对HashMap的理解(三):ConcurrentHashMap
HashMap不是线程安全的。在并发插入元素的时候,有可能出现环链表,让下一次读操作出现死循环。
避免HashMap的线程安全问题有很多方法,比如改用HashTable或Collections.synchronizedMap. (Hashtable是对hashmap中的方法加上了Synchronize,会锁定整个map)
但这两者有着共同的问题:性能。无论读操作还是写操作,它们都会给整个集合加锁,导致同一时间的其他操作为之阻塞。如图。
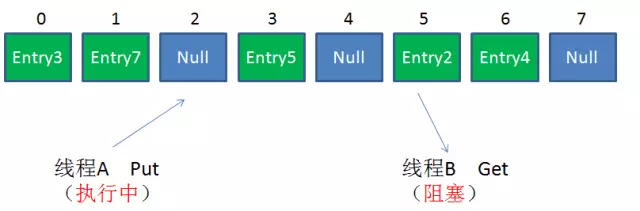
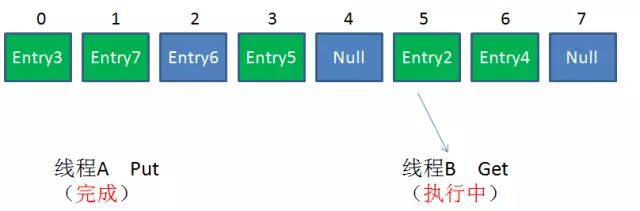
HashTable容器使用synchronized来保证线程安全,但在线程竞争激烈的情况下,HashTable的效率非常低。因为当一个线程访问HashTable的同步方法,其他线程也访问HashTable的同步方法时,会进入阻塞或轮询状态。如线程1使用put进行元素添加,线程2不但不能使用put方法添加元素,也不能使用get方法来获取元素,所以竞争越激烈效率越低。
那么在并发环境下,如何能够兼顾线程安全和运行效率呢?这时候ConcurrentHashMap就应运而生了。ConcurrentHashMap的锁分段技术可有效提升并发访问率
Hashtable容器在竞争激烈的并发环境下表现出效率低下的原因是所有访问HashTable的线程都必须竞争同一把锁。假如容器里有多把锁,每一把锁用于锁容器中的一部分数据,那么当多线程访问容器里不同数据段的数据时,线程之间就不会存在锁竞争,从而可以有效提高并发访问效率,这就是ConcurrentHashMap所使用的锁分段技术。首先将数据分成一段一段地存储,然后给每一段数据配一把锁,当一个线程占用锁访问其中一个数据段时,其他段的数据也能被其他线程访问。
对于ConcurrentHashMap,最关键的是要理解一个概念:Segment
Segment是什么呢?Segment本身就相当于一个HashMap对象。
同HashMap一样,Segment包含一个HashEntry数组,数组中的每一个HashEntry既是一个键值对,也是一个链表的头节点。
单一的Segment结构如下:
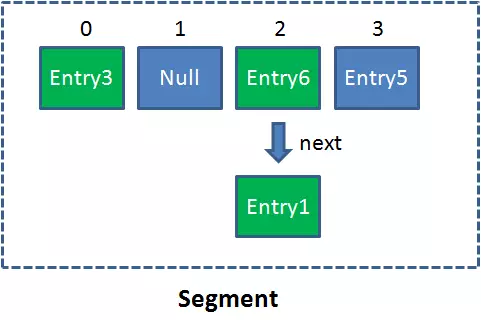
像这样的Segment对象,在ConcurrentHashMap集合中有多少个呢?有2的N次方个,共同保存在一个名为segments的数组当中。
因此整个ConcurrentHashMap的结构如下:
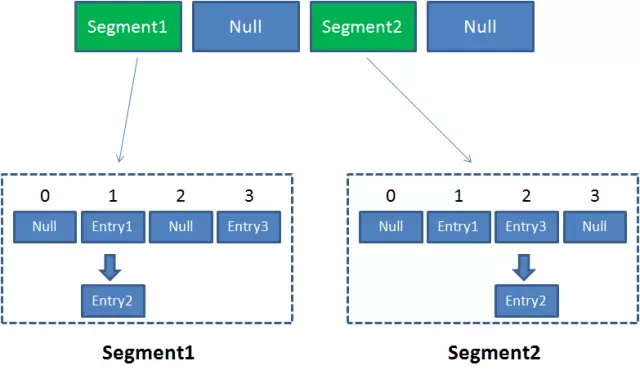
可以说,ConcurrentHashMap是一个二级哈希表。在一个总的哈希表下面,有若干个子哈希表。
这样的二级结构,和数据库的水平拆分有些相似。
每一个Segment就好比一个自治区,读写操作高度自治,Segment之间互不影响。
(一)、ConcurrentHashMap并发读写的几种情形:
Case1:不同Segment的并发写入
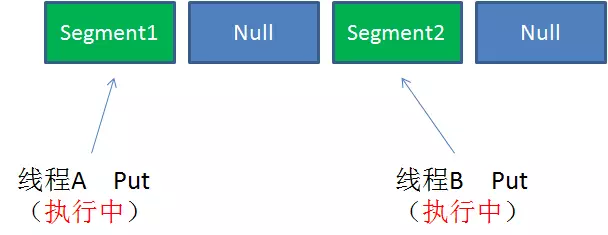
不同Segment的写入是可以并发执行的。
Case2:同一Segment的一写一读
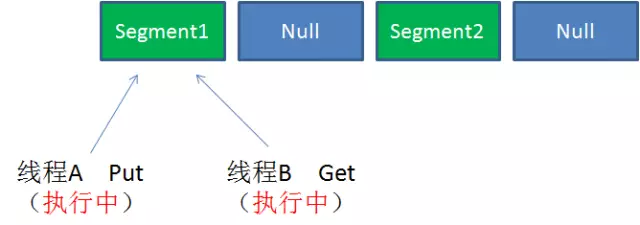
同一Segment的写和读是可以并发执行的。
Case3:同一Segment的并发写入
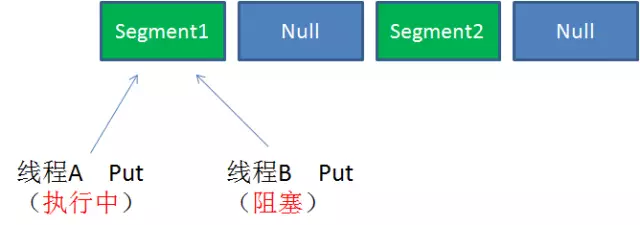
Segment的写入是需要上锁的,因此对同一Segment的并发写入会被阻塞。
由此可见,ConcurrentHashMap当中每个Segment各自持有一把锁。在保证线程安全的同时降低了锁的粒度,让并发操作效率更高。
(二)、ConcurrentHashMap读写的详细过程:
Get方法:
1.为输入的Key做Hash运算,得到hash值。
2.通过hash值,定位到对应的Segment对象
3.再次通过hash值,定位到Segment当中数组的具体位置。
get操作的高效之处在于整个get过程不需要加锁,除非读到的值是空才会加锁重读。我们知道HashTable容器的get方法是需要加锁的,那么ConcurrentHashMap的get操作是如何做到不加锁的呢?原因是它的get方法里将要使用的共享变量都定义成volatile类型, 如用于统计当前Segement大小的count字段和用于存储值的HashEntry的value。 定义成volatile的变量, 能够在线程之间保持可见性, 能够被多线程同时读, 并且保证不会读到过期的值, 但是只能被单线程写(有一种情况可以被多线程写, 就是写入的值不依赖于原值),在get操作里只需要读不需要写共享变量count和value, 所以可以不用加锁。 之所以不会读到过期的值, 是因为根据Java内存模型的happen before原则, 对volatile字段的写入操作先于读操作, 即使两个线程同时修改和获取volatile变量, get操作也能拿到最新的值, 这是用volatile替换锁的经典应用场景。
Put方法:
1.为输入的Key做Hash运算,得到hash值
2.通过hash值,定位到对应的Segment对象
3.获取可重入锁
4.判断是否需要对Segment里的HashEntry数组进行扩容
5.再次通过hash值,定位到Segment当中数组的具体位置
6.插入或覆盖HashEntry对象
7.释放锁。
(1) 是否需要扩容
在插入元素前会先判断Segment里的HashEntry数组是否超过容量(threshold) , 如果超过阈值, 则对数组进行扩容。 值得一提的是, Segment的扩容判断比HashMap更恰当, 因为HashMap是在插入元素后判断元素是否已经到达容量的, 如果到达了就进行扩容, 但是很有可能扩容之后没有新元素插入, 这时HashMap就进行了一次无效的扩容。
(2) 如何扩容
在扩容的时候, 首先会创建一个容量是原来容量两倍的数组, 然后将原数组里的元素进行再散列后插入到新的数组里。 为了高效, ConcurrentHashMap不会对整个容器进行扩容, 而只对某个segment进行扩容。
从步骤可以看出,ConcurrentHashMap在读写时都需要二次定位。首先定位到Segment,之后定位到Segment内具体数组下标。
(三)、ConcurrentHashMap的size方法
既然每个Segment都各自加锁,那么在调用Size方法时,怎么解决一致性的问题呢?
Size方法的目的是统计ConcurrentHashMap的总元素数量, 自然需要把各个Segment内部的元素数量汇总起来。
但是,如果在统计Segment元素数量的过程中,已统计过的Segment瞬间插入新的元素,这时候该怎么办呢?

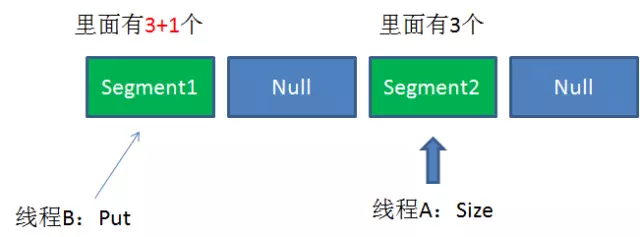

ConcurrentHashMap的Size方法是一个嵌套循环,大体逻辑如下:
1.遍历所有的Segment。
2.把Segment的元素数量累加起来。
3.把Segment的修改次数累加起来。
4.判断所有Segment的总修改次数是否大于上一次的总修改次数。如果大于,说明统计过程中有修改,重新统计,尝试次数+1;如果不是。说明没有修改,统计结束。
5.如果尝试次数超过阈值,则对每一个Segment加锁,再重新统计。
6.再次判断所有Segment的总修改次数是否大于上一次的总修改次数。由于已经加锁,次数一定和上次相等。
7.释放锁,统计结束。
这种思想和乐观锁悲观锁的思想如出一辙。
为了尽量不锁住所有Segment,首先乐观地假设Size过程中不会有修改。当尝试一定次数,才无奈转为悲观锁,锁住所有Segment保证强一致性。
参考:
《Java并发编程的艺术》
来自公众号:

对HashMap的理解(三):ConcurrentHashMap的更多相关文章
- HashMap、Hashtable、ConcurrentHashMap面试总结
原文链接:https://www.cnblogs.com/hexinwei1/p/10000779.html 小总结 HashMap.Hashtable.ConcurrentHashMap HashM ...
- [转帖]HashMap、HashTable、ConcurrentHashMap的原理与区别
HashMap.HashTable.ConcurrentHashMap的原理与区别 http://www.yuanrengu.com/index.php/2017-01-17.html 2017年1月 ...
- HashMap的扩容机制, ConcurrentHashMap和Hashtable主要区别
源代码查看,有三个常量, static final int DEFAULT_INITIAL_CAPACITY = 16; static final int MAXIMUM_CAPACITY = 1 & ...
- HashMap,Hashtable,ConcurrentHashMap 和 synchronized Map 的原理和区别
HashMap 是否是线程安全的,如何在线程安全的前提下使用 HashMap,其实也就是HashMap,Hashtable,ConcurrentHashMap 和 synchronized Map 的 ...
- Java集合——HashMap、HashTable以及ConCurrentHashMap异同比较
0. 前言 HashMap和HashTable的区别一种比较简单的回答是: (1)HashMap是非线程安全的,HashTable是线程安全的. (2)HashMap的键和值都允许有null存在,而H ...
- 集合类HashMap,HashTable,ConcurrentHashMap区别?
1.HashMap 简单来说,HashMap由数组+链表组成的,数组是HashMap的主体,链表则是主要为了解决哈希冲突而存在的,如果定位到的数组位置不含链表(当前entry的next指向null), ...
- HashMap,HashTable,ConcurrentHashMap的实现原理及区别
http://youzhixueyuan.com/concurrenthashmap.html 一.哈希表 哈希表就是一种以 键-值(key-indexed) 存储数据的结构,我们只要输入待查找的值即 ...
- HashMap和Hashtable以及ConcurrentHashMap的区别
HashMap和Hashtable的区别 何为HashMap HashMap是在JDK1.2中引入的Map的实现类. HashMap是基于哈希表实现的,每一个元素是一个key-value对,其内部 ...
- Java虚拟机内存溢出异常--《深入理解Java虚拟机》学习笔记及个人理解(三)
Java虚拟机内存溢出异常--<深入理解Java虚拟机>学习笔记及个人理解(三) 书上P39 1. 堆内存溢出 不断地创建对象, 而且保证创建的这些对象不会被回收即可(让GC Root可达 ...
- BEGINNING SHAREPOINT® 2013 DEVELOPMENT 第2章节--SharePoint 2013 App 模型概览 理解三个SharePoint 部署模型 Apps
BEGINNING SHAREPOINT® 2013 DEVELOPMENT 第2章节--SharePoint 2013 App 模型概览 理解三个SharePoint 部署模型 Apps ...
随机推荐
- Java多线程多个线程wait(),一个notify()唤醒,唤醒的顺序
package thread; public class ThreadWN implements Runnable { public String name; public String getNam ...
- javaweb学习2——HTTP协议
声明:本文只是自学过程中,记录自己不会的知识点的摘要,如果想详细学习JavaWeb,请到孤傲苍狼博客学习,JavaWeb学习点此跳转 本文链接:https://www.cnblogs.com/xdp- ...
- windows系统下构建Jenkins持续集成
环境准备 windows10+tomcat+python3.x(安装方法自行百度) 安装Jenkins 从https://jenkins.io/download/ 下载war包 将war包放到tomc ...
- 模拟websocket推送消息服务mock工具二
模拟websocket推送消息服务mock工具二 在上一篇博文中有提到<使用electron开发一个h5的客户端应用创建http服务模拟后端接口mock>使用electron创建一个模拟后 ...
- VM虚拟机安装CentOS 7.0添加jdk环境
虚拟机注册码 5A02H-AU243-TZJ49-GTC7K-3C61N 安装centos系统,网络类型选择桥接网络安装完成后vi /etc/sysconfig/network-scripts/ifc ...
- 2019网易笔试题C++--丰收
题目描述 又到了丰收的季节,恰好小易去牛牛的果园里游玩. 牛牛常说他多整个果园的每个地方都了如指掌,小易不太相信,所以他想考考牛牛. 在果园里有N堆苹果,每堆苹果的数量为ai,小易希望知道从左往右数第 ...
- Hbase RESTFul API创建namespace返回500
1.使用官方提供的/namespaces/namespace创建namespace失败,返回500,官方提供示例:/namespaces/namespace POST 创建一个新的namespace. ...
- 你也可以手绘二维码(二)纠错码字算法:数论基础及伽罗瓦域GF(2^8)
摘要:本文讲解二维码纠错码字生成使用到的数学数论基础知识,伽罗瓦域(Galois Field)GF(2^8),这是手绘二维码填格子理论基础,不想深究可以直接跳过.同时数论基础也是 Hash 算法,RS ...
- python-模拟掷骰子,两个筛子数据可视化
""" 作者:zxj 功能:模拟掷骰子,两个筛子数据可视化 版本:3.0 日期:19/3/24 """ import random impo ...
- 深度学习-tensorflow学习笔记(1)-MNIST手写字体识别预备知识
深度学习-tensorflow学习笔记(1)-MNIST手写字体识别预备知识 在tf第一个例子的时候需要很多预备知识. tf基本知识 香农熵 交叉熵代价函数cross-entropy 卷积神经网络 s ...