【RL系列】Multi-Armed Bandit问题笔记
这是我学习Reinforcement Learning的一篇记录总结,参考了这本介绍RL比较经典的Reinforcement Learning: An Introduction (Drfit) 。这本书的正文部分对理论的分析与解释做的非常详细,并且也给出了对结论详尽的解析,但是把问题的解决和实现都留到到了课后题,所以本篇文章主要侧重与对Multi-Armed Bandit问题解决算法的实现以及对实现中可能遇到的问题进行一个总结与记录。此外,如果困于书中对于理论解释的冗长,可以参考下面这两篇文章(推荐阅读顺序为:书 → 下面这两篇 → 本篇):
《Reinforcement Learning》 读书笔记 2:多臂Bandit(Multi-armed Bandits)
问题分析
Multi-Armed Bandit问题是一个十分经典的强化学习(RL)问题,翻译过来为“多臂抽奖问题”。对于这个问题,我们可以将其简化为一个最优选择问题。
假设有K个选择,每个选择都会随机带来一定的收益,对每个个收益所服从的概率分布,我们可以认为是Banit一开始就设定好的。举个例子,对三臂Bandit来说,每玩一次,可以选择三个臂杆中的任意一个,那么动作集合Actions = [1, 2, 3],这里的1、2、3分别表示一号臂杆,二号臂杆和三号臂杆。掰动一号号臂杆时,获得的收益服从均匀分布U(-1, 1),也就是说收益为从-1到1的一个随机数,且收益的均值为0。那么二号臂杆和三号臂杆也同样有自己收益的概率分布,分别为正态分布N(1, 1)和均匀分布U(-2, 1)。这里所需要解决关键问题就是,如何选择动作来确保实验者能获得的收益最高。
我们可以从收益的概率分布上发现二号臂杆的收益均值最高,所以每次实验拉动二号即可,最优选择即为二号。但是对于实验者来说收益概率分布是个黑箱,并不能做出直接判断,所以我们使用RL来估计出那个最优的选择。
算法实现
这里以Sample Average Epsilon-greedy算法为例,给出RL解决Multi-Armed Bandit问题的大致框架:
1. 随机生成收益均值序列,这里我们假设所有选择对应的收益概率分布均为方差相同的正态分布,只不过各个分布的均值不一,这里使用Matlab代码来进行解释
- % 10-Armed Bandit
- K = 10;
- AverReward = randn([1 K]);
- % Reward for each Action per experiment
- % Reward(Action) = normrnd(AverReward(Action), 1);
2. 依据epsilon-greedy判断当前应当选择的动作。在每次实验开始时,随机一个大于0小于1的值,如果该值小于epsilon,则随机选择动作;如果大于,选择当前平均收益最高的那个动作。
- N = 1000 % 1000 experiments
- for n = 1:N
- [max i] = max(Q);
- if(max~=0 & rand(1) < 1 - epsilon)
- Action = i;
- else
- Action = unidrnd(K);
- end
- % Q is a set of records of current average reward.
- % Action is in {1, 2, 3, 4, 5, 6, 7, 8, 9, 10}
- % Q(1) represents current average reward for action = 1.
- end
3. 使用增量形式实现更新当前平均收益Q值
- N = 1000 % 1000 experiments
- for n = 1:N
- [max i] = max(Q);
- if(max~=0 & rand(1) < 1 - epsilon)
- Action = i;
- else
- Action = unidrnd(K);
- end
- % Q is a set of records of current average reward.
- % Action is in {1, 2, 3, 4, 5, 6, 7, 8, 9, 10}
- % Q(1) represents current average reward for action = 1.
- Reward(Action) = normrnd(AverReward(Action), 1);
- N(Action) = N(Action) + 1;
- Q(Action) = (Reward(Action) - Q(Action))*(1/N(Action)) + Q(Action);
- end
评价指标
依据 Reinforcement Learning: An Introduction (Drfit) 中关于这一部分的结论分析,主要的两个评价指标是Average Reward和Optimal Action Rate。这两个指标都是用来评价不同算法的优劣程度的。这里的Average Reward和先前提到的当前收益均值是有所不同的。参照上一部分算法实现中给的例子,每次学习过程需要进行1000次实验,每次学习完成后则会得到一个最优估计值,将最优估计值Q记录下来并进行下一次学习,当进行n次学习后,评价收益均值即为这n个Q值的均值,给出Average Reward的计算方法:
需要注意的是,在计算Average Reward(AR)时,各动作的收益概率分布需要保持不变。不同的算法得到的AR值也不同,通常来说一个算法的AR值越高表明依据该算法获得的最优估计值与实际的最优值间的差距越小,简单来说就是该算法的可靠性越高。
Optimal Action Rate(OAR) 表示最佳动作选择率,当进行多次学习时,计算最优估计值与实际最优值速对应的动作相符的频率,将其近似为一个算法的OAR。通常来说,一个算法的OAR越高,说明该算法估计的成功率越高,稳定性越好。
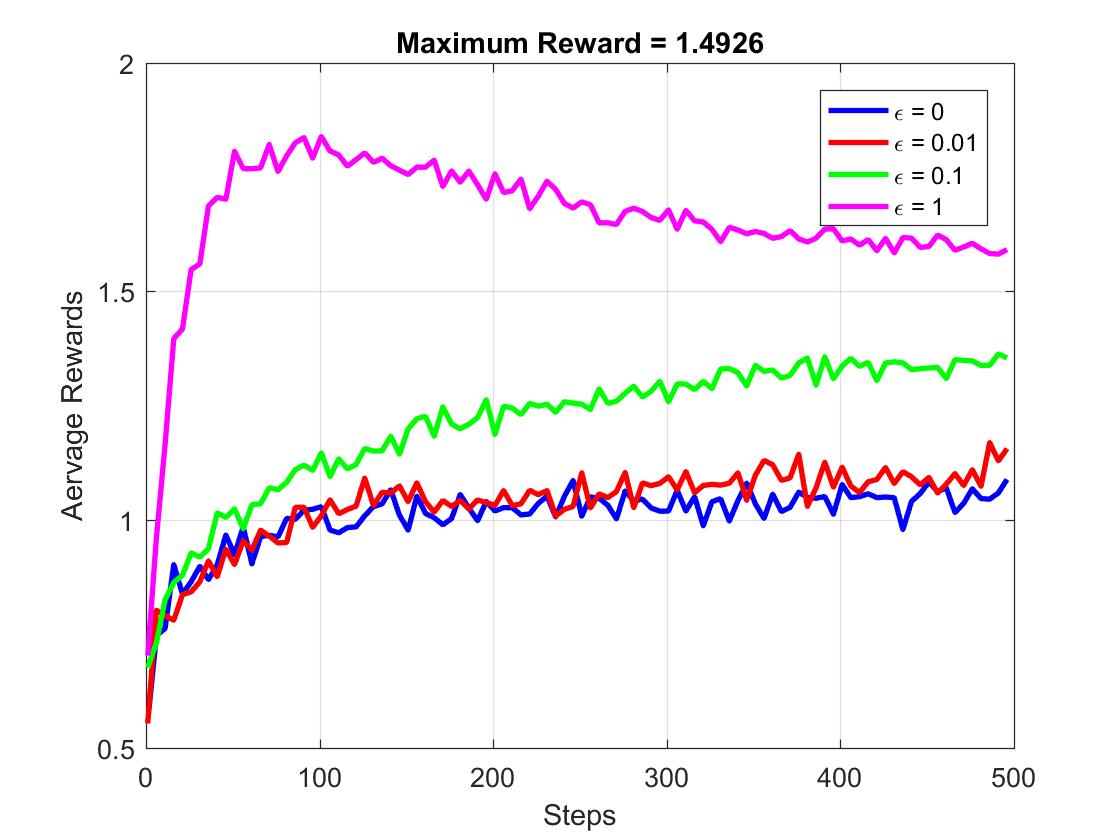
这里给出不同epsilon值所对应不同的epsilon-greedy算法的AR与OAR的对比。下面先给出实验的具体参数设置:
- 10-Armed Bandit,也就是说K = 10
- Epsilon = [0 0.01 0.1 1]
- 收益服从正态分布N(Reward(Action), 1)
- 每次学习实验次数为500次
- 学习次数为500次
下图给出了随着实验次数的增加,Average Reward的变化图像:
后续请关注:https://blog.csdn.net/baidu_37355300/article/details/80869577
【RL系列】Multi-Armed Bandit问题笔记的更多相关文章
- 【RL系列】Multi-Armed Bandit笔记——UCB策略与Gradient策略
本篇主要是为了记录UCB策略与Gradient策略在解决Multi-Armed Bandit问题时的实现方法,涉及理论部分较少,所以请先阅读Reinforcement Learning: An Int ...
- 【RL系列】Multi-Armed Bandit笔记补充(一)
在此之前,请先阅读上一篇文章:[RL系列]Multi-Armed Bandit笔记 本篇的主题就如标题所示,只是上一篇文章的补充,主要关注两道来自于Reinforcement Learning: An ...
- 【RL系列】Multi-Armed Bandit笔记补充(二)
本篇的主题是对Upper Conference Bound(UCB)策略进行一个理论上的解释补充,主要探讨UCB方法的由来与相关公式的推导. UCB是一种动作选择策略,主要用来解决epsilon-gr ...
- 【RL系列】马尔可夫决策过程——状态价值评价与动作价值评价
请先阅读上两篇文章: [RL系列]马尔可夫决策过程中状态价值函数的一般形式 [RL系列]马尔可夫决策过程与动态编程 状态价值函数,顾名思义,就是用于状态价值评价(SVE)的.典型的问题有“格子世界(G ...
- 【RL系列】从蒙特卡罗方法步入真正的强化学习
蒙特卡罗方法给我的感觉是和Reinforcement Learning: An Introduction的第二章中Bandit问题的解法比较相似,两者皆是通过大量的实验然后估计每个状态动作的平均收益. ...
- 【RL系列】马尔可夫决策过程中状态价值函数的一般形式
请先阅读上一篇文章:[RL系列]马尔可夫决策过程与动态编程 在上一篇文章里,主要讨论了马尔可夫决策过程模型的来源和基本思想,并以MAB问题为例简单的介绍了动态编程的基本方法.虽然上一篇文章中的马尔可夫 ...
- 系列文章--Node.js学习笔记系列
Node.js学习笔记系列总索引 Nodejs学习笔记(一)--- 简介及安装Node.js开发环境 Nodejs学习笔记(二)--- 事件模块 Nodejs学习笔记(三)--- 模块 Nodejs学 ...
- 人工智能中小样本问题相关的系列模型演变及学习笔记(二):生成对抗网络 GAN
[说在前面]本人博客新手一枚,象牙塔的老白,职业场的小白.以下内容仅为个人见解,欢迎批评指正,不喜勿喷![握手][握手] [再啰嗦一下]本文衔接上一个随笔:人工智能中小样本问题相关的系列模型演变及学习 ...
- 【RL系列】MDP与DP问题
推荐阅读顺序: Reinforcement Learning: An Introduction (Drfit) 有限马尔可夫决策过程 动态编程笔记 Dynamic programming in Py ...
随机推荐
- Linux MySql5.6.38安装过程
1.下载mysql安装包mysql-5.6.38-linux-glibc2.12-x86_64.tar.gz 2.用xftp工具将其上传到Linux服务器上的soft文件夹,没有的话先创建 [root ...
- BigDecimalUtil 工具类
一.为什么要用BigDecimal? 涉及到加减乘除,用int,double 会出现数据丢失,这个时候就要用BigDecimal. 注意:在new BigDecimal(Double.toString ...
- hive遇到的问题以及解决办法
hive java.lang.ClassNotFoundException: Class org.apache.hive.hcatalog.data.JsonSerDe not found hadoo ...
- python+requests实现接口测试 - cookies的使用
在很多时候,发送请求后,服务端会对发送请求方进行身份识别,如果请求中缺少识别信息或存在错误的识别信息, 会造成识别失败. 如一些需要用户登录以后才能访问的页面. import requests mya ...
- 论文笔记 M. Saquib Sarfraz_Pose-Sensitive Embedding_re-ranking_2018_CVPR
1. 摘要 作者使用一个pose-sensitive-embddding,把姿态的粗糙.精细信息结合在一起应用到模型中. 用一个新的re-ranking方法,不需要重新计算新的ranking列表,是一 ...
- B. Vile Grasshoppers
http://codeforces.com/problemset/problem/937/B The weather is fine today and hence it's high time to ...
- MHA实践操作
1.MHA部署解读: 1.1MHA Manager可以部署在一台slave上.MHA Manager探测集群的node节点,当发现master出现故障的时候,它可以自动将具有最新数据的slave提升为 ...
- gitblit-1.8.0域认证
gitblit-1.8.0\data\defaults.properties # # DEFAULTS.PROPERTIES # # The default Gitblit settings. # # ...
- PCB布线经验
查看: 3645|回复: 11 [经验] PCB设计经验(1)——布局基本要领 [复制链接] ohahaha 927 TA的帖子 0 TA的资源 纯净的硅(中级) 发消息 加好友 电 ...
- 用java数组模拟购物商城功能与实现
实体类1(商品): package mall.model; public class goods { private int shoppingID; // 商品编号 private String sh ...