Storm实时计算框架的编程模式
storm分布式流式计算框架。
nimbus:主进程服务(职责就是任务的分配的,程序的分发)
supervisor:工作进程服务(职责就是启动线程池,接受任务,运行任务,报告任务的运行状态)
注意容错:supervisor与nimbus都是基于zookeeper来实现容错,任务运行的元数据存储的zk里面,如果工作节点宕机,zk可以发现,执行触发机制,通知nimbus,对任务进行重新的分发。
===================================================================================
1.Bolt任务crash引起的消息未被应答。此时,acker中所有与此Bolt任务关联的消息都会因为超时而失败,对应的Spout的fail方法将被调用
2.acker任务失败。如果acker任务本身失败了,它在失败之前持有的所有消息都将超时而失败。Spout的fail方法将被调用
3.Spout任务失败。在情况下,与Spout任务对接的外部设备(如MQ)负责消息的完整性。例如,当客户端异常时,kestrel队列会将处于pending状态的所有消息重新放回队列中
任务槽(slot)故障
Worker失败。每个Worker中包含数个Bolt(或Spout)任务。Supervisor负责监控这些任务,当worker失败后会尝试在本机重启它,如果它在启动时连续失败了一定的次数,无法发送心跳信息到Nimbus,Nimbus将在另一台主机上重新分配worker
Supervisor失败。Supervisor是无状态(所有的状态都保存在Zookeeper或者磁盘上)和快速失败(每当遇到任何意外的情况,进程自动毁灭)的,因此Supervisor的失败不会影响当前正在运行的任务,只要及时将他们重新启动即可。
Nimbus失败。Nimbus也是无状态和快速失败的,因此Nimbus的失败不会影响当前正在运行的任务,但是当Nimbus失败时,无法提交新的任务,只要及时将它重新启动即可。
为了管理Spout的可靠性,可以在发射元组的时候,在元组里面包含一个消息ID
===================================================================================
下面看一下提供的编程模型
===================================
实现IRichSpout接口(BaseRichSpout),表示此处就是数据的源(1.设置数据格式-字段,2.初始化业务对象,3.处理完数据之后发送数据到下游) []
@Override
public void declareOutputFields(OutputFieldsDeclarer arg0) {
//设置输出的数据格式字段
} @Override
public void open(Map arg0, TopologyContext arg1,SpoutOutputCollector arg2) {
//首先获取到SpoutOutputCollector
//初始化相关的参数数据
} @Override
public void nextTuple() {
//开始处理数据
}
实现IRichBolt接口(BaseBasicBolt ),表示对数据的处理逻辑接口(初始化对象,处理数据,发送到下游继续处理)
@Override
public void prepare(Map arg0, TopologyContext arg1, OutputCollector arg2) {
//初始化相关的参数对象OutputCollector
} @Override
public void declareOutputFields(OutputFieldsDeclarer arg0) {
//声明处理输出的字段数据
} @Override
public void execute(Tuple arg0) {
//处理业务数据接口
}
组装通过Topology实现,设置spout,bolt的pie流程关系,设置任务的名称以及并行度等参数,此类里面有个main函数就是执行的入口函数。
==================================================================================================
storm的操作算子:
Tident提供了 joins, aggregations, grouping, functions, 以及 filters等能力,所以使用它既可以完成聚合计算,连接计算,我们可以把它嵌入到blot里面,所以blot是处理逻辑,而Tident主要的作用就是提聚合操作的算子。
Trident的topology会被编译成尽可能高效的Storm topology。只有在需要对数据进行repartition的时候(如groupby或者shuffle)才会把tuple通过network发送出去,如果你有一个trident如下
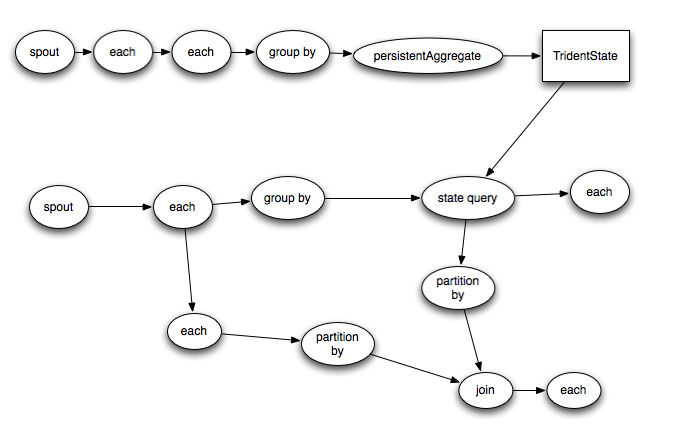

上图就是编译前与编译之后的运行图,也就是说,为了可以并发执行,尽量保证本地计算,编写生成新的拓扑运行。而需要网络传输的数据则进行shuffle操作(网络传输数据)。
Storm实时计算框架的编程模式的更多相关文章
- Storm实时计算:流操作入门编程实践
转自:http://shiyanjun.cn/archives/977.html Storm实时计算:流操作入门编程实践 Storm是一个分布式是实时计算系统,它设计了一种对流和计算的抽象,概念比 ...
- 实时计算框架:Flink集群搭建与运行机制
一.Flink概述 1.基础简介 Flink是一个框架和分布式处理引擎,用于对无界和有界数据流进行有状态计算.Flink被设计在所有常见的集群环境中运行,以内存执行速度和任意规模来执行计算.主要特性包 ...
- Spark Streaming实时计算框架介绍
随着大数据的发展,人们对大数据的处理要求也越来越高,原有的批处理框架MapReduce适合离线计算,却无法满足实时性要求较高的业务,如实时推荐.用户行为分析等. Spark Streaming是建立在 ...
- 大数据笔记(二十二)——大数据实时计算框架Storm
一. 1.对比:离线计算和实时计算 离线计算:MapReduce,批量处理(Sqoop-->HDFS--> MR ---> HDFS) 实时计算:Storm和Spark Sparki ...
- 可以穿梭时空的实时计算框架——Flink对时间的处理
Flink对于流处理架构的意义十分重要,Kafka让消息具有了持久化的能力,而处理数据,甚至穿越时间的能力都要靠Flink来完成. 在Streaming-大数据的未来一文中我们知道,对于流式处理最重要 ...
- storm实时计算实例(socket实时接入)
介绍 实现了一个简单的从实时日志文件监听,写入socket服务器,再接入Storm计算的一个流程. 源码 日志监听实时写入socket服务器 package socket; import java ...
- 大数据“重磅炸弹”——实时计算框架 Flink
Flink 学习 项目地址:https://github.com/zhisheng17/flink-learning/ 博客:http://www.54tianzhisheng.cn/tags/Fli ...
- [开源]CSharpFlink(NET 5.0开发)分布式实时计算框架,PC机10万数据点秒级计算测试说明
github地址:https://github.com/wxzz/CSharpFlinkgitee地址:https://gitee.com/wxzz/CSharpFlink 1 计算 ...
- 实时计算框架:Spark集群搭建与入门案例
一.Spark概述 1.Spark简介 Spark是专为大规模数据处理而设计的,基于内存快速通用,可扩展的集群计算引擎,实现了高效的DAG执行引擎,可以通过基于内存来高效处理数据流,运算速度相比于Ma ...
随机推荐
- C99新特性:变长数组(VLA)
C99标准引入了变长数组,它允许使用变量定义数组各维.例如您可以使用下面的声明: ; ; double sales[rows][cols]; // 一个变长数组(VLA) 变长数组有一些限制,它必须是 ...
- hadoop(四): 本地 hbase 集群配置 Azure Blob Storage
基于 HDP2.4安装(五):集群及组件安装 创建的hadoop集群,修改默认配置,将hbase 存储配置为 Azure Blob Storage 目录: 简述 配置 验证 FAQ 简述: hadoo ...
- MongoDB备份与导入
导出mongodb的数据 mongodump -d nodes -o url 导入mongodb数据mongorestore --db nodes url 删除mongodb的数据库db.dropDa ...
- js 删除DropDownList的选项
function del_DropDownList_Option() { var ddlXZ= document.getElementById("name&quo ...
- Hibernate3回顾-1-部署
web备份版本,详见doc版本. 一.背景(部署简单回顾) 我们知道,一个Hibernate快速上手的简单流程是这样. 1引入对应jar包. 中间涉及log4的jar包和配置,略. 2 实体类 pac ...
- EnterpriseLibrary之Caching应用
http://blog.csdn.net/linux7985/article/details/6239433 http://cache.baiducontent.com/c?m=9f65cb4a8c8 ...
- vs 添加坚竖虚线(垂直虚线、肾虚线 by 我的Y韬)
Indent Guides https://visualstudiogallery.msdn.microsoft.com/e792686d-542b-474a-8c55-630980e72c30 vs ...
- 一个 IT 青年北漂四年的感悟
转载自:http://www.codeceo.com/article/it-man-beijing-4-years.html 工作这几年,每年都会有朋友离开北京,每次朋友跟我告别的时候总是让我有很多感 ...
- 【mongodb系统学习之十二】mongodb修改数据(一)
十二.mongodb修改数据:update 1).修改数据库数据:update:语法 db.collectionName.update({},{},boolean,boolean): 2).updat ...
- onNewIntent调用时机
在IntentActivity中重写下列方法:onCreate onStart onRestart onResume onPause onStop onDestroy onNewIntent 一 ...