centos7搭建EFK日志分析系统
前言
EFK可能都不熟悉,实际上EFK是大名鼎鼎的日志系统ELK的一个变种
在没有分布式日志的时候,每次出问题了需要查询日志的时候,需要登录到Linux服务器,使用命令cat -n xxxx|grep xxxx 搜索出日志在哪一行,然后cat -n xxx|tail -n +n行|head -n 显示多少行,这样不仅效率低下,而且对于程序异常也不方便查询,日志少还好,一旦整合出来的日志达到几个G或者几十G的时候,仅仅是搜索都会搜索很长时间了,当然如果知道是哪天什么时候发生的问题当然也方便查询,但是实际上很多时候有问题的时候,是不知道到底什么时候出的问题,所以就必须要在聚合日志中去搜索(一般日志是按照天来分文件的,聚合日志就是把很多天的日志合并在一起,这样方便查询),而搭建EFK日志分析系统的目的就是将日志聚合起来,达到快速查看快速分析的目的,使用EFK不仅可以快速的聚合出每天的日志,还能将不同项目的日志聚合起来,对于微服务和分布式架构来说,查询日志尤为方便,而且因为日志保存在Elasticsearch中,所以查询速度非常之快
认识EFK
EFK不是一个软件,而是一套解决方案,并且都是开源软件,之间互相配合使用,完美衔接,高效的满足了很多场合的应用,是目前主流的一种日志系统。EFK是三个开源软件的缩写,分别表示:Elasticsearch , FileBeat, Kibana , 其中ELasticsearch负责日志保存和搜索,FileBeat负责收集日志,Kibana 负责界面,当然EFK和大名鼎鼎的ELK只有一个区别,那就是EFK把ELK的Logstash替换成了FileBeat,因为Filebeat相对于Logstash来说有2个好处:
1、侵入低,无需修改程序目前任何代码和配置
2、相对于Logstash来说性能高,Logstash对于IO占用很大
当然FileBeat也并不是完全好过Logstash,毕竟Logstash对于日志的格式化这些相对FileBeat好很多,FileBeat只是将日志从日志文件中读取出来,当然如果你日志本身是有一定格式的,FileBeat也可以格式化,但是相对于Logstash来说,还是差一点
Elasticsearch
Elasticsearch是个开源分布式搜索引擎,提供搜集、分析、存储数据三大功能。它的特点有:分布式,零配置,自动发现,索引自动分片,索引副本机制,restful风格接口,多数据源,自动搜索负载等。
FileBeat
Filebeat隶属于Beats。目前Beats包含六种工具:
Packetbeat(搜集网络流量数据)
Metricbeat(搜集系统、进程和文件系统级别的 CPU 和内存使用情况等数据)
Filebeat(搜集文件数据)
Winlogbeat(搜集 Windows 事件日志数据)
Auditbeat( 轻量型审计日志采集器)
Heartbeat(轻量级服务器健康采集器)
Kibana
Kibana可以为 Logstash 、Beats和 ElasticSearch 提供的日志分析友好的 Web 界面,可以帮助汇总、分析和搜索重要数据日志。
EFK架构图
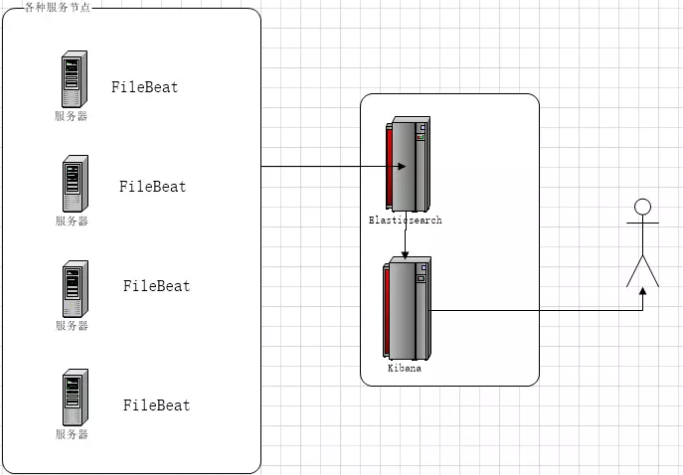
安装Java JDK
Elasticsearch需要运行在Java 8 及以上,所以需要先安装Java8,下载JavaJDK
登录网址:http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
选择对应jdk版本下载。
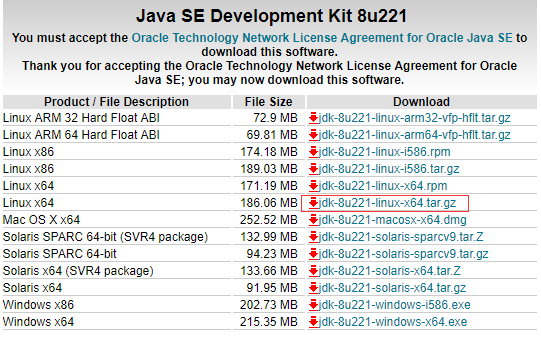
解压
tar -zxvf jdk-8u221-linux-x64.tar.gz
编辑环境变量
vi /etc/profile
在文件末尾加上
JAVA_HOME=/usr/local/jdk1.8.0_221/
JRE_HOME=$JAVA_HOME/jre
CLASS_PATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JRE_HOME/lib
PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin
export JAVA_HOME JRE_HOME CLASS_PATH PATH
其中/usr/local/jdk1.8.0_221/替换成自己Java jdk解压出来的主目录,wq保存退出,使配置生效
source /etc/profile
查看是否安装成功
java -version
如果正常输出Java版本则安装成功
安装Elasticsearch
下载Elasticsearch,本文以Elasticsearch6.2.4为例,当前Elasticsearch最新版本为Elasticsearch6.4.0,注意Elasticsearch、Kibana、FileBeat一定要使用相同的版本
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-6.2.4.tar.gz
解压
tar -zxvf elasticsearch-6.2.4.tar.gz
进入Elasticsearch主目录,修改配置
vi config/elasticsearch.yml
添加以下配置,或者将对应的配置注释取消修改
network.host: 0.0.0.0
http.port: 9200
由于Elasticsearch不能使用root用户打开,所以需要专门创建一个用户来启动Elasticsearch
$ adduser elastic
#设置密码
$ passwd elastic
#需要输入2次密码
#授权
$ chmod -R 777 /usr/local/elasticsearch-6.2.4
#切换用户
$ su elastic
创建的用户名为elastic,其中/usr/local/elasticsearch-6.2.4为解压出来的Elasticsearch主目录
启动Elasticsearch
./bin/elasticsearch
如果遇到错误:max file descriptors [65535] for elasticsearch process is too low, increase to at least [65536]
vi /etc/security/limits.conf
如果有 * soft nofile 65535 * hard nofile 65535 则将65535修改为65536,如果没有则在后面添加,注意此处的65535对应descriptors [65535]中的65535,修改后的值65536对应increase to at least [65536],所以当提示不一致时,需要根据具体的错误提示具体修改
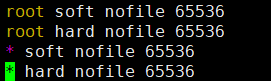
如果遇到错误: max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]
vi /etc/sysctl.conf
添加配置
vm.max_map_count=262144
并执行命令
sysctl -p
以上2个修改需要在root用户权限修改,如果是使用xshell开两个窗口的话修改完成之后一定要断开重新登录一下,启动成功用执行命令
curl 127.0.0.1:9200
会得到类似以下json
{
"name" : "dQIO4Ad",
"cluster_name" : "elasticsearch",
"cluster_uuid" : "P8KtmO3vQdactRW1jX9JnQ",
"version" : {
"number" : "6.2.4",
"build_hash" : "ccec39f",
"build_date" : "2018-04-12T20:37:28.497551Z",
"build_snapshot" : false,
"lucene_version" : "7.2.1",
"minimum_wire_compatibility_version" : "5.6.0",
"minimum_index_compatibility_version" : "5.0.0"
},
"tagline" : "You Know, for Search"
}
安装Kibana
下载Kibana
wget https://artifacts.elastic.co/downloads/kibana/kibana-6.2.4-linux-x86_64.tar.gz
解压
tar -zxvf kibana-6.2.4-linux-x86_64.tar.gz
进入主目录,修改配置
vi config/kibana.yml
添加以下配置或者取消注释并修改
elasticsearch.url: "http://localhost:9200"
server.host: "0.0.0.0"
kibana.index: ".kibana"
其中elasticsearch.url为Elasticsearch的地址,server.host默认是localhost,如果只是本地访问可以默认localhost,如果需要外网访问,可以设置为0.0.0.0
启动Kibana
./bin/kibana
安装FileBeat
下载FileBeat
wget https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-6.2.4-linux-x86_64.tar.gz
解压
tar -zxvf filebeat-6.2.4-linux-x86_64.tar.gz
进入主目录,修改配置
vi filebeat.yml
找到类似以下的配置并修改
filebeat.prospectors:
- type: log
enabled: true
paths:
- /var/xxx/*.log
- /var/xxx/*.out
- /var/lib/docker/containers/*/*.log
multiline.pattern: ^\[
multiline.negate: true
multiline.match: after
setup.kibana:
host: "localhost:5601"
output.elasticsearch:
hosts: ["localhost:9200"]
配置一定要注意格式,是以2个空格为子级,里面的配置都在配置文件中,列出来的只是要修改的部分,enabled默认为false,需要改成true才会收集日志。其中/var/xxx/*.log修改为自己的日志路径,注意-后面有一个空格,
如果多个路径则添加一行,一定要注意新行前面的4个空格,multiline开头的几个配置取消注释就行了,是为了兼容多行日志的情况,setup.kibana中的host取消注释,根据实际情况配置地址,output.elasticsearch中的host也一样,根据实际情况配置
如果要在efk服务器上收集其他节点服务器的日志,要在需要被收集日志的服务器节点安装filebeat,并修改filebeat的yml文件中setup.kibana和output.elasticsearch的host指定elk的服务器地址。
启动FileBeat
./filebeat -c /usr/local/filebeat-6.2.4-linux-x86_64/filebeat.yml
/usr/local/filebeat/filebeat.yml为filebeat 的配置文件地址,需要根据实际情况修改,启动后FileBeat就会自动收集日志了
配置Kibana
打开浏览器进入http://127.0.0.1:5601,会出现如下页面:
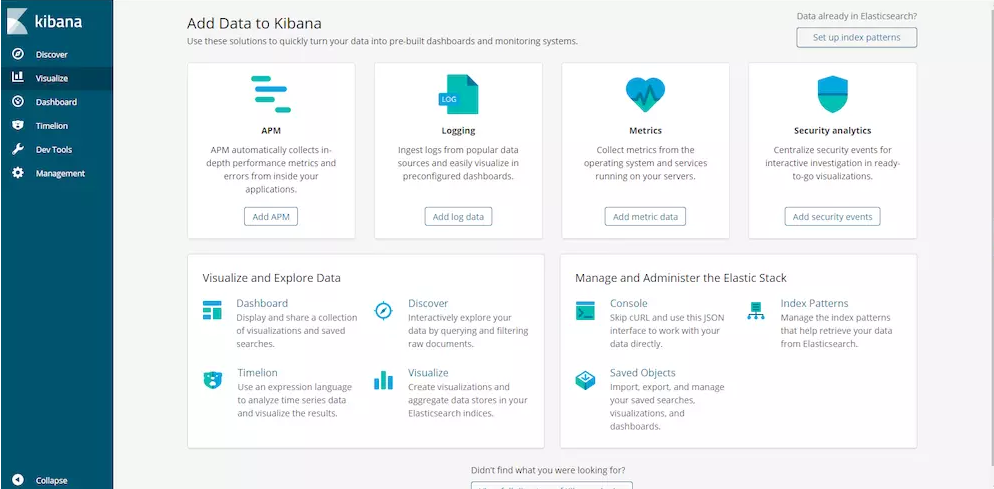
点击Management进入配置
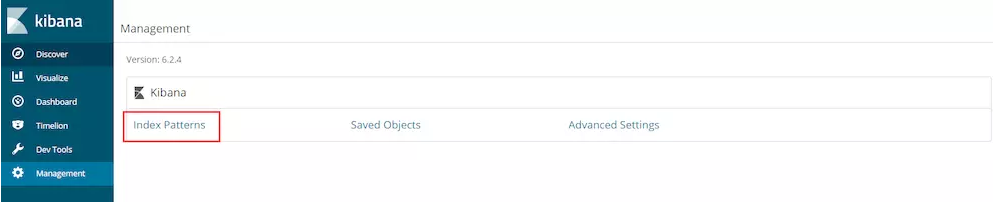
点击进入Index Patterns

如图所示,FileBeat默认创建的Elasticsearch索引格式为filebeat-版本号-日期,所以需要在第一个红框的输入框中输入
filebeat-6.2.4-*
能匹配到Elasticsearch的索引,第二个红框出会显示出Elasticsearch中已有的索引,点击Next step进入下一步

点击Create index pattern完成配置,配置完成后点击 Discover就能查看日志了,还能搜索,如下图

EFK搭建成功!!!
centos7搭建EFK日志分析系统的更多相关文章
- 十九,基于helm搭建EFK日志收集系统
目录 EFK日志系统 一,EFK日志系统简介: 二,EFK系统部署 1,EFK系统部署方式 2,基于Helm方式部署EFK EFK日志系统 一,EFK日志系统简介: 关于系统日志收集处理方案,其实有很 ...
- Docker搭建EFK日志收集系统,并自定义es索引名
EFK架构图 一.EFK简介 EFK不是一个软件,而是一套解决方案,并且都是开源软件,之间互相配合使用,完美衔接,高效的满足了很多场合的应用,是目前主流的一种日志系统. EFK是三个开源软件的缩写,分 ...
- 快速搭建ELK日志分析系统
一.ELK搭建篇 官网地址:https://www.elastic.co/cn/ 官网权威指南:https://www.elastic.co/guide/cn/elasticsearch/guide/ ...
- Kubernetes 系列(八):搭建EFK日志收集系统
Kubernetes 中比较流行的日志收集解决方案是 Elasticsearch.Fluentd 和 Kibana(EFK)技术栈,也是官方现在比较推荐的一种方案. Elasticsearch 是一个 ...
- 搭建ELK日志分析系统
看了辣么多博客,就数这个最详细最容易理解了:https://blog.csdn.net/qq_22211217/article/details/80764568 >>>>> ...
- Docker搭建ElasticSearch+Redis+Logstash+Filebeat日志分析系统
一.系统的基本架构 在以前的博客中有介绍过在物理机上搭建ELK日志分析系统,有兴趣的朋友可以看一看-------------->>链接戳我<<.这篇博客将介绍如何使用Docke ...
- 十分钟搭建和使用ELK日志分析系统
前言 为满足研发可视化查看测试环境日志的目的,准备采用EK+filebeat实现日志可视化(ElasticSearch+Kibana+Filebeat).题目为“十分钟搭建和使用ELK日志分析系统”听 ...
- 快速搭建ELK7.5版本的日志分析系统--搭建篇
title: 快速搭建ELK7.5版本的日志分析系统--搭建篇 一.ELK安装部署 官网地址:https://www.elastic.co/cn/ 官网权威指南:https://www.elastic ...
- Rsyslog+ELK日志分析系统搭建总结1.0(测试环境)
因为工作需求,最近在搭建日志分析系统,这里主要搭建的是系统日志分析系统,即rsyslog+elk. 因为目前仍为测试环境,这里说一下搭建的基础架构,后期上生产线再来更新最后的架构图,大佬们如果有什么见 ...
随机推荐
- Homebrew 使用国内镜像
在国内的网络环境下使用 Homebrew 安装软件的过程中,可能会长时间卡在 Updating Homebrew ... 方法一:按command + c 取消本次更新操作,直接安装软件 方法二:设置 ...
- Multiple commands produce "*.framework"
参考链接记录个问题,这是xcode10后新build系统导致的,新系统帮我们检查了很多东西,最优化我们的构建, 两种方案 1.用旧的系统(不推荐) 2.这个是build setting->b ...
- 彻底搞懂Python的字符编码
前言:中文编码问题一直是程序员头疼的问题,而Python2中的字符编码足矣令新手抓狂.本文将尽量用通俗的语言带大家彻底的了解字符编码以及Python2和3中的各种编码问题. 一.什么是字符编码. 要彻 ...
- web-msg-sender的https支持改造
用的是nginx代理转发443到2120端口实现,官方说workman原生支持,没有实现(现象是 访问 htttps://域名:2120/ 超时,不知道是服务器问题还是什么) 后转为用nginx代理转 ...
- Fiddler is not capturing web request from Firefox
Fiddler is not capturing web request from Firefox You can also get the FiddlerHook plug in for Firef ...
- python文件导出exe可执行程序
开门见山的说: 1.安装pyinstaller.(windows 用pip3 Mac 用pip)在cmd中输入:pip3 install pyinstaller 2.找到你要打包的文件的目录的上一个目 ...
- imfilter
图像处理函数详解——imfilter功能:对任意类型数组或多维图像进行滤波.用法:B = imfilter(A,H) B = imfilter(A,H,option1,option2,...) 或写作 ...
- SQL SERVER SELECT语句中加锁选项的详细说明
共享锁(读锁)和排他锁(写锁) 共享锁(S锁):共享 (S) 用于不更改或不更新数据的操作(只读操作),如 SELECT 语句. 如果事务T对数据A加上共享锁后,则其他事务只能对A再加共享锁,不能 ...
- python2,socket多进程的错误pickle.PicklingError: Can't pickle
python2,socket多进程的错误pickle.PicklingError: Can't pickle 源码: #coding:utf-8 import socket import pickle ...
- ubuntu 12.04 以固定 IP 地址连接网络并配置DNS
sudo vim /etc/network/interfaces auto eth0 iface eth0 inet static address 192.168.2.155 netmask 255. ...