python多进程(三)
消息队列
使用multiprocessing里面的Queue来实现消息队列。
from multiprocessing import Queue
q = Queue
q.put(data)
data = q.get(data)
例子:
from multiprocessing import Queue, Process # 写数据的进程
def write(q):
for i in ['a','b','c','d']:
q.put(i) # 把消息放入队列
print ('put {0} to queue'.format(i)) # 读取数据的进程
def read(q):
while 1:
result = q.get() # 从队列中读取消息
print ("get {0} from queue".format(result)) def main():
# 父进程创建Queue,并传给各个子进程
q = Queue()
pw = Process(target=write,args=(q,)) # 使用多进程,传入的参数是消息队列
pr = Process(target=read,args=(q,))
pw.start() # 启动子进程,写入数据
pr.start() # 启动子进程,读取数据
pw.join() # 等待pw进程结束
pr.terminate() #停止
# 相当于join,等pr完成以后,while是一个死循环,这里强制结束,因为读取数据的进程应该是一直监听是否有数据产生,有就会去读取。 if __name__ == '__main__':
main() 结果:
put a to queue
get a from queue
put b to queue
get b from queue
put c to queue
get c from queue
put d to queue
get d from queue
使用multiprocessing里面的PIPE来实现消息队列。
import time
from multiprocessing import Pipe, Process # 发送消息的进程
def proc1(pipe):
for i in xrange(1, 10):
pipe.send(i)
print ("send {0} to pipe".format(i))
time.sleep(1) # 接收消息的进程
def proc2(pipe):
n = 9
while n > 0:
result = pipe.recv()
print ("recv {0} from pipe".format(result))
n -= 1 def main():
pipe = Pipe(duplex=False) # 设置半双工模式,p1只负责发送消息,p2只负责接收消息,pipe是一个tuple类型
p1 = Process(target=proc1, args=(pipe[1],))
p2 = Process(target=proc2, args=(pipe[0],)) #接收写0
p1.start()
p2.start()
p1.join()
p2.join()
pipe[0].close()
pipe[1].close() if __name__ == '__main__':
main() 结果:
send 1 to pipe
recv 1 from pipe
recv 2 from pipe
send 2 to pipe
send 3 to pipe
recv 3 from pipe
recv 4 from pipe
send 4 to pipe
send 5 to pipe
recv 5 from pipe
recv 6 from pipe
send 6 to pipe
recv 7 from pipe
send 7 to pipe
recv 8 from pipe
send 8 to pipe
send 9 to pipe
recv 9 from pipe
Python提供了Queue模块来专门实现消息队列
from multiprocessing import Queue
from threading import Thread
import time """
一个生产者和两个消费者,
采用多线程继承的方式,
一个消费偶数,一个消费奇数。
""" class Proceducer(Thread):
def __init__(self, queue):
super(Proceducer, self).__init__()
self.queue = queue def run(self):
try:
for i in xrange(1, 10):
print ("put {0} to queue".format(i))
self.queue.put(i)
except Exception as e:
print ("put data error")
raise e class Consumer_even(Thread):
def __init__(self, queue):
super(Consumer_even, self).__init__()
self.queue = queue def run(self):
try:
while not self.queue.empty(): # 判断队列是否为空
number = self.queue.get(block=True, timeout=3) # 从队列中获取消息,block=True表示阻塞,设置超时未3s
if number % 2 == 0: # 如果获取的消息是偶数
print("get {0} from queue EVEN, thread name is {1}".format(number, self.getName()))
else:
self.queue.put(number) # 如果获取的消息不是偶数,就接着把它放回队列中
time.sleep(1)
except Exception as e:
raise e class Consumer_odd(Thread):
def __init__(self, queue):
super(Consumer_odd, self).__init__()
self.queue = queue def run(self):
try:
while not self.queue.empty():
number = self.queue.get(block=True, timeout=3)
if number % 2 != 0: # 如果获取的消息是奇数
print("get {0} from queue ODD, thread name is {1}".format(number, self.getName()))
else:
self.queue.put(number)
time.sleep(1)
except Exception as e:
raise e def main():
queue = Queue()
p = Proceducer(queue=queue)
# 开始产生消息
print("开始产生消息")
p.start()
p.join() # 等待生产消息的进程结束
time.sleep(1) # 消息生产完成之后暂停1s
c1 = Consumer_even(queue=queue)
c2 = Consumer_odd(queue=queue) # 开始消费消息
print("开始消费消息")
c1.start()
c2.start()
c1.join()
c2.join()
print ("消息消费完成") if __name__ == '__main__':
main() 结果:
开始产生消息
put 1 to queue
put 2 to queue
put 3 to queue
put 4 to queue
put 5 to queue
put 6 to queue
put 7 to queue
put 8 to queue
put 9 to queue
开始消费消息
get 1 from queue ODD, thread name is Thread-3
get 2 from queue EVEN, thread name is Thread-2
get 3 from queue ODD, thread name is Thread-3
get 4 from queue EVEN, thread name is Thread-2
get 5 from queue ODD, thread name is Thread-3
get 6 from queue EVEN, thread name is Thread-2
get 7 from queue ODD, thread name is Thread-3
get 8 from queue EVEN, thread name is Thread-2
get 9 from queue ODD, thread name is Thread-3
消息消费完成
Celery异步分布式
什么是celery
几个概念
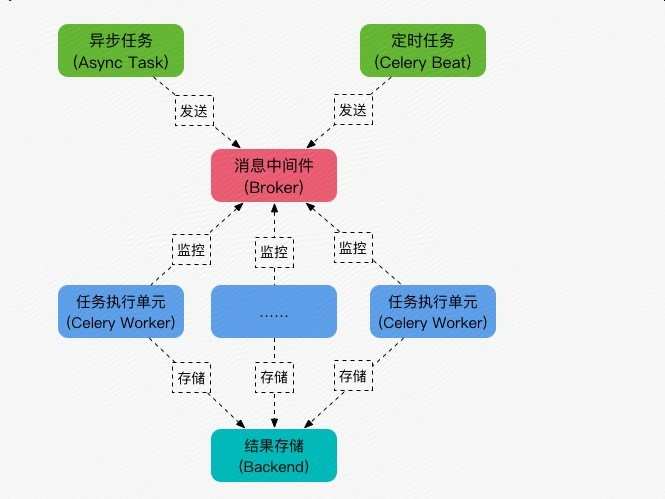
redis://:password@hostname:port/db_number
例如:
BROKER_URL = 'redis://localhost:6379/0'
安装celery
pip install celery
pip install redis
pip install redis-py-with-geo # 没有安装这个会报错 File "/usr/lib/python2.7/site-packages/kombu/transport/redis.py", line 671, in _receive
while c.connection.can_read(timeout=0):
TypeError: can_read() got an unexpected keyword argument 'timeout'
例子:
vi tasks.py
#/usr/bin/env python
#-*- coding:utf-8 -*-
from celery import Celery
broker="redis://110.106.106.220:5000/5"
backend="redis://110.106.106.220:5000/6"
app = Celery("tasks", broker=broker, backend=backend) @app.task
def add(x, y):
return x+y
现在broker、backend、task都有了,接下来我们就运行worker进行工作,在tasks.py目录运行:
celery -A tasks worker -l info
启动后可以看到如下信息:
[root@izwz920j4zsv1q15yhii1qz scripts]# celery -A celery_test worker -l info
/usr/lib/python2.7/site-packages/celery/platforms.py:796: RuntimeWarning: You're running the worker with superuser privileges: this is absolutely not recommended! Please specify a different user using the -u option. User information: uid=0 euid=0 gid=0 egid=0 uid=uid, euid=euid, gid=gid, egid=egid, -------------- celery@izwz920j4zsv1q15yhii1qz v4.1.1 (latentcall)
---- **** -----
--- * *** * -- Linux-3.10.0-693.2.2.el7.x86_64-x86_64-with-centos-7.4.1708-Core 2018-05-25 14:28:38
-- * - **** ---
- ** ---------- [config]
- ** ---------- .> app: celery_test:0x25a6450
- ** ---------- .> transport: redis://110.106.106.220:5000/5
- ** ---------- .> results: redis://110.106.106.220:5000/6
- *** --- * --- .> concurrency: 1 (prefork)
-- ******* ---- .> task events: OFF (enable -E to monitor tasks in this worker)
--- ***** -----
-------------- [queues]
.> celery exchange=celery(direct) key=celery [tasks]
. tasks.add [2018-05-25 14:28:38,431: INFO/MainProcess] Connected to redis://110.106.106.220:5000/5
[2018-05-25 14:28:38,443: INFO/MainProcess] mingle: searching for neighbors
[2018-05-25 14:28:39,475: INFO/MainProcess] mingle: all alone
[2018-05-25 14:28:39,528: INFO/MainProcess] celery@izwz920j4zsv1q15yhii1qz ready.
意思就是运行 tasks 这个任务集合的 worker 进行工作(当然此时broker中还没有任务,worker此时相当于待命状态),最后一步,就是触发任务,最简单方式就是再写一个脚本然后调用那个被装饰成 task 的函数。
vi trigger.py
from tasks import add
result = add.delay(4, 4) #不要直接 add(4, 4),这里需要用 celery 提供的接口 delay 进行调用
while not result.ready(): # 是否处理
time.sleep(1)
print 'task done: {0}'.format(result.get()) # 获取结果
print(result.task_id)
[root@izwz920j4zsv1q15yhii1qz scripts]# python trigger.py
task done: 8
celery-task-meta-d64def11-6b77-443f-84c2-0cbd850972f2
celery的任务状态
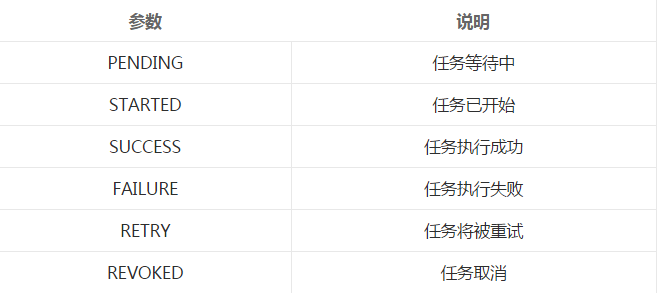
在之前启动tasks.py的窗口可以看到如下信息:
[2018-05-25 14:28:38,431: INFO/MainProcess] Connected to redis://110.106.106.220:5000/5
[2018-05-25 14:28:38,443: INFO/MainProcess] mingle: searching for neighbors
[2018-05-25 14:28:39,475: INFO/MainProcess] mingle: all alone
[2018-05-25 14:28:39,528: INFO/MainProcess] celery@izwz920j4zsv1q15yhii1qz ready.
[2018-05-25 14:33:30,340: INFO/MainProcess] Received task: tasks.add[d64def11-6b77-443f-84c2-0cbd850972f2]
[2018-05-25 14:33:30,373: INFO/ForkPoolWorker-1] Task tasks.add[d64def11-6b77-443f-84c2-0cbd850972f2] succeeded in 0.0313169739966s: 8
[2018-05-25 14:33:47,082: INFO/MainProcess] Received task: tasks.add[5ae26e89-5d91-496e-8e1c-e0504fbbd39a]
[2018-05-25 14:33:47,086: INFO/ForkPoolWorker-1] Task tasks.add[5ae26e89-5d91-496e-8e1c-e0504fbbd39a] succeeded in 0.00259069999447s: 8
在redis中查看:
110.106.106.220:5000[5]> select 5
OK
110.106.106.220:5000[5]> keys *
1) "_kombu.binding.celeryev"
2) "_kombu.binding.celery.pidbox"
3) "_kombu.binding.celery"
110.106.106.220:5000[5]> select 6
OK
110.106.106.220:5000[6]> keys *
1) "celery-task-meta-5ae26e89-5d91-496e-8e1c-e0504fbbd39a"
2) "celery-task-meta-d64def11-6b77-443f-84c2-0cbd850972f2"
110.106.106.220:5000[6]> get celery-task-meta-d64def11-6b77-443f-84c2-0cbd850972f2
"{\"status\": \"SUCCESS\", \"traceback\": null, \"result\": 8, \"task_id\": \"d64def11-6b77-443f-84c2-0cbd850972f2\", \"children\": []}"
110.106.106.220:5000[6]> get celery-task-meta-5ae26e89-5d91-496e-8e1c-e0504fbbd39a
"{\"status\": \"SUCCESS\", \"traceback\": null, \"result\": 8, \"task_id\": \"5ae26e89-5d91-496e-8e1c-e0504fbbd39a\", \"children\": []}"
python多进程(三)的更多相关文章
- Python多进程(1)——subprocess与Popen()
Python多进程方面涉及的模块主要包括: subprocess:可以在当前程序中执行其他程序或命令: mmap:提供一种基于内存的进程间通信机制: multiprocessing:提供支持多处理器技 ...
- python 多进程开发与多线程开发
转自: http://tchuairen.blog.51cto.com/3848118/1720965 博文作者参考的博文: 博文1 博文2 我们先来了解什么是进程? 程序并不能单独运行,只有将程 ...
- day-4 python多进程编程知识点汇总
1. python多进程简介 由于Python设计的限制(我说的是咱们常用的CPython).最多只能用满1个CPU核心.Python提供了非常好用的多进程包multiprocessing,他提供了一 ...
- Python 多进程multiprocessing
一.python多线程其实在底层来说只是单线程,因此python多线程也称为假线程,之所以用多线程的意义是因为线程不停的切换这样比串行还是要快很多.python多线程中只要涉及到io或者sleep就会 ...
- Python 多进程 多线程 协程 I/O多路复用
引言 在学习Python多进程.多线程之前,先脑补一下如下场景: 说有这么一道题:小红烧水需要10分钟,拖地需要5分钟,洗菜需要5分钟,如果一样一样去干,就是简单的加法,全部做完,需要20分钟:但是, ...
- python多进程详解
目录 python多进程 序.multiprocessing 一.Process process介绍 例1.1:创建函数并将其作为单个进程 例1.2:创建函数并将其作为多个进程 例1.3:将进程定义为 ...
- python多进程multiprocessing Pool相关问题
python多进程想必大部分人都用到过,可以充分利用多核CPU让代码效率更高效. 我们看看multiprocessing.pool.Pool.map的官方用法 map(func, iterable[, ...
- python 多进程数量 对爬虫程序的影响
1. 首先看一下 python 多进程的优点和缺点 多进程优点: 1.稳定性好: 多进程的优点是稳定性好,一个子进程崩溃了,不会影响主进程以及其余进程.基于这个特性,常常会用多进程来实现守护服务器的功 ...
- 取代 Python 多进程!伯克利开源分布式框架 Ray
Ray 由伯克利开源,是一个用于并行计算和分布式 Python 开发的开源项目.本文将介绍如何使用 Ray 轻松构建可从笔记本电脑扩展到大型集群的应用程序. 并行和分布式计算是现代应用程序的主要内容. ...
- 学习Python的三种境界
前言 王国维在<人间词话>中将读书分为了三种境界:"古今之成大事业.大学问者,必经过三种之境界:'昨夜西风凋碧树,独上高楼,望尽天涯路'.此第一境也.'衣带渐宽终不悔,为伊消得人 ...
随机推荐
- mvc中的action验证登录(ActionFilterAttribute)
方法一 : 1.创建一个全局action过滤器 (在appstart 的filterconfig中注册 filters.Add(new LoginAttribute());) 2.不需要登 ...
- Angular的第一个helloworld
在安装了node,npm,angular-cli,vscode之后,我们来创建一个angular的应用 创建第一个hello world 使用的IDE工具为vscode 打开vscode,打开一个命令 ...
- java SE 入门之控制语句&方法&递归算法(第五篇)
一 控制语句(选择结构) 在学习控制语句之前,我们要先明确两件事情,什么是顺序结构(也叫做顺序执行),什么是选择结构 (分支结构或分支执行或选择执行),我们的代码执行是分为先后顺序的,就像我们之前写的 ...
- C# 分页方法
using System;using System.Collections.Generic;using System.Linq;using System.Text;using System.Web; ...
- java设计模式-----13、组合模式
Composite模式也叫组合模式,是构造型的设计模式之一.通过递归手段来构造树形的对象结构,并可以通过一个对象来访问整个对象树. 组合(Composite)模式的其它翻译名称也很多,比如合成模式.树 ...
- javascript面向对象的常见写法与优缺点
我们通过表单验证的功能,来逐步演进面向对象的方式. 对于刚刚接触javascript的朋友来说,如果要写一个验证用户名,密码,邮箱的功能, 一般可能会这么写: //表单验证 var checkUs ...
- 网络编程: 基于TCP协议的socket, 实现一对一, 一对多通信
TCP协议 面向连接 可靠的 面向字节流形式的 tcp是基于链接的,必须先启动服务端,然后再启动客户端去链接服务端 TCP协议编码流程: 服务器端: 客户端 实例化对 ...
- php返回数组后处理(开户成功后弹窗提示)
1. 在注册的时候,注册成功后经常会弹窗提示自己注册的信息,这类做法需要返回mysql数据库中获取的数组值,返回给前台页面,赋值给弹窗. 2.做法: 返回数组 打印的数组的值 返回数组处理 赋值给弹窗 ...
- CSS 媒体查询创建响应式网站
使用 CSS 媒体查询创建响应式网站 适用于所有屏幕大小的设计 固定宽度的静态网站很快被灵活的响应式设计所取代,该设计可以根据屏幕大小进行上扩和下扩.利用响应式设计,无论您采用什么设备或屏幕来访问网 ...
- asp.net mvc +easyui 实现权限管理(二)
一写完后,好久没有继续写了.最近公司又在重新开发权限系统了,但是由于我人微言轻,无法阻止他们设计一个太监版的权限系统.想想确实是官大一级压死人啊, 没办法我只好不参与了 让他们去折腾. 我就大概说一下 ...