Linux性能监控分析命令(五)—free命令介绍
性能监控分析的命令包括如下:
1、vmstat
2、sar
3、iostat
4、top
5、free
6、uptime
7、netstat
8、ps
9、strace
10、lsof
命令介绍:
free命令是监控Linux内存使用最常用的命令
语法格式:
free [options]
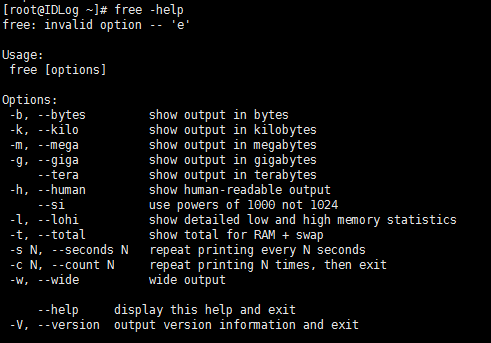
参数说明:
-m:以M为单位查看内容使用情况(默认为kb)
-b:以字节为单位查看内存使用情况
-s:可以在指定时间段内不间断监控内存使用情况
-k:以KB为单位显示内存使用情况
-g:以GB为单位显示内存使用情况
-o:不显示缓冲区调节列
-t:显示内存总和列
-V:显示版本信息
free命令执行结果如下:

各个字段说明:
total:总计物理内存的大小
used:已使用的大小
free:空闲可用的大小
shared:多个进程共享的内存总额
buffers/cached:磁盘缓存的大小
第三行(-/+ buffers/cache)
used:已使用多大
free:可用有多少
第四行是交换分区SWAP的,也就是我们通常所说的虚拟内存。
第二行与第三行used/free区别:
这两个的区别在于使用的角度来看,第一行是从OS的角度来看,因为对于OS,buffers/cached 都是属于被使用,所以他的可用内存是1651532KB,已用内存是287436KB,其中包括,内核(OS)使用+Application(X, oracle,etc)使用的+buffers+cached.
第三行所指的是从应用程序角度来看,对于应用程序来说,buffers/cached 是等于可用的,因为buffer/cached是为了提高文件读取的性能,当应用程序需在用到内存的时候,buffer/cached会很快地被回收。
所以从应用程序的角度来说,可用内存=系统free memory+buffers+cached。
如本机情况的可用内存为:
1864980=1651532KB+23688KB+760KB
我们使用total1、used1、free1、used2、free2 等名称来代表上面统计数据的各值
可以整理出如下等式:
total1 = used1 + free1
total1 = used2 + free2
used1 = buffers1 + cached1 + used2
free2 = buffers1 + cached1 + free1
cache 和 buffer的区别:
Cache: 高速缓存,是位于CPU与主内存间的一种容量较小但速度很高的存储器。由于CPU的速度远高于主内存,CPU直接从内存中存取数据要等待一定时间周 期,Cache中保存着CPU刚用过或循环使用的一部分数据,当CPU再次使用该部分数据时可从Cache中直接调用,这样就减少了CPU的等待时间,提 高了系统的效率。Cache又分为一级Cache(L1 Cache)和二级Cache(L2 Cache),L1 Cache集成在CPU内部,L2 Cache早期一般是焊在主板上,现在也都集成在CPU内部,常见的容量有256KB或512KB L2 Cache。
Buffer:缓冲区,一个用于存储速度不同步的设备或优先级不同的设备之间传输数据的区域。通过缓冲区,可以使进程之间的相互等待变少,从而使从速度慢的设备读入数据时,速度快的设备的操作进程不发生间断。
Free中的buffer和cache:(它们都是占用内存):
buffer: 作为buffer cache的内存,是块设备的读写缓冲区
cache: 作为page cache的内存, 文件系统的cache
如果 cache 的值很大,说明cache住的文件数很多。如果频繁访问到的文件都能被cache住,那么磁盘的读IO bi会非常小。
Buffers和Cached的区别
缓存(cached)是把读取过的数据保存起来,重新读取时若命中(找到需要的数据)就不要去读硬盘了,若没有命中就读硬盘。其中的数据会根据读取频率进行组织,把最频繁读取的内容放在最容易找到的位置,把不再读的内容不断往后排,直至从中删除。
缓冲(buffers)是根据磁盘的读写设计的,把分散的写操作集中进行,减少磁盘碎片和硬盘的反复寻道,从而提高系统性能。linux有一个守护进程定 期清空缓冲内容(即写如磁盘),也可以通过sync命令手动清空缓冲。举个例子吧:我这里有一个ext2的U盘,我往里面cp一个3M的MP3,但U盘的 灯没有跳动,过了一会儿(或者手动输入sync)U盘的灯就跳动起来了。卸载设备时会清空缓冲,所以有些时候卸载一个设备时要等上几秒钟。
修改/etc/sysctl.conf中的vm.swappiness右边的数字可以在下次开机时调节swap使用策略。该数字范围是0~100,数字越大越倾向于使用swap。默认为60,可以改一下试试。
两者都是RAM中的数据。简单来说,buffer是即将要被写入磁盘的,而cache是被从磁盘中读出来的。
buffer是由各种进程分配的,被用在如输入队列等方面,一个简单的例子如某个进程要求有多个字段读入,在所有字段被读入完整之前,进程把先前读入的字段放在buffer中保存。
cache经常被用在磁盘的I/O请求上,如果有多个进程都要访问某个文件,于是该文件便被做成cache以方便下次被访问,这样可提供系统性能。
接下来解释什么时候内存会被交换,以及按什么方交换:
当可用内存少于额定值的时候,就会开会进行交换;查看额定值的命令:
#cat /proc/meminfo

交换将通过三个途径来减少系统中使用的物理页面的个数:
1.减少缓冲与页面cache的大小,
2.将系统V类型的内存页面交换出去,
3.换出或者丢弃页面。(Application 占用的内存页,也就是物理内存不足)。
事实上,少量地使用swap是不是影响到系统性能的。
常用操作
free //以KB为单位,显式系统内存使用情况
free -ml -s 1 //每秒以M为单位,显式系统内存详细使用情况。
free -c 4 -s 2 //为KB为单位,每2秒显式系统内存使用情况,一共显示4次
free -t //以总和的形式显示内存的使用信息
free -s 10 //周期性的查询内存使用信息,每10s 执行一次命令
参考文档:
https://www.cnblogs.com/ggjucheng/archive/2012/01/08/2316438.html
https://www.cnblogs.com/peida/archive/2012/12/25/2831814.html
http://blog.csdn.net/hylongsuny/article/details/7742995
Linux性能监控分析命令(五)—free命令介绍的更多相关文章
- Linux性能监控分析命令(四)—top命令介绍
性能监控分析的命令包括如下: 1.vmstat 2.sar 3.iostat 4.top 5.free 6.uptime 7.netstat 8.ps 9.strace 10.lsof ======= ...
- Linux性能监控分析命令(三)—iostat命令介绍
性能监控分析的命令包括如下: 1.vmstat 2.sar 3.iostat 4.top 5.free 6.uptime 7.netstat 8.ps 9.strace 10.lsof 命令介绍: i ...
- Linux性能监控分析命令(二)—sar命令介绍
性能监控分析的命令包括如下: 1.vmstat 2.sar 3.iostat 4.top 5.free 6.uptime 7.netstat 8.ps 9.strace 10.lsof ======= ...
- linux性能监控分析及通过nmon_analyse生成分析报表
nmon是一款分析 AIX 和 Linux 性能的免费工具 nmon 工具还可以将相同的数据捕获到一个文本文件,便于以后对报告进行分析和绘制图形.输出文件采用电子表格的格式 (.csv). 性能介绍 ...
- 【转载】linux性能监控分析及通过nmon_analyse生成分析报表
转载地址:http://www.cnblogs.com/Lam7/p/6604832.html nmon是一款分析 AIX 和 Linux 性能的免费工具 nmon 工具还可以将相同的数据捕获到一个文 ...
- Linux性能监控分析命令(一)—vmstat命令详解
一.vmstat介绍 语法格式: vmstat [-V] [-n] [-S unit] [delay [count]] -V prints version. -n causes the headers ...
- Linux性能监控分析命令
vmstat sar iostat top free uptime netstat ps strace lsof
- Linux 性能监控分析
好文,参考 http://blog.csdn.net/hexieshangwang/article/details/47187185
- Linux性能监控与分析之--- CPU
Linux性能监控与分析之--- CPU 望月成三人关注 2016.07.25 18:16:12字数 1,576阅读 2,837 CPU性能指标 用户进程使用CPU的比率 系统进程使用CPU的比率 W ...
随机推荐
- OpenStack 监控解决方案
正如你们看到的那样,到目前为止(OpenStack Kilo),OpenStack自己的监控组件Telemetry并不是完美, 获取的监控数据以及制作出来的图表有时候让人匪夷所思,因其重点并不是监控而 ...
- 阿里云slb+https 实践操作练习
如果只是练习按照文档步骤逐步执行即可. 如果是业务需要,只供参考. 有道笔记链接->
- MyEclipse开发工具,当选中一个单词时,其他相同的单词会被高亮显示(选中/标记)
1.步骤: Window-->Preferences-->Java-->Editor-->Mark Occurremces下的 Mark Occurremces of the ...
- python基础学习之路No.3 控制流if,while,for
在学习编程语言的过程中,有一个很重要的东西,它就是判断,也可以称为控制流. 一般有if.while.for三种 ⭐if语句 if语句可以有一个通俗的解释,如果.假如 如果条件1满足,则…… 如果条件2 ...
- javaweb作业一
作业:Http全称叫什么?有什么特点?端口号是多少?超文本传输协议:(1)遵循请求/响应模型(2)http协议是一种无状态协议,请求/响应完成后,连接会断开.这时,服务器无法知道当前访问的用户是否是老 ...
- oracle数据库11g(11.2.0.1)安装报错:提示ins_ctx.mk编译错误。
https://blog.csdn.net/weixin_42967330/article/details/81668404
- 【LOJ】#2028. 「SHOI2016」随机序列
题解 我们发现只有从第一个往后数,用乘号联通的块是有贡献的 为什么,因为后面所有表达式 肯定会有 + ,还会有个-,贡献全都被抵消了 所以我们处理出前缀乘积,然后乘上表达式的方案数 答案就是\(\su ...
- 【51nod】1773 A国的贸易
题解 FWT板子题 可以发现 \(dp[i][u] = \sum_{i = 0}^{N - 1} dp[i - 1][u xor (2^i)] + dp[i - 1][u]\) 然后如果把异或提出来可 ...
- 【LOJ】#2031. 「SDOI2016」数字配对
题解 这个图是个二分图,因为如果有一个奇环的话,我们会发现一个数变成另一个数要乘上个数不同的质数,显然不可能 然后我们发现这个不是求最大流,而是问一定价值的情况下最大流是多少,二分一个流量,加上一条边 ...
- 【LOJ】#2290. 「THUWC 2017」随机二分图
题解 看了一眼觉得是求出图对图统计完美匹配的个数(可能之前做过这样模拟题弃疗了,一直心怀恐惧... 然后说是统计一下每种匹配出现的概率,也就是,当前左边点匹配状态为S,右边点匹配状态为T,每种匹配出现 ...