Spark编程环境搭建(基于Intellij IDEA的Ultimate版本)(包含Java和Scala版的WordCount)(博主强烈推荐)
福利 => 每天都推送
为什么,我要在这里提出要用Ultimate版本。
IDEA Community(社区版)再谈之无奈之下还是去安装旗舰版
IntelliJ IDEA的黑白色背景切换(Ultimate和Community版本皆通用)
使用 IntelliJ IDEA 导入 Spark 最新源码及编译 Spark 源代码
IDEA里如何多种方式打jar包,然后上传到集群
IntelliJ IDEA(Community版本)的下载、安装和WordCount的初步使用(本地模式和集群模式)
IntelliJ IDEA(Ultimate版本)的下载、安装和WordCount的初步使用(本地模式和集群模式)
基于Intellij IDEA搭建Spark开发环境搭——参考文档
参考文档http://spark.apache.org/docs/latest/programming-guide.html
操作步骤
a)创建maven 项目
b)引入依赖(Spark 依赖、打包插件等等)
基于Intellij IDEA搭建Spark开发环境—maven vs sbt
a)哪个熟悉用哪个
b)Maven也可以构建scala项目
基于Intellij IDEA搭建Spark开发环境搭—maven构建scala项目
参考文档http://docs.scala-lang.org/tutorials/scala-with-maven.html
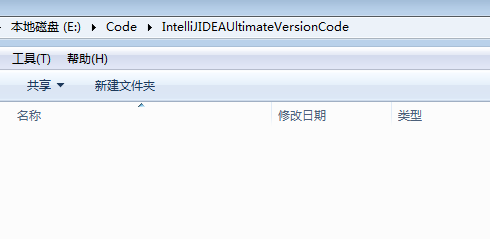
操作步骤
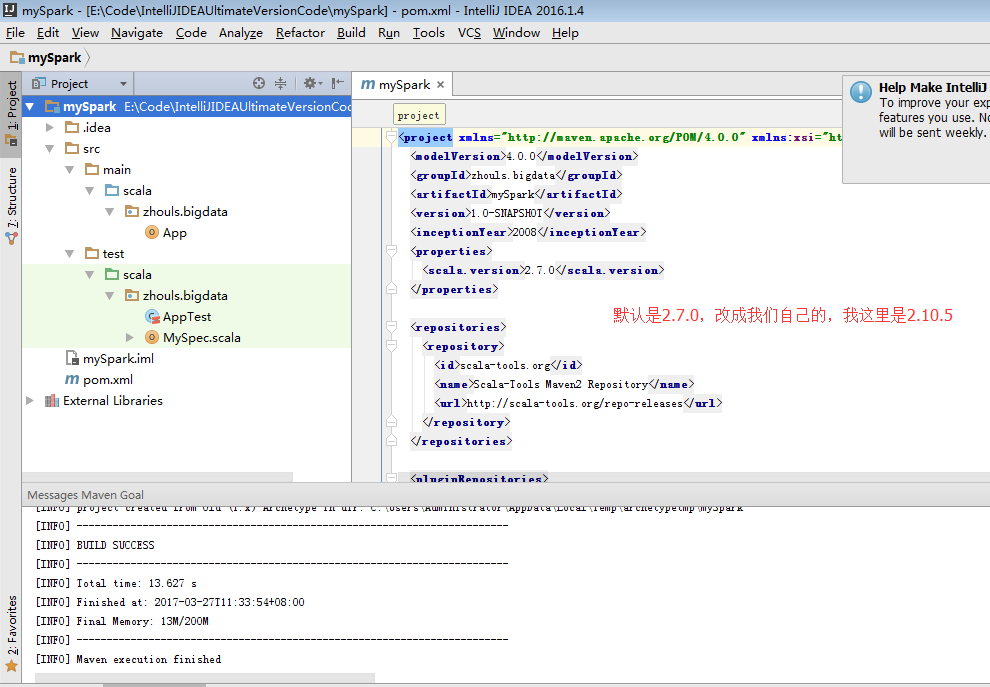
a) 用maven构建scala项目(基于net.alchim31.maven:scala-archetype-simple)
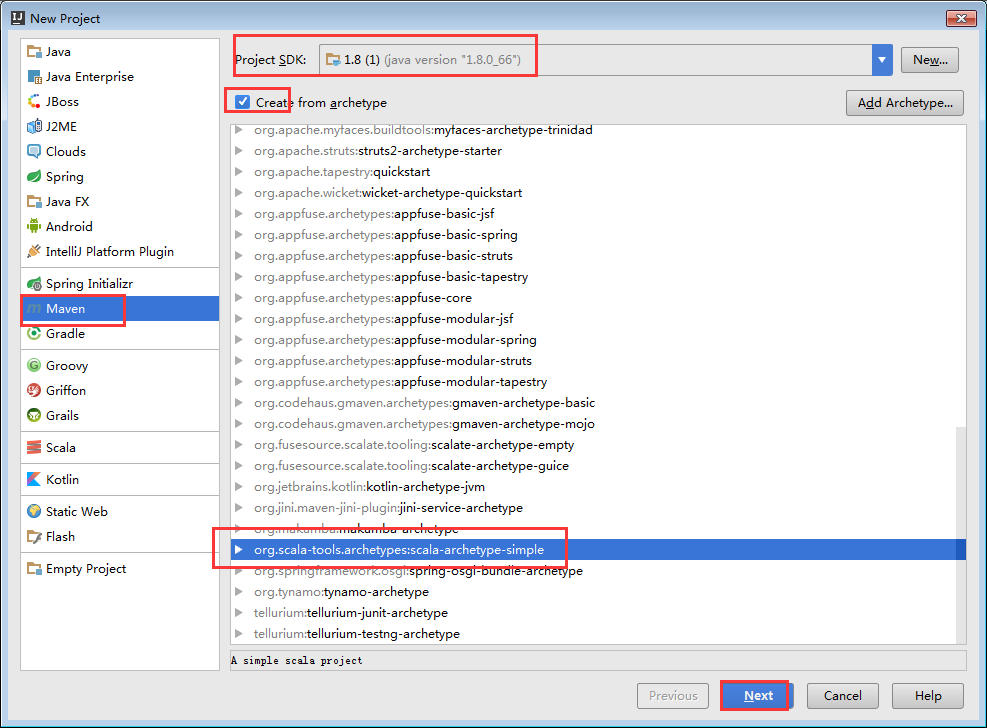

GroupId:zhouls.bigdata
ArtifactId:mySpark
Version:1.0-SNAPSHOT
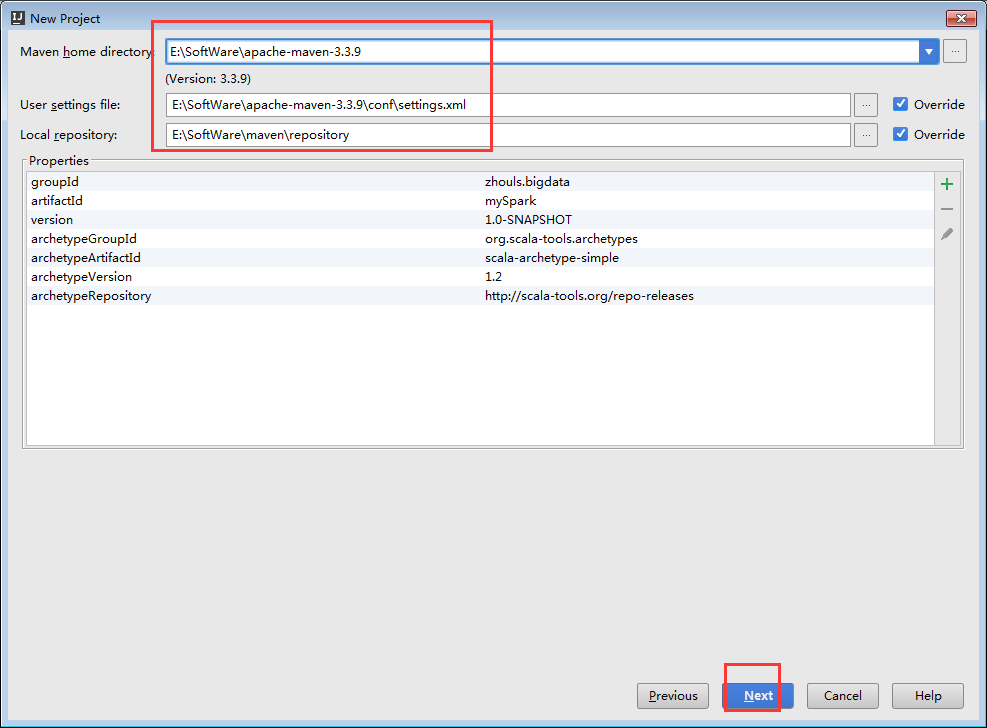

mySpark E:\Code\IntelliJIDEAUltimateVersionCode\mySpark
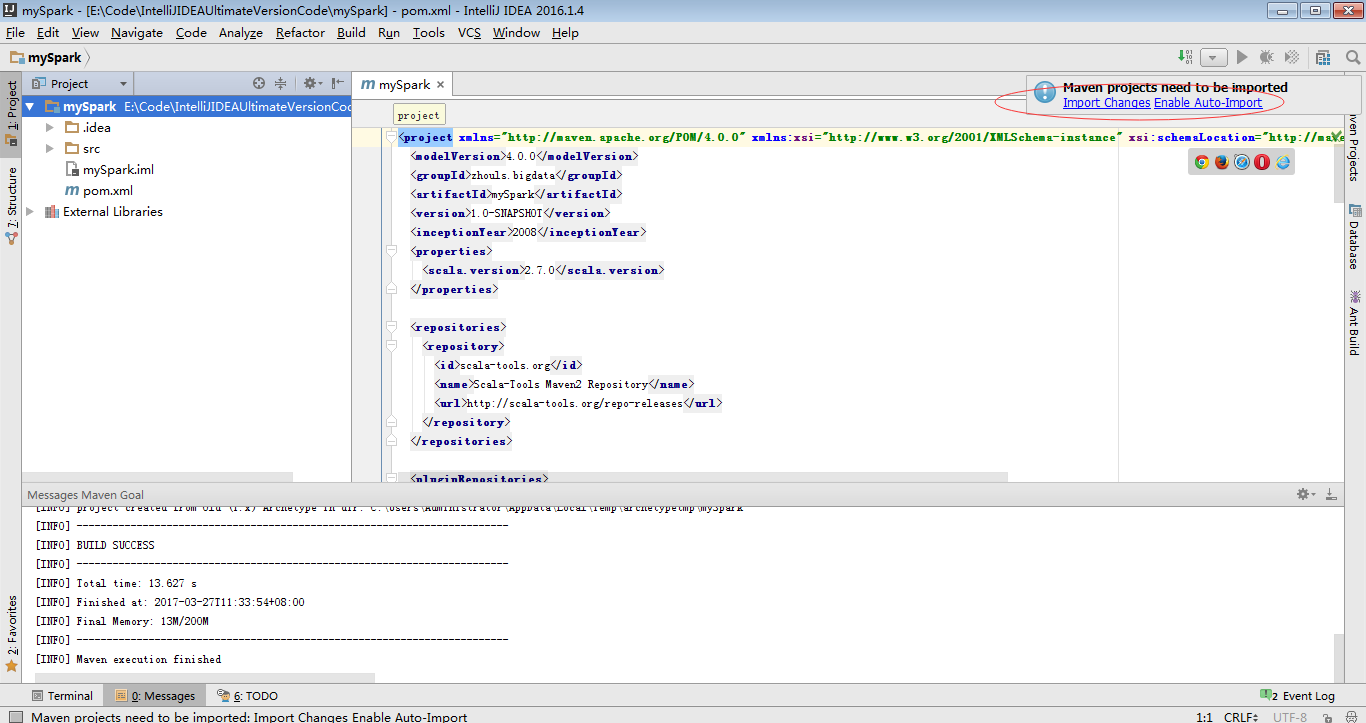
因为,我本地的scala版本是2.10.5
选中,delete就好。

其实,这个就是windows里的cmd终端,只是IDEA它把这个cmd终端集成到这了。
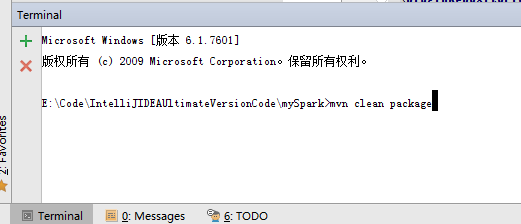
mvn clean package
这只是做个测试而已。
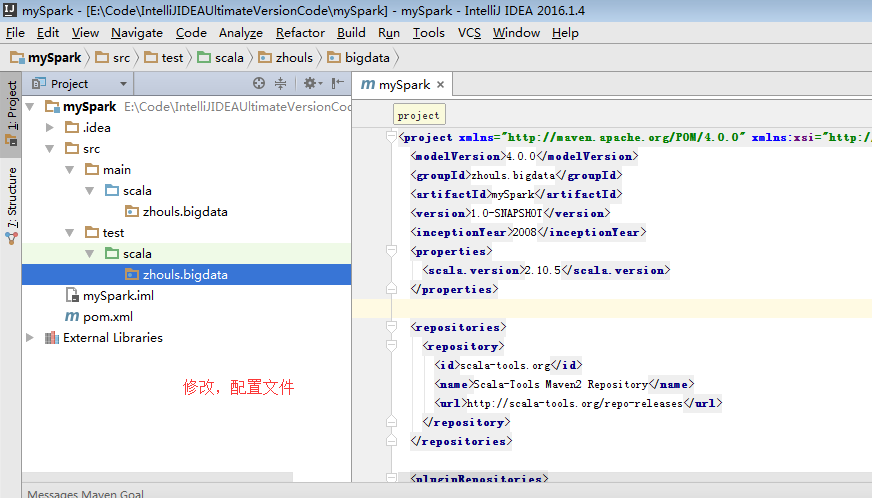
b)pom.xml引入依赖(spark依赖、打包插件等等)
注意:scala与java版本的兼容性
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd">
<modelVersion>4.0.</modelVersion>
<groupId>zhouls.bigdata</groupId>
<artifactId>mySpark</artifactId>
<version>1.0-SNAPSHOT</version>
<name>mySpark</name>
<inceptionYear></inceptionYear>
<properties>
<scala.version>2.10.</scala.version>
<spark.version>1.6.</spark.version>
</properties> <repositories>
<repository>
<id>scala-tools.org</id>
<name>Scala-Tools Maven2 Repository</name>
<url>http://scala-tools.org/repo-releases</url>
</repository>
</repositories> <pluginRepositories>
<pluginRepository>
<id>scala-tools.org</id>
<name>Scala-Tools Maven2 Repository</name>
<url>http://scala-tools.org/repo-releases</url>
</pluginRepository>
</pluginRepositories> <dependencies>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.4</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.specs</groupId>
<artifactId>specs</artifactId>
<version>1.2.</version>
<scope>test</scope>
</dependency>
<!--spark -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.</artifactId>
<version>${spark.version}</version>
<scope>provided</scope>
</dependency>
</dependencies> <build>
<!--
<sourceDirectory>src/main/scala</sourceDirectory>
<testSourceDirectory>src/test/scala</testSourceDirectory>
-->
<plugins>
<plugin>
<groupId>org.scala-tools</groupId>
<artifactId>maven-scala-plugin</artifactId>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
<configuration>
<scalaVersion>${scala.version}</scalaVersion>
<args>
<arg>-target:jvm-1.5</arg>
</args>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-eclipse-plugin</artifactId>
<configuration>
<downloadSources>true</downloadSources>
<buildcommands>
<buildcommand>ch.epfl.lamp.sdt.core.scalabuilder</buildcommand>
</buildcommands>
<additionalProjectnatures>
<projectnature>ch.epfl.lamp.sdt.core.scalanature</projectnature>
</additionalProjectnatures>
<classpathContainers>
<classpathContainer>org.eclipse.jdt.launching.JRE_CONTAINER</classpathContainer>
<classpathContainer>ch.epfl.lamp.sdt.launching.SCALA_CONTAINER</classpathContainer>
</classpathContainers>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>2.4.</version>
<executions>
<!-- Run shade goal on package phase -->
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<transformers>
<!-- add Main-Class to manifest file -->
<transformer
implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer">
<!--<mainClass>com.dajiang.MyDriver</mainClass>-->
</transformer>
</transformers>
<createDependencyReducedPom>false</createDependencyReducedPom>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
<reporting>
<plugins>
<plugin>
<groupId>org.scala-tools</groupId>
<artifactId>maven-scala-plugin</artifactId>
<configuration>
<scalaVersion>${scala.version}</scalaVersion>
</configuration>
</plugin>
</plugins>
</reporting>
</project>
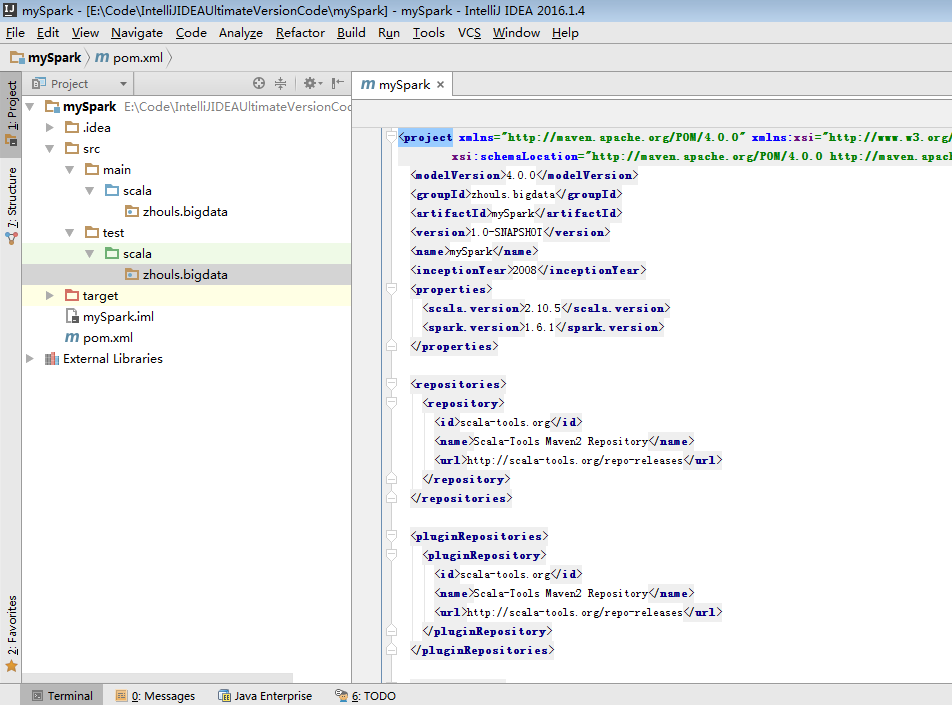
为了养成,开发规范。
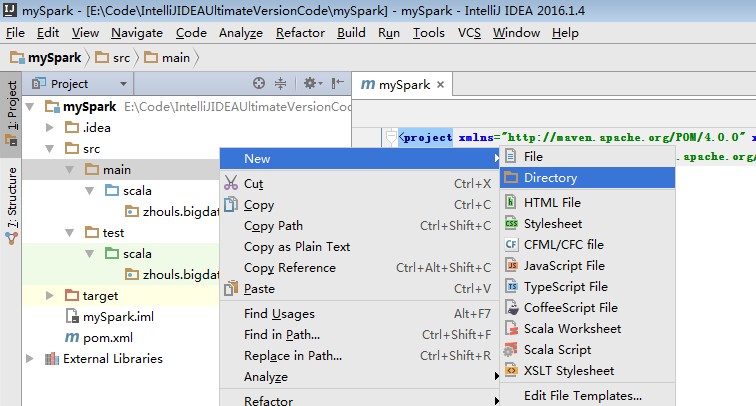
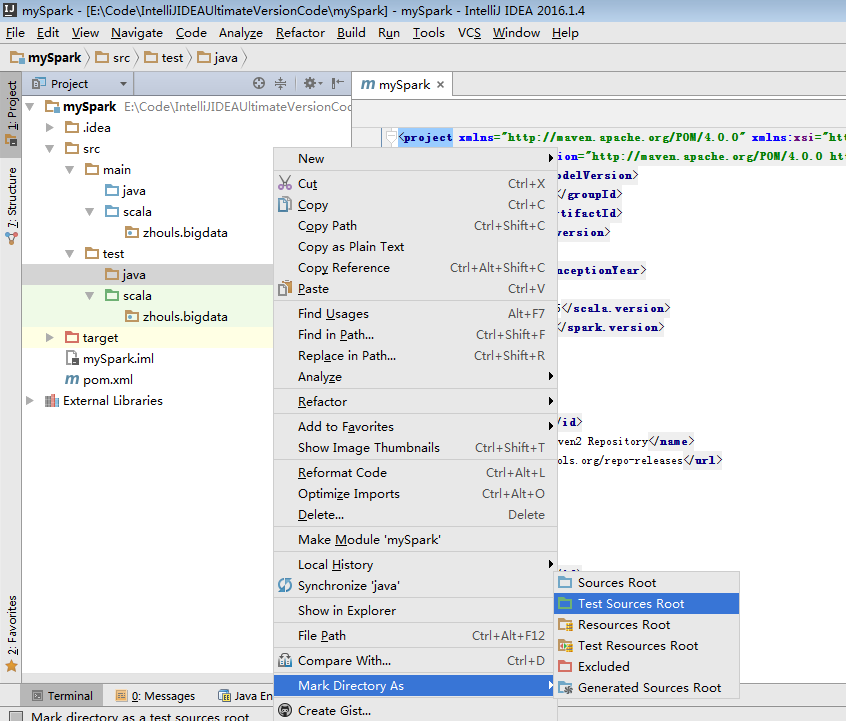
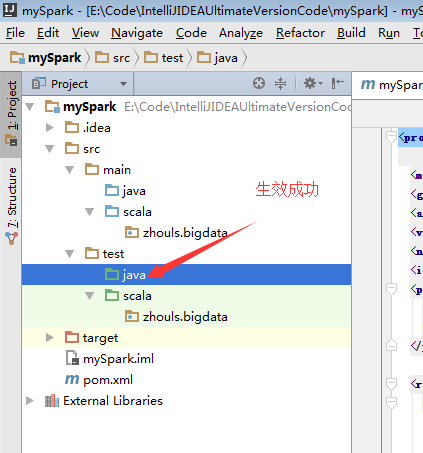
默认,创建是没有生效的,比如做如下,才能生效。
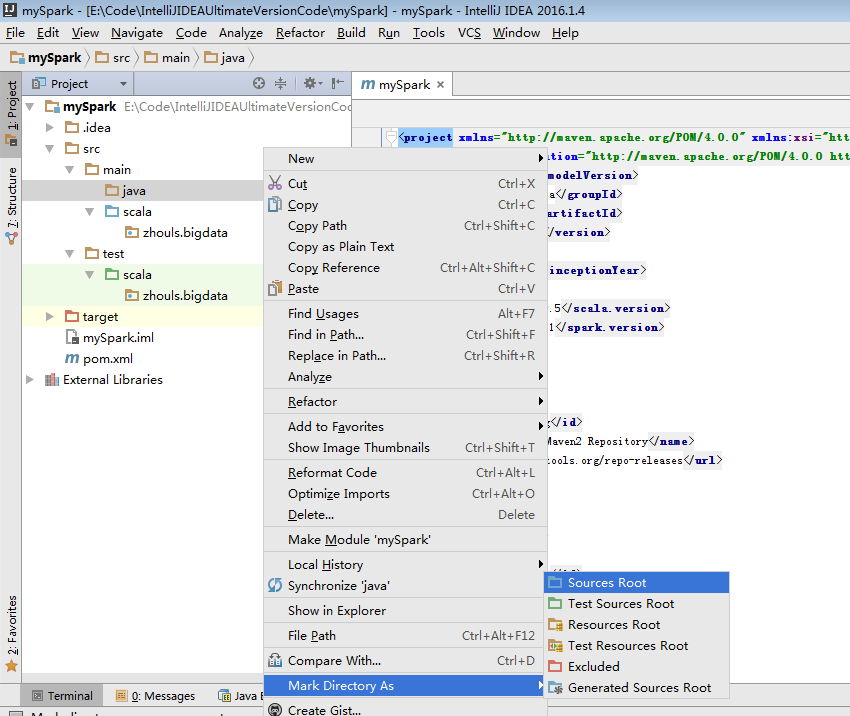
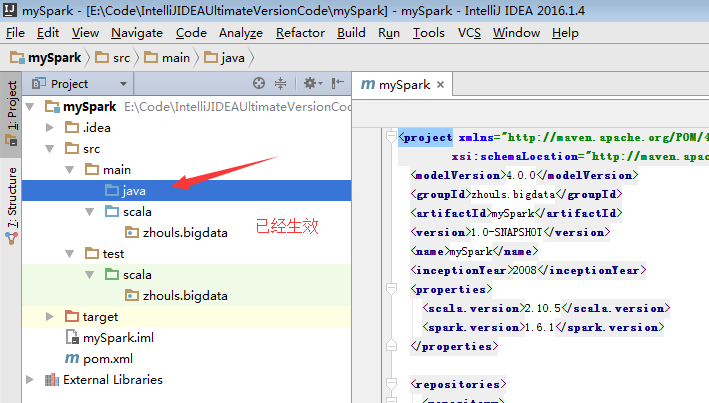
同样,对于下面的单元测试,也是一样

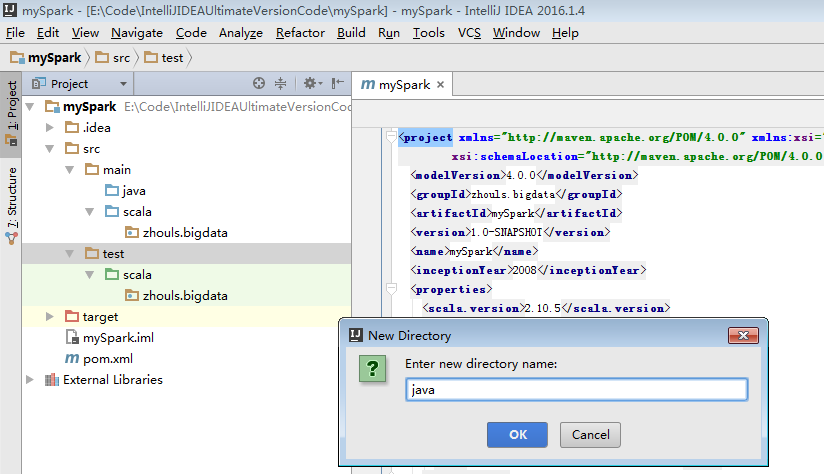
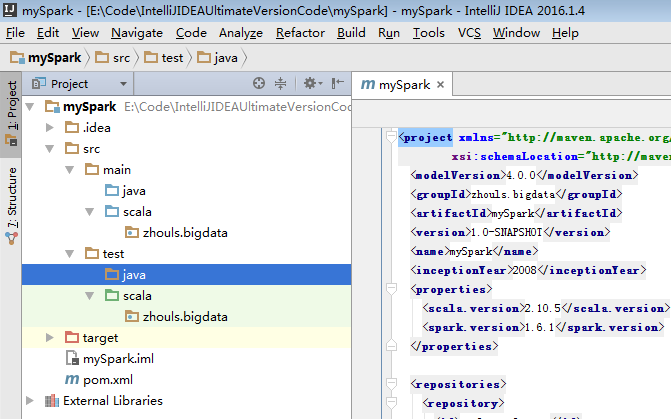
默认,也是没有生效的。
必须做如下的动作,才能生效。
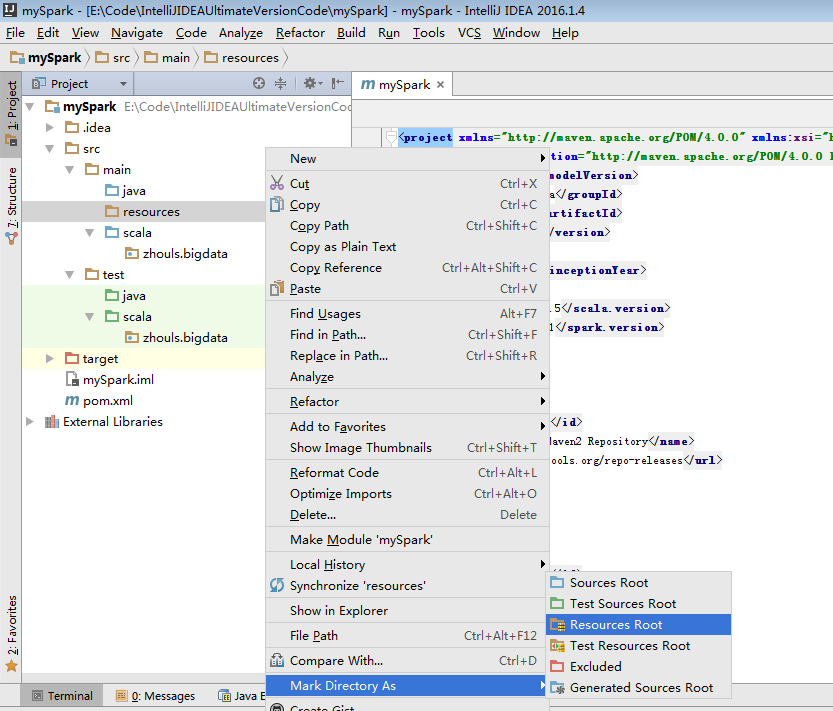
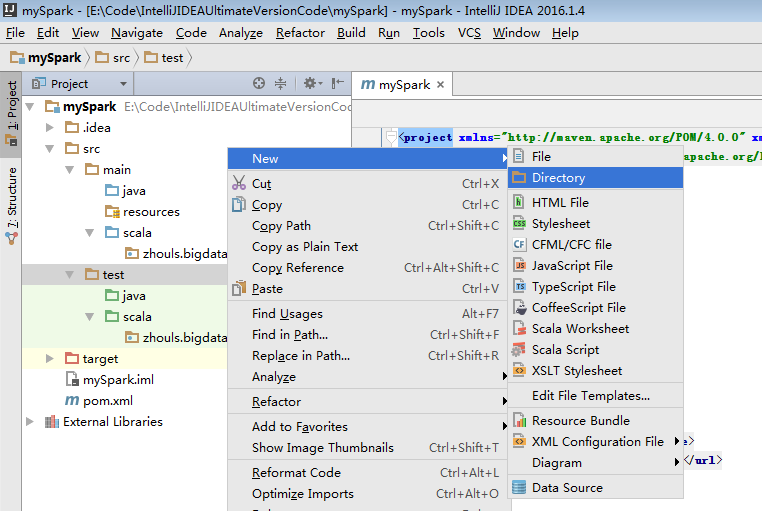


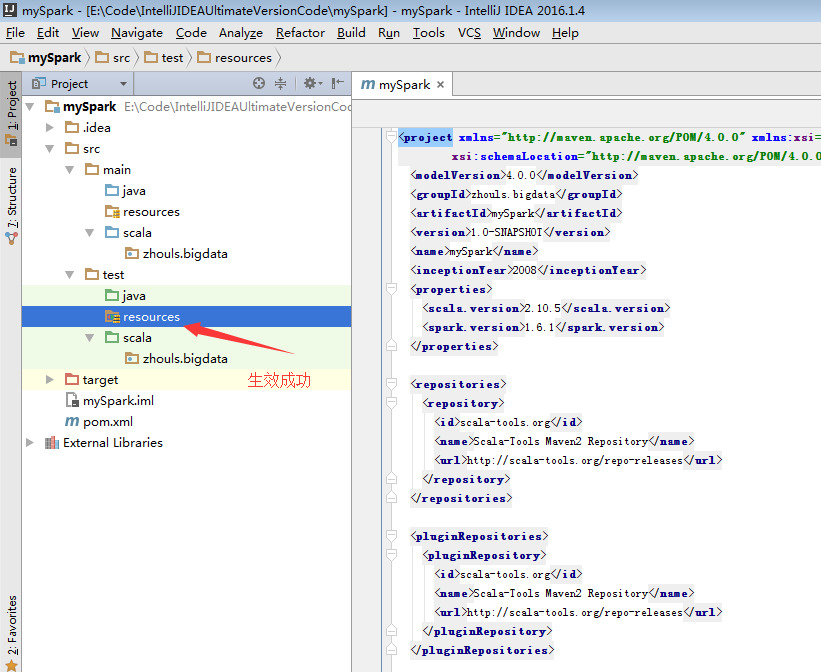
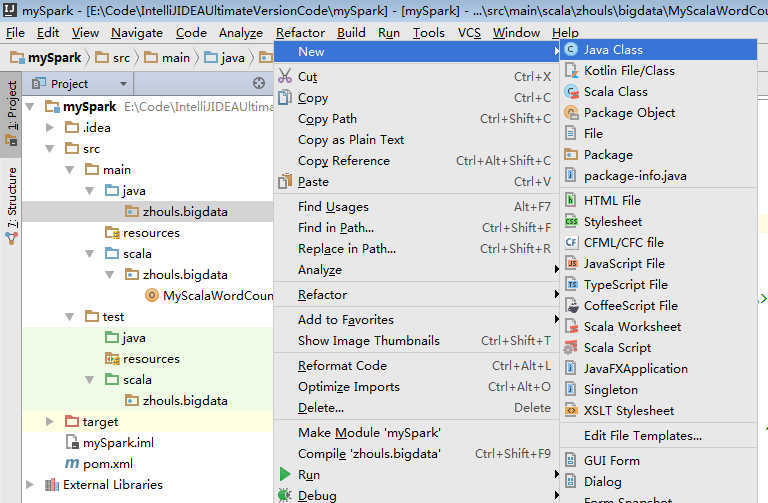
开发第一个Spark程序

scala入门-01-IDEA安装scala插件

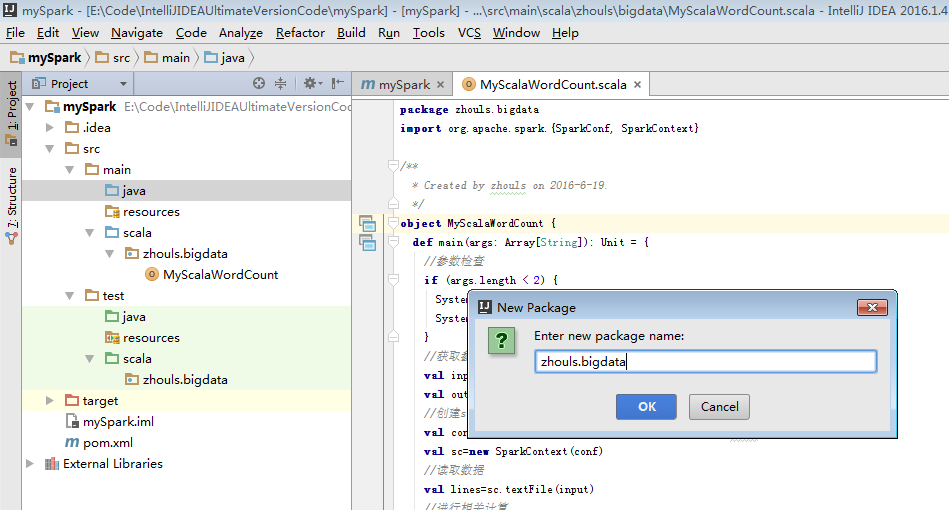
a) 第一个Scala版本的spark程序


package zhouls.bigdata
import org.apache.spark.{SparkConf, SparkContext} /**
* Created by zhouls on 2016-6-19.
*/
object MyScalaWordCount {
def main(args: Array[String]): Unit = {
//参数检查
if (args.length < 2) {
System.err.println("Usage: MyScalaWordCout <input> <output> ")
System.exit(1)
}
//获取参数
val input=args(0)
val output=args(1)
//创建scala版本的SparkContext
val conf=new SparkConf().setAppName("MyScalaWordCout ")
val sc=new SparkContext(conf)
//读取数据
val lines=sc.textFile(input)
//进行相关计算
val resultRdd=lines.flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_)
//保存结果
resultRdd.saveAsTextFile(output)
sc.stop()
}
}
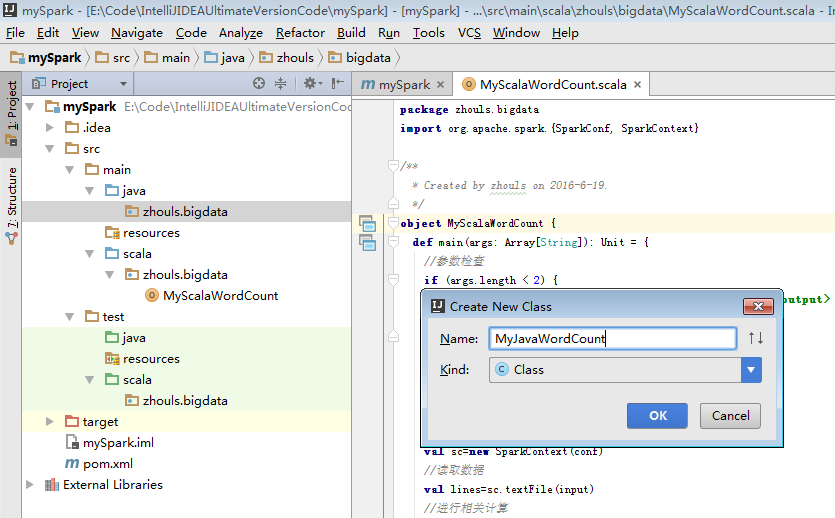
b) 第一个Java版本的spark程序

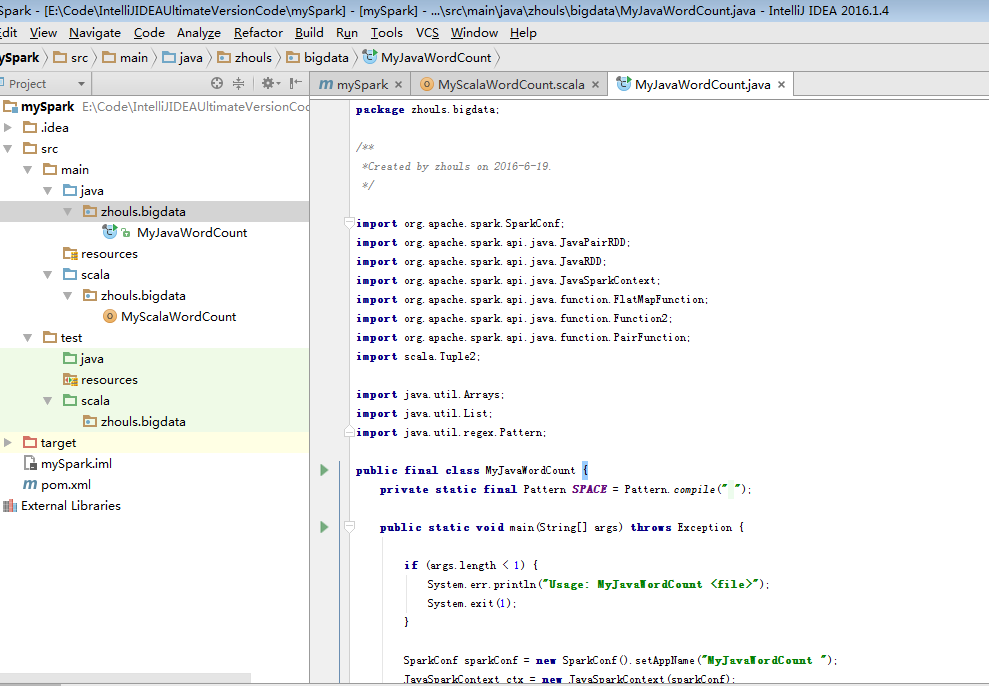
package zhouls.bigdata; import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import scala.Tuple2; import java.util.Arrays; /**
* Created by zhouls on 2016-6-19.
*/
public class MyJavaWordCount {
public static void main(String[] args) {
//参数检查
if(args.length<2){
System.err.println("Usage: MyJavaWordCount <input> <output> ");
System.exit(1);
}
//获取参数
String input=args[0];
String output=args[1]; //创建java版本的SparkContext
SparkConf conf=new SparkConf().setAppName("MyJavaWordCount");
JavaSparkContext sc=new JavaSparkContext(conf);
//读取数据
JavaRDD inputRdd=sc.textFile(input);
//进行相关计算
JavaRDD words=inputRdd.flatMap(new FlatMapFunction() {
public Iterable call(String line) throws Exception {
return Arrays.asList(line.split(" "));
}
}); JavaPairRDD result=words.mapToPair(new PairFunction() {
public Tuple2 call(String word) throws Exception {
return new Tuple2(word,1);
}
}).reduceByKey(new Function2() {
public Integer call(Integer x, Integer y) throws Exception {
return x+y;
}
});
//保存结果
result.saveAsTextFile(output);
//关闭sc
sc.stop();
}
}
或者
package zhouls.bigdata; /**
*Created by zhouls on 2016-6-19.
*/ import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import scala.Tuple2; import java.util.Arrays;
import java.util.List;
import java.util.regex.Pattern; public final class MyJavaWordCount {
private static final Pattern SPACE = Pattern.compile(" "); public static void main(String[] args) throws Exception { if (args.length < 1) {
System.err.println("Usage: MyJavaWordCount <file>");
System.exit(1);
} SparkConf sparkConf = new SparkConf().setAppName("MyJavaWordCount ");
JavaSparkContext ctx = new JavaSparkContext(sparkConf);
JavaRDD<String> lines = ctx.textFile(args[0], 1); JavaRDD<String> words = lines.flatMap(new FlatMapFunction<String, String>() {
public Iterable<String> call(String s) {
return Arrays.asList(SPACE.split(s));
}
}); JavaPairRDD<String, Integer> ones = words.mapToPair(new PairFunction<String, String, Integer>() {
public Tuple2<String, Integer> call(String s) {
return new Tuple2<String, Integer>(s, 1);
}
}); JavaPairRDD<String, Integer> counts = ones.reduceByKey(new Function2<Integer, Integer, Integer>() {
public Integer call(Integer i1, Integer i2) {
return i1 + i2;
}
}); List<Tuple2<String, Integer>> output = counts.collect();
for (Tuple2<?, ?> tuple : output) {
System.out.println(tuple._1() + ": " + tuple._2());
}
ctx.stop();
}
}
运行自己开发第一个Spark程序
Spark maven 项目打包
IDEA里如何多种方式打jar包,然后上传到集群
推荐下面这种方式
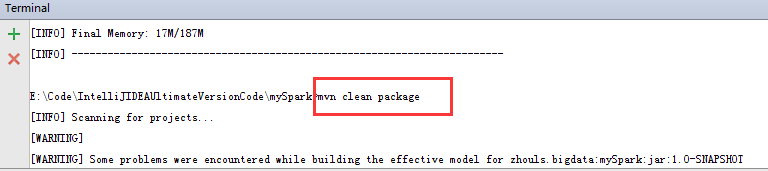
1、先切换到此工程路径下

默认,会到E:\Code\IntelliJIDEAUltimateVersionCode\mySpark>
mvn clean package
mvn package
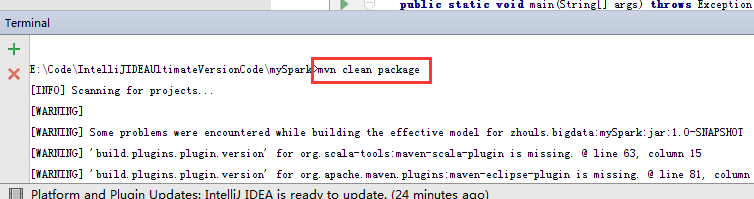

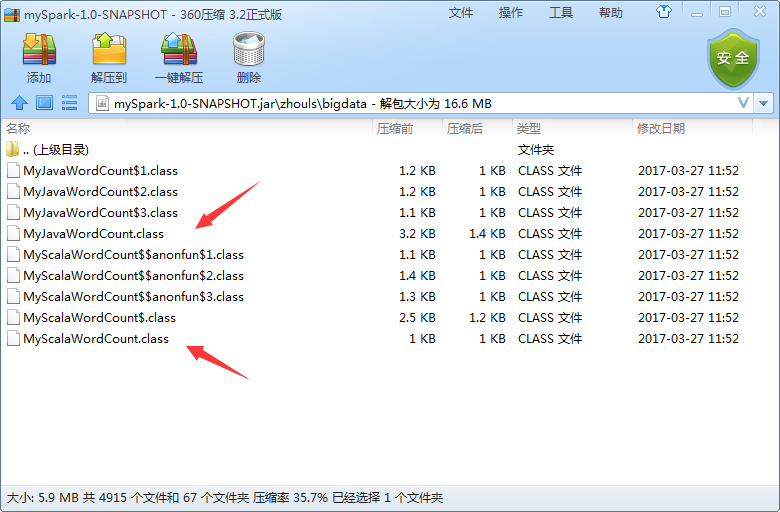
为了,更好的学习,其实,我们可以将它拷贝到桌面,去看看,是否真正打包进入。因为这里,是需要包括MyJavaWordCount.java和MyScalaWordCout.scala


准备好数据

[spark@sparksinglenode wordcount]$ pwd
/home/spark/testspark/inputData/wordcount
[spark@sparksinglenode wordcount]$ ll
total 4
-rw-rw-r-- 1 spark spark 92 Mar 24 18:45 wc.txt
[spark@sparksinglenode wordcount]$ cat wc.txt
hadoop spark
storm zookeeper
scala java
hive hbase
mapreduce hive
hadoop hbase
spark hadoop
[spark@sparksinglenode wordcount]$
上传好刚之前打好的jar包
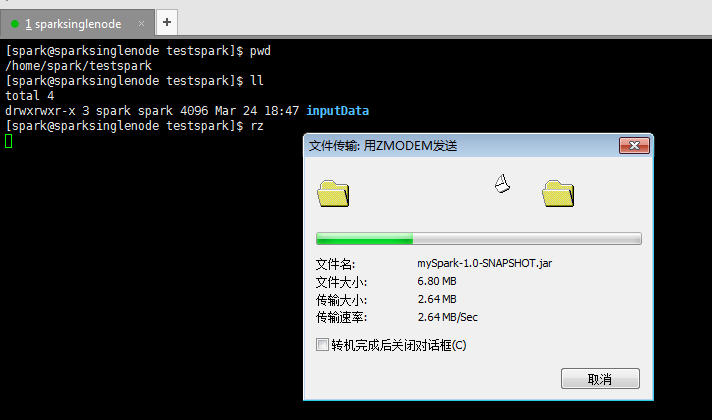
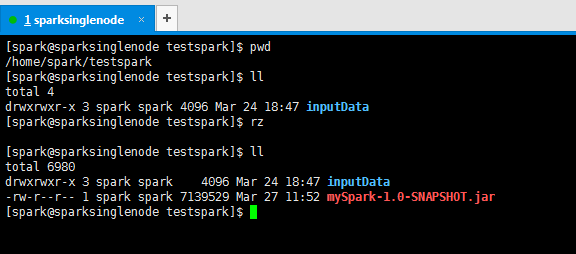
提交Spark 集群运行
a) 提交Scala版本的Wordcount
到$SPARK_HOME安装目录下,去执行如下命令。

[spark@sparksinglenode spark-1.6.1-bin-hadoop2.6]$ $HADOOP_HOME/bin/hadoop fs -mkdir -p hdfs://sparksinglenode:9000/testspark/inputData/wordcount

[spark@sparksinglenode spark-1.6.1-bin-hadoop2.6]$ $HADOOP_HOME/bin/hadoop fs -copyFromLocal /home/spark/testspark/inputData/wordcount/wc.txt hdfs://sparksinglenode:9000/testspark/inputData/wordcount/


[spark@sparksinglenode spark-1.6.1-bin-hadoop2.6]$ bin/spark-submit --class zhouls.bigdata.MyScalaWordCount /home/spark/testspark/mySpark-1.0-SNAPSHOT.jar hdfs://sparksinglenode:9000/testspark/inputData/wordcount/wc.txt hdfs://sparksinglenode:9000/testspark/outData/MyScalaWordCount
注意,以上,是输入路径和输出都要在集群里。因为我这里的程序打包里,制定是在集群里(即hdfs)。所以只能用这种方法。
成功!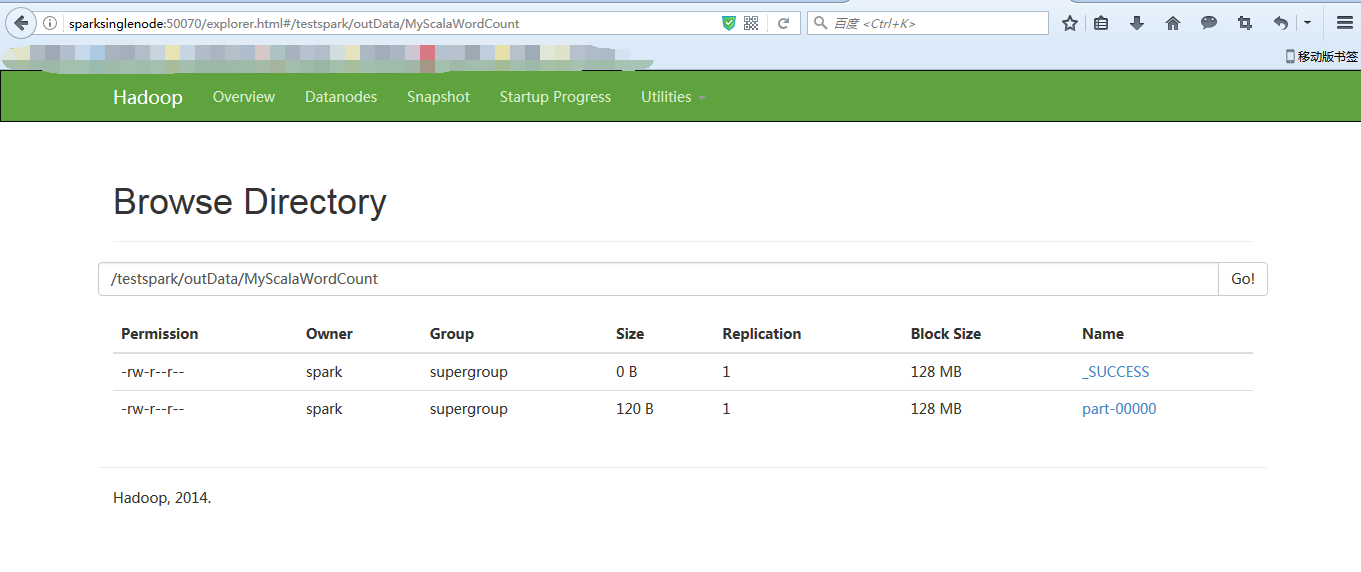

[spark@sparksinglenode spark-1.6.1-bin-hadoop2.6]$ $HADOOP_HOME/bin/hadoop fs -cat hdfs://sparksinglenode:9000/testspark/outData/MyScalaWordCount/part-*
17/03/27 20:12:55 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
(storm zookeeper,1)
(hadoop spark,1)
(spark hadoop,1)
(mapreduce hive,1)
(scala java,1)
(hive hbase,1)
(hadoop hbase,1)
[spark@sparksinglenode spark-1.6.1-bin-hadoop2.6]$
注意:若想要在本地(即windows里或linux里能运行的话。则只需在程序代码里。注明是local就好,这个很简单。不多赘述,再打包。再运行就可以了。
[spark@sparksinglenode spark-1.6.1-bin-hadoop2.6]$ bin/spark-submit --class zhouls.bigdata.MyScalaWordCount /home/spark/testspark/mySpark-1.0-SNAPSHOT.jar /home/spark/testspark/inputData/wordcount/wc.txt /home/spark/testspark/outData/MyScalaWordCount
b) 提交Java版本的Wordcount

[spark@sparksinglenode spark-1.6.1-bin-hadoop2.6]$ bin/spark-submit --class zhouls.bigdata.MyJavaWordCount /home/spark/testspark/mySpark-1.0-SNAPSHOT.jar hdfs://sparksinglenode:9000/testspark/inputData/wordcount/wc.txt hdfs://sparksinglenode:9000/testspark/outData/MyJavaWordCount
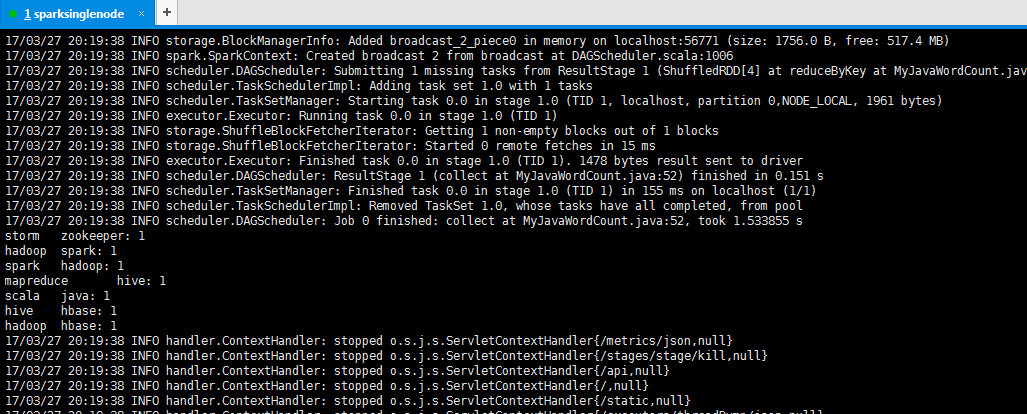
storm zookeeper: 1
hadoop spark: 1
spark hadoop: 1
mapreduce hive: 1
scala java: 1
hive hbase: 1
hadoop hbase: 1
注意:若想要在本地(即windows里或linux里能运行的话。则只需在程序代码里。注明是local就好,这个很简单。不多赘述,再打包。再运行就可以了。
bin/spark-submit --class com.zhouls.test.MyJavaWordCount /home/spark/testspark/mySpark-1.0.SNAPSHOT.jar /home/spark/testspark/inputData/wordcount/wc.txt /home/spark/testspark/outData/MyJavaWordCount
成功!
关于对pom.xml的进一步深入,见
对于maven创建spark项目的pom.xml配置文件(图文详解)
推荐博客
Scala IDEA for Eclipse里用maven来创建scala和java项目代码环境(图文详解)
用maven来创建scala和java项目代码环境(图文详解)(Intellij IDEA(Ultimate版本)、Intellij IDEA(Community版本)和Scala IDEA for Eclipse皆适用)(博主推荐)
同时,大家可以关注我的个人博客:
http://www.cnblogs.com/zlslch/ 和 http://www.cnblogs.com/lchzls/ http://www.cnblogs.com/sunnyDream/
详情请见:http://www.cnblogs.com/zlslch/p/7473861.html
人生苦短,我愿分享。本公众号将秉持活到老学到老学习无休止的交流分享开源精神,汇聚于互联网和个人学习工作的精华干货知识,一切来于互联网,反馈回互联网。
目前研究领域:大数据、机器学习、深度学习、人工智能、数据挖掘、数据分析。 语言涉及:Java、Scala、Python、Shell、Linux等 。同时还涉及平常所使用的手机、电脑和互联网上的使用技巧、问题和实用软件。 只要你一直关注和呆在群里,每天必须有收获
对应本平台的讨论和答疑QQ群:大数据和人工智能躺过的坑(总群)(161156071)![]()
![]()
![]()
![]()
![]()




打开百度App,扫码,精彩文章每天更新!欢迎关注我的百家号: 九月哥快讯
Spark编程环境搭建(基于Intellij IDEA的Ultimate版本)(包含Java和Scala版的WordCount)(博主强烈推荐)的更多相关文章
- IntelliJ IDEA(Ultimate版本)的下载、安装和WordCount的初步使用(本地模式和集群模式)
不多说,直接上干货! IntelliJ IDEA号称当前Java开发效率最高的IDE工具.IntelliJ IDEA有两个版本:社区版(Community)和旗舰版(Ultimate).社区版时免费的 ...
- Ubuntu14.04下Ambari安装搭建部署大数据集群(图文分五大步详解)(博主强烈推荐)
不多说,直接上干货! 写在前面的话 (1) 最近一段时间,因担任我团队实验室的大数据环境集群真实物理机器工作,至此,本人秉持负责.认真和细心的态度,先分别在虚拟机上模拟搭建ambari(基于CentO ...
- Ubuntu14.04下Cloudera安装搭建部署大数据集群(图文分五大步详解)(博主强烈推荐)(在线或离线)
第一步: Cloudera Manager安装之Cloudera Manager安装前准备(Ubuntu14.04)(一) 第二步: Cloudera Manager安装之时间服务器和时间客户端(Ub ...
- Spark编程环境搭建及WordCount实例
基于Intellij IDEA搭建Spark开发环境搭建 基于Intellij IDEA搭建Spark开发环境搭——参考文档 ● 参考文档http://spark.apache.org/docs/la ...
- CentOS6.5下Ambari安装搭建部署大数据集群(图文分五大步详解)(博主强烈推荐)
第一步: Ambari安装之Ambari安装前准备(CentOS6.5)(一) 第二步: Ambari安装之部署本地库(镜像服务器)(二) 第三步: Ambari安装之安装并配置Ambari-serv ...
- CentOS6.5下Cloudera安装搭建部署大数据集群(图文分五大步详解)(博主强烈推荐)
不多说,直接上干货! 第一步: Cloudera Manager安装之Cloudera Manager安装前准备(CentOS6.5)(一) 第二步: Cloudera Manager安装之时间服务 ...
- 用maven来创建scala和java项目代码环境(图文详解)(Intellij IDEA(Ultimate版本)、Intellij IDEA(Community版本)和Scala IDEA for Eclipse皆适用)(博主推荐)
不多说,直接上干货! 为什么要写这篇博客? 首先,对于spark项目,强烈建议搭建,用Intellij IDEA(Ultimate版本),如果你还有另所爱好尝试Scala IDEA for Eclip ...
- 使用 IntelliJ IDEA 导入 Spark 最新源码及编译 Spark 源代码(博主强烈推荐)
前言 其实啊,无论你是初学者还是具备了有一定spark编程经验,都需要对spark源码足够重视起来. 本人,肺腑之己见,想要成为大数据的大牛和顶尖专家,多结合源码和操练编程. 准备工作 1.sca ...
- IntelliJ IDEA(Community版本)的下载、安装和WordCount的初步使用(本地模式和集群模式)
不多说,直接上干货! 对于初学者来说,建议你先玩玩这个免费的社区版,但是,一段时间,还是去玩专业版吧,这个很简单哈,学聪明点,去搞到途径激活!可以看我的博客. 包括: IntelliJ IDEA(Co ...
随机推荐
- 使用百度webuploader实现大文件上传
版权所有 2009-2018荆门泽优软件有限公司 保留所有权利 官方网站:http://www.ncmem.com/ 产品首页:http://www.ncmem.com/webapp/up6.2/in ...
- SpringMvc中controller之间的方法调用
方法一, return new ModelAndView("redirect:"+新地址); 方法二, response.sendRedirect(新地址); return nul ...
- Perf -- Linux下的系统性能调优工具,第 1 部分
Perf 简介 Perf 是用来进行软件性能分析的工具. 通过它,应用程序可以利用 PMU,tracepoint 和内核中的特殊计数器来进行性能统计.它不但可以分析指定应用程序的性能问题 (per t ...
- 集合(六)LinkedHashMap
上两篇文章讲了HashMap和HashMap在多线程下引发的问题,说明了,HashMap是一种非常常见.非常有用的集合,并且在多线程情况下使用不当会有线程安全问题. 大多数情况下,只要不涉及线程安全问 ...
- Android-XML格式描述
XML是W3C公司提出的标准,使用范围非常广阔,在框架的配置,程序的配置,布局文件的定义,网络传输等,无所不在: 以前学Java的时候,对XML的名词定义是,根节点,子节点 等等,而在Android里 ...
- Google Summer of Code礼包
这个暑假参加google summer of code, 给Google的分布式容器管理系统kubernates开发新的特性,希望从中学习更多的分布式的技术,锻炼自己的编程技巧. 中午在学校的图书馆吗 ...
- asp.net 进行发送邮箱验证
利用发送邮件验证码进行注册验证 需要引用using System.Net.Mail;命名空间 #region /// <summary> /// 发送邮件 /// </summary ...
- iOS App的加固保护原理
本文由 网易云发布. 本文从攻防原理层面解析了iOS APP的安全策略.iOS以高安全性著称,但它并非金刚不坏之身.对于信息安全而言,止大风于青萍之末是上上策,杭研深入各个细节的研发工作,正是网易产 ...
- leetcode 75. 颜色分类 JAVA
题目: 给定一个包含红色.白色和蓝色,一共 n 个元素的数组,原地对它们进行排序,使得相同颜色的元素相邻,并按照红色.白色.蓝色顺序排列. 此题中,我们使用整数 0. 1 和 2 分别表示红色.白色和 ...
- “全栈2019”Java多线程第二十三章:活锁(Livelock)详解
难度 初级 学习时间 10分钟 适合人群 零基础 开发语言 Java 开发环境 JDK v11 IntelliJ IDEA v2018.3 文章原文链接 "全栈2019"Java多 ...