ORM 数据库使用
使用 Flask-SQLAlchemy 来操作数据库
1 配置
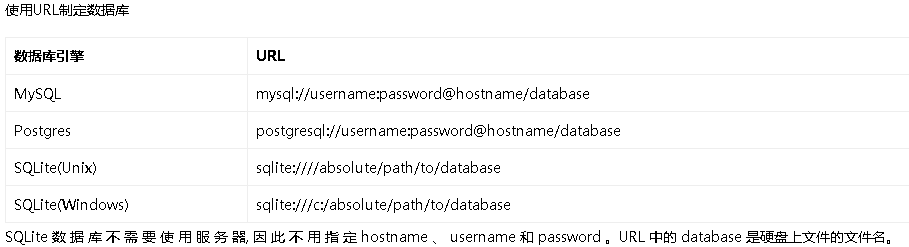
本文使用sqlite来作为例子演示,在config.py里面更新下数据库的配置
import os
basedir = os.path.abspath(os.path.dirname(__file__))
SQLALCHEMY_DATABASE_URI = 'sqlite:///' + os.path.join(basedir, 'app.db')
SQLALCHEMY_MIGRATE_REPO = os.path.join(basedir, 'db_repository')Flask-SQLAlchemy会引用到 SQLALCHEMY_DATABASE_URI 来获取数据库的存储位置,SQLAlchemy-migrate 会引用SQLALCHEMY_MIGRATE_REPO,移动的数据库文件会放到这个目录下
配置对象中还有一个很有用的选项,即 SQLALCHEMY_COMMIT_ON_TEARDOWN 键,将其设为 True时,每次请求结束后都会自动提交数据库中的变动
完善数据库基本配置之后,在app/__init__.py初始化数据库引擎对象
from flask import Flask
from flask_sqlalchemy import SQLAlchemy
app = Flask(__name__)
app.config.from_object('config')
db = SQLAlchemy(app)
from app import views, models
这样就初始化了一个db对象,并且引入models,models就是数据库的描述模版,下面会介绍
2 设计数据库model

如何用Flask-SQLAlchemy描述这张表?app/models.py
from app import db
class User(db.Model):
id = db.Column(db.Integer, primary_key=True)
nickname = db.Column(db.String(64), index=True, unique=True)
email = db.Column(db.String(120), index=True, unique=True)
def __repr__(self):
return '<User %r>' % (self.nickname)3 创建数据库
配置好了,数据库表也定义好了,接下来就是创建数据库。创建一个创建数据库的脚本,放到跟config.py同目录下,命名为db_create.py。先安装SQLAlchemy-migrate
easy_install SQLAlchemy-migrate 安装完成之后,编写db_create.py
#!flask/bin/python
from migrate.versioning import api
from config import SQLALCHEMY_DATABASE_URI
from config import SQLALCHEMY_MIGRATE_REPO
from app import db
import os.path
db.create_all()
if not os.path.exists(SQLALCHEMY_MIGRATE_REPO):
api.create(SQLALCHEMY_MIGRATE_REPO, 'database repository')
api.version_control(SQLALCHEMY_DATABASE_URI, SQLALCHEMY_MIGRATE_REPO)
else:
api.version_control(SQLALCHEMY_DATABASE_URI, SQLALCHEMY_MIGRATE_REPO, api.version(SQLALCHEMY_MIGRATE_REPO))
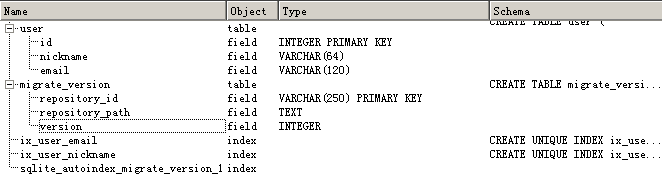
运行db_create.py创建数据库,python ./db_create.py,创建成功后会生成如下文件

3 数据迁移
models.py更新了,添加一张表,怎么更新数据库,可以把每次数据库结构的变动当作一次数据迁移
#!flask/bin/python运行 python ./db_migrate.py
import imp
from migrate.versioning import api
from app import db
from config import SQLALCHEMY_DATABASE_URI
from config import SQLALCHEMY_MIGRATE_REPO
v = api.db_version(SQLALCHEMY_DATABASE_URI, SQLALCHEMY_MIGRATE_REPO)
migration = SQLALCHEMY_MIGRATE_REPO + ('/versions/%03d_migration.py' % (v+1))
tmp_module = imp.new_module('old_model')
old_model = api.create_model(SQLALCHEMY_DATABASE_URI, SQLALCHEMY_MIGRATE_REPO)
exec(old_model, tmp_module.__dict__)
script = api.make_update_script_for_model(SQLALCHEMY_DATABASE_URI, SQLALCHEMY_MIGRATE_REPO, tmp_module.meta, db.metadata)
open(migration, "wt").write(script)
api.upgrade(SQLALCHEMY_DATABASE_URI, SQLALCHEMY_MIGRATE_REPO)
v = api.db_version(SQLALCHEMY_DATABASE_URI, SQLALCHEMY_MIGRATE_REPO)
print('New migration saved as ' + migration)
print('Current database version: ' + str(v))
SQLAlchemy-migrate通过对比数据库的结构(从app.db文件读取)和models结构(从app/models.py文件读取)的方式来创建迁移任务,两者之间的差异将作为一个迁移脚本记录在迁移库中,迁移脚本知道如何应用或者撤销一次迁移,所以它可以方便的升级或者降级一个数据库的格式
3 操作实战
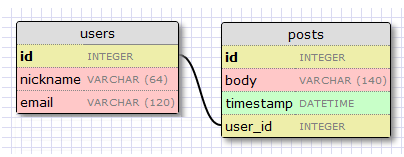
更新app/models.py
from app import db
class User(db.Model):
id = db.Column(db.Integer, primary_key=True)
nickname = db.Column(db.String(64), index=True, unique=True)
email = db.Column(db.String(120), index=True, unique=True)
posts = db.relationship('Post', backref='author', lazy='dynamic')
def __repr__(self):
return '<User %r>' % (self.nickname)
class Post(db.Model):
id = db.Column(db.Integer, primary_key = True)
body = db.Column(db.String(140))
timestamp = db.Column(db.DateTime)
user_id = db.Column(db.Integer, db.ForeignKey('user.id'))
def __repr__(self):
return '<Post %r>' % (self.body)
运行 python ./db_migrate.py,查看数据库磁盘结构
Users这张表并没有posts字段,why?SQLAlchemy运行时会动态向Usrs插入posts字段,这样访问Users.posts会包含这个用户发出的所有文章列表。这里relationship第二个参数backref='author',效果就是系统动态往Post插入author字段,这样访问post.author就能访问到该文章作者的信息了
3 操作数据库
可以在线操作,也可以离线操作,只要在python文件里面
from app import db, models就可以操作数据库了
from app import db, models
import datetime
@app.route('/testdb_addusers')
def testdb_addusers():
users = { 'Miguel', 'sysnap', 'helxx', 'xxxx'}
for name in users:
mail = name + '@email.com'
u = models.User(nickname=name, email=mail)
db.session.add(u)
p = models.Post(body='my first post!', timestamp=datetime.datetime.utcnow(), author=u)
db.session.add(p)
db.session.commit()
return "add user ok"
@app.route('/testdb_queryall')
def testdb_queryall():
users = models.User.query.all()
for u in users:
print u.email,u.nickname, u.posts.all()
return "xxxx"
ORM 数据库使用的更多相关文章
- Android高性能ORM数据库DBFlow入门
DBFlow,综合了 ActiveAndroid, Schematic, Ollie,Sprinkles 等库的优点.同时不是基于反射,所以性能也是非常高,效率紧跟greenDAO其后.基于注解,使用 ...
- golang学习笔记16 beego orm 数据库操作
golang学习笔记16 beego orm 数据库操作 beego ORM 是一个强大的 Go 语言 ORM 框架.她的灵感主要来自 Django ORM 和 SQLAlchemy. 目前该框架仍处 ...
- ORM数据库框架 SQLite 常用数据库框架比较 MD
Markdown版本笔记 我的GitHub首页 我的博客 我的微信 我的邮箱 MyAndroidBlogs baiqiantao baiqiantao bqt20094 baiqiantao@sina ...
- ORM数据库框架 SQLite ORMLite MD
Markdown版本笔记 我的GitHub首页 我的博客 我的微信 我的邮箱 MyAndroidBlogs baiqiantao baiqiantao bqt20094 baiqiantao@sina ...
- ORM数据库框架 greenDAO SQLite MD
Markdown版本笔记 我的GitHub首页 我的博客 我的微信 我的邮箱 MyAndroidBlogs baiqiantao baiqiantao bqt20094 baiqiantao@sina ...
- ORM数据库框架 LitePal SQLite MD
Markdown版本笔记 我的GitHub首页 我的博客 我的微信 我的邮箱 MyAndroidBlogs baiqiantao baiqiantao bqt20094 baiqiantao@sina ...
- Django 2.0 学习(16):Django ORM 数据库操作(下)
Django ORM数据库操作(下) 一.增加表记录 对于表单有两种方式: # 方式一:实例化对象就是一条表记录france_obj = models.Student(name="海地&qu ...
- Django 2.0 学习(14):Django ORM 数据库操作(上)
Django ORM 数据库操作(上) ORM介绍 映射关系: 数据库表名 ---------->类名:数据库字段 ---------->类属性:数据库表一行数据 ----------&g ...
- Django ORM 数据库增删改查
Django ORM 数据库增删改查 增 # 创建.增加数据(推荐) models.UserInfo.objects.create(username=') # 创建.增加数据 dic = {'} mo ...
- Django【第5篇】:Django之ORM数据库操作
django之ORM数据库操作 一.ORM介绍 映射关系: 表名 -------------------->类名 字段-------------------->属性 表记录-------- ...
随机推荐
- [转载]Java中继承、装饰者模式和代理模式的区别
[转载]Java中继承.装饰者模式和代理模式的区别 这是我在学Java Web时穿插学习Java设计模式的笔记 我就不转载原文了,直接指路好了: 装饰者模式和继承的区别: https://blog.c ...
- 线程池工具ThreadPoolExecutor
JDK1.5中引入了强大的concurrent包,其中最常用的莫过了线程池的实现ThreadPoolExecutor,它给我们带来了极大的方便,但同时,对于该线程池不恰当的设置也可能使其效率并不能达到 ...
- 你所不知道的 Console
1.凡人视角 打印字符串 代码: console.log("I am a 凡人"); 打印提示消息 代码: console.info("Yes, you arm a 凡人 ...
- shell 数组介绍
平时的定义a=1;b=2;c=3,变量如果多了,再一个一个定义很繁琐,并且取变量值也很累.简单的说,数组就是各种数据类型的元素按一定顺序排列的集合. 数组就是把有限个元素变量或数组用一个名字命名,然后 ...
- JS 详解 Cookie、 LocalStorage 与 SessionStorage-转载
记录一下这些知识,有时候用到会忘记,对原文作者表达感谢. 附上原文链接:JS 详解 Cookie. LocalStorage 与 SessionStorage 基本概念 Cookie Cookie 是 ...
- golang GC(二 定位)
前面已经介绍过golang的GC算法.要是我们的程序在运行是因为GC导致行能下降,该如何定位呢?说实话,工作中由于对go的gc问题不重视,根本没考虑过这个问题,今天特意来补补课.
- TCP/IP网络
1. 简述osi七层模型和TCP/IP五层模型 一.OSI参考模型 今天我们先学习一下以太网最基本也是重要的知识——OSI参考模型. 1.OSI的来源 OSI(Op ...
- 3.Vue过滤器
1.概念: Vue.js 允许你自定义过滤器,可被用作一些常见文本的格式化,过滤器可以用在两个地方:mustache 插值和 v-bind 表达式.过滤器应该被添加在 JavaScript 表达式的尾 ...
- Til the Cows Come Home(Dijkstra)
Dijkstra (迪杰斯特拉)最短路算法,算是模板 POJ - 2387 #include<iostream> #include<algorithm> #include< ...
- mysql查询表中最后一条记录
查询全部的记录: select * from test_limit ; 查第一条记录: select * from test_limit limit 1; ...