Lucene学习之初步了解
全文搜索
比如,我们一个文件夹中,或者一个磁盘中有很多的文件,记事本、world、Excel、pdf,我们想根据其中的关键词搜索包含的文件。例如,我们输入Lucene,所有内容含有Lucene的文件就会被检查出来。这就是所谓的全文检索。因此,很容易的我们想到,应该建立一个关键字与文件的相关映射,盗用ppt中的一张图,很明白的解释了这种映射如何实现。
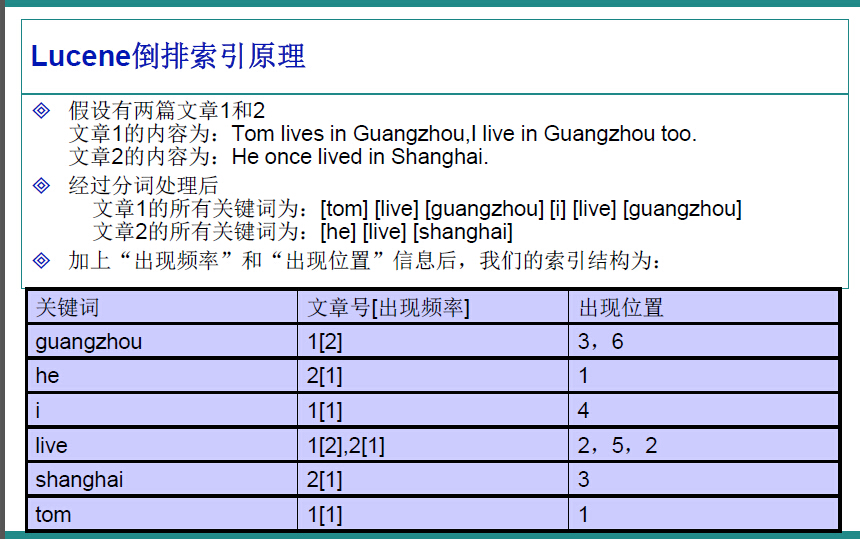
在Lucene中,就是使用这种“倒排索引”的技术,来实现相关映射。 有了这种映射关系,我们就来看看Lucene的架构设计。下面是Lucene的资料必出现的一张图,但也是其精髓的概括。
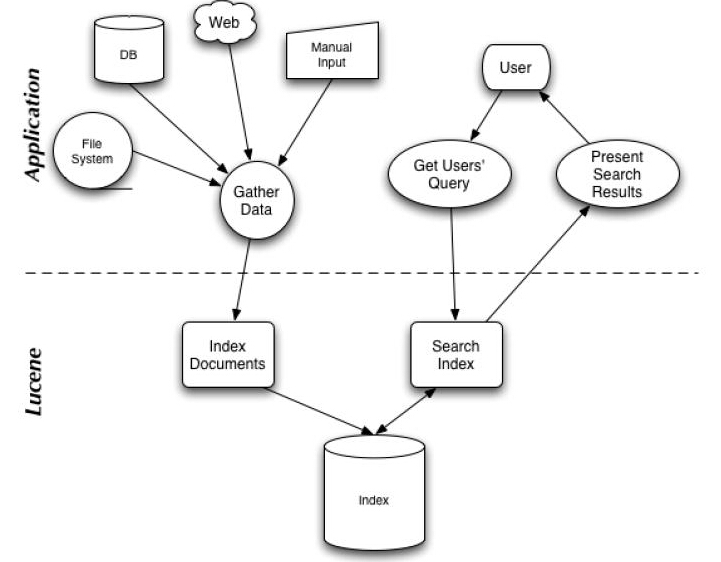
我们可以看到,Lucene的使用主要体现在两个步骤:
1 创建索引,通过IndexWriter对不同的文件进行索引的创建,并将其保存在索引相关文件存储的位置中。
2 通过索引查寻关键字相关文档。
Analyzer analyzer = new StandardAnalyzer(Version.LUCENE_CURRENT);
// Store the index in memory:
Directory directory = new RAMDirectory();
// To store an index on disk, use this instead:
//Directory directory = FSDirectory.open("/tmp/testindex");
IndexWriterConfig config = new IndexWriterConfig(Version.LUCENE_CURRENT, analyzer);
IndexWriter iwriter = new IndexWriter(directory, config);
Document doc = new Document();
String text = "This is the text to be indexed.";
doc.add(new Field("fieldname", text, TextField.TYPE_STORED));
iwriter.addDocument(doc);
iwriter.close();
// Now search the index:
DirectoryReader ireader = DirectoryReader.open(directory);
IndexSearcher isearcher = new IndexSearcher(ireader);
// Parse a simple query that searches for "text":
QueryParser parser = new QueryParser(Version.LUCENE_CURRENT, "fieldname", analyzer);
Query query = parser.parse("text");
ScoreDoc[] hits = isearcher.search(query, null, 1000).scoreDocs;
assertEquals(1, hits.length);
// Iterate through the results:
for (int i = 0; i < hits.length; i++) {
Document hitDoc = isearcher.doc(hits[i].doc);
assertEquals("This is the text to be indexed.", hitDoc.get("fieldname"));
}
ireader.close();
directory.close();
索引的创建
首先,我们需要定义一个词法分析器。
比如一句话,“我爱我们的中国!”,如何对他拆分,扣掉停顿词“的”,提取关键字“我”“我们”“中国”等等。这就要借助的词法分析器Analyzer来实现,这里面使用的是标准的词法分析器,如果专门针对汉语,还可以搭配paoding,进行使用。
Analyzer analyzer = new StandardAnalyzer(Version.LUCENE_CURRENT);
参数中的Version.LUCENE_CURRENT,代表使用当前的Lucene版本,本文环境中也可以写成Version.LUCENE_40。
第二步,确定索引文件存储的位置,Lucene提供给我们两种方式:
1 本地文件存储
Directory directory = FSDirectory.open("/tmp/testindex");
2 内存存储
Directory directory = new RAMDirectory();
可以根据自己的需要进行设定。
第三步,创建IndexWriter,进行索引文件的写入。
IndexWriterConfig config = new IndexWriterConfig(Version.LUCENE_CURRENT, analyzer);
IndexWriter iwriter = new IndexWriter(directory, config);
这里的IndexWriterConfig,据官方文档介绍,是对indexWriter的配置,其中包含了两个参数,第一个是目前的版本,第二个是词法分析器Analyzer。
第四步,内容提取,进行索引的存储
Document doc = new Document();
String text = "This is the text to be indexed.";
doc.add(new Field("fieldname", text, TextField.TYPE_STORED));
iwriter.addDocument(doc);
iwriter.close();
第一行,申请了一个document对象,这个类似于数据库中的表中的一行。
第二行,是我们即将索引的字符串。
第三行,把字符串存储起来(因为设置了TextField.TYPE_STORED,如果不想存储,可以使用其他参数,详情参考官方文档),并存储“表明”为"fieldname".
第四行,把doc对象加入到索引创建中。
第五行,关闭IndexWriter,提交创建内容。
这就是索引创建的过程。
关键字查询:
第一步,打开存储位置
DirectoryReader ireader = DirectoryReader.open(directory);
第二步,创建搜索器
IndexSearcher isearcher = new IndexSearcher(ireader);
第三步,类似SQL,进行关键字查询
QueryParser parser = new QueryParser(Version.LUCENE_CURRENT, "fieldname", analyzer);
Query query = parser.parse("text");
ScoreDoc[] hits = isearcher.search(query, null, 1000).scoreDocs;
assertEquals(1, hits.length);
for (int i = 0; i < hits.length; i++) {
Document hitDoc = isearcher.doc(hits[i].doc);
assertEquals("This is the text to be indexed.",hitDoc.get("fieldname"));
}
这里,我们创建了一个查询器,并设置其词法分析器,以及查询的“表名“为”fieldname“。查询结果会返回一个集合,类似SQL的ResultSet,我们可以提取其中存储的内容。
关于各种不同的查询方式,可以参考官方手册,或者推荐的PPT
第四步,关闭查询器等。
ireader.close();
directory.close();
Lucene学习之初步了解的更多相关文章
- Lucene学习入门——下载初识
本文从官网下载Lucene开始,一步一步进行Lucene的应用学习研究.下载初识Snowball Stemmer 1.下载 (1)首先,去Lucne的Apache官网主页 http://lucene. ...
- Lucene学习笔记(更新)
1.Lucene学习笔记 http://www.cnblogs.com/hanganglin/articles/3453415.html
- Lucene学习总结之七:Lucene搜索过程解析
一.Lucene搜索过程总论 搜索的过程总的来说就是将词典及倒排表信息从索引中读出来,根据用户输入的查询语句合并倒排表,得到结果文档集并对文档进行打分的过程. 其可用如下图示: 总共包括以下几个过程: ...
- Lucene学习总结之六:Lucene打分公式的数学推导
在进行Lucene的搜索过程解析之前,有必要单独的一张把Lucene score公式的推导,各部分的意义阐述一下.因为Lucene的搜索过程,很重要的一个步骤就是逐步的计算各部分的分数. Lucene ...
- Lucene学习-深入Lucene分词器,TokenStream获取分词详细信息
Lucene学习-深入Lucene分词器,TokenStream获取分词详细信息 在此回复牛妞的关于程序中分词器的问题,其实可以直接很简单的在词库中配置就好了,Lucene中分词的所有信息我们都可以从 ...
- Lucene学习总结之七:Lucene搜索过程解析 2014-06-25 14:23 863人阅读 评论(1) 收藏
一.Lucene搜索过程总论 搜索的过程总的来说就是将词典及倒排表信息从索引中读出来,根据用户输入的查询语句合并倒排表,得到结果文档集并对文档进行打分的过程. 其可用如下图示: 总共包括以下几个过程: ...
- Lucene学习总结之六:Lucene打分公式的数学推导 2014-06-25 14:20 384人阅读 评论(0) 收藏
在进行Lucene的搜索过程解析之前,有必要单独的一张把Lucene score公式的推导,各部分的意义阐述一下.因为Lucene的搜索过程,很重要的一个步骤就是逐步的计算各部分的分数. Lucene ...
- Apache Lucene学习笔记
Hadoop概述 Apache lucene: 全球第一个开源的全文检索引擎工具包 完整的查询引擎和搜索引擎 部分文本分析引擎 开发人员在此基础建立完整的全文检索引擎 以下为转载:http://www ...
- Lucene学习笔记
师兄推荐我学习Lucene这门技术,用了两天时间,大概整理了一下相关知识点. 一.什么是Lucene Lucene即全文检索.全文检索是计算机程序通过扫描文章中的每一个词,对每一个词建立一个索引,指明 ...
随机推荐
- 自定义的GitLab 头像无法正常显示以及URL总是指向localhost
解决指向localhost的问题: 编辑gitlab的配置vi /etc/gitlab/gitlab.rb,修改external_url 参数值 [Mesogene@localhost ~]$ sud ...
- 如何在Google Map中处理大量标记(ASP.NET)(转)
如何在Google Map中处理大量标记(ASP.NET)(原创-翻译) Posted on 2010-07-29 22:04 Happy Coding 阅读(8827) 评论(8) 编辑 收藏 在你 ...
- exist和not exist用法
参考:http://wenku.baidu.com/view/577f4d49cf84b9d528ea7a6f.html //这个讲的很详细 引用自:http://chenling1018.bl ...
- Piggy-Bank (hdoj1114)
Piggy-Bank Problem Description Before ACM can do anything, a budget must be prepared and the necessa ...
- Wordpress 音频播放器 Wordpress audio player with jQuery audioplayer.swf
原文地址:http://justcoding.iteye.com/blog/545978 Wordpress audio player with jQuery How to use Wordpress ...
- poj 1065 Wooden Sticks_贪心
题意:将木棍放在机器里处理,第一根需要一分钟,剩余的如果大于等于前边放入的长度和重量,就不用费时间,否则需要一分钟,计算给出一组数的最少时间. 思路:先按长度排序,相同在比较重量,然后按顺序比较得出结 ...
- Uber上海公司被司机打上门
“Uber上周的工资没有到账,司机们都急了.”9月13日,<IT时报>记者接到Uber司机爆料,称Uber(优步)拖欠工资,客服给的解释是银行系统对接问题,但多名司机赶往Uber上海公司咨 ...
- 我使用过的Linux命令之file - 检测并显示文件类型
摘自:http://codingstandards.iteye.com/blog/804463 我使用过的Linux命令之file - 检测并显示文件类型 用途说明 file命令是用来检测并显示文件类 ...
- 创建渐进式jpeg图片
<?php // Create an image instance $im = imagecreatefromjpeg('test.jpg'); // Enable interlancing ...
- 编译hadoop2.2.0源码时报错
编译hadoop2.2.0源码时, mvn install -DskipTests 报错: [ERROR] COMPILATION ERROR : [INFO] ------------------- ...