浏览器对象(因为浏览器对象只需要被实例化一次). 重写爬虫文件的closed ...
- Scrapy中集成selenium
面对众多动态网站比如说淘宝等,一般情况下用selenium最好 那么如何集成selenium到scrapy中呢? 因为每一次request的请求都要经过中间件,所以写在中间件中最为合适 from se ...
- 在Scrapy中使用selenium
在scrapy中使用selenium 在scrapy中需要获取动态加载的数据的时候,可以在下载中间件中使用selenium 编码步骤: 在爬虫文件中导入webdrvier类 在爬虫文件的爬虫类的构造方 ...
- selenium在scrapy中的应用
引入 在通过scrapy框架进行某些网站数据爬取的时候,往往会碰到页面动态数据加载的情况发生,如果直接使用scrapy对其url发请求,是绝对获取不到那部分动态加载出来的数据值.但是通过观察我们会发现 ...
- 第三百五十一节,Python分布式爬虫打造搜索引擎Scrapy精讲—将selenium操作谷歌浏览器集成到scrapy中
第三百五十一节,Python分布式爬虫打造搜索引擎Scrapy精讲—将selenium操作谷歌浏览器集成到scrapy中 1.爬虫文件 dispatcher.connect()信号分发器,第一个参数信 ...
随机推荐
- IDEA问题java: -source 1.6 中不支持diamond、 lambda 表达式
文章目录 一.问题:连片的java: -source 1.6 中不支持 diamond 运算符.lambda 表达式 二.解决方法: 1.在微信群里问大佬,大佬在玩游戏,回复的比较慢 2.自己查Goo ...
- 小程序web-view利用url给内嵌的网页传值
这个方法跟网页上的一样,直接通过截取url中传过来的参数来取值 <web-view src="https://www.baidu.com/test.html?url=http://ww ...
- tp5更改入口文件到根目录的方法分享
tp5把入口文件放到了public目录中,对于服务器或者vps来说没啥,因为可以指定目录,但是对于虚拟主机就不行了,我们必须吧index.php这入口文件放到根目录,那么我么需要改一下相对的引入文件的 ...
- MAMP 环境下安装Redis扩展
1. 下载对应版本的 php 源码,(当前使用版本是 php5.6.30 )版本号最后一位有点区别不影响链接:http://php.net/get/php-5.6.31.tar.bz2/from/a/ ...
- sql_profile 固定SQL执行计划
使用 sql_profile 固定SQL执行计划 Table of Contents 1. 扯蛋 2. 利用SQL PROFILE固定执行计划 2.1. 查看原来语句的执行计划 2.2. 指定SQL使 ...
- java tfserving grpc 通信调用代码解析 【重点参考】
https://blog.csdn.net/shin627077/article/details/78592729/ [重点参考]
- (4)rapidxml的详解及使用
RapidXml是指 XML DOM解析工具包,是一个快速的读写xml文件的库文件(hpp). (1)创建XML文件 #include <iostream> #includ ...
- promise 实现红绿灯
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- flannel下k8s pod及容器无法跨主机互通问题
参照文档 https://blog.csdn.net/a610786189/article/details/80340556 https://blog.csdn.net/weixin_43092 ...
- DES加密解密工具
using System; using System.Text; using System.Security.Cryptography; using System.IO; namespace DESP ...