深度学习GPU集群管理软件 OpenPAI 简介
OpenPAI:大规模人工智能集群管理平台
2018年5月22日,在微软举办的“新一代人工智能开放科研教育平台暨中国高校人工智能科研教育高峰论坛”上,微软亚洲研究院宣布,携手北京大学、中国科学技术大学、西安交通大学和浙江大学四所国内顶尖高校共建新一代人工智能开放科研教育平台,以推动中国人工智能领域科研与教育事业的发展。作为由微软亚洲研究院为该平台提供的三大关键技术之一,Open Platform for AI(OpenPAI)也备受瞩目。
事实上,随着人工智能技术的快速发展,各种深度学习框架层出不穷,为了提高效率,更好地让人工智能快速落地,很多企业都很关注深度学习训练的平台化问题。例如,如何提升GPU等硬件资源的利用率?如何节省硬件投入成本?如何支持算法工程师更方便的应用各类深度学习技术,从繁杂的环境运维等工作中解脱出来?等等。
为了解决这些问题,微软亚洲研究院和微软(亚洲)互联网工程院基于各自的特长,联合研发、创建了OpenPAI,希望为深度学习提供一个深度定制和优化的人工智能集群管理平台,让人工智能堆栈变得简单、快速、可扩展。
为什么要使用OpenPAI?
● 为深度学习量身定做,可扩展支撑更多AI和大数据框架
通过创新的PAI运行环境支持,几乎所有深度学习框架如CNTK、TensorFlow、PyTorch等无需修改即可运行;其基于Docker的架构则让用户可以方便地扩展更多AI与大数据框架。
● 容器与微服务化,让AI流水线实现DevOps
OpenPAI 100%基于微服务架构,让AI平台以及开发便于实现DevOps的开发运维模式。
● 支持GPU多租,可统筹集群资源调度与服务管理能力
在深度学习负载下,GPU逐渐成为资源调度的一等公民,OpenPAI提供了针对GPU优化的调度算法,丰富的端口管理,支持Virtual Cluster多租机制,可通过Launcher Server为服务作业的运行保驾护航。
● 提供丰富的运营、监控、调试功能,降低运维复杂度
PAI为运营人员提供了硬件、服务、作业的多级监控,同时开发者还可以通过日志、SSH等方便调试作业。
● 兼容AI开发工具生态
平台实现了与Visual Studio Tools for AI等开发工具的深度集成,用户可以一站式进行AI开发。
OpenPAI架构与功能简介
OpenPAI是由微软亚洲研究院和微软(亚洲)互联网工程院联合研发的,支持多种深度学习、机器学习及大数据任务,可提供大规模GPU集群调度、集群监控、任务监控、分布式存储等功能,且用户界面友好,易于操作。
OpenPAI的架构如下图所示,用户通过Web Portal调用REST Server的API提交作业(Job)和监控集群,其它第三方工具也可通过该API进行任务管理。随后REST Server与Launcher交互,以执行各种作业,再由Launcher Server处理作业请求并将其提交至Hadoop YARN进行资源分配与调度。可以看到,OpenPAI给YARN添加了GPU支持,使其能将GPU作为可计算资源调度,助力深度学习。其中,YARN负责作业的管理,其它静态资源(下图蓝色方框所示)则由Kubernetes进行管理。
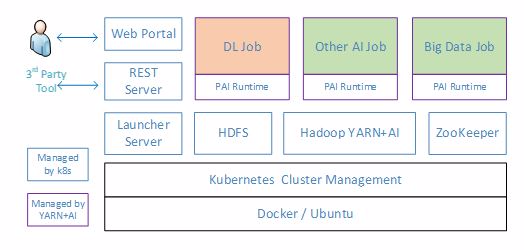
OpenPAI架构
OpenPAI完全基于微服务架构,所有的OpenPAI服务和AI Job均在容器中运行,这样的设计让OpenPAI的部署更加简单,无论是在Ubuntu裸机集群还是在云服务器上,仅需运行几个脚本即可完成部署。这同时也使其能够支持多种不同类型的AI任务,如CNTK、TensorFlow、PyTorch等不同的深度学习框架。此外,用户通过自定义Job容器即可支持新的深度学习框架和其他机器学习、大数据等AI任务,具有很强的扩展性。
在运维方面,OpenPAI提供了AI任务在线调试、错误报警、日志管理、性能检测等功能,显著降低了AI平台的日常运维难度。同时,它还支持MPI、RDMA网络,可满足企业对大规模深度学习任务的性能要求。
不仅如此,OpenPAI还实现了与Visual Studio的集成。Visual Studio Tools for AI是微软Visual Studio 2017 IDE的扩展,用户在Visual Studio中就可以开发、调试和部署深度学习和AI解决方案。集成后,用户在Visual Studio中调试好的模型可便捷地部署到OpenPAI集群中。

任务部署成功后Visual Studio中的任务列表概览
运行管理界面
OpenPAI提供了友好的用户界面,操作简单,便于用户进行集群监控、任务提交等。例如,主界面上显示了集群的GPU利用率、节点总数、CPU利用率、网络状况等。当某项数据异常时,OpenPAI将启动报警机制通知用户,并在UI上以颜色改变的形式进行提醒(如变成红色等)。
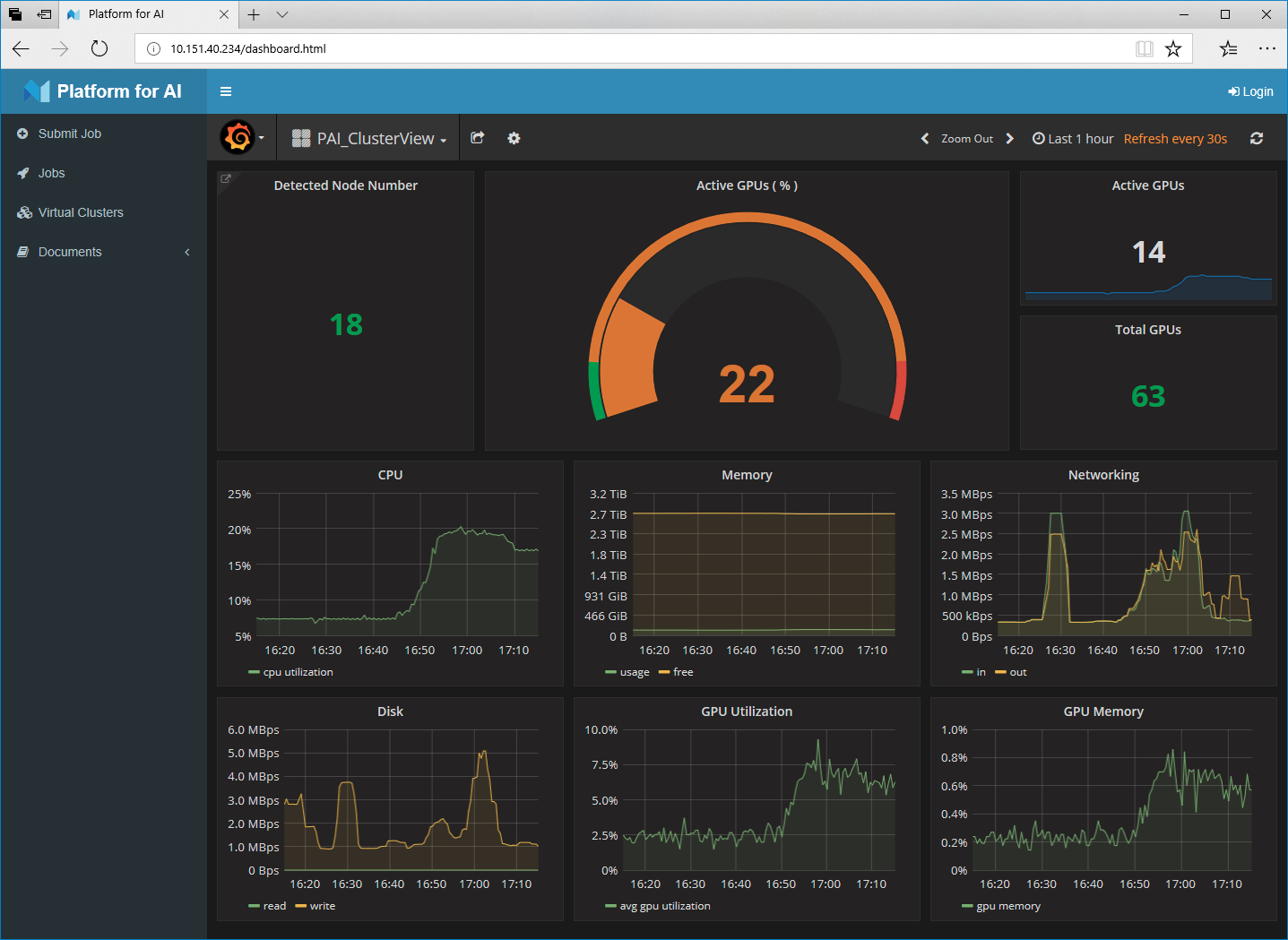
OpenPAI主界面
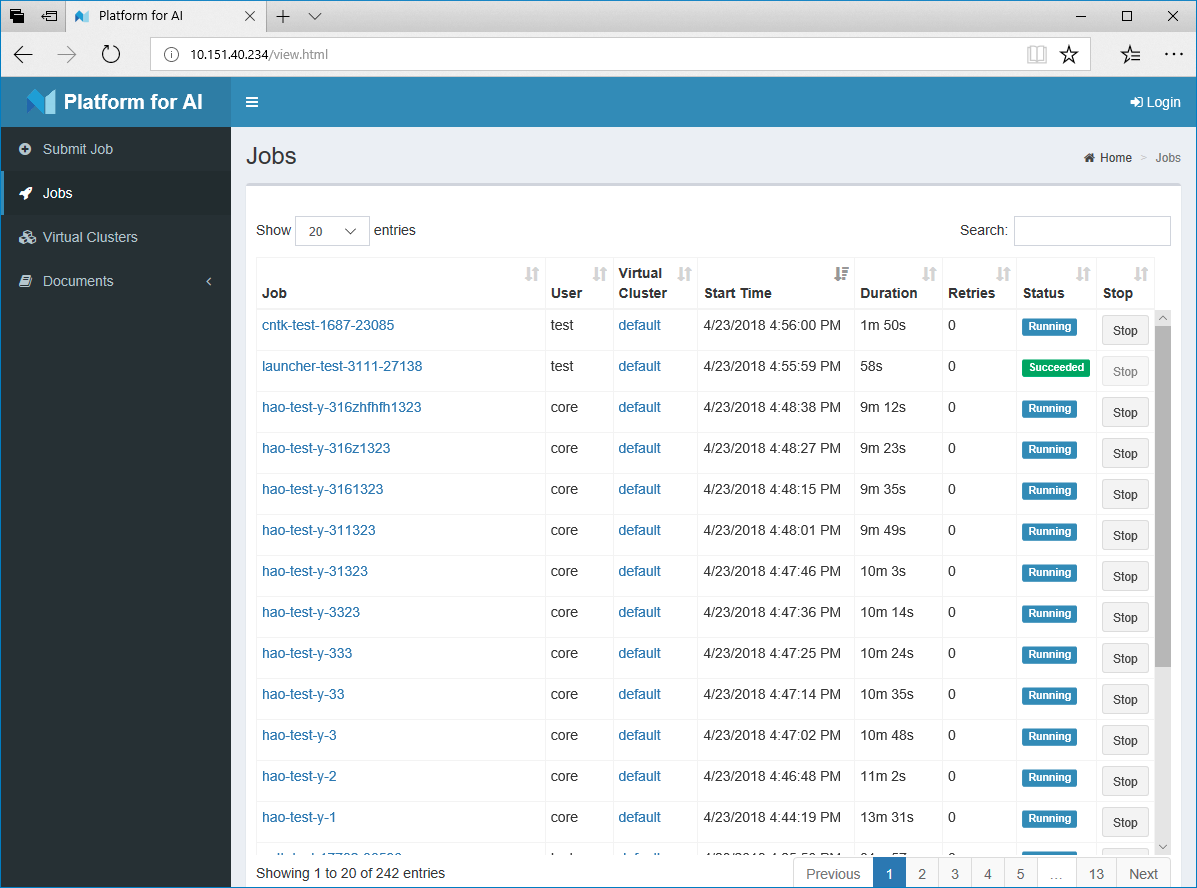
集群Job概览,点击Job名称可以查看详细信息及日志信息
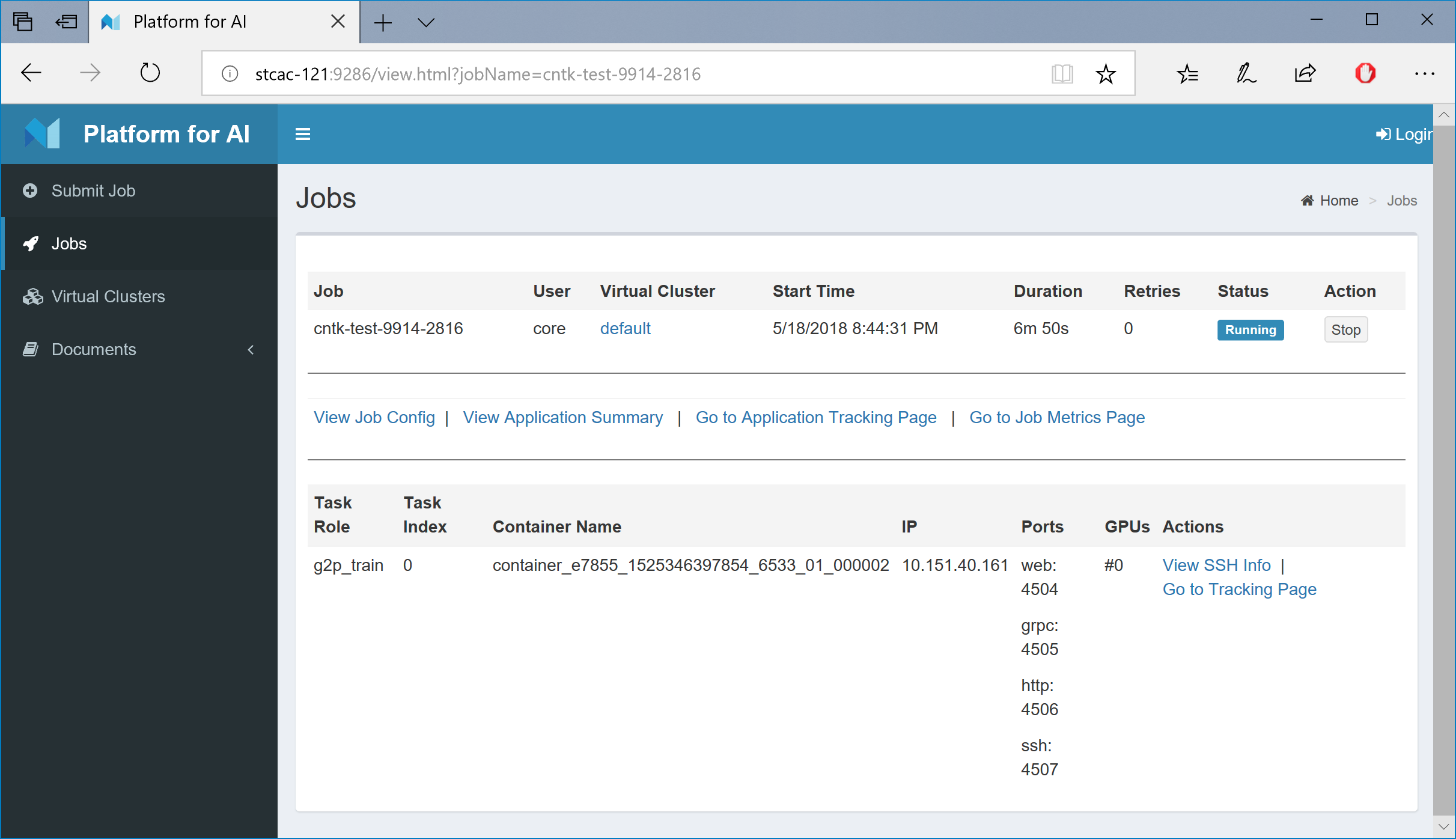
Job运行状态页显示容器的IP地址、端口和GPU位置,该页面还提供远程SSH登录容器的信息
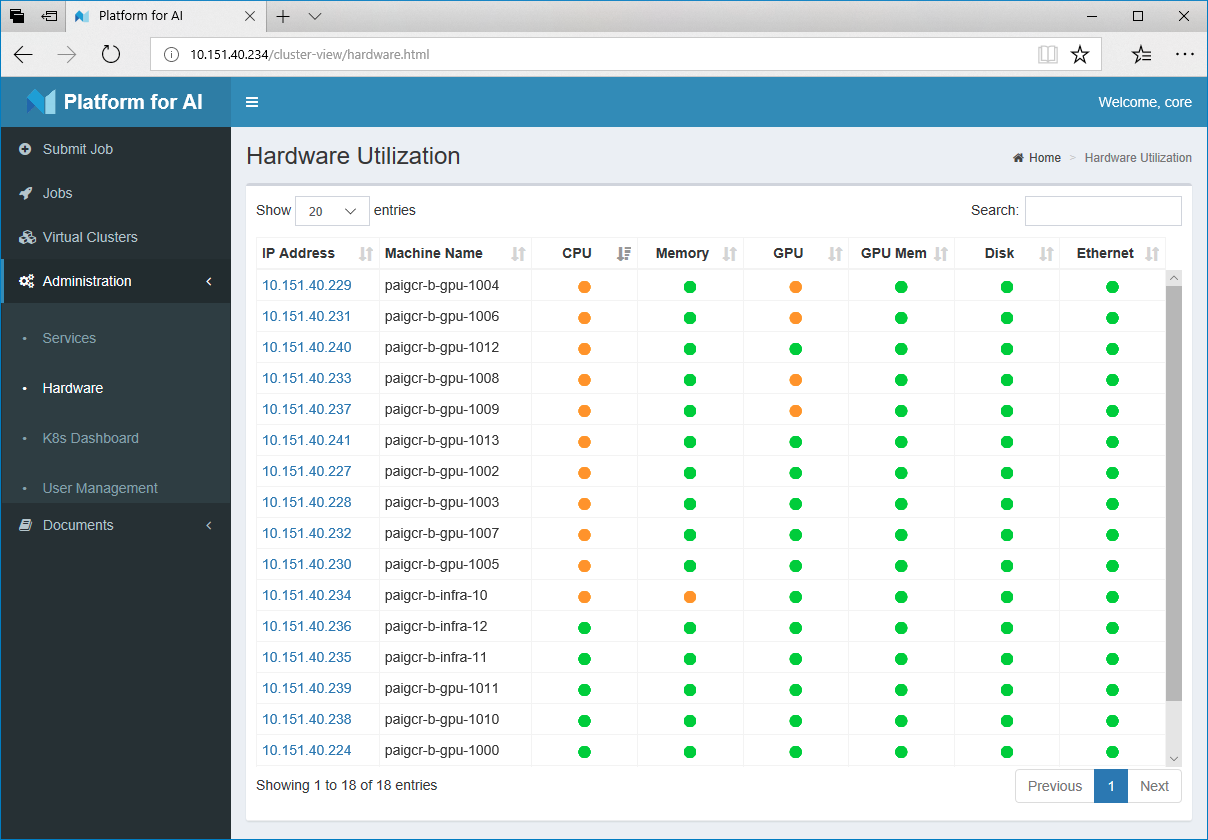
集群中机器运行状况概览,不同颜色展现了不同的忙闲程度
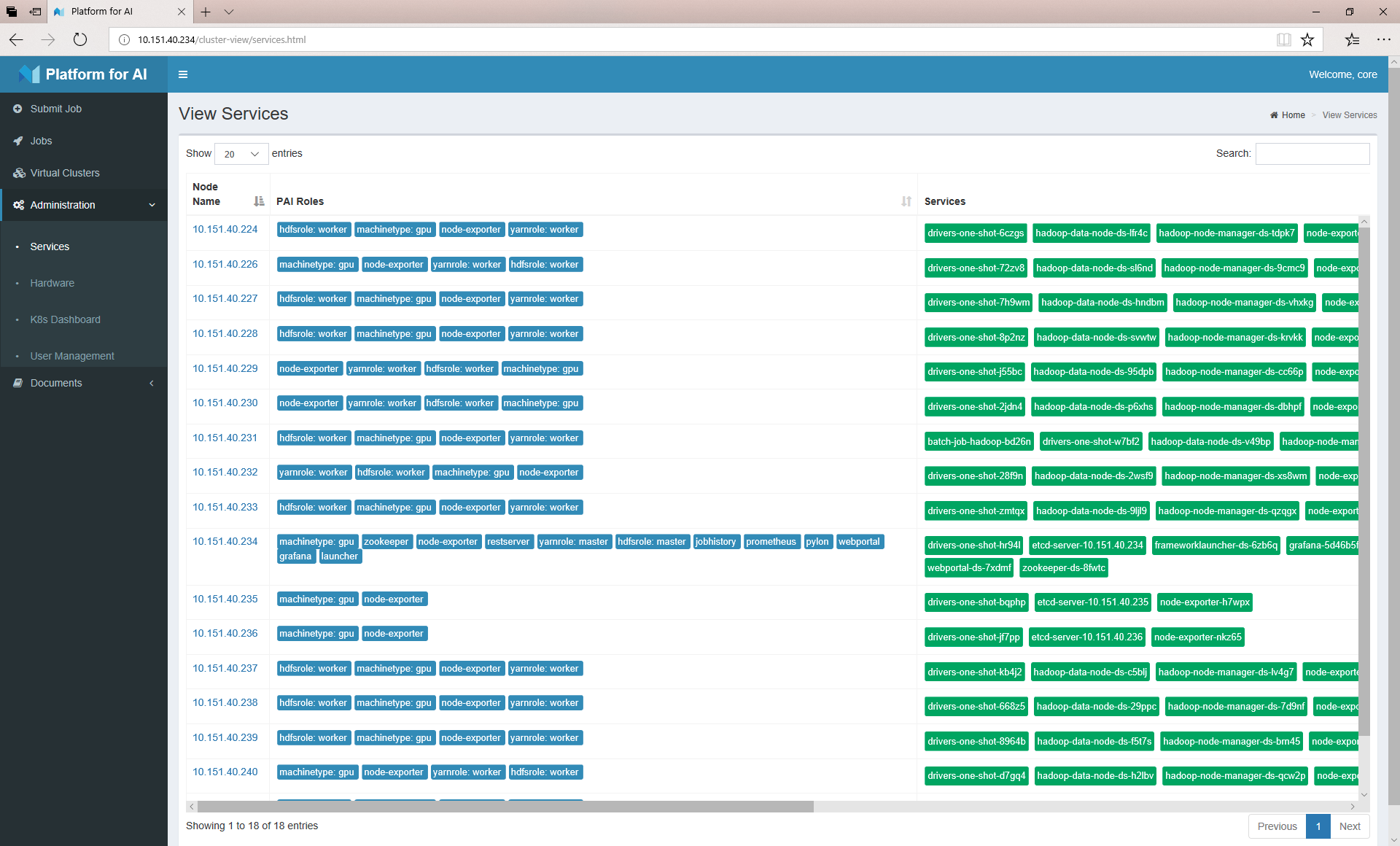
集群中每台机器上的Service运行状况
入门教程
OpenPAI部署
平台部署主要分为以下几个步骤:
1. 编译支持GPU调度的Hadoop AI容器,详见https://github.com/Microsoft/pai/blob/master/hadoop-ai/README.md
2. 部署Kubernetes以及系统服务(如drivers、zookeeper、REST Server等)。详见https://github.com/Microsoft/pai/blob/master/pai-management/README.md
3. 访问Web Portal进行任务提交和集群管理。
提交深度学习Job示例
1. 将你的数据和代码上传至HDFS:
如用hdfs命令行将数据上传至hdfs://host:port/path/tensorflow-distributed-jobguid/data
2. 准备Job配置文件:(详见https://github.com/Microsoft/pai/tree/master/job-tutorial)

3. 浏览Web Portal,点击"Submit Job"上传配置文件,即可提交你的Job。
想要体验、了解OpenPAI,请访问:https://github.com/Microsoft/pai
深度学习GPU集群管理软件 OpenPAI 简介的更多相关文章
- 轻量级集群管理软件-Ansible
ansible概述和运行机制 ansible概述 Ansible是一款为类Unix系统开发的自由开源的配置和自动化工具, 它用Python写成,类似于saltstack和Puppet,但是有一个不同 ...
- 轻量级集群管理软件-ClusterShell
如果集群数量不多的话,选择一个轻量级的集群管理软件就显得非常有必要了.ClusterShell就是这样一种小的集群管理工具,原理是利用ssh,可以说是Linux系统下非常好用的运维工具 cluste ...
- 集群管理软件clustershell
一.简介 1.安装方便.一条指令就能轻松安装. 2.配置方便.很多集群管理软件都需要在所有的服务器上都安装软件,而且还要进行很多的连接操作,clustershell就相当的方便了,仅仅需要所有机器能够 ...
- 运维利器-ClusterShell集群管理操作记录
在运维实战中,如果有若干台数据库服务器,想对这些服务器进行同等动作,比如查看它们当前的即时负载情况,查看它们的主机名,分发文件等等,这个时候该怎么办?一个个登陆服务器去操作,太傻帽了!写个shell去 ...
- Clustershell集群管理
在运维实战中,如果有若干台数据库服务器,想对这些服务器进行同等动作,比如查看它们当前的即时负载情况,查看它们的主机名,分发文件等等,这个时候该怎么办?一个个登陆服务器去操作,太傻帽了!写个shell去 ...
- 运维利器-ClusterShell集群管理
在运维实战中,如果有若干台数据库服务器,想对这些服务器进行同等动作,比如查看它们当前的即时负载情况,查看它们的主机名,分发文件等等,这个时候该怎么办?一个个登陆服务器去操作,太傻帽了!写个shell去 ...
- 集群管理工具Salt
集群管理工具Salt 简介 系统管理员(SA)通常需要管理和维护数以百计的服务器,如果没有自动化的配置管理和命令执行工具,那么SA的工作将会变得很繁重.例如,要给集群中的每个服务器添加一个系统用户,那 ...
- OpenPAI:大规模人工智能集群管理平台介绍及任务提交指南
产品渊源: 随着人工智能技术的快速发展,各种深度学习框架层出不穷,为了提高效率,更好地让人工智能快速落地,很多企业都很关注深度学习训练的平台化问题.例如,如何提升GPU等硬件资源的利用率?如何节省硬件 ...
- 学习笔记(4)——实验室集群管理结点IP配置
经过验证,集群管理结点mgt的IP配置应为如下所示: [root@mgt zmq]# ifconfig//外部网卡 eth0 Link encap:Ethernet HWaddr 5C:F3:FC:E ...
随机推荐
- javascript中创建对象的几种不同方法
javascript中创建对象的几种不同方法 方法一:最直白的方式:字面量模式创建 <script> var person={ name:"小明", age:20, s ...
- python 把一文件包含中文的字符写到另外文件乱码 UnicodeDecodeError: 'gbk' codec can't decode byte 0xac in position
报错的代码是: file2 = open('target.txt','w')for line in open('test.txt'): file2.write(line)原因:文件编码不一致导致解决方 ...
- mongodb与关系型数据库优缺点比较
1.与关系型数据库相比,MongoDB的优点:①弱一致性(最终一致),更能保证用户的访问速度②文档结构的存储方式,能够更便捷的获取数据③内置GridFS,支持大容量的存储.④内置Sharding.⑤第 ...
- 13-hadoop-入门程序
通过之前的操作, http://www.cnblogs.com/wenbronk/p/6636926.html http://www.cnblogs.com/wenbronk/p/6659481.ht ...
- linux文件 面试知识
1. 文件存储结构 Linux正统的文件系统(如ext2.ext3)中,一个文件由目录项.inode和数据块组成. 目录项:包括文件名和inode节点号. inode:又称文件索引节点, ...
- 面试题6:二叉树最近公共节点(LCA)《leetcode236》
Lowest Common Ancestor of a Binary Tree(二叉树的最近公共父亲节点) Given a binary tree, find the lowest common an ...
- [作业] Python入门基础--三级菜单
用字典存储数据 可以随时返回上一级,随时退出程序 只能用循环判断等内置方法,不得导入模块 menu = { '广东':{ '广州':{ '越秀区':{ '面积':'33.80', '人口':'115万 ...
- ES6新特性:var与let区别
1.let的用法类似于var,但是所声明的变量,只在let命令所在的代码块内有效.var定义的变量为全局变量. 2.var在同一块可以重复定义,let不能 //正常 function () { var ...
- 机器学习classification_report方法及precision精确率和recall召回率 说明
classification_report简介 sklearn中的classification_report函数用于显示主要分类指标的文本报告.在报告中显示每个类的精确度,召回率,F1值等信息. 主要 ...
- Java基础之Object类
类Object是类层次结构的根类.每个类都直接或者间接地继承Object类.所有对象(包括数组)都实现这个类的方法.Object类中的构造方法只有一个,并且是无参构造方法,这说明每个类中默认的无参构造 ...