Python学习---爬虫学习[scrapy框架初识]
Scrapy
Scrapy是一个框架,可以帮助我们进行创建项目,运行项目,可以帮我们下载,解析网页,同时支持cookies和自定义其他功能。
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。 其可以应用在数据挖掘,信息处理或存储历史数据等一系列的程序中。其最初是为了页面抓取 (更确切来说, 网络抓取 )所设计的, 也可以应用在获取API所返回的数据(例如 Amazon Associates Web Services ) 或者通用的网络爬虫。Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试。
【更多参考】http://www.cnblogs.com/wupeiqi/articles/6229292.html
scrapy框架介绍以及安装
Linux
pip3 install scrapy
Windows
1. pip3 install wheel
1-1安装Twisted
a. http://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted, 下载:Twisted-17.1.0-cp35-cp35m-win_amd64.whl
b. 进入文件所在目录
c. pip3 install Twisted-17.1.0-cp35-cp35m-win_amd64.whl
2. pip3 install scrapy
3. windows上scrapy依赖 https://sourceforge.net/projects/pywin32/files/
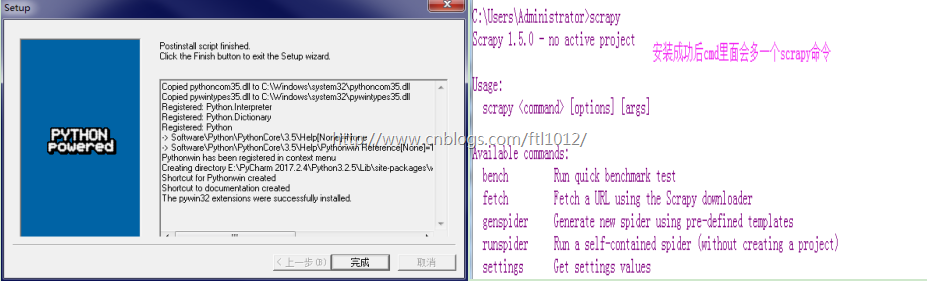
创建一个scrapy工程:
创建一个scrapy工程:
scrapy startproject scy
scrapy genspider baidu baidu.com

baidu.py里面的内容
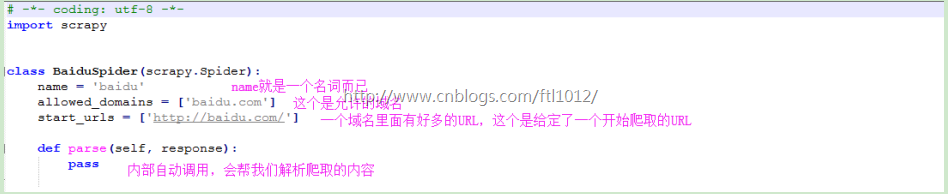
response.text可以打印具体的内容
scrapy crawl baidu
scrapy crawl baidu --nolog [不打印日志]

修改settting.py 让spider不去访问robot.txt文件

附: 查看spider文件的其他模板
scrapy genspider --list

项目结构以及爬虫应用简介
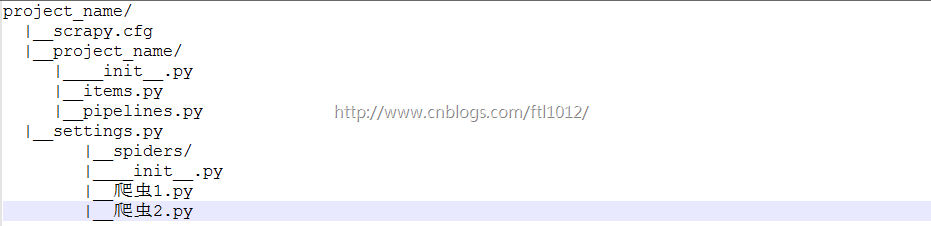
文件说明:
· scrapy.cfg 项目的主配置信息。(真正爬虫相关的配置信息在settings.py文件中)
· items.py 设置数据存储模板,用于结构化数据,如:Django的Model
· pipelines 数据处理行为,如:一般结构化的数据持久化
· settings.py 配置文件,如:递归的层数、并发数,延迟下载等
· spiders 爬虫目录,如:创建文件,编写爬虫规则
爬取笑话网
# -*- coding: utf-8 -*-
import scrapy
from scrapy.selector import HtmlXPathSelector
from scrapy.http import Request
class XiaohuarSpider(scrapy.Spider):
name = "xiaohuar"
allowed_domains = ["xiaohuar.com"]
start_urls = ['http://www.xiaohuar.com/list-1-0.html'] visited_set = set()
def parse(self, response):
self.visited_set.add(response.url)
# 1. 当前页面的所有校花爬下来
# 获取div并且属性为 class=item masonry_brick
hxs = HtmlXPathSelector(response)
item_list = hxs.select('//div[@class="item masonry_brick"]')
for item in item_list:
v = item.select('.//span[@class="price"]/text()').extract_first()
print(v) # 2. 在当前页中获取 http://www.xiaohuar.com/list-1-\d+.html,
# page_list = hxs.select('//a[@href="http://www.xiaohuar.com/list-1-1.html"]')
page_list = hxs.select('//a[re:test(@href,"http://www.xiaohuar.com/list-1-\d+.html")]/@href').extract()
for url in page_list:
if url in self.visited_set:
pass
else:
obj = Request(url=url,method='GET',callback=self.parse)
yield obj
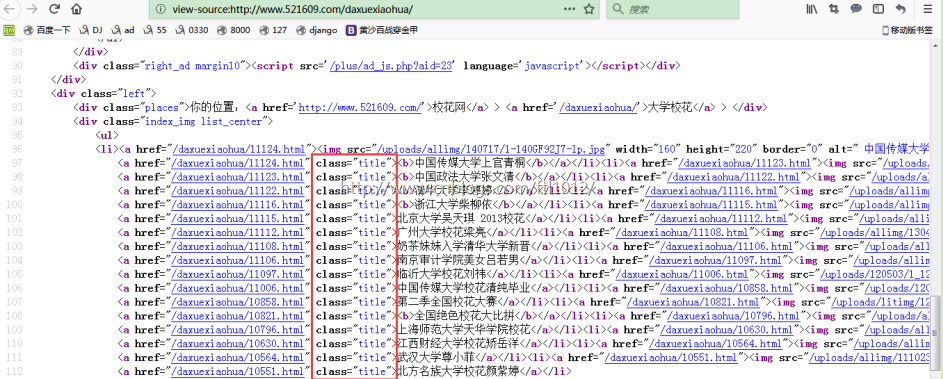
view-source: http://www.521609.com/daxuexiaohua/

Django和scrapy框架的小对比
Django和scrapy框架的小对比
########## scrapy ##########
Django
django-admin startproject mysite # 创建Django工程
cd mysite
python3 namage.py startapp app01
python3 namage.py startapp app02
scrapy
scrapy startproject scy # 创建scrapy工程
cd scy
scrapy genspider chouti chouti.com
scrapy crawl 名字 --nolog
Python学习---爬虫学习[scrapy框架初识]的更多相关文章
- Python网络爬虫之Scrapy框架(CrawlSpider)
目录 Python网络爬虫之Scrapy框架(CrawlSpider) CrawlSpider使用 爬取糗事百科糗图板块的所有页码数据 Python网络爬虫之Scrapy框架(CrawlSpider) ...
- Python逆向爬虫之scrapy框架,非常详细
爬虫系列目录 目录 Python逆向爬虫之scrapy框架,非常详细 一.爬虫入门 1.1 定义需求 1.2 需求分析 1.2.1 下载某个页面上所有的图片 1.2.2 分页 1.2.3 进行下载图片 ...
- 16.Python网络爬虫之Scrapy框架(CrawlSpider)
引入 提问:如果想要通过爬虫程序去爬取”糗百“全站数据新闻数据的话,有几种实现方法? 方法一:基于Scrapy框架中的Spider的递归爬取进行实现(Request模块递归回调parse方法). 方法 ...
- 16,Python网络爬虫之Scrapy框架(CrawlSpider)
今日概要 CrawlSpider简介 CrawlSpider使用 基于CrawlSpider爬虫文件的创建 链接提取器 规则解析器 引入 提问:如果想要通过爬虫程序去爬取”糗百“全站数据新闻数据的话, ...
- Python分布式爬虫必学框架Scrapy打造搜索引擎
Python分布式爬虫必学框架Scrapy打造搜索引擎 部分课程截图: 点击链接或搜索QQ号直接加群获取其它资料: 链接:https://pan.baidu.com/s/1-wHr4dTAxfd51M ...
- Python分布式爬虫必学框架Scrapy打造搜索引擎 ✌✌
Python分布式爬虫必学框架Scrapy打造搜索引擎 ✌✌ (一个人学习或许会很枯燥,但是寻找更多志同道合的朋友一起,学习将会变得更加有意义✌✌) 第1章 课程介绍 介绍课程目标.通过课程能学习到 ...
- Python分布式爬虫必学框架scrapy打造搜索引擎✍✍✍
Python分布式爬虫必学框架scrapy打造搜索引擎 整个课程都看完了,这个课程的分享可以往下看,下面有链接,之前做java开发也做了一些年头,也分享下自己看这个视频的感受,单论单个知识点课程本身 ...
- python网络爬虫学习笔记
python网络爬虫学习笔记 By 钟桓 9月 4 2014 更新日期:9月 4 2014 文章文件夹 1. 介绍: 2. 从简单语句中開始: 3. 传送数据给server 4. HTTP头-描写叙述 ...
- 爬虫06 /scrapy框架
爬虫06 /scrapy框架 目录 爬虫06 /scrapy框架 1. scrapy概述/安装 2. 基本使用 1. 创建工程 2. 数据分析 3. 持久化存储 3. 全栈数据的爬取 4. 五大核心组 ...
随机推荐
- mongodb limit()和skip()
MongoDB Limit() 方法 如果你需要在MongoDB中读取指定数量的数据记录,可以使用MongoDB的Limit方法,limit()方法接受一个数字参数,该参数指定从MongoDB中读取的 ...
- Spring4.x所有Maven依赖
Spring4.x所有Maven依赖 定义Spring版本号 1 <properties> 2 <org.springframework.version>4.3.7.RELEA ...
- Task.Factory.StartNew和Task.Run
在系统中单开线程进行操作,经常用到Task,发现Task主要有以下两种方法 Task.Factory.StartNew(() => { }); Task.Run(() => { }); 初 ...
- redis on windows
https://github.com/MSOpenTech/redis 下载解压 在/bin/release里还有一个压缩包,这个压缩包是生成好的 解压 运行redis-server 乌拉乌拉说了一堆 ...
- Spring-boot简单的理解
SpringBoot启动 SpringApplication.run(MyBootApplication.class); SpringApplication.run启动SpringBoot应用,主要过 ...
- css3 animation(动画)笔记
在开始介绍Animation之前我们有必要先来了解一个特殊的东西,那就是"Keyframes",我们把他叫做“关键帧”,玩过flash的朋友可能对这个东西并不会陌生.下面我们就一起 ...
- spark算子集锦
Spark 是大数据领域的一大利器,花时间总结了一下 Spark 常用算子,正所谓温故而知新. Spark 算子按照功能分,可以分成两大类:transform 和 action.Transform 不 ...
- django(六):view和cbv
FBV即以函数的形式实现视图函数,CBV即以类的形式实现视图函数:相比而言,CBV根据请求方式书写各自的代码逻辑,结构清晰明了,但是由于多了一层反射机制,性能要差一些:FBV执行效率要高一些,但是代码 ...
- jackson @ResponseBody 处理日期类型的字段
前言:以前只知道一种方式(@JsonFormat)来处理日期格式问题,今天才发现还有两种方式,并且可以全局设置格式,这里记录一下. 首先,pom.xml 中需要先引入如下 jackson 的依赖: & ...
- 浅谈一致性哈希(My转)
一致性哈希(Consistent hashing)算法是由 MIT 的Karger 等人与1997年在一篇学术论文(<Consistent hashing and random trees: d ...