verilog实现的16位CPU单周期设计
verilog实现的16位CPU单周期设计
这个工程完成了16位CPU的单周期设计,模块化设计,包含对于关键指令的仿真与设计,有包含必要的分析说明。
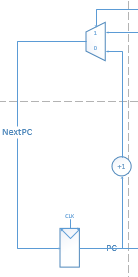
单周期CPU结构图
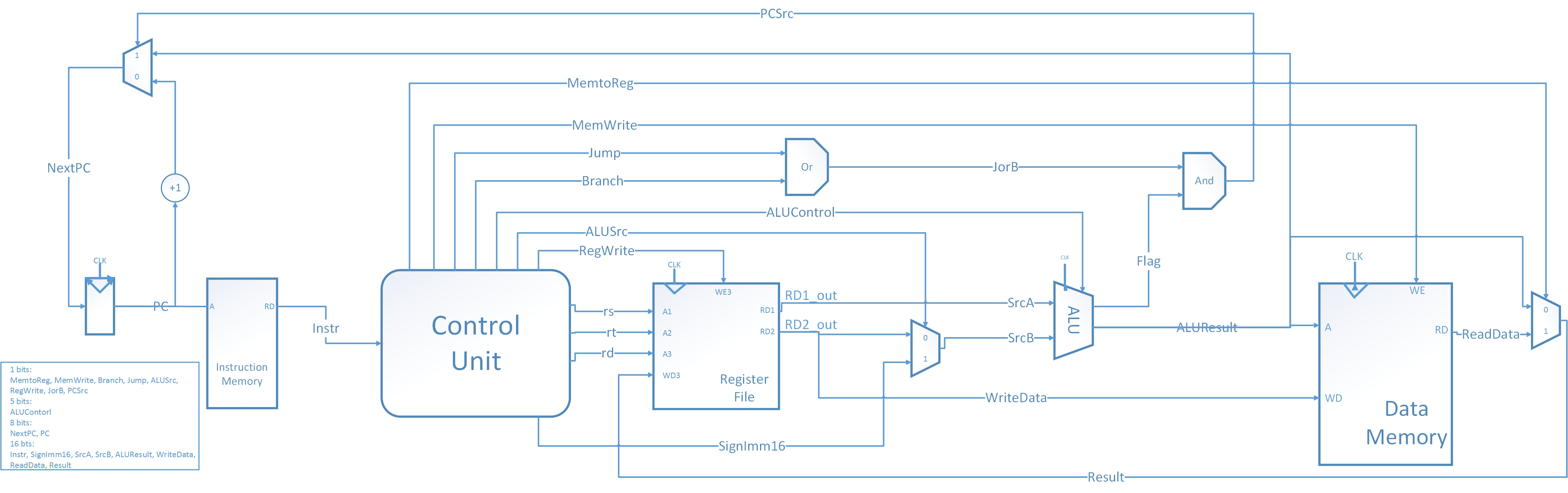
单周期CPU设计真值表与结构图
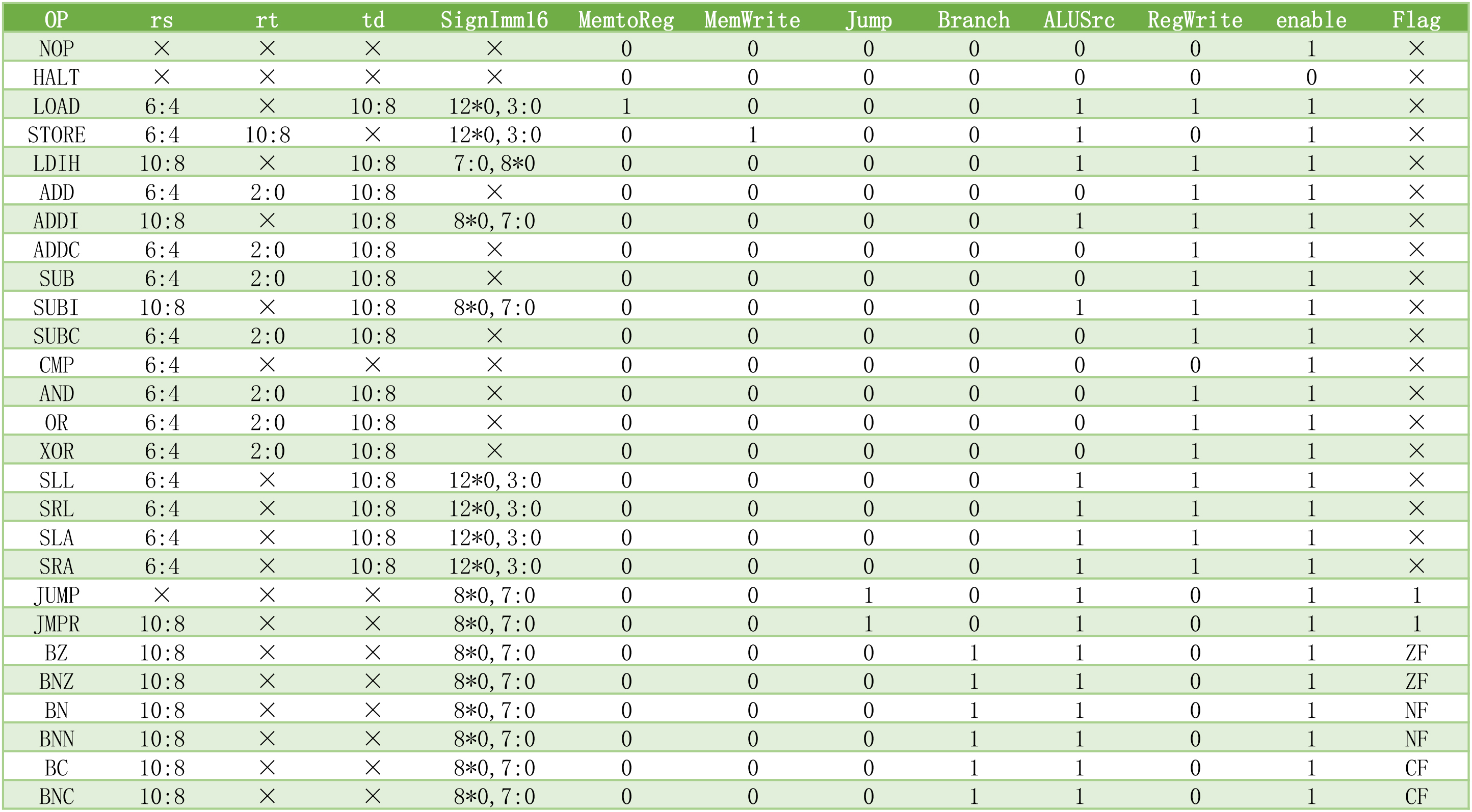
该CPU用到的指令集,16位8个通用寄存器
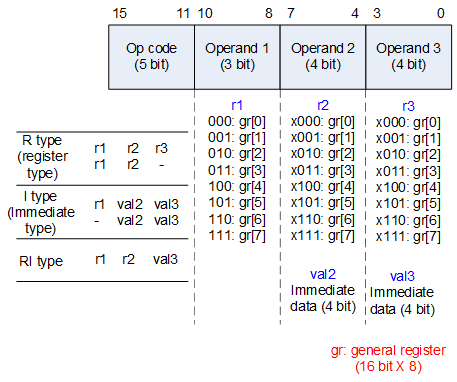
设计思路
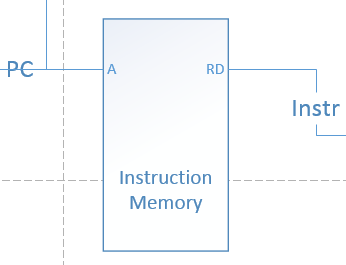
Instruction Memory:
输入8位的PC指令,输出对应内存的16位指令
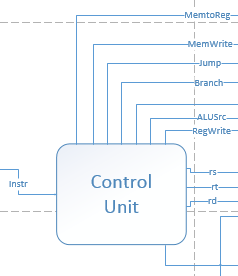
Control Unit
输入16位的指令,根据真值表,输出对应结果
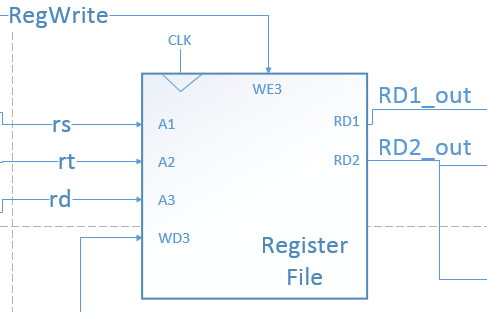
Register File
输入三个地址和写入内容,写入信号,输出两个地址对应的内容
由于单周期内不能一边读一边写,故有一个时钟信号,通过一级缓存,在下一个时钟信号来临时立即写入内存
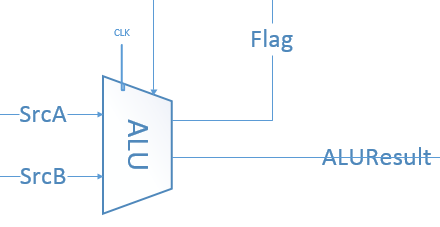
ALU
输入运算数和指令,输出运算结果以及标志位
由于单周期内,标志位并不在当前周期而在下一周期使用,故增加时钟信号,通过一级缓存,在下一个周期时判断使用
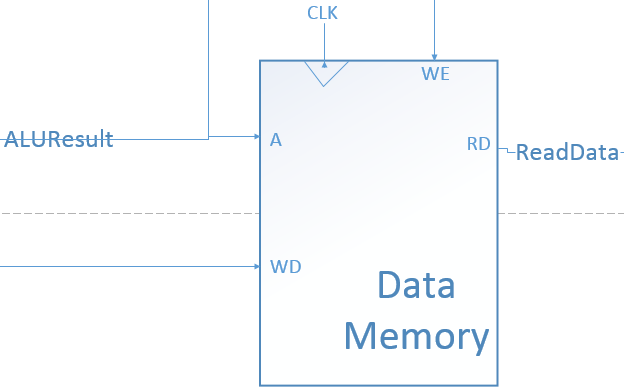
Data Memory
输入一个地址,写入内容和写入信号,输出读取内容
由于单周期内不能一边读一边写,故有一个时钟信号,通过一级缓存,在下一个时钟信号来临时立即写入内存
PC-NextPC
根据分支指令,跳转指令和标志位的组合逻辑,决定PC是+1还是到某目标位置
实验结果
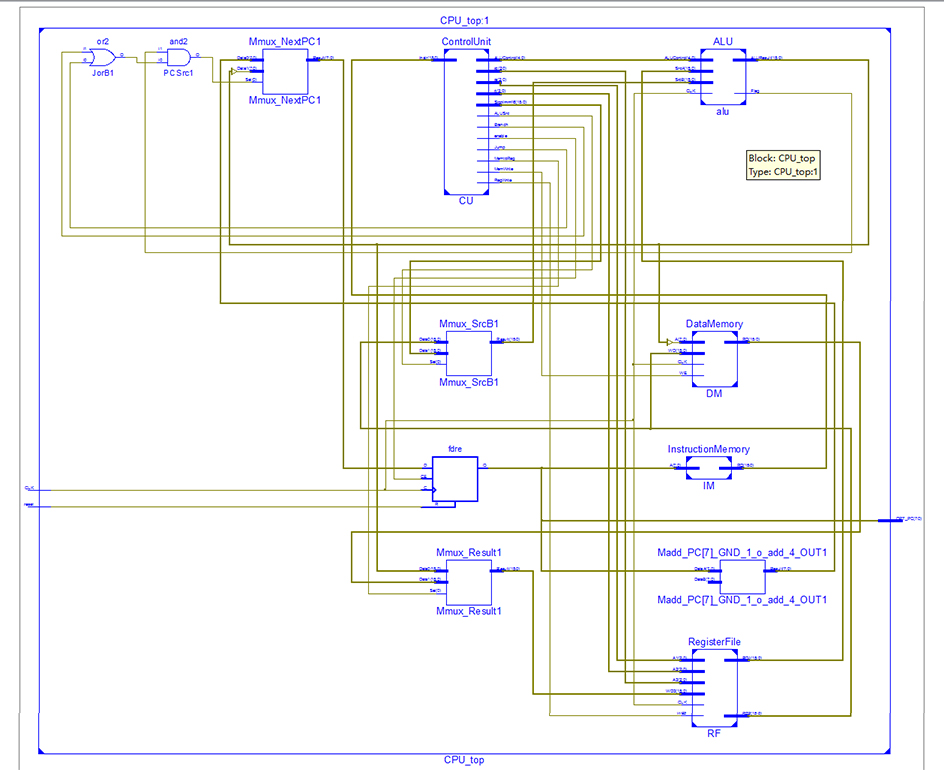
RTL图
Testbench内容
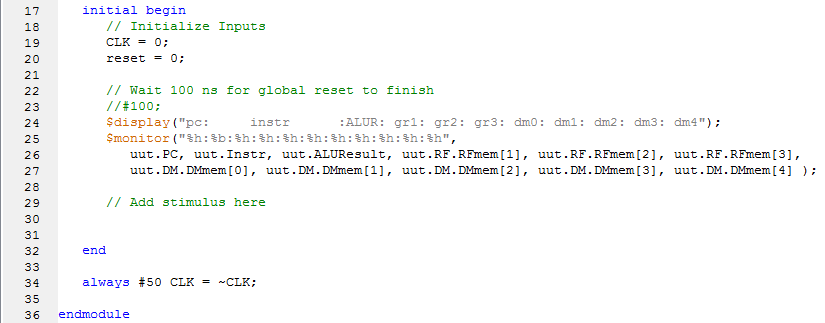
在test中,通过每隔50个ns,时钟取反一次,CPU通过一次时钟的上升沿计算一个周期,通过输出用到的通用寄存器和用到的datamemory里面的变量来观察整个CPU的流程结果,测试CPU是否正确工作
Instruction Memory:
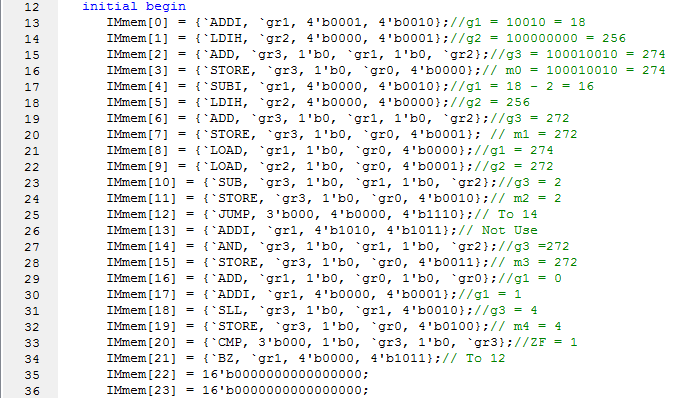
指令0:gr1原本初始化时为0,把gr1加上一个立即数18,gr1为18(0012)
指令1:gr2原本初始化时为0,把gr2加上一个高八位1,gr2为256(0100)
指令2:从gr1和gr2中取值相加,结果保存在gr3中,gr3应为274(0112)
指令3:把gr3的值保存到datamemory中的dm0,dm0为274(0112)
指令4:gr1的值为18,减去一个立即数2,gr1为16(0010)
指令5:gr2的值为256,加上一个高八位立即数0,结果不变为256(0100)
指令6:从gr1和gr2中取值相加,结果保存在gr3中,gr3应为272(0110)
指令7:把gr3的值保存到datamemory中的dm1,dm1为272(0110)
指令8:从dm0中取值到gr1中,gr1为274(0112)
指令9:从dm1中取值到gr2中,gr2为272(0110)
指令10:从gr1和gr2中取值相减,结果保存在gr3中,gr3应为2(0002)
指令11:把gr3的值保存到datamemory中的dm2,dm2为2(0002)
指令12:跳转指令,PC跳转到第14条指令
指令13:该指令不被执行,如gr1中出现274+171=445(01BD)则出错
指令14:从gr1和gr2中取值与操作,结果保存在gr3中,gr3应为272(0110)
指令15:把gr3的值保存到datamemory中的dm3,dm3为272(0110)
指令16:把gr1的值置为0
指令17:把gr1的值置为1
指令18:把gr1的值算术左移两位保存在gr3中,gr3为4
指令19:把gr3的值保存到datamemory中的dm4,dm4为4(0004)
指令20:把gr3和gr3相减让ZF标志位为1
指令21:因为ZF标志位为1,所以跳转到指令12,循环执行,如PC的值大于21,则出错
实验结果:

结果分析:
- 指令0~3,测试立即数加法和加法,计算18(0012)+256(0100)=274(0112),得到0112存储在dm0上。√
- 指令4~7,测试立即数减法和加法,计算18-2(0010)+256(0110)=272(0110),得到0110存储在dm1上。√
- 指令8~11,测试减法和读取写入,计算274(0112)-272(0110)=2(0002),得到0002存储在dm2上。√
- 指令12~15,测试跳转指令和位操作指令,PC值从0c跳转到0e把274(100010010)和272(100010000)与操作得到272(1000100010)[0110]存储在dm3上。√
- 指令16~19,测试移位指令,将1(0001)左移2位得到4(0004)存储在dm4上。√
- 指令20~21,测试分支指令,cmp指令让两个相同的数相减,bz指令跳转,PC在15->0c->…->15->0c之间循环执行。√
各类指令均取很具有代表性的指令,也测试了较难的指令,结果和预期结果相符。
完整代码
CPU_top.v
`timescale 1ns / 1ps
module CPU_top(
input CLK,
input reset,
output [7:0] OPT_PC
);
reg [7:0] PC;
wire [15:0] Instr;
wire [2:0] rs;
wire [2:0] rt;
wire [2:0] rd;
wire [15:0] SignImm16;
wire MemtoReg, MemWrite, Branch, ALUSrc, RegWrite, Jump;
wire [4:0] ALUControl;
wire JorB, PCSrc, Flag;
wire [15:0] RD1_out;
wire [15:0] RD2_out;
wire [15:0] SrcA;
wire [15:0] SrcB;
wire [15:0] ALUResult;
wire [15:0] WriteData;
wire [15:0] ReadData;
wire [15:0] Result;
wire [7:0] NextPC;
wire enable;
initial begin
PC = 8'b00000000;
end
InstructionMemory IM(
.A(PC),
.RD(Instr)
);
ControlUnit CU(
.Instr(Instr),
.MemtoReg(MemtoReg),
.MemWrite(MemWrite),
.Branch(Branch),
.ALUControl(ALUControl),
.ALUSrc(ALUSrc),
.RegWrite(RegWrite),
.Jump(Jump),
.enable(enable),
.rs(rs),
.rt(rt),
.rd(rd),
.SignImm16(SignImm16)
);
RegisterFile RF(
.CLK(CLK),
.A1(rs),
.A2(rt),
.A3(rd),
.WD3(Result),
.WE3(RegWrite),
.RD1(RD1_out),
.RD2(RD2_out)
);
assign SrcA = RD1_out;
assign SrcB = (ALUSrc) ? SignImm16 : RD2_out;
ALU alu(
.CLK(CLK),
.ALUControl(ALUControl),
.SrcA(SrcA),
.SrcB(SrcB),
.ALUResult(ALUResult),
.Flag(Flag)
);
assign WriteData = RD2_out;
DataMemory DM(
.CLK(CLK),
.WE(MemWrite),
.A(ALUResult),
.WD(WriteData),
.RD(ReadData)
);
assign Result = (MemtoReg) ? ReadData : ALUResult;
assign JorB = ( Jump | Branch );//Jump or Branch,判断当前指令是否需要跳转
assign PCSrc = ( JorB & Flag );//加上Flag判断跳转是否成立
assign NextPC = (PCSrc) ? ALUResult[7:0] : (PC + 1'b1);//跳转成立则NextPC为新值,否则加1
always@(posedge CLK)//时序,每个周期PC值变化一次
begin
if(reset)
PC <= 0;
else
begin
if(enable)
PC <= NextPC;
else
PC <= PC;
end
end
assign OPT_PC = PC;
endmodule
ControlUnit.v
`timescale 1ns / 1ps
`include"headfile.v"
module ControlUnit(
input [15:0] Instr,
output MemtoReg,
output MemWrite,
output reg Branch,
output [4:0] ALUControl,
output reg ALUSrc,
output reg RegWrite,
output Jump,
output enable,
output reg [2:0] rs,
output reg [2:0] rt,
output [2:0] rd,
output reg [15:0] SignImm16
);
wire [4:0] Op;
assign Op = Instr[15:11];//指令高5位是Op
//Set A1(rs) 根据真值表设置A1的取值位置
always@(*)
begin
if((Op == `BZ)
||(Op == `BN)
||(Op == `JMPR)
||(Op == `BC)
||(Op == `BNZ)
||(Op == `BNN)
||(Op == `BNC)
||(Op == `ADDI)
||(Op == `SUBI)
||(Op == `LDIH))
rs <= Instr[10:8];
else
rs <= Instr[6:4];
end
//Set A2(rt) 根据真值表设置A2的取值位置
always@(*)
begin
if(Op == `STORE)
rt <= Instr[10:8];
else
rt <= Instr[2:0];
end
//Set A3(rd) 根据真值表设置A3的取值位置
assign rd = Instr[10:8];
//Set SignImm16 根据真值表设置立即数的取值位置
always@(*) //只要立即数存在,ALUSrc的选择即为立即数1
begin
if((Op == `LOAD)
||(Op == `STORE)
||(Op == `SLL)
||(Op == `SRL)
||(Op == `SLA)
||(Op == `SRA))
begin
SignImm16 <= { {12{1'b0}}, Instr[3:0]};
ALUSrc <= 1'b1;
end
else if((Op == `ADDI)
||(Op == `SUBI)
||(Op == `JUMP)
||(Op == `JMPR)
||(Op == `BZ)
||(Op == `BNZ)
||(Op == `BN)
||(Op == `BNN)
||(Op == `BC)
||(Op == `BNC))
begin
SignImm16 <= { {8{1'b0}}, Instr[7:0]};
ALUSrc <= 1'b1;
end
else if(Op == `LDIH)
begin
SignImm16 <= {Instr[7:0], {8{1'b0}}};
ALUSrc <= 1'b1;
end
else//其余情况,立即数为空值x,ALUSrc选择不为立即数
begin
SignImm16 <= { {16{1'bx}} };
ALUSrc <= 1'b0;
end
end
//ALUControl与Op一致
assign ALUControl = Op;
//MemtoReg当且仅当LOAD指令时为1
assign MemtoReg = (Op == `LOAD);
//MemWrite当且仅当STORE指令时为1
assign MemWrite = (Op == `STORE);
//Jump当指令为跳转类型时为1
assign Jump = ( (Op == `JUMP) || (Op == `JMPR));
//Set Branch 仅当分支指令时为1
always@(*)
begin
if((Op == `BZ)
||(Op == `BNZ)
||(Op == `BN)
||(Op == `BNN)
||(Op == `BC)
||(Op == `BNC))
Branch <= 1'b1;
else
Branch <= 1'b0;
end
//Set RegWrite 根据真值表设置RegWrite的取值
always@(*)
begin
if((Op == `LOAD)
||(Op == `LDIH)
||(Op == `ADD)
||(Op == `SUB)
||(Op == `ADDI)
||(Op == `SUBI)
||(Op == `ADDC)
||(Op == `SUBC)
||(Op == `AND)
||(Op == `OR)
||(Op == `XOR)
||(Op == `SLL)
||(Op == `SRL)
||(Op == `SLA)
||(Op == `SRA))
RegWrite <= 1'b1;
else
RegWrite <= 1'b0;
end
//遇到终止指令时,关闭CPU
assign enable = ~(Op == `HALT);
endmodule
InstructionMemory.v
`timescale 1ns / 1ps
`include"headfile.v"
module InstructionMemory(
input [7:0] A,
output [15:0] RD
);
reg [15:0] IMmem [29:0];
assign RD = IMmem[A];//立即根据地址取出内容
initial begin
IMmem[0] = {`ADDI, `gr1, 4'b0001, 4'b0010};//g1 = 10010 = 18
IMmem[1] = {`LDIH, `gr2, 4'b0000, 4'b0001};//g2 = 100000000 = 256
IMmem[2] = {`ADD, `gr3, 1'b0, `gr1, 1'b0, `gr2};//g3 = 100010010 = 274
IMmem[3] = {`STORE, `gr3, 1'b0, `gr0, 4'b0000};// m0 = 100010010 = 274
IMmem[4] = {`SUBI, `gr1, 4'b0000, 4'b0010};//g1 = 18 - 2 = 16
IMmem[5] = {`LDIH, `gr2, 4'b0000, 4'b0000};//g2 = 256
IMmem[6] = {`ADD, `gr3, 1'b0, `gr1, 1'b0, `gr2};//g3 = 272
IMmem[7] = {`STORE, `gr3, 1'b0, `gr0, 4'b0001}; // m1 = 272
IMmem[8] = {`LOAD, `gr1, 1'b0, `gr0, 4'b0000};//g1 = 274
IMmem[9] = {`LOAD, `gr2, 1'b0, `gr0, 4'b0001};//g2 = 272
IMmem[10] = {`SUB, `gr3, 1'b0, `gr1, 1'b0, `gr2};//g3 = 2
IMmem[11] = {`STORE, `gr3, 1'b0, `gr0, 4'b0010};// m2 = 2
IMmem[12] = {`JUMP, 3'b000, 4'b0000, 4'b1110};// To 14
IMmem[13] = {`ADDI, `gr1, 4'b1010, 4'b1011};// Not Use
IMmem[14] = {`AND, `gr3, 1'b0, `gr1, 1'b0, `gr2};//g3 =272
IMmem[15] = {`STORE, `gr3, 1'b0, `gr0, 4'b0011};// m3 = 272
IMmem[16] = {`ADD, `gr1, 1'b0, `gr0, 1'b0, `gr0};//g1 = 0
IMmem[17] = {`ADDI, `gr1, 4'b0000, 4'b0001};//g1 = 1
IMmem[18] = {`SLL, `gr3, 1'b0, `gr1, 4'b0010};//g3 = 4
IMmem[19] = {`STORE, `gr3, 1'b0, `gr0, 4'b0100};// m4 = 4
IMmem[20] = {`CMP, 3'b000, 1'b0, `gr3, 1'b0, `gr3};//ZF = 1
IMmem[21] = {`BZ, `gr1, 4'b0000, 4'b1011};// To 12
IMmem[22] = 16'b0000000000000000;
IMmem[23] = 16'b0000000000000000;
IMmem[24] = 16'b0000000000000000;
IMmem[25] = 16'b0000000000000000;
IMmem[26] = 16'b0000000000000000;
IMmem[27] = 16'b0000000000000000;
IMmem[28] = 16'b0000000000000000;
IMmem[29] = 16'b0000000000000000;
end
endmodule
RegisterFile.v
`timescale 1ns / 1ps
module RegisterFile(
input CLK,
input [2:0] A1,
input [2:0] A2,
input [2:0] A3,
input [15:0] WD3,
input WE3,
output [15:0] RD1,
output [15:0] RD2
);
reg [15:0] RFmem [7:0];
reg reallWE3; reg [2:0] reallA3; reg [15:0] reallWD3;
initial begin//初始化8个通用寄存器为0
reallWE3 = 1'b0;
RFmem[0] = 16'h0000000000000000;
RFmem[1] = 16'h0000000000000000;
RFmem[2] = 16'h0000000000000000;
RFmem[3] = 16'h0000000000000000;
RFmem[4] = 16'h0000000000000000;
RFmem[5] = 16'h0000000000000000;
RFmem[6] = 16'h0000000000000000;
RFmem[7] = 16'h0000000000000000;
end
//避免对一个寄存器同时读写,一级缓存处理
always@(posedge CLK)
begin
reallWE3 <= WE3;
reallA3 <= A3;
reallWD3 <= WD3;
end
//有写入内容时直接写入到指定位置
always@(*)
begin
if(reallWE3)
RFmem[reallA3] <= reallWD3;
end
//根据地址直接从寄存器取值
assign RD1 = RFmem[A1];
assign RD2 = RFmem[A2];
endmodule
SignExtend.v
`timescale 1ns / 1ps
module SignExtend(
input [7:0] SignImm8,
output [15:0] SignImm16
);
assign SignImm16 = {{8{SignImm8[7]}}, SignImm8};
endmodule
ALU.v
`timescale 1ns / 1ps
`include"headfile.v"
module ALU(
input CLK,
input [4:0] ALUControl,
input [15:0] SrcA,
input [15:0] SrcB,
output reg [15:0] ALUResult,
output reg Flag
);
reg CF_temp;
wire ZF_temp, NF_temp;
reg ZF, CF, NF;
always@(*)//根据指令内容,对操作数进行不同的运算
begin
case(ALUControl)
`NOP: ALUResult <= ALUResult;
`HALT: ALUResult <= ALUResult;
`AND: ALUResult <= ( SrcA & SrcB );
`OR: ALUResult <= ( SrcA | SrcB );
`XOR: ALUResult <= ( SrcA ^ SrcB );
`SLL: ALUResult <= ( SrcA << SrcB );
`SRL: ALUResult <= ( SrcA >> SrcB );
`SLA: ALUResult <= ( SrcA <<< SrcB );
`SRA: ALUResult <= ( SrcA >>> SrcB );
`JUMP: ALUResult <= SrcB;//增加一位处理是否溢出设置CF
`LDIH: {CF_temp, ALUResult} <= {1'b0, SrcA} + {1'b0, SrcB};
`ADD: {CF_temp, ALUResult} <= {1'b0, SrcA} + {1'b0, SrcB};
`ADDI: {CF_temp, ALUResult} <= {1'b0, SrcA} + {1'b0, SrcB};
`ADDC: ALUResult <= ( SrcA + SrcB + CF_temp);
`SUB: ALUResult <= ( SrcA - SrcB );
`SUBI: ALUResult <= ( SrcA - SrcB );
`SUBC: ALUResult <= ( SrcA - SrcB - CF_temp);
`CMP: ALUResult <= ( SrcA - SrcB );
`LOAD: ALUResult <= ( SrcA + SrcB );
`STORE: ALUResult <= ( SrcA + SrcB );
`JMPR: ALUResult <= ( SrcA + SrcB );
`BZ: ALUResult <= ( SrcA + SrcB );
`BNZ: ALUResult <= ( SrcA + SrcB );
`BN: ALUResult <= ( SrcA + SrcB );
`BNN: ALUResult <= ( SrcA + SrcB );
`BC: ALUResult <= ( SrcA + SrcB );
`BNC: ALUResult <= ( SrcA + SrcB );
default: ALUResult <= ALUResult;
endcase
end
//结果为0时ZF标志位为1
assign ZF_temp = (ALUResult == 0);
//结果高位为1时ZF标志位为1
assign NF_temp = (ALUResult[15] == 1'b1);
//CF在运算时已处理
//assign CF_temp = CF_temp;
//增加一级缓存,为CMP的下一个周期使用
always@(posedge CLK)
begin
ZF <= ZF_temp;
CF <= CF_temp;
NF <= NF_temp;
end
//Set Flag 根据真值表设置
always@(*)
begin
case(ALUControl)
`JUMP: Flag <= 1'b1;//跳转指令恒为1
`JMPR: Flag <= 1'b1;
`BZ: Flag <= ZF;//根据ZF标志位
`BNZ: Flag <= ~ZF;
`BN: Flag <= NF;//根据NF标志位
`BNN: Flag <= ~NF;
`BC: Flag <= CF;//根据CF标志位
`BNC: Flag <= ~CF;
default: Flag <= 1'b0;//其余为0
endcase
end
endmodule
DataMemory.v
`timescale 1ns / 1ps
module DataMemory(
input CLK,
input WE,
input [7:0] A,
input [15:0] WD,
output [15:0] RD
);
reg [15:0] DMmem [29:0];
reg reallWE; reg [7:0] reallA; reg [15:0] reallWD;
initial begin//初始化时全为0
reallWE = 1'b0;
DMmem[0] = 16'b0000000000000000;
DMmem[1] = 16'b0000000000000000;
DMmem[2] = 16'b0000000000000000;
DMmem[3] = 16'b0000000000000000;
DMmem[4] = 16'b0000000000000000;
DMmem[5] = 16'b0000000000000000;
DMmem[6] = 16'b0000000000000000;
DMmem[7] = 16'b0000000000000000;
DMmem[8] = 16'b0000000000000000;
DMmem[9] = 16'b0000000000000000;
DMmem[10] = 16'b0000000000000000;
DMmem[11] = 16'b0000000000000000;
DMmem[12] = 16'b0000000000000000;
DMmem[13] = 16'b0000000000000000;
DMmem[14] = 16'b0000000000000000;
DMmem[15] = 16'b0000000000000000;
DMmem[16] = 16'b0000000000000000;
DMmem[17] = 16'b0000000000000000;
DMmem[18] = 16'b0000000000000000;
DMmem[19] = 16'b0000000000000000;
DMmem[20] = 16'b0000000000000000;
DMmem[21] = 16'b0000000000000000;
DMmem[22] = 16'b0000000000000000;
DMmem[23] = 16'b0000000000000000;
DMmem[24] = 16'b0000000000000000;
DMmem[25] = 16'b0000000000000000;
DMmem[26] = 16'b0000000000000000;
DMmem[27] = 16'b0000000000000000;
DMmem[28] = 16'b0000000000000000;
DMmem[29] = 16'b0000000000000000;
end
//增加一级缓存对应RegisterFile的读写处理
always@(posedge CLK)
begin
reallWE <= WE;
reallA <= A;
reallWD <= WD;
end
//根据写入地址直接写入
always@(*)
begin
if(reallWE)
DMmem[reallA] <= reallWD;
end
//根据地址直接读取
assign RD = DMmem[A];
endmodule
headfile.v
`ifndef HEADFILE_H_
//State for CPU
`define idle 1'b0
`define exec 1'b1
//Data transfer & Arithmetic
`define NOP 5'b00000
`define HALT 5'b00001
`define LOAD 5'b00010
`define STORE 5'b00011
`define LDIH 5'b10000
`define ADD 5'b01000
`define ADDI 5'b01001
`define ADDC 5'b10001
`define CMP 5'b01100
//Logical / shift
`define AND 5'b01101
`define SLL 5'b00100
`define SLA 5'b00101
//Control
`define JUMP 5'b11000
`define JMPR 5'b11001
`define BZ 5'b11010
`define BNZ 5'b11011
`define BN 5'b11100
`define BC 5'b11110
//Add by myself
`define SUB 5'b01010
`define SUBI 5'b01011
`define SUBC 5'b10010
`define OR 5'b01110
`define XOR 5'b01111
`define SRL 5'b00110
`define SRA 5'b00111
`define BNN 5'b11101
`define BNC 5'b11111
//gr
`define gr0 3'b000
`define gr1 3'b001
`define gr2 3'b010
`define gr3 3'b011
`endif
VTF_CPUtop.v
`timescale 1ns / 1ps
module VTF_CPUtop;
// Inputs
reg CLK;
reg reset;
reg [7:0] OPT_PC;
// Instantiate the Unit Under Test (UUT)
CPU_top uut (
.CLK(CLK),
.reset(reset),
.OPT_PC(OPT_PC)
);
initial begin
// Initialize Inputs
CLK = 0;
reset = 0;
// Wait 100 ns for global reset to finish
//#100;
$display("pc: instr :ALUR: gr1: gr2: gr3: dm0: dm1: dm2: dm3: dm4");
$monitor("%h:%b:%h:%h:%h:%h:%h:%h:%h:%h:%h",
uut.PC, uut.Instr, uut.ALUResult, uut.RF.RFmem[1], uut.RF.RFmem[2], uut.RF.RFmem[3],
uut.DM.DMmem[0], uut.DM.DMmem[1], uut.DM.DMmem[2], uut.DM.DMmem[3], uut.DM.DMmem[4] );
// Add stimulus here
end
always #50 CLK = ~CLK;
endmodule
后寄语:只有辛苦过,才有资格吐槽,才知道该如何去改进,才知道架构师与码农之间的区别。
verilog实现的16位CPU单周期设计的更多相关文章
- 16位CPU多周期设计
16位CPU多周期设计 这个工程完成了16位CPU的多周期设计,模块化设计,有包含必要的分析说明. 多周期CPU结构图 多周期CPU设计真值表 对应某一指令的情况,但仅当对应周期时才为对应的输出,不是 ...
- verilog实现的16位CPU设计
verilog实现的16位CPU设计 整体电路图 CPU状态图 idle代表没有工作,exec代表在工作 实验设计思路 五级流水线,增加硬件消耗换取时间的做法. 具体每一部分写什么将由代码部分指明. ...
- 16位cpu下主引导扇区及用户程序的编写
一些约定 主引导扇区代码(0面0道1扇区)加载至0x07c00处 用户程序头部代码需包含以下信息:程序总长度.程序入口.重定位表等信息 用户程序 当虚拟机启动时,在屏幕上显示以下两句话: This i ...
- 对所有CPU寄存器的简述(16位CPU14个,32位CPU16个)
32位CPU所含有的寄存器有:4个数据寄存器(EAX.EBX.ECX和EDX)2个变址和指针寄存器(ESI和EDI)2个指针寄存器(ESP和EBP)6个段寄存器(ES.CS.SS.DS.FS和GS)1 ...
- 16位/32位/64位CPU的位究竟是说啥
平时,我们谈论CPU,都会说某程序是32位编译,可以跑在32位机或64位机,或则是在下载某些开源包时,也分32位CPU版本或64CPU位版本,又或者在看计算机组成相关书籍时,特别时谈到X86 CPU时 ...
- 梦回----32位CPU和64位CPU的通用寄存器
1 32位Intel的CPU通用寄存器 32位CPU所含有的寄存器有:4个数据寄存器(EAX.EBX.ECX和EDX):2个变址和指针寄存器(ESI和EDI):2个指针寄存器(ESP和EBP):6个段 ...
- Intel X86 32位CPU内存管理----《Linux内核源码情景分析》笔记(一)
Intel X86 32位CPU内存管理 在X86系列中,8086和8088是16为处理器,而从80386开始为32为处理器,80286则是该系列从8088到80386,也就是16位处理器到32位处理 ...
- 通用32位CPU 常用寄存器及其作用
目录 32位CPU所含有的寄存器 数据寄存器 变址寄存器 指针寄存器 段寄存器 指令指针寄存器 标志寄存器 32位CPU所含有的寄存器 4个数据寄存器(EAX.EBX.ECX和EDX) 2个变址和指针 ...
- 使用Verilog搭建一个单周期CPU
使用Verilog搭建一个单周期CPU 搭建篇 总体结构 其实跟使用logisim搭建CPU基本一致,甚至更简单,因为完全可以照着logisim的电路图来写,各个模块和模块间的连接在logisim中非 ...
随机推荐
- 十六、Struts2文件上传与下载
文件上传与下载 1.文件上传前提:<form action="${pageContext.request.contextPath}/*" method="post& ...
- Rich控件二
Calendar控件 使用案例: 在Default.aspx中: <div> <h1>Calendar控件</h1> <asp:Calendar ID=&q ...
- MySQL的存储引擎整理
01.MyISAM MySQL 5.0 以前的默认存储引擎.MyISAM 不支持事务.也不支持外键,其优势是访问的速度快,对事务完整性没有要求或者以SELECT.INSERT 为主的应用基本上都可以使 ...
- MariaDB之基于Percona Xtrabackup备份大数据库[完整备份与增量备份]
MariaDB之基于Percona Xtrabackup备份大数据库[完整备份与增量备份] 1.Xtrabackup的安装 percona-xtrabackup-2.2.3-4982.el6.x86_ ...
- css3选择器 以及当天知道的东西
10.25日伪类:a:link{}未访问的链接 a:visited{}已访问的链接 a:hover{}鼠标移动到链接上 a:active{}选定的链接 注:a:hover ...
- 改变tabbar的高度做法
UITabBarController *tabBarController =[[UITabBarController alloc] init]; CGRect frame = self.window. ...
- redmine添加自定义属性
使用redmine创建问题的时候,可能会发现没有我们需要的属性,这时候我们可以添加自定义的属性. 以添加满意度属性为例: 1.进入redmine管理界面,选择自定义属性 2.选择问题下面的新建自定义属 ...
- C语言中的关键字
1.C语言中的关键字都有实际的意义. 2.C语言中的23个关键字如下: char:声明字符型变量. short:声明短整型变量. int:声明整型变量. long:声明长整型变量. float:声明浮 ...
- asp.net跨页面传值
a.aspx.cs //获取a中的id HttpCookie objCookie = new HttpCookie("myCookie", id); Response.Cookie ...
- Vue.js学习 Item9 – 表单控件绑定
基础用法 可以用 v-model 指令在表单控件元素上创建双向数据绑定.根据控件类型它自动选取正确的方法更新元素.尽管有点神奇,v-model 不过是语法糖,在用户输入事件中更新数据,以及特别处理一些 ...