python (2)xpath与定向爬虫
内容来自:极客学院,教学视频;
写在前面:
提取Item
选择器介绍
我们有很多方法从网站中提取数据。Scrapy 使用一种叫做 XPath selectors的机制,它基于 XPath表达式。
这是一些XPath表达式的例子和他们的含义
- /html/head/title: 选择HTML文档<head>元素下面的<title> 标签。
- /html/head/title/text(): 选择前面提到的<title> 元素下面的文本内容
- //td: 选择所有 <td> 元素
- //div[@class="mine"]: 选择所有包含 class="mine" 属性的div 标签元素
这只是几个使用XPath的简单例子,但是实际上XPath非常强大。
为了方便使用XPaths,Scrapy提供XPathSelector 类, 有两种口味可以选择, HtmlXPathSelector
(HTML数据解析) 和XmlXPathSelector (XML数据解析)。 为了使用他们你必须通过一个 Response
对象对他们进行实例化操作。你会发现Selector对象展示了文档的节点结构。因此,第一个实例化的selector必与根节点或者是整个目录有关
。
Selectors 有三种方法
- select():返回selectors列表, 每一个select表示一个xpath参数表达式选择的节点.
- extract():返回一个unicode字符串,该字符串为XPath选择器返回的数据
- re(): 返回unicode字符串列表,字符串作为参数由正则表达式提取出来
一.xpath与定向爬虫
知识点:(话说秒杀 正则表达式啊)
// 定位根节点
/往下层寻找
/text()获取标签中的内容
/@xxxx提取属性的内容
#-*-coding:utf8-*-
from lxml import etree
html = '''
<!DOCTYPE html>
<html>
<head lang="en">
<meta charset="UTF-8">
<title>测试-常规用法</title>
</head>
<body>
<div id="content">
<ul id="useful">
<li>这是第一条信息</li>
<li>这是第二条信息</li>
<li>这是第三条信息</li>
</ul>
<ul id="useless">
<li>不需要的信息1</li>
<li>不需要的信息2</li>
<li>不需要的信息3</li>
</ul> <div id="url">
<a href="http://jikexueyuan.com">极客学院</a>
<a href="http://jikexueyuan.com/course/" title="极客学院课程库">点我打开课程库</a>
</div>
</div> </body>
</html>
''' selector = etree.HTML(html) #提取文本
content = selector.xpath('//ul[@id="useful"]/li/text()')#提取li标签里的内容
for each in content:
print each #提取属性
link = selector.xpath('//a/@href')#提取标签里面的链接
for each in link:
print each title = selector.xpath('//a/@title')
print title[0]
运行结果:
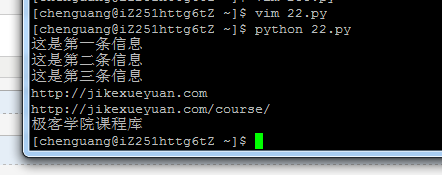
二. xpath的特殊用法
例如:1. start-with(@属性名称,属性地址相同的部分)
2.string(.)
#-*-coding:utf8-*-
from lxml import etree html1 = '''
<!DOCTYPE html>
<html>
<head lang="en">
<meta charset="UTF-8">
<title></title>
</head>
<body>
<div id="test-1">需要的内容1</div>
<div id="test-2">需要的内容2</div>
<div id="testfault">需要的内容3</div>
</body>
</html>
''' html2 = '''
<!DOCTYPE html>
<html>
<head lang="en">
<meta charset="UTF-8">
<title></title>
</head>
<body>
<div id="test3">
我左青龙,
<span id="tiger">
右白虎,
<ul>上朱雀,
<li>下玄武。</li>
</ul>
老牛在当中,
</span>
龙头在胸口。
</div>
</body>
</html>
''' selector = etree.HTML(html1)
content = selector.xpath('//div[starts-with(@id,"test")]/text()')
for each in content:
print each selector = etree.HTML(html2)
content_1 = selector.xpath('//div[@id="test3"]/text()')
for each in content_1:
print each data = selector.xpath('//div[@id="test3"]')[0]
info = data.xpath('string(.)')
content_2 = info.replace('\n','').replace(' ','')
print content_2
运行结果:

三:实战演练 百度贴吧
#-*-coding:utf8-*-
from lxml import etree
from multiprocessing.dummy import Pool as ThreadPool
import requests
import json
import sys reload(sys) sys.setdefaultencoding('utf-8') '''重新运行之前请删除content.txt,因为文件操作使用追加方式,会导致内容太多。''' def towrite(contentdict):
f.writelines(u'回帖时间:' + str(contentdict['topic_reply_time']) + '\n')
f.writelines(u'回帖内容:' + unicode(contentdict['topic_reply_content']) + '\n')
f.writelines(u'回帖人:' + contentdict['user_name'] + '\n\n') def spider(url):
html = requests.get(url)
selector = etree.HTML(html.text)
content_field = selector.xpath('//div[@class="l_post l_post_bright "]')
item = {}
for each in content_field:
reply_info = json.loads(each.xpath('@data-field')[0].replace('"',''))
author = reply_info['author']['user_name']
content = each.xpath('div[@class="d_post_content_main"]/div/cc/div[@class="d_post_content j_d_post_content "]/text()')[0]
reply_time = reply_info['content']['date']
print content
print reply_time
print author
item['user_name'] = author
item['topic_reply_content'] = content
item['topic_reply_time'] = reply_time
towrite(item) if __name__ == '__main__':
pool = ThreadPool(4)
f = open('content.txt','a')
page = []
for i in range(1,21):
newpage = 'http://tieba.baidu.com/p/3522395718?pn=' + str(i)
page.append(newpage) results = pool.map(spider, page)
pool.close()
pool.join()
f.close()
python (2)xpath与定向爬虫的更多相关文章
- Python 中国大学排名定向爬虫
代码来自于中国大学Mooc北京理工大学Pythont教学团队:https://www.icourse163.org/learn/BIT-1001870001#/learn/content?type=d ...
- Python淘宝商品比价定向爬虫
1.项目基本信息 目标: 获取淘宝搜索页面的信息,提取其中的商品名称和价格理解: 淘宝的搜索接口.翻页的处理 很多人学习python,不知道从何学起.很多人学习python,掌握了基本语法过后,不知道 ...
- 定向爬虫 - Python模拟新浪微博登录
当我们试图从新浪微博抓取数据时,我们会发现网页上提示未登录,无法查看其他用户的信息. 模拟登录是定向爬虫制作中一个必须克服的问题,只有这样才能爬取到更多的内容. 实现微博登录的方法有很多,一般我们在模 ...
- Python定向爬虫实战
转载请注明原文地址:http://www.cnblogs.com/ygj0930/p/7019963.html 一:requests模块介绍 requests是第三方http库,可以十分方便地实现py ...
- 放养的小爬虫--京东定向爬虫(AJAX获取价格数据)
放养的小爬虫--京东定向爬虫(AJAX获取价格数据) 笔者声明:只用于学习交流,不用于其他途径.源代码已上传github.githu地址:https://github.com/Erma-Wang/Sp ...
- python beautifulsoup/xpath/re详解
自己在看python处理数据的方法,发现一篇介绍比较详细的文章 转自:http://blog.csdn.net/lingojames/article/details/72835972 20170531 ...
- python Cmd实例之网络爬虫应用
python Cmd实例之网络爬虫应用 标签(空格分隔): python Cmd 爬虫 废话少说,直接上代码 # encoding=utf-8 import os import multiproces ...
- 使用python做最简单的爬虫
使用python做最简单的爬虫 --之心 #第一种方法import urllib2 #将urllib2库引用进来response=urllib2.urlopen("http://www.ba ...
- Python之定向爬虫Scrapy
1.Scrapy介绍 Scrapy,Python开发的一个快速,高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据.Scrapy用途广泛,可以用于数据挖掘.监测和自动化测试 ...
随机推荐
- knockoutJs基础1 - 简单的knockoutjs实现
简单的knockoutjs实现 1.knockoutJs是在MVVM的机制下实现的,所以要有view(HTML页面中的DOM标签)和viewModel(JavaScript中的js代码). 2.在vi ...
- spring源码学习之:xml配置文件标签自定义
Spring框架从2.0版本开始,提供了基于Schema风格的XML扩展机制,允许开发者扩展最基本的spring配置文件(一 般是classpath下的spring.xml).试想一下,如果我们直接在 ...
- java多线程之:深入JVM锁机制2-Lock (转载)
前文(深入JVM锁机制-synchronized)分析了JVM中的synchronized实现,本文继续分析JVM中的另一种锁Lock的实现.与synchronized不同的是,Lock完全用Java ...
- 学习smali
添加控件id 在R$id.smali文件下添加: .field public static final adposition:I = 0x7f05003d 添加类中常量 MainActivity.sm ...
- myBatis 参数配置
关于参数的类型 有四种类型: http://www.07net01.com/zhishi/402787.html 以上链接有所介绍,四种类型有:单个参数.多个参数.Map封装参数.List封装IN 如 ...
- EDIUS和VEGAS哪个更好用
随着数字化电视系统发展的步伐日趋加快,计算机技术逐步渗透到广播电视的各个领域,非线性编辑系统在广播电视行业内占据越来越重要的地位,而且正向多样化 发展.因此,非线性编辑技术的操作应用对于编辑人员有着非 ...
- 2的N次方 【转】
题目的链接为:http://acm.njupt.edu.cn/acmhome/problemdetail.do?&method=showdetail&id=1009 题目为: 2的N次 ...
- linux -samba
yum install samba samba-client samba-swat samba-common-3.6.9-151.el6.x86_64 //主要提供samba服务器的设置文件与设置文件 ...
- (四)文本编辑器Vim/Vi
目录 前言 常用命令 扩展应用 总结 本系列先前的随笔位于新浪博客 前言 Vi和Vim都是文本编辑器,不同的是Vim是Vi的升级版本,它不仅兼容Vi的所有指令,而且还有一些新的特性在里面. Vim/V ...
- C#基础——Func和Action的介绍及其用法
Func是一种委托,这是在3.5里面新增的,2.0里面我们使用委托是用Delegate,Func位于System.Core命名空间下,使用委托可以提升效率,例如在反射中使用就可以弥补反射所损失的性能. ...