L1、L2正则化详解
正则化是一种回归的形式,它将系数估计(coefficient estimate)朝零的方向进行约束、调整或缩小。也就是说,正则化可以在学习过程中降低模型复杂度和不稳定程度,从而避免过拟合的危险。
一、数学基础
1. 范数
范数是衡量某个向量空间(或矩阵)中的每个向量以长度或大小。范数的一般化定义:对实数p>=1, 范数定义如下:

- L1范数
当p=1时,是L1范数,其表示某个向量中所有元素绝对值的和。 - L2范数
当p=2时,是L2范数, 表示某个向量中所有元素平方和再开根, 也就是欧几里得距离公式。
2. 拉普拉斯分布
如果随机变量的概率密度函数分布为:

那么它就是拉普拉斯分布。其中,μ 是数学期望,b > 0 是振幅。如果 μ = 0,那么,正半部分恰好是尺度为 1/2 的指数分布。

3. 高斯分布
又叫正态分布,若随机变量X服从一个数学期望为μ、标准方差为σ2的高斯分布,记为:X∼N(μ,σ2),其概率密度函数为:

其概率密度函数为正态分布的期望值μ决定了其位置,其标准差σ决定了分布的幅度。当μ = 0,σ = 1时的正态分布是标准正态分布。

还有涉及极大似然估计、概率论相关的先验和后验相关概率, 为了控制篇幅, 本文就不详细介绍, wiki百科和百度百科都讲得很清楚。
二、正则化解决过拟合问题
正则化通过降低模型的复杂性, 达到避免过拟合的问题。 正则化是如何解决过拟合的问题的呢?从网上找了很多相关文章, 下面列举两个主流的解释方式。
原因1:来自知乎上一种比较直观和简单的理解, 模型过于复杂是因为模型尝试去兼顾各个测试数据点, 导致模型函数如下图,处于一种动荡的状态, 每个点的到时在某些很小的区间里,函数值的变化很剧烈。这就意味着函数在某些小区间里的导数值(绝对值)非常大,由于自变量值可大可小,所以只有系数足够大,才能保证导数值很大。

而加入正则能抑制系数过大的问题。如下公式, 是岭回归的计算公式。

如果发生过拟合, 参数θ一般是比较大的值, 加入惩罚项后, 只要控制λ的大小,当λ很大时,θ1到θn就会很小,即达到了约束数量庞大的特征的目的。
原因二:从贝叶斯的角度来分析, 正则化是为模型参数估计增加一个先验知识,先验知识会引导损失函数最小值过程朝着约束方向迭代。 L1正则是拉普拉斯先验,L2是高斯先验。整个最优化问题可以看做是一个最大后验估计,其中正则化项对应后验估计中的先验信息,损失函数对应后验估计中的似然函数,两者的乘积即对应贝叶斯最大后验估计。
给定训练数据, 贝叶斯方法通过最大化后验概率估计参数θ:

说明:P(θ)是参数向量θ的先验概率。
下面我们从最大后验估计(MAP)的方式, 推导下加入L1和L2惩罚项的Lasso和岭回归的公式。
首先我们看下最小二乘公式的推导(公式推导截图来自知乎大神)

这个是通过最大似然估计的方法, 推导出线性回归最小二乘计算公式。
假设1: w参数向量服从高斯分布
以下为贝叶斯最大后验估计推导:
最终的公式就是岭回归计算公式。与上面最大似然估计推导出的最小二乘相比,最大后验估计就是在最大似然估计公式乘以高斯先验, 这里就理解前面L2正则就是加入高斯先验知识。
假设2: w参数服从拉普拉斯分布
以下为贝叶斯最大后验估计推导:
最终的公式就是Lasso计算公式。与上面最大似然估计推导出的最小二乘相比,最大后验估计就是在最大似然估计公式乘以拉普拉斯先验, 这里就理解前面L1正则就是加入拉普拉斯先验知识。


L1和L2正则化的比较
为了帮助理解,我们来看一个直观的例子:假定x仅有两个属性,于是无论岭回归还是Lasso接触的w都只有两个分量,即w1,w2,我们将其作为两个坐标轴,然后在图中绘制出两个式子的第一项的”等值线”,即在(w1,w2)空间中平方误差项取值相同的点的连线。再分别绘制出L1范数和L2范数的等值线,即在(w1,w2)空间中L1范数取值相同的点的连线,以及L2范数取值相同的点的连线(如下图所示)。
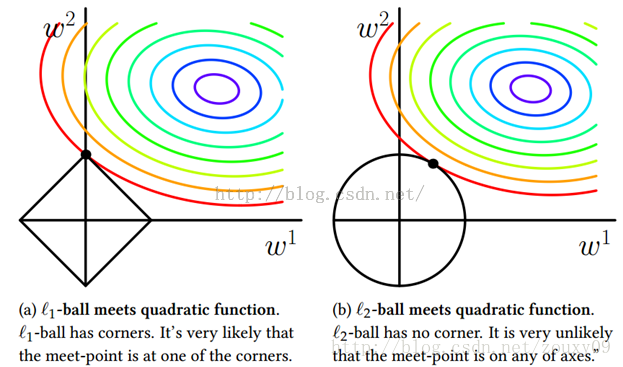
岭回归与Lasso的解都要在平方误差项与正则化项之间折中,即出现在图中平方误差项等值线与正则化项等值线相交处。而由上图可以看出,采用L1范数时平方误差项等值线与正则化项等值线的交点常出现在坐标轴上,即w1或w2为0,而在采用L2范数时,两者的交点常出现在某个象限中,即w1或w2均非0。
这说明了岭回归的一个明显缺点:模型的可解释性。它将把不重要的预测因子的系数缩小到趋近于 0,但永不达到 0。也就是说,最终的模型会包含所有的预测因子。但是,在 Lasso 中,如果将调整因子 λ 调整得足够大,L1 范数惩罚可以迫使一些系数估计值完全等于 0。因此,Lasso 可以进行变量选择,产生稀疏模型。注意到w取得稀疏解意味着初始的d个特征中仅有对应着w的非零分量的特征才会出现在最终模型中,于是求解L1范数正则化的结果时得到了仅采用一部分初始特征的模型;换言之,基于L1正则化的学习方法就是一种嵌入式特征选择方法,其特征选择过程和学习器训练过程融为一体,同时完成。
总结
- L2 regularizer :使得模型的解偏向于范数较小的 W,通过限制 W 范数的大小实现了对模型空间的限制,从而在一定程度上避免了 overfitting 。不过 ridge regression 并不具有产生稀疏解的能力,得到的系数仍然需要数据中的所有特征才能计算预测结果,从计算量上来说并没有得到改观。
- L1 regularizer :它的优良性质是能产生稀疏性,导致 W 中许多项变成零。 稀疏的解除了计算量上的好处之外,更重要的是更具有“可解释性”。
作者:suwi
链接:https://www.jianshu.com/p/c9bb6f89cfcc
L1、L2正则化详解的更多相关文章
- 机器学习中正则惩罚项L0/L1/L2范数详解
https://blog.csdn.net/zouxy09/article/details/24971995 原文转自csdn博客,写的非常好. L0: 非零的个数 L1: 参数绝对值的和 L2:参数 ...
- 机器学习中L1,L2正则化项
搞过机器学习的同学都知道,L1正则就是绝对值的方式,而L2正则是平方和的形式.L1能产生稀疏的特征,这对大规模的机器学习灰常灰常重要.但是L1的求解过程,实在是太过蛋疼.所以即使L1能产生稀疏特征,不 ...
- 防止过拟合:L1/L2正则化
正则化方法:防止过拟合,提高泛化能力 在训练数据不够多时,或者overtraining时,常常会导致overfitting(过拟合).其直观的表现如下图所示,随着训练过程的进行,模型复杂度增加,在tr ...
- ML-线性模型 泛化优化 之 L1 L2 正则化
认识 L1, L2 从效果上来看, 正则化通过, 对ML的算法的任意修改, 达到减少泛化错误, 但不减少训练误差的方式的统称 训练误差 这个就损失函数什么的, 很好理解. 泛化错误 假设 我们知道 预 ...
- L0,L1,L2正则化浅析
在机器学习的概念中,我们经常听到L0,L1,L2正则化,本文对这几种正则化做简单总结. 1.概念 L0正则化的值是模型参数中非零参数的个数. L1正则化表示各个参数绝对值之和. L2正则化标识各个参数 ...
- L1,L2正则化代码
# L1正则 import numpy as np from sklearn.linear_model import Lasso from sklearn.linear_model import SG ...
- HIVE之正则化详解
有大神写的很好了,我借花献佛,有兴趣,看链接,在此不再赘述.想要学习Hive正则表达式重点应该是正则表达式的表示方式,只有正则表达式使用溜了,hive正则那就是小case. 附参考博文: https: ...
- L1和L2正则化(转载)
[深度学习]L1正则化和L2正则化 在机器学习中,我们非常关心模型的预测能力,即模型在新数据上的表现,而不希望过拟合现象的的发生,我们通常使用正则化(regularization)技术来防止过拟合情况 ...
- python数据类型及其详解
一.数据类型介绍 1.字符串(string) 三种类型:单引号,双引号,三引号 a = 'jam' b = "JamHsiao" c = '''JAMHSIAO''' print( ...
随机推荐
- 【基础数位DP-模板】HDU-2089-不要62
不要62 Time Limit: / MS (Java/Others) Memory Limit: / K (Java/Others) Total Submission(s): Accepted Su ...
- jmeter非GUI的运行命令
jmeter 的参数 参数说明: -h 帮助 -> 打印出有用的信息并退出 -n 非 GUI 模式 -> 在非 GUI 模式下运行 JMeter -t 测试文件 -> 要运行的 JM ...
- 1113 form表单与css选择器
目录 1.form表单 form元素 特点 参数 form元素内的控件 1.input的使用 2.select标签 3.textarea元素 4.autofocus属性 2.CSS 1.基础语法 cs ...
- wxpython图形化界面编程(一):添加菜单,设置图片大小,添加文本框等,并简要布局
#-*-encoding:utf-8-*-import wx def loadframe(): app = wx.App() mywindow = myframe() mywindow.Show() ...
- SIGAI深度学习第二集 人工神经网络1
讲授神经网络的思想起源.神经元原理.神经网络的结构和本质.正向传播算法.链式求导及反向传播算法.神经网络怎么用于实际问题等 课程大纲: 神经网络的思想起源 神经元的原理 神经网络结构 正向传播算法 怎 ...
- Base64().encodeBase64Chunked导致换行符的问题
String linkStr=new String(new Base64().encodeBase64Chunked(new String("conferid="+cid+&quo ...
- 存在日期类型的JSON数据,进行SpringMVC参数绑定时存在的问题和解决方案
这篇文章已经过时了. 请参考比较合适的前后端交互方式. 首先是发送AJAX请求的html页面 <!DOCTYPE html> <html> <head> <m ...
- Flask-第三方插件
Flask-Session 因为flask自带的session是将session存在cookie中: 所以才有了第三方Flask_session插件,可以将session存储在我们想存储的数据库中(r ...
- GEOS库的编译
下载地址https://trac.osgeo.org/geos/ 选择最新的geos-3.6.2版本,下载 将geos-3.6.2放在VS2012文件夹下,本例是D:\VS2012 打开VS2012开 ...
- org.hibernate.TypeMismatchException: Provided id of the wrong type for class *** Expected ***
今天上生产发现warn日志有异常,就查看了下: 2018-12-05 10:05:05.666 [pool-4-thread-1] ERROR org.springframework.batch.co ...