Hadoop学习之路(九)HDFS深入理解
HDFS的优点和缺点
HDFS的优点
1、可构建在廉价机器上
通过多副本提高可靠性,提供了容错和恢复机制
服务器节点的宕机是常态 必须理性对象
2、高容错性
数据自动保存多个副本,副本丢失后,自动恢复
HDFS的核心设计思想: 分散均匀存储 + 备份冗余存储
3、适合批处理
移动计算而非数据,数据位置暴露给计算框架
海量数据的计算 任务 最终是一定要被切分成很多的小任务进行
4、适合大数据处理
GB、TB、甚至 PB 级数据,百万规模以上的文件数量,10K+节点规模
5、流式文件访问
一次性写入,多次读取,保证数据一致性
HDFS的缺点
不适合以下操作
1、低延迟数据访问
比如毫秒级 低延迟与高吞吐率
2、小文件存取
占用 NameNode 大量内存 150b* 1000W = 15E,1.5G 寻道时间超过读取时间
3、并发写入、文件随机修改
一个文件只能有一个写者 仅支持 append
抛出问题:HDFS文件系统为什么不适用于存储小文件?
这是和HDFS系统底层设计实现有关系的,HDFS本身的设计就是用来解决海量大文件数据的存储.,他天生喜欢大数据的处理,大文件存储在HDFS中,会被切分成很多的小数据块,任何一个文件不管有多小,都是一个独立的数据块,而这些数据块的信息则是保存在元数据中的,在之前的博客HDFS基础里面介绍过在HDFS集群的namenode中会存储元数据的信息,这里再说一下,元数据的信息主要包括以下3部分:
1)抽象目录树
2)文件和数据块的映射关系,一个数据块的元数据大小大约是150byte
3)数据块的多个副本存储地
而元数据的存储在磁盘(1和2)和内存中(1、2和3),而服务器中的内存是有上限的,举个例子:
有100个1M的文件存储进入HDFS系统,那么数据块的个数就是100个,元数据的大小就是100*150byte,消耗了15000byte的内存,但是只存储了100M的数据。
有1个100M的文件存储进入HDFS系统,那么数据块的个数就是1个,元数据的大小就是150byte,消耗量150byte的内存,存储量100M的数据。
所以说HDFS文件系统不适用于存储小文件。
HDFS的辅助功能
HDFS作为一个文件系统。有两个最主要的功能:上传和下载。而为了保障这两个功能的完美和高效实现,HDFS提供了很多的辅助功能
1.心跳机制
普通话讲解
1、 Hadoop 是 Master/Slave 结构,Master 中有 NameNode 和 ResourceManager,Slave 中有 Datanode 和 NodeManager
2、 Master 启动的时候会启动一个 IPC(Inter-Process Comunication,进程间通信)server 服 务,等待 slave 的链接
3、 Slave 启动时,会主动链接 master 的 ipc server 服务,并且每隔 3 秒链接一次 master,这 个间隔时间是可以调整的,参数为 dfs.heartbeat.interval,这个每隔一段时间去连接一次 的机制,我们形象的称为心跳。Slave 通过心跳汇报自己的信息给 master,master 也通 过心跳给 slave 下达命令,
4、 NameNode 通过心跳得知 Datanode 的状态 ,ResourceManager 通过心跳得知 NodeManager 的状态
5、 如果 master 长时间都没有收到 slave 的心跳,就认为该 slave 挂掉了。!!!!!
大白话讲解
1、DataNode启动的时候会向NameNode汇报信息,就像钉钉上班打卡一样,你打卡之后,你领导才知道你今天来上班了,同样的道理,DataNode也需要向NameNode进行汇报,只不过每次汇报的时间间隔有点短而已,默认是3秒中,DataNode向NameNode汇报的信息有2点,一个是自身DataNode的状态信息,另一个是自身DataNode所持有的所有的数据块的信息。而DataNode是不会知道他保存的所有的数据块副本到底是属于哪个文件,这些都是存储在NameNode的元数据中。
2、按照规定,每个DataNode都是需要向NameNode进行汇报。那么如果从某个时刻开始,某个DataNode再也不向NameNode进行汇报了。 有可能宕机了。因为只要通过网络传输数据,就一定存在一种可能: 丢失 或者 延迟。
3、HDFS的标准: NameNode如果连续10次没有收到DataNode的汇报。 那么NameNode就会认为该DataNode存在宕机的可能。
4、DataNode启动好了之后,会专门启动一个线程,去负责给NameNode发送心跳数据包,如果说整个DataNode没有任何问题,但是仅仅只是当前负责发送信条数据包的线程挂了。NameNode会发送命令向这个DataNode进行确认。查看这个发送心跳数据包的服务是否还能正常运行,而为了保险起见,NameNode会向DataNode确认2遍,每5分钟确认一次。如果2次都没有返回 结果,那么NameNode就会认为DataNode已经GameOver了!!!
最终NameNode判断一个DataNode死亡的时间计算公式:
timeout = 10 * 心跳间隔时间 + 2 * 检查一次消耗的时间
心跳间隔时间:dfs.heartbeat.interval 心跳时间:3s
检查一次消耗的时间:heartbeat.recheck.interval checktime : 5min
最终结果默认是630s。
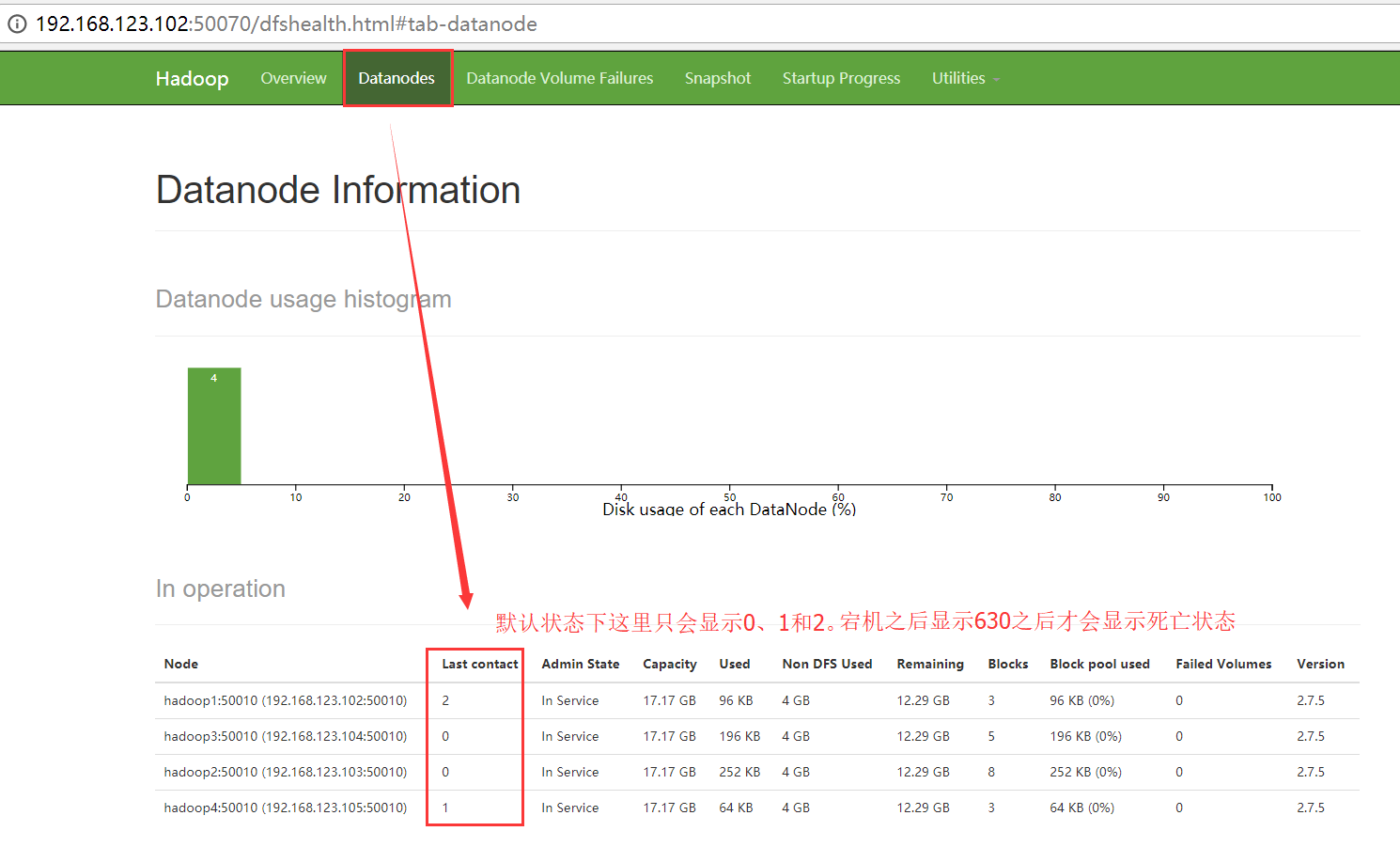
2.安全模式
1、HDFS的启动和关闭都是先启动NameNode,在启动DataNode,最后在启动secondarynamenode。
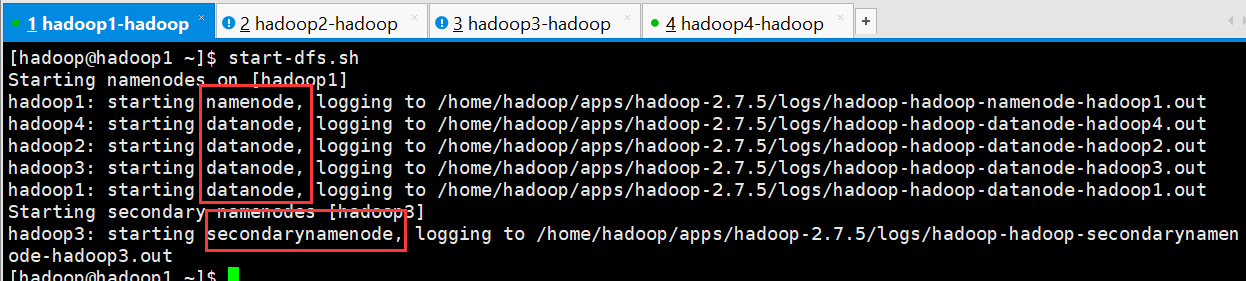
2、决定HDFS集群的启动时长会有两个因素:
1)磁盘元数据的大小
2)datanode的节点个数
当元数据很大,或者 节点个数很多的时候,那么HDFS的启动,需要一段很长的时间,那么在还没有完全启动的时候HDFS能否对外提供服务?
在HDFS的启动命令start-dfs.sh执行的时候,HDFS会自动进入安全模式
为了确保用户的操作是可以高效的执行成功的,在HDFS发现自身不完整的时候,会进入安全模式。保护自己。
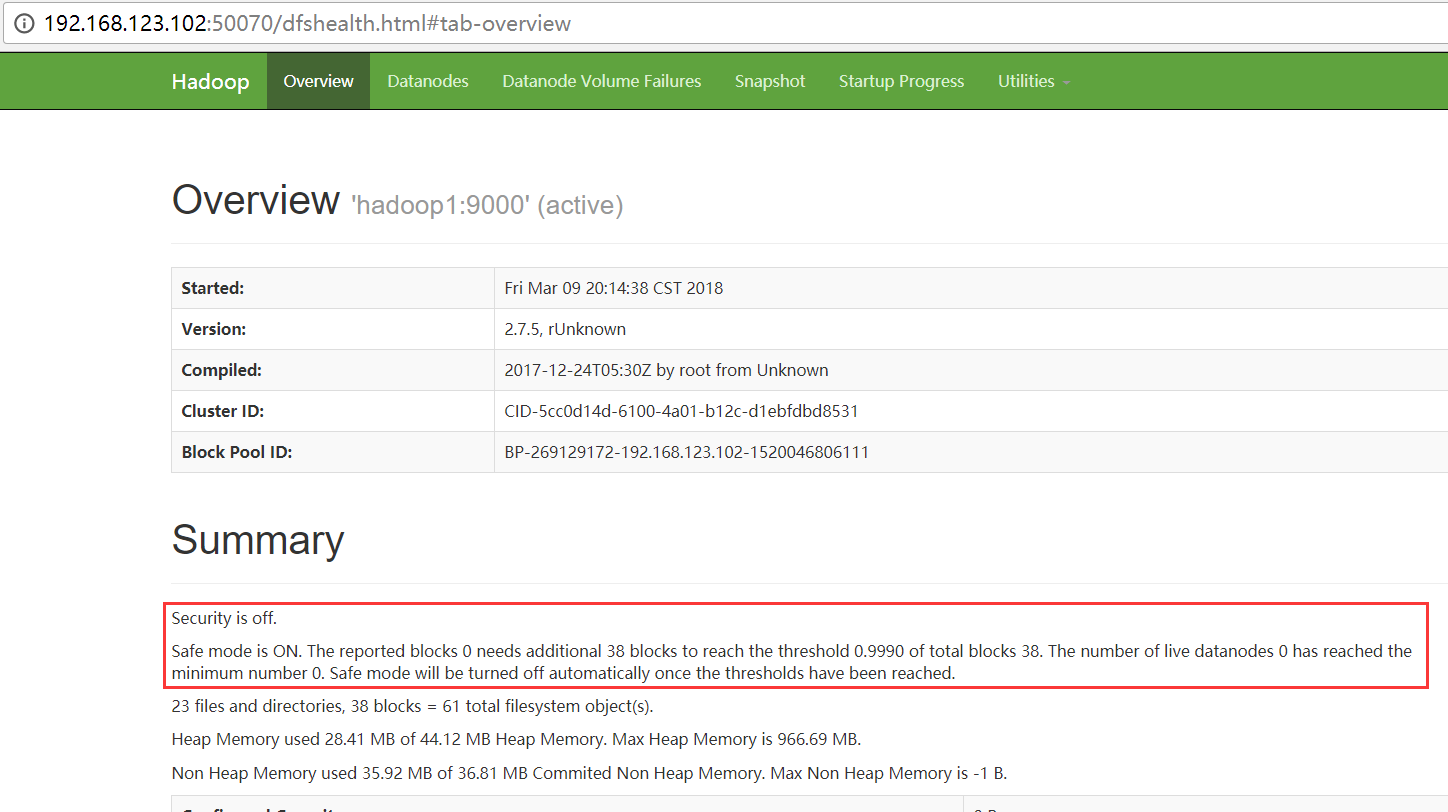
在正常启动之后,如果HDFS发现所有的数据都是齐全的,那么HDFS会启动的退出安全模式

3、对安全模式进行测试
安全模式常用操作命令:
- hdfs dfsadmin -safemode leave //强制 NameNode 退出安全模式
- hdfs dfsadmin -safemode enter //进入安全模式
- hdfs dfsadmin -safemode get //查看安全模式状态
- hdfs dfsadmin -safemode wait //等待,一直到安全模式结束
手工进入安全模式进行测试
1、测试创建文件夹
- [hadoop@hadoop1 ~]$ hdfs dfsadmin -safemode enter
- Safe mode is ON
- [hadoop@hadoop1 ~]$ hadoop fs -mkdir -p /xx/yy/zz
- mkdir: Cannot create directory /xx/yy/zz. Name node is in safe mode.
- [hadoop@hadoop1 ~]$

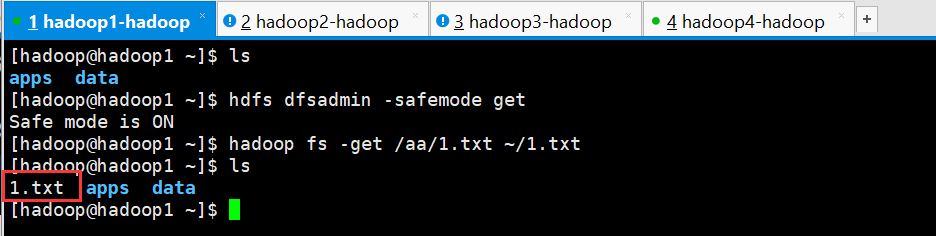
2、测试下载文件
- [hadoop@hadoop1 ~]$ ls
- apps data
- [hadoop@hadoop1 ~]$ hdfs dfsadmin -safemode get
- Safe mode is ON
- [hadoop@hadoop1 ~]$ hadoop fs -get /aa/.txt ~/.txt
- [hadoop@hadoop1 ~]$ ls
- .txt apps data
- [hadoop@hadoop1 ~]$
3、测试上传
- [hadoop@hadoop1 ~]$ hadoop fs -put .txt /a/xx.txt
- put: Cannot create file/a/xx.txt._COPYING_. Name node is in safe mode.
- [hadoop@hadoop1 ~]$

4、得出结论,在安全模式下:
如果一个操作涉及到元数据的修改的话。都不能进行操作
如果一个操作仅仅只是查询。那是被允许的。
所谓的安全模式,仅仅只是保护namenode,而不是保护datanode
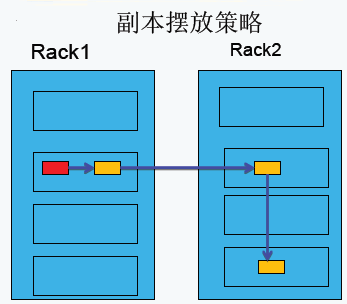
3.副本存放策略
第一副本:放置在上传文件的DataNode上;如果是集群外提交,则随机挑选一台磁盘不太慢、CPU不太忙的节点上;
第二副本:放置在于第一个副本不同的机架的节点上;
第三副本:与第二个副本相同机架的不同节点上;
如果还有更多的副本:随机放在节点中;
4.负载均衡
负载均衡理想状态:节点均衡、机架均衡和磁盘均衡。
Hadoop的HDFS集群非常容易出现机器与机器之间磁盘利用率不平衡的情况,例如:当集群内新增、删除节点,或者某个节点机器内硬盘存储达到饱和值。当数据不平衡时,Map任务可能会分配到没有存储数据的机器,这将导致网络带宽的消耗,也无法很好的进行本地计算。
当HDFS负载不均衡时,需要对HDFS进行数据的负载均衡调整,即对各节点机器上数据的存储分布进行调整。从而,让数据均匀的分布在各个DataNode上,均衡IO性能,防止热点的发生。进行数据的负载均衡调整,必须要满足如下原则:
- 数据平衡不能导致数据块减少,数据块备份丢失
- 管理员可以中止数据平衡进程
- 每次移动的数据量以及占用的网络资源,必须是可控的
- 数据均衡过程,不能影响namenode的正常工作
负载均衡的原理
数据均衡过程的核心是一个数据均衡算法,该数据均衡算法将不断迭代数据均衡逻辑,直至集群内数据均衡为止。该数据均衡算法每次迭代的逻辑如下:
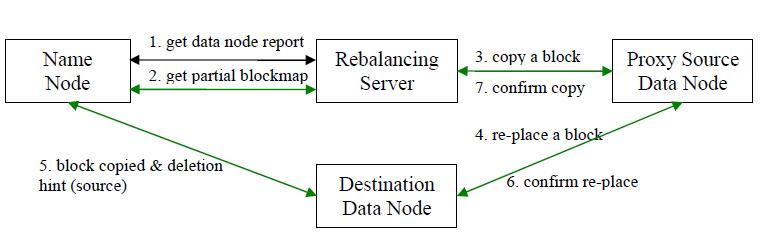
步骤分析如下:
- 数据均衡服务(Rebalancing Server)首先要求 NameNode 生成 DataNode 数据分布分析报告,获取每个DataNode磁盘使用情况
- Rebalancing Server汇总需要移动的数据分布情况,计算具体数据块迁移路线图。数据块迁移路线图,确保网络内最短路径
- 开始数据块迁移任务,Proxy Source Data Node复制一块需要移动数据块
- 将复制的数据块复制到目标DataNode上
- 删除原始数据块
- 目标DataNode向Proxy Source Data Node确认该数据块迁移完成
- Proxy Source Data Node向Rebalancing Server确认本次数据块迁移完成。然后继续执行这个过程,直至集群达到数据均衡标准
DataNode分组
在第2步中,HDFS会把当前的DataNode节点,根据阈值的设定情况划分到Over、Above、Below、Under四个组中。在移动数据块的时候,Over组、Above组中的块向Below组、Under组移动。四个组定义如下:
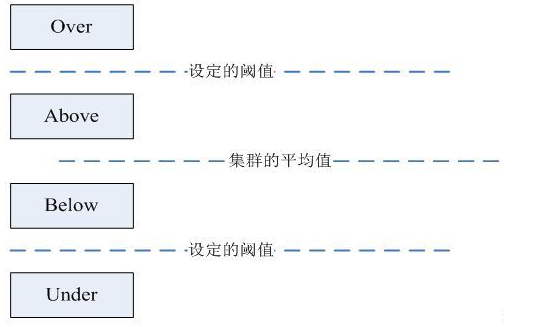
- Over组:此组中的DataNode的均满足
DataNode_usedSpace_percent > Cluster_usedSpace_percent + threshold
- Above组:此组中的DataNode的均满足
Cluster_usedSpace_percent + threshold > DataNode_ usedSpace _percent >Cluster_usedSpace_percent
- Below组:此组中的DataNode的均满足
Cluster_usedSpace_percent > DataNode_ usedSpace_percent > Cluster_ usedSpace_percent – threshold
- Under组:此组中的DataNode的均满足
Cluster_usedSpace_percent – threshold > DataNode_usedSpace_percent
Hadoop HDFS 数据自动平衡脚本使用方法
在Hadoop中,包含一个start-balancer.sh脚本,通过运行这个工具,启动HDFS数据均衡服务。该工具可以做到热插拔,即无须重启计算机和 Hadoop 服务。HadoopHome/bin目录下的start−balancer.sh脚本就是该任务的启动脚本。启动命令为:‘HadoopHome/bin目录下的start−balancer.sh脚本就是该任务的启动脚本。启动命令为:‘Hadoop_home/bin/start-balancer.sh –threshold`
影响Balancer的几个参数:
- -threshold
- 默认设置:10,参数取值范围:0-100
- 参数含义:判断集群是否平衡的阈值。理论上,该参数设置的越小,整个集群就越平衡
- dfs.balance.bandwidthPerSec
- 默认设置:1048576(1M/S)
- 参数含义:Balancer运行时允许占用的带宽
示例如下:
- #启动数据均衡,默认阈值为 %
- $Hadoop_home/bin/start-balancer.sh
- #启动数据均衡,阈值 %
- bin/start-balancer.sh –threshold
- #停止数据均衡
- $Hadoop_home/bin/stop-balancer.sh
在hdfs-site.xml文件中可以设置数据均衡占用的网络带宽限制
- <property>
- <name>dfs.balance.bandwidthPerSec</name>
- <value></value>
- <description> Specifies the maximum bandwidth that each datanode can utilize for the balancing purpose in term of the number of bytes per second. </description>
- </property>
Hadoop学习之路(九)HDFS深入理解的更多相关文章
- 阿里封神谈hadoop学习之路
阿里封神谈hadoop学习之路 封神 2016-04-14 16:03:51 浏览3283 评论3 发表于: 阿里云E-MapReduce >> 开源大数据周刊 hadoop 学生 s ...
- 《Hadoop学习之路》学习实践
(实践机器:blog-bench) 本文用作博文<Hadoop学习之路>实践过程中遇到的问题记录. 本文所学习的博文为博主“扎心了,老铁” 博文记录.参考链接https://www.cnb ...
- Hadoop学习之路(十)HDFS API的使用
HDFS API的高级编程 HDFS的API就两个:FileSystem 和Configuration 1.文件的上传和下载 package com.ghgj.hdfs.api; import org ...
- Hadoop 学习之路(六)—— HDFS 常用 Shell 命令
1. 显示当前目录结构 # 显示当前目录结构 hadoop fs -ls <path> # 递归显示当前目录结构 hadoop fs -ls -R <path> # 显示根目录 ...
- Hadoop学习之路(二)Hadoop发展背景
Hadoop产生的背景 1. HADOOP最早起源于Nutch.Nutch的设计目标是构建一个大型的全网搜索引擎,包括网页抓取.索引.查询等功能,但随着抓取网页数量的增加,遇到了严重的可扩展性问题—— ...
- 小强的Hadoop学习之路
本人一直在做NET开发,接触这行有6年了吧.毕业也快四年了(6年是因为大学就开始在一家小公司做门户网站,哈哈哈),之前一直秉承着学要精,就一直一门心思的在做NET(也是懒吧).最近的工作一直都和大数据 ...
- 我的hadoop学习之路
Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS.HDFS有高容错性的特点,并且设计用来部署在低廉的(low-cost)硬件上. Ha ...
- hadoop学习第二天-了解HDFS的基本概念&&分布式集群的搭建&&HDFS基本命令的使用
一.HDFS的相关基本概念 1.数据块 1.在HDFS中,文件诶切分成固定大小的数据块,默认大小为64MB(hadoop2.x以后是128M),也可以自己配置. 2.为何数据块如此大,因为数据传输时间 ...
- Hadoop 学习之路(三)—— 分布式计算框架 MapReduce
一.MapReduce概述 Hadoop MapReduce是一个分布式计算框架,用于编写批处理应用程序.编写好的程序可以提交到Hadoop集群上用于并行处理大规模的数据集. MapReduce作业通 ...
- Hadoop学习(2)-- HDFS
随着信息技术的高度发展,数据量越来越多,当一个操作系统管辖范围存储不下时,只能将数据分配到更多的磁盘中存储,但是数据分散在多台磁盘上非常不方便管理和维护,迫切需要一种系统来管理多台机器上的文件,因此诞 ...
随机推荐
- An internal error occurred during: "Updating status for Tomcat v7.0 Server at localhost..."
tomcat启动maven工程的时候提示如下错误信息: An internal error occurred during: "Updating status for Tomcat v7.0 ...
- 深入理解java虚拟机---java内存区域与内存溢出异常---1内存结构
本文来源于翁舒航的博客,点击即可跳转原文观看!!!(被转载或者拷贝走的内容可能缺失图片.视频等原文的内容) 若网站将链接屏蔽,可直接拷贝原文链接到地址栏跳转观看,原文链接:https://www.cn ...
- 小tip:CSS3下的渐变文字效果实现——张鑫旭
by zhangxinxu from http://www.zhangxinxu.com本文地址:http://www.zhangxinxu.com/wordpress/?p=1601 一.方法一:借 ...
- Git 学习之Git 基础(二)
Git 基础 读完本章你就能上手使用 Git 了.本章将介绍几个最基本的,也是最常用的 Git 命令,以后绝大多数时间里用到的也就是这几个命令.读完本章,你就能初始化一个新的代码仓库,做一些适当配置: ...
- HTML5实现输入密码(六个格子)
我的思路:用六个li充当六个格子,同时将input框隐藏,点击承载六个格子的容器时,使焦点聚焦在input上,可以输入.通过监听input框输入的长度,控制格子内小黑点是否显示,同时用正则替换非数字. ...
- 【代码笔记】iOS-单击手势的添加
一,效果图. 二,工程图. 三,代码. RootViewController.h #import <UIKit/UIKit.h> @interface RootViewController ...
- 计时器(Chronometer)
计时器(Chronometer) 常用属性:format(计时器的计时格式) 常用方法: setBase(long base) 设置计时器的起始时间 setFormat(String format) ...
- shiro web 集成
集成方法 shiro与web集成,主要是通过配置一个ShiroFilter拦截所有URL,其中ShiroFilter类似于SpringMVC的前端控制器,是所有请求入口点,负责根据配置(如ini配置文 ...
- webpack HMR是如何工作的?
https://github.com/webpack/docs/wiki/hot-module-replacement-with-webpack https://www.jianshu.com/p/9 ...
- JWT能够干什么,不应该干什么?
http://cryto.net/~joepie91/blog/2016/06/13/stop-using-jwt-for-sessions/ At the start of this article ...