Spring实战6:利用Spring和JDBC访问数据库
主要内容
- 定义Spring的数据访问支持
- 配置数据库资源
- 使用Spring提供的JDBC模板
写在前面:经过上一篇文章的学习,我们掌握了如何写web应用的控制器层,不过由于只定义了SpitterRepository和SpittleRepository接口,在本地启动该web服务的时候会遇到控制器无法注入对应的bean的错误,因此我决定跳过6~9章,先搞定数据库访问者一章。
在企业级应用开发中不可避免得会涉及到数据持久化层,在数据持久化层的开发过程中,可能遇到很多陷阱。你需要初始化数据库访问框架、打开数据库连接、处理各种异常,最后还要记得关闭连接。如果在这些步骤中你有一步做错了,那就又丢失公司数据的风险。妥当得处理这些并不容易,Spring提供了一套完整的数据库访问框架,用于简化各种数据库访问技术的使用。
在开发Spttr应用的持久层时,你需要在JDBC、Hibernate、Java Perssitence或者其他ORM框架等技术中进行选择。Spring扮演的角色是尽量消除你在使用这些技术时需要写的重复代码,以便开发人员专注于业务逻辑。
10.1 学习Spring的数据库访问哲学
Spring框架的目标之一就是让开发者面向接口编程,Spring的数据访问支持也不例外。
和很多其他应用一样,Spittr应用也需要从数据库中读取信息或者写入信息到数据库。为了避免持久化相关的代码遍布应用的各个地方,一般我们会将这些任务整合到一个模块中完成,这类模块通常被称之为数据访问对象(DAOs)或者repositories。
为了避免业务层模块强依赖于某种类型的数据库(关系型orNoSQL),数据库访问层应以接口形式对外提供服务。下图展示了这个思路:
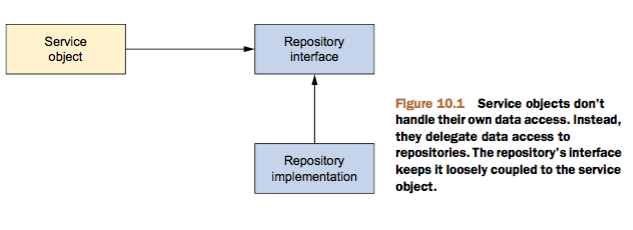
如你所见,service对象通过接口访问repository对象,这有很多好处:(1)因为service对象并不限制于某个特定的数据访问实现,这使得service对象便于测试;(2)你可以创建这些数据库访问接口的mock实现,这样即使没有建立数据库连接你也可以测试service对象;(3)可以显著加速单元测试的执行速度;(4)可以避免某个测试用例因数据不一致而失败。
数据访问层通过repository接口中的几个方法与service层沟通,这使得应用设计非常灵活,即使将来要更换数据库持久层框架,对应用的其他部分的影响也非常小。如果数据访问层的实现细节散步到应用的其他部分,则整个应用跟数据访问层紧密耦合在一起。
INTERFACES AND SPRING 如果你读完上面两段话之后能够感觉到我有很强的意愿将持久化层隐藏在接口之后,那说明我正确得表达了自己的想法。我相信接口是书写松耦合的代码的关键,不仅是数据库访问层,应该在应用的所有模块之间使用接口进行交互。虽然Spring并没有强制要求面向接口编程,但是Spring的设计思想鼓励面向接口编程——最好通过接口将一个bean装配到另一个bean的属性中。
Spring提供了方便的异常体系,也可以帮助开发者隔离数据库访问层与应用的其他模块。
10.1.1 了解Spring的数据访问的异常体系
在使用原始的JDBC接口时,如果你不捕获SQLException,就不能做任何事情。SQLException的意思是在尝试访问数据库过程中发生了某些错误,但是并没有提供足够的信息告诉开发人员具体的错误原因以及如何修正错误。
下列这些情况都可能引发SQLException:
- 连接数据库失败;
- 查询语句中存在语法错误;
- 查询中提到的表或者列不存在;
- 插入或者更新操作违背了数据库一致性;
关于SQLException最大的问题在于:当捕获它的时候应该如何处理。调查显示,很多引起SQLException的故障不能在catch代码块中修复。大部分被抛出的SQLException表示应用发生了致命故障。如果应用不能连接数据库,通常意味着应用不能继续执行;同样地,如果在查询语句中有错误,在运行时能做的工作也很少。
既然我们并不能做些操作来恢复SQLException,为什么必须捕获它?
即使你计划处理一些SQLException,你也必须捕获SQLException对象然后查看它的属性才能发掘出问题的本质。这是因为SQLException是一个代之所有数据库访问相关问题的异常,而不是针对每个可能的问题定义一个异常类型。
一些持久化框架提供了丰富的异常体系。例如,Hibernate提供了几乎两打不通的异常,每种代表一个特定的数据库访问问题。这令使用Hibernate的开发者可以为自己想处理的异常书写catch块。
即使这样,Hibernate的异常也只对Hibernate框架有用,如果你使用Hibernate自己的异常体系,就可能使程序的剩余部分强依赖于Hibernate,将来如果想升级为其他的持久化框架会非常麻烦。在这节开头的时候说过,我们希望隔离数据访问层和持久化机制的特性。如果在数据访问层处理Hibernate框架抛出的专属异常,则会影响到应用中的其余模块;如果不这么做,你必须捕获该持久化的专属异常,然后重新抛出一个平台无关的异常。
SPRING'S PERSISTENCE PLATFORM-AGNOSTIC EXCEPTION
一方面,JDBC提供的异常体系过于普遍——根本没有异常体系可言;另一方面,Hibernate的异常体系是针对这个框架自己的,因此我们需要一套数据库访问的异常体系,既具备足够强的描述能力,又不要跟具体的持久化框架直接关联。
Spring JDBC提供的异常体系同时满足上述两个条件。不同于传统的JDBC,Spring JDBC针对某些具体的问题定义了对应的数据库访问异常。下表展示了Spring 数据访问异常和JDBC的异常之间的对应关系。

如你所见,Spring为在读取或者写入数据库时可能出错的原因设置了对应的异常类型,Spring 实际提供的数据库访问异常要远多于表10.1所列出的那些。
Spring在提供如此丰富的异常前提下,还保证这些异常类型跟具体的持久化机制隔离。这意味着无论你使用什么持久化框架,你都可以使用同一套异常定义——持久化机制的选择与数据访问层实现解耦合。
LOOK, MA! NO CATCH BLOCKS!
表10.1中没有说明的是:所有这些异常的根对象是DataAccessException,这是一个unchecked exception。换句话说,Spring不会强制你捕获这些数据库访问异常。
Spring通过提供unchecked exception,让开发者决定是否需要捕获并处理某个异常。为了充分发挥Spring的数据访问异常,你最好使用Spring提供的数据访问模板。
10.1.2 模式化数据访问
如果你之前通过飞机出行过,你一定明白在行程过程中最重要的事情是将行李从A地托运到B地。要妥当得完成这个事情需要很多步骤:当你到达机场时,你首先需要检查行李;然后需要通过机场的安全扫描,以免不小心将可能危害飞行安全的东西带上飞机;然后行李需要通过长长的传送带被运上飞机。如果你需要转乘航线,行李也需要跟着你一起运输。当你到达最终目的地时,行李会被运下飞机然后放置在传送带上,最后,你需要去目的地机场的指定地点领取自己的行李。
虽然在这个过程中有需要步骤,但是你仅仅需要参与其中的一部分。在这个例子中,整个过程就是将行李从出发城市运输到目的城市,这个过程是固定的不会改变。在运输过程可以分成明确的几步:检查行李、装载行李、卸载行李等。在这其中一些步骤也是固定的,每次都一样:当飞机到达目的地之后,所有行李都需要卸载并放在机场的指定地点。
在指定的节点,总程序会将一部分工作委托给一个子程序,用于完成更加细节的任务,这就是总程序中的变量部分。例如,行李的托运开始于乘客自己检查行李,因为每个乘客的动作都不相同——各自检查自己的行李,因此总程序中的这个步骤如何执行具体取决于每个乘客。用软件开发中的术语描述,上述过程就是模板模式:模板方法规定整个算法的执行过程,将每个步骤的具体细节通过接口委托给子类完成。
Spring提供的数据访问支持也使用了模板模式。无论你选择使用什么技术,数据访问的步骤就是固定的几步(例如,在开始时,你一定需要获取一个数据库连接;在操作完成后,你一定需要释放之前获取的资源),但是每一步具体怎么实现有所不同。你用不同的方法查询或者更新不同的数据,这些属于数据库访问过程中的变量。
Spring将数据访问过程中的固定步骤和变量部分分为两类:模板(templates)和回调函数(callbacks)。模板负责管理数据访问过程中的固定步骤,而由你定制的业务逻辑则写在回调函数中。下图显示了这两类对象的责任和角色:

如你所见,Spring的模板类处理数据访问的固定步骤——事务管理、资源管理和异常处理;与此同时,跟应用相关的数据访问任务——创建语句、绑定参数和处理结果集等,则需要在回调函数中完成。这种框架十分优雅,作为开发人员你只需要关注具体的数据访问逻辑。
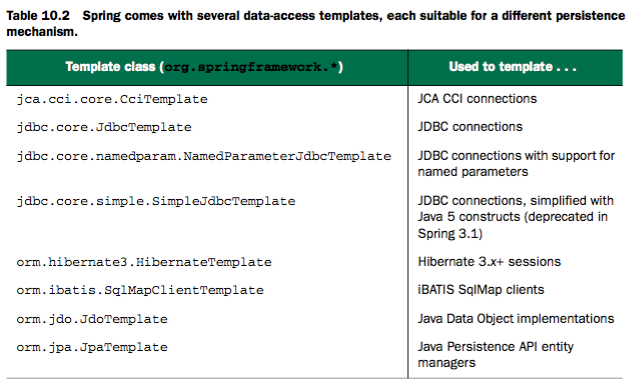
Spring提供了集中不同的模板,开发者根据项目中使用的持久化框架选择对应的模板工具类。如果你使用原始的JDBC方式,则可以使用JdbcTemplate;如果你更倾向于使用ORM框架,则可以使用HibernateTemplate和JpaTemplate。表10.2列出了Spring提供的数据访问模板。
Spring为不同的持久化技术提供了对应的数据访问模板,在这一章中并不能一一讲述。因此我们将选择最有效和你最可能使用的进行讲解。
这一章首先介绍JDBC技术,因为它最简单;在后面还会介绍Hibernate和JPA——两种最流行的基于POJO的ORM框架。PS:除了《Spring in Action》中的这几种持久化技术,现在更加流行的是Mybatis框架,后续我会专门写对应的总结和学习笔记。
但是,所有这些持久化框架都需要依赖于具体的数据源,因此在开始学习templates和repositories之前,需要学习在Spring中如何配置数据源——用于连接数据库。
10.2 配置数据源
Spring提供了几种配置数据源的方式,列举如下:
- 通过JDBC驱动定义数据源;
- 从JNDI中查询数据源;
- 从连接池中获取数据源;
对于生产级别的应用,我建议使用从数据库连接池中获取的数据源;如果有可能,也可以通过JNDI从应用服务器中获取数据源;接下来首先看下如何配置Spring应用从JNDI获取数据源。
10.2.1 使用JNDI数据源
Spring应用一般部署在某个J2EE容器中,例如WebSphere、JBoss或者Tomcat。开发者可以在这些服务器中配置数据源,一遍Spring应用通过JNDI获取。按照这种方式配置数据源的好处在于:数据源配置在应用外部,允许应用在启动完成时再请求数据源进行数据访问;而且,数据源配置在应用服务器中有助于提高性能,且系统管理员可以进行热切换。
首先,需要在tomcat中配置数据源,方法参见stackoverflowHow to use JNDI DataSource provided by Tomcat in Spring?
在SpringXML配置文件中使用<jee:jndi-lookup>元素定义数据源对应的Spring bean。Spring应用根据jndi-name从Tomcat容器中查找数据源;如果应用是运行Java应用服务器中,则需要设置resource-ref为true,这样在查询的时候会在jndi-name指定的名字前面加上java:comp/env/。
<jee:jndi-lookup id="dataSource"
jndi-name="/jdbc/SpitterDS"
resource-ref="true" />如果你使用JavaConfig,则可以使用JndiObjectFactoryBean从JNDI中获取DataSource:
@Beanpublic JndiObjectFactoryBean dataSource() {
JndiObjectFactoryBean jndiObjectFB = new JndiObjectFactoryBean();
jndiObjectFB.setJndiName("/jdbc/SpittrDS");
jndiObjectFB.setResourceRef(true);
jndiObjectFB.setProxyInterface(javax.sql.DataSource.class);
return jndiObjectFB;
}显然,在这里Java配置文件需要写更多代码,一般而言JavaConfig要比XML配置文件更简单,这是个例外。
10.2.2 使用数据库连接池
尽管Spring自身不提供数据连接池,但可以和很多第三方库集成使用,例如:
- Apache Commons DBCP(http://commons.apache.org/proper/commons-dbcp/)
- c3p0(http://sourceforge.net/projects/c3p0/)
- BoneCP(http://jolbox.com/)
最常用的是DBCP,首先需要在pom文件中添加对应的依赖,代码如下:
<dependency><groupId>org.apache.commons</groupId><artifactId>commons-dbcp2</artifactId><version>2.0</version></dependency>关于commons-dbcp版本的区别:commons-dbcp现在分成了2个大版本,不同的版本要求的JDK不同:
- DBCP 2.X compiles and runs under Java 7 only (JDBC 4.1)
- DBCP 1.4 compiles and runs under Java 6 only (JDBC 4)
如果在XML文件中使用,则可以使用下列代码配置DBCP的BasicDataSource:
<bean id="dataSource" class="org.apache.commons.dbcp2.BasicDataSource"
p:driverClassName="org.h2.Driver"
p:url="jdbc:h2:tcp://localhost/~/spitter"
p:username="sa"
p:password=""
p:initialSize="5" />如果你使用Java配置文件,则可以使用下列代码配置DataSourcebean。
@Beanpublic BasicDataSource dataSource() {
BasicDataSource ds = new BasicDataSource();
ds.setDriverClassName("org.h2.Driver");
ds.setUrl("jdbc:h2:tcp://localhost/~/spitter");
ds.setUsername("sa");
ds.setPassword("");
ds.setInitialSize(5);
return ds;
}前四个属性属于配置BasicDataSource的必备属性,driverClassName指定JDBC驱动类的全称,这里我们配置了H2数据库的驱动;url属性用于设置完整的数据库地址;username和password分别指定用户名和密码。BasicDataSource中还有其他的属性,可以设置数据连接池的属性,例如,initialSize属性用于指定连接池初始化时建立几个数据库连接。对于dbcp1.4系列,BasicDataSource的属性可列举如下表10.3所示:

对于dbcp2.x系列,如果你希望了解更多BasicDataSource的属性,可参照官方文档:dbcp2配置。
10.2.3 使用基于JDBC驱动的数据源
在Spring中最简单的数据源就是通过JDBC驱动配置的数据源。Spring提供了三个相关的类供开发者选择(都在org.springframework.jdbc.datasource包中):
- DriverManagerDataSource——每次请求连接时都返回新的连接,用过的连接会马上关闭并释放资源;
- SimpleDriverDataSource——功能和DriverManagerDataSource相同,不同之处在于该类直接和JDBC驱动交互,免去了类在特定环境(如OSGi容器)中可能遇到的类加载问题。
- SingleConnectionDataSource——每次都返回同一个连接对象,可以理解为只有1个连接的数据源连接池。
配置这些数据源跟之前配置DBCP的BasicDataSource类似,例如,可以用下列代码配置DriverManagerDataSource
@Beanpublic DataSource dataSource() {
DriverManagerDataSource ds = new DriverManagerDataSource();
ds.setDriverClassName("org.h2.Driver");
ds.setUrl("jdbc:h2:tcp://localhost/~/spitter");
ds.setUsername("sa");
ds.setPassword("");
return ds;
}上述配置代码的XML形式如下:
<bean id="dataSource" class="org.springframework.jdbc.datasource.DriverManagerDataSource"
p:driverClassName="org.h2.Driver"
p:url="jdbc:h2:tcp://localhost/~/spitter"
p:username="sa"
p:password="" />由于上述这三个数据源对象对多线程应用的支持都不好,因此强烈建议直接使用数据库连接池。
10.2.4 使用嵌入式数据源
嵌入式数据源作为应用的一部分运行,非常适合在开发和测试环境中使用,但是不适合用于生产环境。因为在使用嵌入式数据源的情况下,你可以在每次应用启动或者每次运行单元测试之前初始化测试数据。
使用Spring的jdbc名字空间配置嵌入式数据源非常简单,下列代码显示了如何使用jdbc名字空间配置嵌入式的H2数据库,并配置需要初始化的数据。
<jdbc:embedded-database id="dataSource" type="H2"><jdbc:script location="classpath*:schema.sql" /><jdbc:script location="classpath*:test-data.sql" /></jdbc:embedded-database><jdbc:embedded-database>的type属性设置为H2表明嵌入式数据库的类型是H2数据库(确保引入了H2的依赖库)。在<jdbc:embedded-database>配置中,可以配置多个<jdbc:script>元素,用于设置和初始化数据库:在这个例子中,schema.sql文件中包含用于创建数据表的关系;test-data.sql文件中用于插入测试数据。
如果你使用JavaConfig,则可以使用EmbeddedDatabaseBuilder构建嵌入式数据源:
@Bean
public DataSource dataSource() {
return new EmbeddedDatabaseBuilder()
.setType(EmbeddedDatabaseType.H2)
.addScript("classpath*:schema.sql")
.addScript("classpath*:test-data.sql")
.build();
}可以看出,setType()方法的作用等同于<jdbc:embedded-database>元素的type属性,addScript()方法的作用等同于<jdbc:script>元素。
10.2.5 使用profiles选择数据源
一般需要在不同的环境(日常环境、性能测试环境、预发环境和生产环境等等)中配置不同的数据源,例如,在开发时非常适合使用嵌入式数据源、在QA环境中比较适合使用DBCP的BasicDataSource、在生产环境中则适合使用<jee:jndi-lookup>元素,即使用JNDI查询数据源。
在Spring实战3:装配bean的进阶知识一文中我们探讨过Spring的bean-profiles特性,这里就需要给不同的数据源配置不同的profiles,Java配置文件的内容如下所示:
package org.test.spittr.config;
import org.apache.commons.dbcp2.BasicDataSource;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.context.annotation.Profile;
import org.springframework.jdbc.datasource.DriverManagerDataSource;
import org.springframework.jdbc.datasource.embedded.EmbeddedDatabaseBuilder;
import org.springframework.jdbc.datasource.embedded.EmbeddedDatabaseType;
import org.springframework.jndi.JndiObjectFactoryBean;
import javax.sql.DataSource;
@Configurationpublic class DataSourceConfiguration {
@Profile("development")
@Beanpublic DataSource embeddedDataSource() {
return new EmbeddedDatabaseBuilder()
.setType(EmbeddedDatabaseType.H2)
.addScript("classpath*:schema.sql")
.addScript("classpath*:test-data.sql")
.build();
}
@Profile("qa")
@Beanpublic BasicDataSource basicDataSource() {
BasicDataSource ds = new BasicDataSource();
ds.setDriverClassName("org.h2.Driver");
ds.setUrl("jdbc:h2:tcp://localhost/~/spitter");
ds.setUsername("sa");
ds.setPassword("");
ds.setInitialSize(5); //初始大小
ds.setMaxTotal(10); //数据库连接池大小return ds;
}
@Profile("production")
@Beanpublic DataSource dataSource() {
JndiObjectFactoryBean jndiObjectFactoryBean = new JndiObjectFactoryBean();
jndiObjectFactoryBean.setJndiName("/jdbc/SpittrDS");
jndiObjectFactoryBean.setResourceRef(true);
jndiObjectFactoryBean.setProxyInterface(javax.sql.DataSource.class);
return (DataSource)jndiObjectFactoryBean.getObject();
}
}利用@Profile注解,Spring应用可以运行时再根据激活的profile选择指定的数据源。在上述代码中,当development对应的profile被激活时,应用会使用嵌入式数据源;当qa对应的profile被激活时,应用会使用DBCP的BasicDataSource;当production对应的profile被激活时,应用会使用从JNDI中获取的数据源。
上述代码对应的XML形式的配置代码如下所示:
<?xml version="1.0" encoding="UTF-8"?><beans xmlns="http://www.springframework.org/schema/beans"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xmlns:p="http://www.springframework.org/schema/p"xmlns:jee="http://www.springframework.org/schema/jee" xmlns:jdbc="http://www.springframework.org/schema/jdbc"xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd http://www.springframework.org/schema/jee http://www.springframework.org/schema/jee/spring-jee.xsd http://www.springframework.org/schema/mvc http://www.springframework.org/schema/mvc/spring-mvc.xsd http://www.springframework.org/schema/jdbc http://www.springframework.org/schema/jdbc/spring-jdbc.xsd"><beans profile="qa"><bean id="dataSource" class="org.apache.commons.dbcp2.BasicDataSource"p:driverClassName="org.h2.Driver"p:url="jdbc:h2:tcp://localhost/~/spitter"p:username="sa"p:password=""p:initialSize="5" /></beans><beans profile="production"><jee:jndi-lookup id="dataSource"jndi-name="/jdbc/SpittrDS"resource-ref="true"/></beans><beans profile="development"><jdbc:embedded-database id="dataSource" type="H2"><jdbc:script location="classpath*:schema.sql" /><jdbc:script location="classpath*:test-data.sql" /></jdbc:embedded-database></beans></beans>建立好数据库连接后,就可以执行访问数据库的任务了。正如之前提到的,Spring对很多持久化技术提供了支持,包括JDBC、Hibernate和Java Persistence API(API)。在下一小节中,我们首先介绍如何在Spring应用中使用JDBC书写持久层。
10.3 在Spring应用中使用JDBC
在实际开发过程中有很多持久化技术可供选择:Hibernate、iBATIS和JPA等。尽管如此,还是有很多应用使用古老的方法即JDBC技术,来访问数据库。
使用JDBC技术不需要开发人员学习新的框架,因为它就是基于SQL语言运行的。JDBC技术更加灵活,开发人员可以调整的余地很大,JDBC技术允许开发人员充分利用数据库的本地特性,而在其他ORM框架中可能做不到如此灵活和可定制。
除了上述提到的灵活性、可定制能力,JDBC技术也有一些缺点。
10.3.1 分析JDBC代码
开发者使用JDBC技术提供的API可以非常底层得操作数据库,同时也意味着,开发者需要负责处理数据访问过程中的各个具体步骤:管理数据库资源和处理数据库访问异常。如果你使用JDBC插入数据库,在这个例子中,假设需要插入一条spitter数据,则可以使用如下代码:
@Componentpublic class SpitterDao {
private static final String SQL_INSERT_SPITTER =
"insert into spitter (username, password, firstName, lastName) values (?, ?, ?, ?)";
@Autowiredprivate DataSource dataSource;
public void addSpitter(Spitter spitter) {
Connection conn = null;
PreparedStatement stmt = null;
try {
conn = dataSource.getConnection();
stmt = conn.prepareStatement(SQL_INSERT_SPITTER);
stmt.setString(1, spitter.getUsername());
stmt.setString(2, spitter.getPassword());
stmt.setString(3, spitter.getFirstName());
stmt.setString(4, spitter.getLastName());
stmt.execute();
} catch (SQLException e) {
//do something...not sure what, though
} finally {
try {
if (stmt != null) {
stmt.close();
}
if (conn != null) {
conn.close();
}
} catch (SQLException e) {
//I'm even less sure about what to do here
}
}
}
}addSpitter函数一共有28行,但是只有6行是真正的业务逻辑。为什么如此简单的操作也需要这么多代码?JDBC需要开发者自己管理数据库连接、自己管理SQL语句,以及自己处理可能抛出的异常。
对于SQLException,开发者并不清楚具体该如何处理该异常(该异常并未指明具体的错误原因),却被迫需要捕获该异常。如果在执行插入语句时发生错误,你需要捕获该异常;如果在关闭statement和connection资源时发生错误,你也需要捕获该异常,但是捕获后你并不能做实际的有意义的操作。
同样,如果你需要更新一条spitter记录,则可使用下列代码:
private static final String SQL_UPDATE_SPITTER =
"update spitter set username = ?, password = ?, firstName = ?, lastName=? where id = ?";
public void saveSpitter(Spitter spitter) {
Connection conn = null;
PreparedStatement stmt = null;
try {
conn = dataSource.getConnection();
stmt = conn.prepareStatement(SQL_UPDATE_SPITTER);
stmt.setString(1, spitter.getUsername());
stmt.setString(2, spitter.getPassword());
stmt.setString(3, spitter.getFirstName());
stmt.setString(4, spitter.getLastName());
stmt.setLong(5, spitter.getId());
stmt.execute();
} catch (SQLException e) {
// Still not sure what I'm supposed to do here
} finally {
try {
if (stmt != null) {
stmt.close();
}
if (conn != null) {
conn.close();
}
} catch (SQLException e) {
// or here
}
}
}这一次,saveSpitter函数用于更新数据库中的一行记录,可以看出,有很多重复代码。理想情况应该是:你只需要写特定功能相关的代码。
为了补足JDBC体验之旅,我们再看看如何使用JDBC从数据库中查询一条记录,例子代码如下:
private static final String SQL_SELECT_SPITTER =
"select id, username, firstName, lastName from spitter where id = ?";
public Spitter findOne(long id) {
Connection conn = null;
PreparedStatement stmt = null;
ResultSet rs = null;
try {
conn = dataSource.getConnection();
stmt = conn.prepareStatement(SQL_SELECT_SPITTER);
stmt.setLong(1, id);
rs = stmt.executeQuery();
Spitter spitter = null;
if (rs.next()) {
spitter = new Spitter();
spitter.setId(rs.getLong("id"));
spitter.setUsername(rs.getString("username"));
spitter.setPassword(rs.getString("password"));
spitter.setFirstName(rs.getString("firstName"));
spitter.setLastName(rs.getString("lastName"));
}
return spitter;
} catch (SQLException e) {
} finally {
if (rs != null) {
try {
rs.close();
} catch (SQLException e) { }
}
if (stmt != null) {
try {
stmt.close();
} catch (SQLException e) { }
}
if (conn != null) {
try {
conn.close();
} catch (SQLException e) { }
}
}
return null;
}这个函数跟之前的insert和update例子一样啰嗦冗长:几乎只有20%的代码是真正有用的业务逻辑,而80%的代码则是模板样式代码。
可以看出,使用JDBC持久化技术,就需要编写大量的模板样式代码,用于创建连接、创建statements和处理异常。另外,上述提到的模板样式代码在数据库访问过程中又非常重要:释放资源和处理异常等,这都能提高数据访问的稳定性。如果没有这些操作,应用就无法及时处理错误、资源始终被占用,会导致内存泄露。因此,开发者需要一个数据库访问框架,用于处理这些模板样式代码。
10.3.2 使用Spring提供的JDBC模板
Spring提供的JDBC框架负责管理资源和异常处理,从而可以简化开发者的JDBC代码。开发者只需要编写写入和读取数据库相关的代码即可。
正如在之前的小节中论述过的,Spring将数据库访问过程中的模板样式代码封装到各个模板类中了,对于JDBC,Spring提供了下列三个模板类:
- JdbcTemplate——最基本的JDBC模板,这个类提供了简单的接口,通过JDBC和索引参数访问数据库;
- NameParameterJdbcTemplate——这个JDBC模板类是的开发者可以执行绑定了指定参数名称的SQL,而不是索引参数;
- SimpleJdbcTemplate——这个版本的JDBC模板利用了Java 5的一些特性,例如自动装箱/拆箱、接口和变参列表等,用于简化JDBC模板的使用。
从Spring 3.1开始已经将SimpleJdbcTemplate废弃,它所拥有的Java 5那些特性被添加到原来的JdbcTemplate中了,因此你可以直接使用JdbcTemplate;当你希望在查询中使用命名参数时,则可以选择使用NamedParameterJdbcTemplate。
INSERTING DATA USING JDBCTEMPLATE
要使用JdbcTemplate对象,需要为之传递DataSource对象。如果使用Java Config配置JdbcTemplatebean,则对应代码如下:
@Beanpublic JdbcTemplate jdbcTemplate(DataSource dataSource) {
return new JdbcTemplate(dataSource);
}这里通过构造函数将DataSource对象注入,而dataSourcebean则来自DataSourceConfiguration文件中定义的javax.sql.DataSource实例。
然后就可以在自己的repository实现中注入jdbcTemplatebean,例如,假设Spitter的repository使用jdbcTemplatebean,代码可列举如下:
package org.test.spittr.dao;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.jdbc.core.JdbcOperations;
import org.springframework.stereotype.Repository;
import org.test.spittr.data.Spitter;
@Repository
public class JdbcSpitterRepository implements SpitterRepository {
@Autowired
private JdbcOperations jdbcOperations;
.....
}这里JdbcSpitterRepository被@Repository注解修饰,component-scanning扫描机制起作用时会自动创建对应的bean。按照“面向接口编程”的原则,我们定义JdbcOperations接口对应的实例,而JdbcTemplate实现了这个接口,从而使得JdbcSpitterRepository与JdbcTemplate解耦合。
使用JdbcTemplate实现的addSpitter()方法非常简单,代码如下:
public void addSpitter(Spitter spitter) {
jdbcOperations.update(SQL_INSERT_SPITTER,
spitter.getUsername(),
spitter.getPassword(),
spitter.getFirstName(),
spitter.getLastName());
}可以看出,这个版本的addSpitter十分简单,不强制开发者写任何管理资源和处理异常的代码,只有插入语句和对应的参数。
当调用update()方法时,JdbcTemplate获取一个连接、创建一个statement,并执行插入语句。
JdbcTemplate内部捕获了可能抛出的SQLException异常,然后转为更具体的数据库访问异常,并重新抛出。由于Spring的数据库访问异常都是运行时异常,开发者可以自己决定是否捕获这些异常。
READING DATA WITH JDBCTEMPLATE
使用JdbcTemplate工具从数据库中读取数据也非常简单,下列代码展示了改造过后的findOne()函数:调用JdbctTemplate的queryForObject函数,用于通过ID查询Spitter对象。
public Spitter findOne(long id) {
return jdbcOperations.queryForObject(
SQL_SELECT_SPITTER,
new SpitterRowMapper(),
id);
}
private static final class SpitterRowMapper implements RowMapper<Spitter> {
public Spitter mapRow(ResultSet resultSet, int i) throws SQLException {
return new Spitter(
resultSet.getLong("id"),
resultSet.getString("firstName"),
resultSet.getString("lastName"),
resultSet.getString("username"),
resultSet.getString("password"));
}
}findOne()函数使用JdbcTemplate的queryForObject()方法从数据库中查询Spitter记录。queryForObject()方法包括三个参数:
- SQL字符串,用于从数据库中查询数据;
- RowMapper对象,用于从结果集ResultSet中提取数据并构造Spitter对象;
- 变量列表,用于指定查询参数(这里是通过id查询)。
这里需要注意SpitterRowMapper类,它实现了RowMapper接口,对于查询结果,JdbcTemplate调用mapRow()方法——一个ResultSet参数和一个row number参数。mapRow()方法的主要作用是:从结果集中取出对应属性的值,并构造一个Spitter对象。
和addSpitter()方法相同,findOne()方法也没有那些JDBC模板样式代码,只有纯粹的用于查询Spitter数据的代码。
10.4 总结
数据就像应用的血液,在某些以数据为中心的业务中,数据本身就是应用。在企业级应用开发中,编写稳定、简单、性能良好的数据访问层非常重要。
JDBC是Java处理关系型数据的基本技术。原生的JDBC技术并不完美,开发者不得不写很多模板样式代码,用于管理资源和处理异常。Spring提供了对应的模板工具类,用于消除这些模板样式代码。
Spring实战6:利用Spring和JDBC访问数据库的更多相关文章
- 2017.10.3 JDBC访问数据库的建立过程
1·JDBC访问数据库,其访问流程: (1)注册驱动 (2)建立连接(Connection) (3)创建数据库操作对象用于执行SQL语句 (4)执行语句 (5)处理执行结果 (6)释放资源 2·注册驱 ...
- 如何通过JDBC访问数据库
Java数据库连接(JDBC)用与在Java程序中实现数据库操作功能,它提供了执行SQL语句.访问各种数据库的方法,并为各种不同的数据库提供统一的操作接口,java.sql包中包含了JDBC操作数据库 ...
- java web中Jdbc访问数据库步骤通俗解释(吃饭),与MVC的通俗解释(做饭)
一.Jdbc访问数据库步骤通俗解释(吃饭) 1)加载驱动 Class.forName(“com.microsoft.jdbc.sqlserver.SQLServer”); 2) 与数据库建立连接 Co ...
- Jdbc访问数据库篇
一万年太久,只争朝夕 What JDBC 上部 JDBC(Java DataBase Connectivity)Java 数据库连接,主要提供编写 Java 数据库应用程序的 API 支持 java. ...
- JDBC访问数据库的具体步骤(MySql + Oracle + SQLServer)
* 感谢DT课堂颜群老师的视频讲解(讲的十分仔细,文末有视频链接) import java.sql.Connection; import java.sql.DriverManager; import ...
- Spring Boot入门(五):使用JDBC访问MySql数据库
本系列博客记录自己学习Spring Boot的历程,如帮助到你,不胜荣幸,如有错误,欢迎指正! 在程序开发的过程中,操作数据库是必不可少的部分,前面几篇博客中,也一直未涉及到数据库的操作,本篇博客 就 ...
- 【Spring实战】—— 15 Spring JDBC模板使用
前一篇通过对传统的JDBC的使用操作,可以体会到使用的繁琐与复杂,套句话说,是用了20%作了真正的工作,80%作了重复的工作. 那么通过本篇,可以了解如下的内容: 1 如何配置数据源 2 如何在spr ...
- Spring实战1:Spring初探
主要内容 Spring的使命--简化Java开发 Spring容器 Spring的整体架构 Spring的新发展 现在的Java程序员赶上了好时候.在将近20年的历史中,Java的发展历经沉浮.尽管有 ...
- Spring实战5-基于Spring构建Web应用
主要内容 将web请求映射到Spring控制器 绑定form参数 验证表单提交的参数 写在前面:关于Java Web,首先推荐一篇文章——写给java web一年左右工作经验的人,这篇文章的作者用精练 ...
随机推荐
- ~0u >> 1
~ 逐位求反u 后辍为 定义unsigned类型>>右移如在32系统中,连起来就是 将32位的0取反后 右移一位.也就是 int 的最大值 2147482347
- CentOS 6.2 OpenVPN 搭建
一.yum 安装. 二.下载 easy-rsa 3.0 三.生成根证书.服务器.客户端证书.ta 生成流程: wget -c https://github.com/OpenVPN/easy-rsa/a ...
- 111. Minimum Depth of Binary Tree
Given a binary tree, find its minimum depth. The minimum depth is the number of nodes along the shor ...
- 信頼済みサイト对window.open窗体大小影响原因之一
如果某站点被添加进去之后,这个站点窗体限制被决定了,window.open里面,status bar 无效的设置不再起作用.而且,如果原来status bar被 任务栏挡住的话,这个时候它就会被显示出 ...
- 固定虚拟机的IP
- Java Warmup
http://www.brendangregg.com/blog/2016-09-28/java-warmup.html
- HttpWebRequest's Timeout and ReadWriteTimeout — What do these mean for the underlying TCP connection?
http://stackoverflow.com/questions/7250983/httpwebrequests-timeout-and-readwritetimeout-what-do-thes ...
- 简单实用的Android ORM框架TigerDB
TigerDB是一个简单的Android ORM框架,它能让你一句话实现数据库的增删改查,同时支持实体对象的持久化和自动映射,同时你也不必关心表结构的变化,因为它会自动检测新增字段来更新你的表结构. ...
- 数据恢复-extundelete
http://extundelete.sourceforge.net/options.html 误删除/usr/share目录因此考虑恢复目录过程如下:1.选用extundelete软件来进行恢复,源 ...
- linux服务之asterisk
由于Asterisk过于专业且复杂,所以目前也存在大量衍生自Asterisk但简化过的通信系统,以让用户较容易使用.比如在欧美比较流行的elastix.trixbox.或以简体中文为基础的Freeir ...