kafka 讲讲acks参数对消息持久化的影响
目录
(0)写在前面
(1)如何保证宕机时数据不丢失?
(2)多副本冗余的高可用机制
(3)多副本之间数据如何同步?
(4)ISR到底指的什么东西?
(5)acks参数的含义?
(6)最后的思考
(0)写在前面
面试大厂时,一旦简历上写了Kafka,几乎必然会被问到一个问题:说说acks参数对消息持久化的影响?
这个acks参数在kafka的使用中,是非常核心以及关键的一个参数,决定了很多东西。
所以无论是为了面试还是实际项目使用,大家都值得看一下这篇文章对Kafka的acks参数的分析,以及背后的原理。
(1)如何保证宕机的时候数据不丢失?
如果要想理解这个acks参数的含义,首先就得搞明白kafka的高可用架构原理。
比如下面的图里就是表明了对于每一个Topic,我们都可以设置他包含几个Partition,每个Partition负责存储这个Topic一部分的数据。
然后Kafka的Broker集群中,每台机器上都存储了一些Partition,也就存放了Topic的一部分数据,这样就实现了Topic的数据分布式存储在一个Broker集群上。

但是有一个问题,万一 一个Kafka Broker宕机了,此时上面存储的数据不就丢失了吗?
没错,这就是一个比较大的问题了,分布式系统的数据丢失问题,是他首先必须要解决的,一旦说任何一台机器宕机,此时就会导致数据的丢失。
(2)多副本冗余的高可用机制
所以如果大家去分析任何一个分布式系统的原理,比如说zookeeper、kafka、redis cluster、elasticsearch、hdfs,等等,其实他都有自己内部的一套多副本冗余的机制,多副本冗余几乎是现在任何一个优秀的分布式系统都一般要具备的功能。
在kafka集群中,每个Partition都有多个副本,其中一个副本叫做leader,其他的副本叫做follower,如下图。

如上图所示,假设一个Topic拆分为了3个Partition,分别是Partition0,Partiton1,Partition2,此时每个Partition都有2个副本。
比如Partition0有一个副本是Leader,另外一个副本是Follower,Leader和Follower两个副本是分布在不同机器上的。
这样的多副本冗余机制,可以保证任何一台机器挂掉,都不会导致数据彻底丢失,因为起码还是有副本在别的机器上的。
(3)多副本之间数据如何同步?
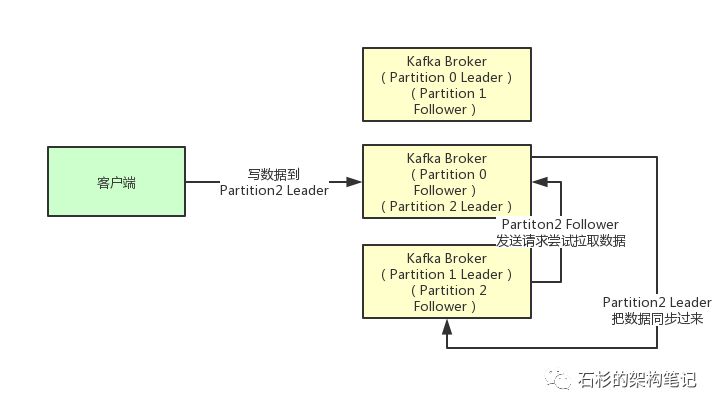
接着我们就来看看多个副本之间数据是如何同步的?其实任何一个Partition,只有Leader是对外提供读写服务的
也就是说,如果有一个客户端往一个Partition写入数据,此时一般就是写入这个Partition的Leader副本。
然后Leader副本接收到数据之后,Follower副本会不停的给他发送请求尝试去拉取最新的数据,拉取到自己本地后,写入磁盘中。如下图所示:
(4)ISR到底指的是什么东西?
既然大家已经知道了Partiton的多副本同步数据的机制了,那么就可以来看看ISR是什么了。
ISR全称是“In-Sync Replicas”,也就是保持同步的副本,他的含义就是,跟Leader始终保持同步的Follower有哪些。
大家可以想一下 ,如果说某个Follower所在的Broker因为JVM FullGC之类的问题,导致自己卡顿了,无法及时从Leader拉取同步数据,那么是不是会导致Follower的数据比Leader要落后很多?
所以这个时候,就意味着Follower已经跟Leader不再处于同步的关系了。但是只要Follower一直及时从Leader同步数据,就可以保证他们是处于同步的关系的。
所以每个Partition都有一个ISR,这个ISR里一定会有Leader自己,因为Leader肯定数据是最新的,然后就是那些跟Leader保持同步的Follower,也会在ISR里。
(5)acks参数的含义
铺垫了那么多的东西,最后终于可以进入主题来聊一下acks参数的含义了。
如果大家没看明白前面的那些副本机制、同步机制、ISR机制,那么就无法充分的理解acks参数的含义,这个参数实际上决定了很多重要的东西。
首先这个acks参数,是在KafkaProducer,也就是生产者客户端里设置的
也就是说,你往kafka写数据的时候,就可以来设置这个acks参数。然后这个参数实际上有三种常见的值可以设置,分别是:0、1 和 all。
第一种选择是把acks参数设置为0,意思就是我的KafkaProducer在客户端,只要把消息发送出去,不管那条数据有没有在哪怕Partition Leader上落到磁盘,我就不管他了,直接就认为这个消息发送成功了。
如果你采用这种设置的话,那么你必须注意的一点是,可能你发送出去的消息还在半路。结果呢,Partition Leader所在Broker就直接挂了,然后结果你的客户端还认为消息发送成功了,此时就会导致这条消息就丢失了。

第二种选择是设置 acks = 1,意思就是说只要Partition Leader接收到消息而且写入本地磁盘了,就认为成功了,不管他其他的Follower有没有同步过去这条消息了。
这种设置其实是kafka默认的设置,大家请注意,划重点!这是默认的设置
也就是说,默认情况下,你要是不管acks这个参数,只要Partition Leader写成功就算成功。
但是这里有一个问题,万一Partition Leader刚刚接收到消息,Follower还没来得及同步过去,结果Leader所在的broker宕机了,此时也会导致这条消息丢失,因为人家客户端已经认为发送成功了。

最后一种情况,就是设置acks=all,这个意思就是说,Partition Leader接收到消息之后,还必须要求ISR列表里跟Leader保持同步的那些Follower都要把消息同步过去,才能认为这条消息是写入成功了。
如果说Partition Leader刚接收到了消息,但是结果Follower没有收到消息,此时Leader宕机了,那么客户端会感知到这个消息没发送成功,他会重试再次发送消息过去。
此时可能Partition 2的Follower变成Leader了,此时ISR列表里只有最新的这个Follower转变成的Leader了,那么只要这个新的Leader接收消息就算成功了。

(6)最后的思考
acks=all 就可以代表数据一定不会丢失了吗?
当然不是,如果你的Partition只有一个副本,也就是一个Leader,任何Follower都没有,你认为acks=all有用吗?
当然没用了,因为ISR里就一个Leader,他接收完消息后宕机,也会导致数据丢失。
所以说,这个acks=all,必须跟ISR列表里至少有2个以上的副本配合使用,起码是有一个Leader和一个Follower才可以。
这样才能保证说写一条数据过去,一定是2个以上的副本都收到了才算是成功,此时任何一个副本宕机,不会导致数据丢失。
所以希望大家把这篇文章好好理解一下,对大家出去面试,或者工作中用kafka都是很好的一个帮助。
kafka 讲讲acks参数对消息持久化的影响的更多相关文章
- 面试官让你讲讲acks参数对消息持久化的影响
(0)写在前面 面试大厂时,一旦简历上写了Kafka,几乎必然会被问到一个问题:说说acks参数对消息持久化的影响? 这个acks参数在kafka的使用中,是非常核心以及关键的一个参数,决定了很多东西 ...
- kafka什么时候会丢消息(转)
因为在具体开发中某些环节考虑使用kafka却担心有消息丢失的风险,本周结合项目对kafka的消息可靠性做了一下调研和总结: 首先明确一下丢消息的定义.kafka集群中的部分或全部broker挂了,导致 ...
- RabbitMQ基本用法、消息分发模式、消息持久化、广播模式
RabbitMQ基本用法 进程queue用于同一父进程创建的子进程间的通信 而RabbitMQ可以在不同父进程间通信(例如在word和QQ间通信) 示例代码 生产端(发送) import pika c ...
- Spring Kafka中关于Kafka的配置参数
#################consumer的配置参数(开始)################# #如果'enable.auto.commit'为true,则消费者偏移自动提交给Kafka的频率 ...
- 深入浅出理解基于 Kafka 和 ZooKeeper 的分布式消息队列
消息队列中间件是分布式系统中重要的组件,主要解决应用耦合,异步消息,流量削锋等问题.实现高性能,高可用,可伸缩和最终一致性架构,是大型分布式系统不可缺少的中间件. 本场 Chat 主要内容: Kafk ...
- Kafka 和 ZooKeeper 的分布式消息队列分析
1. Kafka 总体架构 基于 Kafka-ZooKeeper 的分布式消息队列系统总体架构如下: 如上图所示,一个典型的 Kafka 体系架构包括若干 Producer(消息生产者),若干 bro ...
- Kafka:主要参数详解(转)
原文地址:http://kafka.apache.org/documentation.html ############################# System ############### ...
- RabbitMQ原理与相关操作(三)消息持久化
现在聊一下RabbitMQ消息持久化: 问题及方案描述 1.当有多个消费者同时收取消息,且每个消费者在接收消息的同时,还要处理其它的事情,且会消耗很长的时间.在此过程中可能会出现一些意外,比如消息接收 ...
- EQueue - 详细谈一下消息持久化以及消息堆积的设计
前言 之前写了一篇文章,总体介绍了EQueue.在看这篇文章之前如果还没看过那篇文章,可能会看不懂这篇文章.所以建议没看过的朋友务必先看一下那篇文章中所提到的各种概念,这样才能更好的理解本文所说的内容 ...
随机推荐
- iOS 如何判断一个点在某个指定区域中
在iOS 开发中会遇到 判断位置的情况 iOS 自己都有函数实现的这些功能. 判断一个点是否在这个rect区域中 bool CGRectContainsPoint(CGRect rect,CGPoin ...
- iOS退出APP
强制退出有四种: exit(); abort(); assert(); 主动制造一个崩溃: exit() 1.附加了关闭打开文件与返回状态码给执行环境,并调用你用atexit注册的返回函数: 2.警告 ...
- Jmeter学习笔记(六)——使用badboy录制脚本
1.下载安装 可以去badboy官网下载地址:http://www.badboy.com.au,如果官网打不开也可以去网上搜索下载. 下载之后点击BadboyInstaller-2.2.5.exe普通 ...
- Linux建立虚拟ip的方法
文章来源 运维公会:Linux建立虚拟ip的方法 1.虚拟ip的介绍 虚拟IP地址(VIP) 是一个不与特定计算机或一个计算机中的网络接口卡(NIC)相连的IP地址.数据包被发送到这个VIP地址, ...
- CentOS7.x安装nginx
1.安装先决条件 yum install yum-utils 2.设置yum存储库和创建/etc/yum.repos.d/nginx.repo 使用以下内容命名的文件 :稳定版 [nginx-stab ...
- GITHUB下载源码方式
从昨天开始就想着从GitHub上下载一个开源的Vue的实战项目,希望能从中学习更多的Vue的实用内容,结果搞了半天好不容易下载了,不知道怎么弄.然而,今天终于成功了,激动地我赶紧来记录一下.如何从Gi ...
- python func(*args, **kwargs)
func(*args, **kwargs) *args, **kwargs表示函数的可变参数 *args 表示任何多个无名参数,它是一个tuple **kwargs 表示关键字参数,它是一个dict ...
- 29、[源码]-AOP原理-AnnotationAwareAspectJAutoProxyCreatovi
29.[源码]-AOP原理-AnnotationAwareAspectJAutoProxyCreatovi
- iOS入门及ObjC语法
iOS入门:http://www.jonathanhui.com/ios ObjC语法: http://www.jonathanhui.com/objective-c https://github.c ...
- Java知识点汇总-1
目录 1 native方法 2 泛型 3 hashcode 4 JDK主要的包 5 被final修饰的类特点 6 空串与null串 7 判断字符串是否相等 1 native方法 JDK源代码由C++. ...