[Python爬虫笔记][随意找个博客入门(一)]
[Python爬虫笔记][随意找个博客入门(一)]
标签(空格分隔): Python 爬虫 2016年暑假
来源博客:挣脱不足与蒙昧
1.简单的爬取特定url的html代码
import urllib.request
url = "http://120.27.101.158/"
response = urllib.request.urlopen(url)
html = response.read()
html = html.decode('utf-8');
print (html)
urllib.request.urlopen()- 有点类似于文件操作里的open,返回的
response对象也类似与文件对象。 - 等价于
req = urllib.request.Request("http://placekitten.com/500/600")
response = urllib.request.urlopen(req)
- 有点类似于文件操作里的open,返回的
response.read()response对象的读操作,类似的文件对象的读操作.- 该对象还有以下常用方法
response.geturl() ##访问的具体地址。
response.info() ##远程的服务器的信息
response.getcode() ##http的状态
html.decode()- decode() 方法以encoding指定的编码格式解码字符串。
2.简单的翻译程序(爬取有道词典)
- 在我们注册信息的时候,填写资料的时候,都涉及到表单(form)的应用。 是一个POST请求发送到服务器端的过程。 HTML中的表单时有特定格式的,举个例子,我们打开有道在线翻译,调出调试平台,输入翻译内容“Hello,Python”点击自动翻译。

- 在调试平台中的
network中我们可以看到一些常见的信息 - 如访问的具体的
url地址,http的状态(200)
- 在参数栏(FireFox)可以看见提交的表单信息(
json格式)
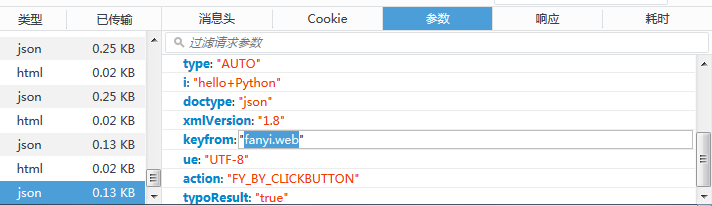
- 在响应栏,可以知道返回的表单信息也是
json格式
用字典传入一个json并提交表单,并解析返回来html里的json,代码如下。
import urllib.request
'''urllib中的parse用来对url解析'''
import urllib.parse
import json
url = 'http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule&smartresult=ugc&sessionFrom=null/'
content = input("你想翻译什么呀?")
data = {}
data['type']='AUTO'
data['i'] = content
data['doctype'] = 'json'
data['xmlVersion'] = '1.8'
data['keyfrom'] = 'fanyi.web'
data['ue'] = 'UTF-8'
data['typoResult'] = 'true'
data = urllib.parse.urlencode(data).encode('utf-8')
response = urllib.request.urlopen(url, data)
html=response.read().decode('utf-8')
target =json.loads(html)
print ("翻译结果是:%s" %(target['translateResult'][0][0]['tgt']))
结果
> print (target)
{'translateResult': [[{'src': '测试程序', 'tgt': 'The test program'}]], 'elapsedTime': 0, 'errorCode': 0, 'smartResult': {'entries': ['', '[计] test program'], 'type': 1}, 'type': 'ZH_CN2EN'}
我们看到翻译的内容在translateResult[0][0][‘tgt’]中

data = urllib.parse.urlencode(data).encode('utf-8')将字典转换为能够
post,get进行的字符串,对于中文编码为默认格式的字符串。encode将该字符串转换为一个字节序列。(从下面程序可以看出其实这个utf-8没什么卵用,换成gbk还会是一样的结果)
data
{'type': 'AUTO', 'ue': 'UTF-8', 'typoResult': 'true', 'i': '程序测试', 'xmlVersion': '1.8', 'keyfrom': 'fanyi.web', 'doctype': 'json'}
data = urllib.parse.urlencode(data); #dict转换为str
'type=AUTO&ue=UTF-8&typoResult=true&i=%E7%A8%8B%E5%BA%8F%E6%B5%8B%E8%AF%95&xmlVersion=1.8&keyfrom=fanyi.web&doctype=json'
data = data.encode('utf-8'); #str转换为byte序列
b'type=AUTO&ue=UTF-8&typoResult=true&i=%E7%A8%8B%E5%BA%8F%E6%B5%8B%E8%AF%95&xmlVersion=1.8&keyfrom=fanyi.web&doctype=json'
response = urllib.request.urlopen(url, data)- 传入的
data必须为byte型字符串
- 传入的
html=response.read().decode('utf-8')- 将接收来的
utf-8页面解码为unicode
- 将接收来的
target =json.loads(html)- 这个页面应该是一个
json,将其转换为字典
- 这个页面应该是一个
3.小模仿,爬谷歌翻译
import re
import urllib.parse
import urllib.request
#----------模拟浏览器的行为,向谷歌翻译发送数据,然后抓取翻译结果,这就是大概的思路-------
def Gtranslate(text):
Gtext=text #text 输入要翻译的英文句子
#hl:浏览器、操作系统语言,默认是zh-CN
#ie:默认是UTF-8
#text:就是要翻译的字符串
#langpair:语言对,即'en'|'zh-CN'表示从英语到简体中文
values={'hl':'zh-CN','ie':'UTF-8','text':Gtext,'langpair':"auto"}
url='http://translate.google.cn/' #URL用来存储谷歌翻译的网址
data = urllib.parse.urlencode(values).encode("utf-8") #将values中的数据通过urllib.urlencode转义为URL专用的格式然后赋给data存储
req = urllib.request.Request(url,data) #然后用URL和data生成一个request
browser='Mozilla/4.0 (Windows; U;MSIE 6.0; Windows NT 6.1; SV1; .NET CLR 2.0.50727)' #伪装一个IE6.0浏览器访问,如果不伪装,谷歌将返回一个403错误
req.add_header('User-Agent',browser)
response = urllib.request.urlopen(req) #向谷歌翻译发送请求
html=response.read() #读取返回页面,然后我们就从这个HTML页面中截取翻译过来的字符串即可
html=html.decode('utf-8')
#使用正则表达式匹配<=TRANSLATED_TEXT=)。而翻译后的文本是'TRANSLATED_TEXT='等号后面的内容
p=re.compile(r"(?<=TRANSLATED_TEXT=).*(?=';INPUT_TOOL_PATH='//www.google.com')")
m=p.search(html)
chineseText=m.group(0).strip(';')
return chineseText
if __name__ == "__main__":
#Gtext为待翻译的字符串
Gtext='我是上帝'
print('The input text: %s' % Gtext)
chineseText=Gtranslate(Gtext).strip("'")
print('Translated End,The output text: %s' % chineseText)
实际的爬虫十分麻烦,要考虑是否被屏蔽,还有登陆等等问题。待继续好好学习。
几个资料
Python网络爬虫(Get、Post抓取方式)
py爬取英文文档学习单词
python网络爬虫入门(二)——用python简单实现调用谷歌翻译
[Python爬虫笔记][随意找个博客入门(一)]的更多相关文章
- Python爬虫,看看我最近博客都写了啥,带你制作高逼格的数据聚合云图
转载请标明出处: http://blog.csdn.net/forezp/article/details/70198541 本文出自方志朋的博客 今天一时兴起,想用python爬爬自己的博客,通过数据 ...
- Python+爬虫+xlwings发现CSDN个人博客热门文章
☞ ░ 前往老猿Python博文目录 ░ 一.引言 最近几天老猿博客的访问量出现了比较大的增长,从常规的1000-3000之间波动的范围一下子翻了将近一倍,粉丝增长从日均10-40人也增长了差不多一倍 ...
- python3.4学习笔记(七) 学习网站博客推荐
python3.4学习笔记(七) 学习网站博客推荐 深入 Python 3http://sebug.net/paper/books/dive-into-python3/<深入 Python 3& ...
- 利用爬虫将Yuan先生的博客文章爬取下来
由于一次巧遇,我阅读了Yuan先生的一篇博客文章,感觉从Yuan先生得博客学到很多东西,很喜欢他得文章.于是我就关注了他,并且想阅读更多出自他手笔得博客文章,无奈,可能Yuan先生不想公开自己得博客吧 ...
- python实现的文本编辑器 - Skycrab - 博客频道 - CSDN.NET
Download Qt, the cross-platform application framework | Qt Project Qt 5.2.1 for Windows 64-bit (VS 2 ...
- python—webshell_醉清风xf_新浪博客
python—webshell_醉清风xf_新浪博客 python—webshell (2012-05-23 09:55:46) 转载▼
- Python爬虫笔记一(来自MOOC) Requests库入门
Python爬虫笔记一(来自MOOC) 提示:本文是我在中国大学MOOC里面自学以及敲的一部分代码,纯一个记录文,如果刚好有人也是看的这个课,方便搬运在自己电脑上运行. 课程为:北京理工大学-嵩天-P ...
- python爬虫笔记Day01
python爬虫笔记第一天 Requests库的安装 先在cmd中pip install requests 再打开Python IDM写入import requests 完成requests在.py文 ...
- Typora笔记上传到博客
Typora笔记上传到博客 Markdown是一种轻量级标记语言,排版语法简洁,让人们更多地关注内容本身而非排版.它使用易读易写的纯文本格式编写文档,可与HTML混编,可导出 HTML.PDF 以及本 ...
随机推荐
- win8发布 wcf问题
WCF services don’t run on IIS 8 with the default configuration, because the webserver doesn’t know, ...
- MySQL 表子查询
MySQL 表子查询 表子查询是指子查询返回的结果集是 N 行 N 列的一个表数据. MySQL 表子查询实例 下面是用于例子的两张原始数据表: article 表: aid title conten ...
- log4j日志输出使用教程
Log4j是帮助开发人员进行日志输出管理的API类库.它最重要的特点就可以配置文件灵活的设置日志信息的优先级.日志信息的输出目的地以及日志信息的输出格式.Log4j除了可以记录程序运行日志信息外还有一 ...
- sql查询语句心得
1)where 有多个用in ,一个用= 2)自身链接 select A.Sno from S A,S B where A.Sname='a' AND A.City=B.City)) 3)外链接(同时 ...
- android JNI (二) 第一个 android工程
下载NDK 后 它自带有 sample,初学者 可以导入Eclipse 运行 这里 我是自己创建的一个新工程 第一步: 新建一个Android工程 jni_test(名字自取) 第二步:为工程添加 本 ...
- CClientDC
CClientDC(客户区设备上下文)用于客户区的输出,它在构造函数中封装了GetDC(),在析构函数中封装了ReleaseDC()函数.一般在响应非窗口重画消息(如键盘输入时绘制文本.鼠标绘图)绘图 ...
- JS encode decode
网上查到的全都是escape,和需要的编码不是一回事,好不容易找到的结果 保存下来以备以后使用 js对文字进行编码涉及3个函数:escape,encodeURI,encodeURIComponent, ...
- Linux系统下快速删除某个目录下大量文件
不管是哪个操作系统,同一级目录存在太多的文件都是一件可怕的事情,不管是读取还是删除的时候. 一旦这种不幸的事情发生在你身上,而又不能完全把整个目录删掉怎么办呢? 你可以用 rm -f *.log 但是 ...
- HBase笔记--自定义filter
自定义filter需要继承的类:FilterBase 类里面的方法调用顺序 方法名 作用 1 boolean filterRowKey(Cell cell) 根据row key过滤row.如果需要 ...
- Linux系统编程(37)—— socket编程之UDP服务器与客户端
典型的UDP客户端/服务器通讯过程: 编写UDP Client程序的步骤 1.初始化sockaddr_in结构的变量,并赋值.这里使用"8888"作为连接的服务程序的端口,从命令行 ...