单机安装hive和presto
问题:
公司最近在搞presto,主要是分析一下presto和hive的查询大数据量的性能对比:
我先把我的对比图拿出来(50条数据左右)针对同一条sql(select * from employee where eid = 1203)
hive的查询,下面有时间:4.436s
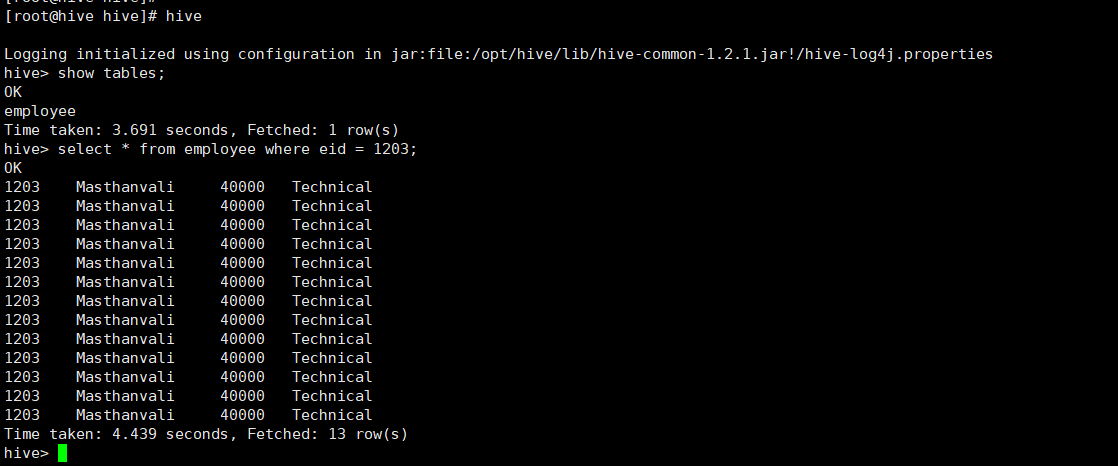
presto的查询: 0.02s
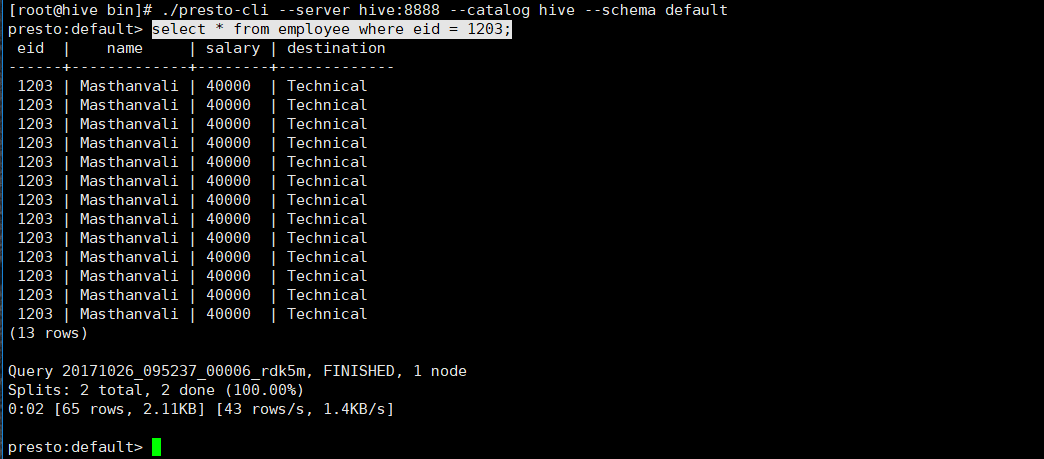
查询效率比为 4.436 / 0.02 === 2021
补充:
presto是什么
Presto是Facebook开发的数据查询引擎,可对250PB以上的数据进行快速地交互式分析。【百度】
我的理解就没那么深了。我认为presto是一个分布式搜索引擎。为了加快查询效率,应对大数据量的查询而产生的:presto不是传统意义上的数据库,
presto产生的目的:
Presto被设计为数据仓库和数据分析产品:数据分析、大规模数据聚集和生成报表。这些工作经常通常被认为是线上分析处理操作。
谁使用Presto:
Presto是FaceBook开源的一个开源项目。Presto在FaceBook诞生,并且由FaceBook内部工程师和开源社区的工程师公共维护和改进。
应用:
扯了那么多,大家应该对presto有点简单的认识了,那就看看怎么应用吧
既然要对比hive和presto的性能问题,那就要面临hadoop环境搭建的问题:下面我简单搭建一下hadoop的单机环境,作为此次的测试环境,
准备软件:链接地址 链接:http://pan.baidu.com/s/1eSaUnYU 密码:5yrg
hadoop-2.6.0.tar
apache-hive-2.1.1
presto-server-0.100.tar
jdk-8u151-linux-x64.tar
注意:其实还需要准备mysql,但是在centos7中默认是Mariadb ,和mysql差不多,直接用这个也行
基本软件准备好,开始安,安装我分为两部分:
1.安装的准备工作(ssh 防火墙,主机名,jdk等配置)
2.软件的安装(mysql,hadoop,hive,presto的安装配置)
安装准备工作:
1> 我是单机测试:所以要把防火墙关闭,防止端口访问不了的问题
centos7的命令是:
systemctl stop firewalld
systemctl disable firewalld ---禁止防火强开启启动
setenforce 0 -- 关闭selinux
修改/etc/selinux/config ,设定 SELINUX=disabled --测底关闭selinux
2> 创建用户(无所谓,为了更正式我写上了,一般用root权限太大,防止出错,无法恢复)
创建用户hive,并以/home/hive 作为所有组件的Home,java例外
3> ssh的免密登录(单机无所谓,集群要分批拷贝到slave机器上)
确保是在/home/hive目下,执行以下命令
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
chmod 644 ~/.ssh/authorized_keys
4>修改hosts文件:
5> jdk的安装(为啥要用jdk8会在最后讲解错误的时候解释,耐心点,往后看)
把jdk8放在/usr/local下:解压即可(由于我在原有集群上改的,jdk的名字还保留原来的,只是把解压后的jdk8的文件放在这个文件夹里面了,这样不影响我原来集群的运行)
tar -zxvf jdk-8u151-linux-x64.tar.gz
6>修改/etc/profile 让环境变量java生效: 执行此命令 source /etc/profile (最后也就安装那么多东西)
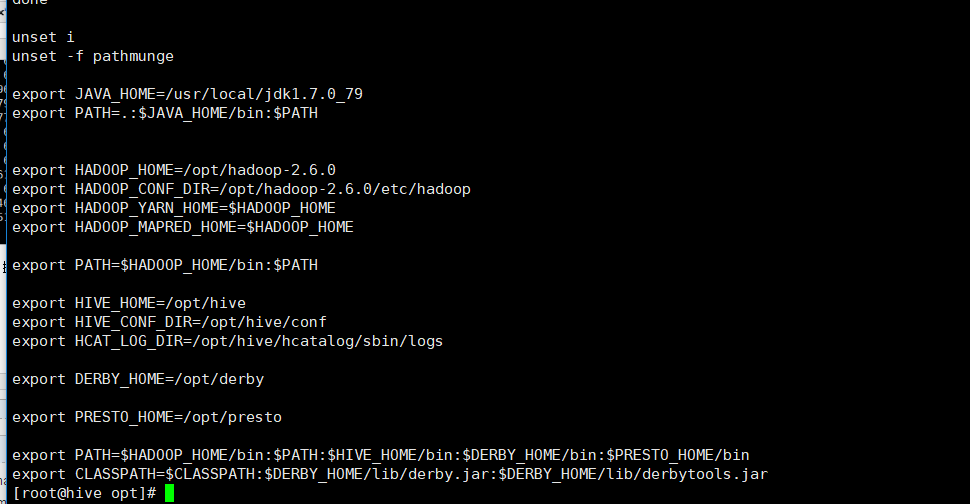
至此,安装前的准备工作已经准备完毕:
软件安装过程:
先安装mysql | 或者mariaDB(centos默认带有的。我直接用这个了)
第一步:
yum -y install MariaDB-client MariaDB-server MariaDB-devel
第二步:开启服务:
service mysql start
第三步:设置密码:(默认无密码)
mysqladmin -u root password ‘888888’
连接数据库:成功如下:
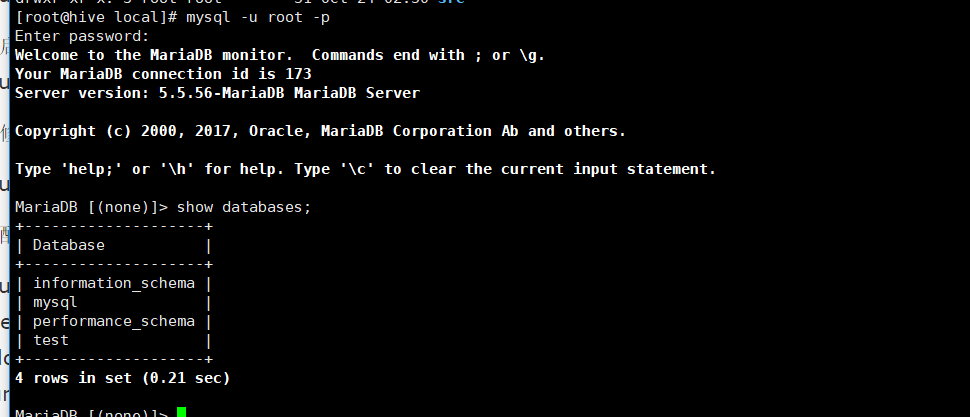
关于授权问题我就不扯了。想玩的去找度娘。安装到这没问题的话就完成30%了,继续加油,搞起来!!!!!
下面安装hadoopl了(兴奋。。。。)
把hadoop2.6 上传到/opt下 如下图:(我把其他软件也放在这了,下面就不说了)
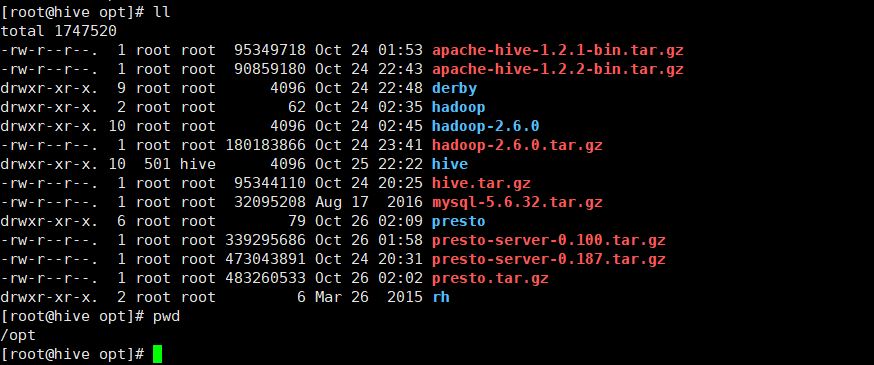
1> 解压hadoop:
2> 在profile中配置hadoop的HADOOP_HOME PATH等,然后source /etc/profile生效
3> 设置hadoop的一些配置文件
先创建一些目录,在core-site.xml hdfs-site,xml中配置要使用:
mkdir -p /home/hadoop/hadoop/tmp
mkdir -p /home/hadoop/hadoop/hdfs
mkdir -p /home/hadoop/hadoop/hdfs/data
mkdir -p /home/hadoop/ hadoop/hdfs/name
3.1》进入到hadoop目录中 进入到 $HADOOP_HOME/etc/hadoop中:
修改hadoop_env.sh,yarn-env.sh,mapred-env.sh 加上JAVA_HOME的路径 export JAVA_HOME=/usr/local/jdk1.7.0_79
3.2》 配置hadoop的四大金刚(core | hdfs | yarn | mapred ).xml文件
配置core
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hive:9001</value>
<description>HDFS的URI,文件系统://namenode标识:端口号,默认是9000</description>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/hadoop/tmp</value>
<description>namenode上本地的hadoop临时文件夹</description>
</property>
<property>
<name>ipc.client.connect.max.retries</name>
<value>100</value>
<description>默认10次,现在配置100次</description>
</property>
<property>
<name>ipc.client.connect.retry.interval</name>
<value>10000</value>
<description>连接间隔1秒钟,默认是0.1秒</description>
</property>
</configuration>
配置hdfs
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/hadoop/hadoop/hdfs/name</value>
<description>namenode上存储hdfs名字空间元数据 </description>
</property>
<property>
<name> dfs.datanode.data.dir</name>
<value>/home/hadoop/hadoop/hdfs/data</value>
<description>datanode上数据块的物理存储位置</description>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
<description>副本个数,配置默认是3,应小于datanode机器数量</description>
</property>
<property>
<name>dfs.namenode.rpc-address</name>
<value>hive:9001</value>
<description>RPC address that handles all clients requests。有人说需要和fs.defaultFS 一样端口</description>
</property>
配置yarn
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>hive:8099</value>
<description>用于管理集群的资源,可以通过浏览器访问 </description>
</property>
<property>
<name>yarn.nodemanager.webapp.address</name>
<value>hive:8042</value>
<description>用于管理节点,可以通过浏览器访问 </description>
</property>
配置mapred
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
最后:slaves
hive
4>启动并验证
$HADOOP_HOME/bin/hdfs namenode –format --这个执行一次即可。
$HADOOP_HOME/sbin/start-dfs.sh
$HADOOP_HOME/sbin/start-yarn.sh
telnet 测试对应端口是不是能连接上:
输入jps看看服务是不是都能起来:

测试结果:
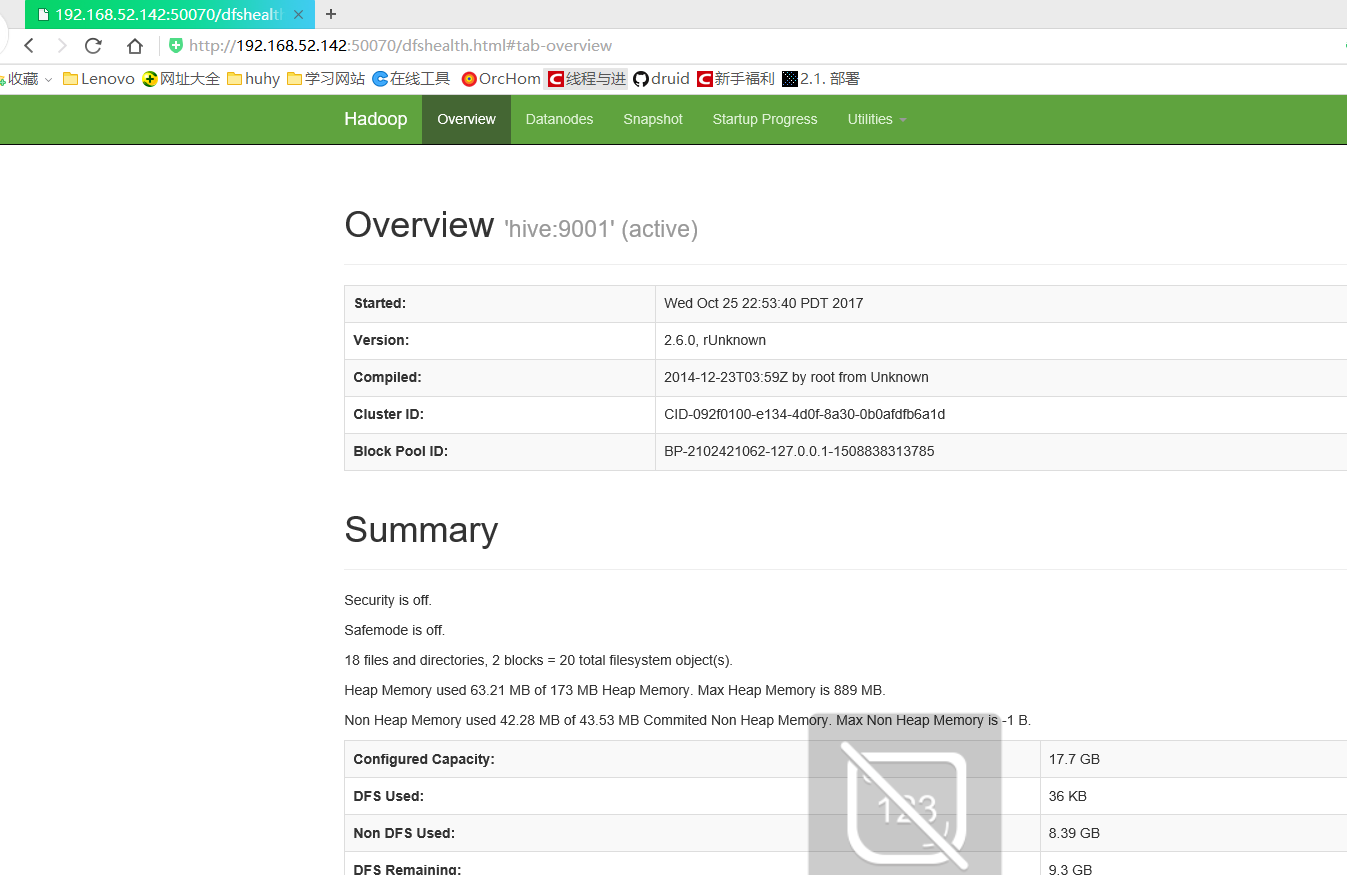

至此hadoop安装完毕,测试完毕:不错完成60%
安装hive :
1>上传到 /opt上 解压 在/etc/profile 配置环境变量位置 让环境变量生效 source /etc/profile
2> 创建一些hive的保存目录
准备hdfs路径
hdfs dfs -mkdir -p /warehouse
hdfs dfs -mkdir -p /tmp/hive
hdfs dfs -chmod 773 /warehouse
hdfs dfs -chmod 773 /tmp/hive
3> cd $HIVE_HOME/conf下修改hive-env.sh ,hive-site.xml (如果没有就用模板修改)
修改hive-env.sh
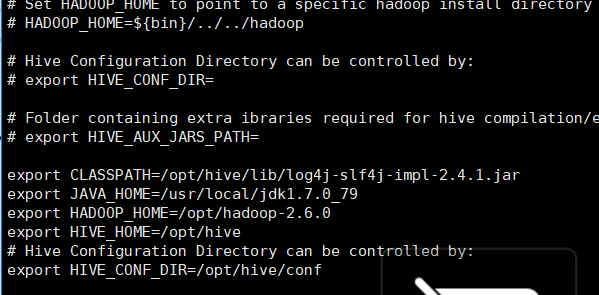
修改hive-site.xml
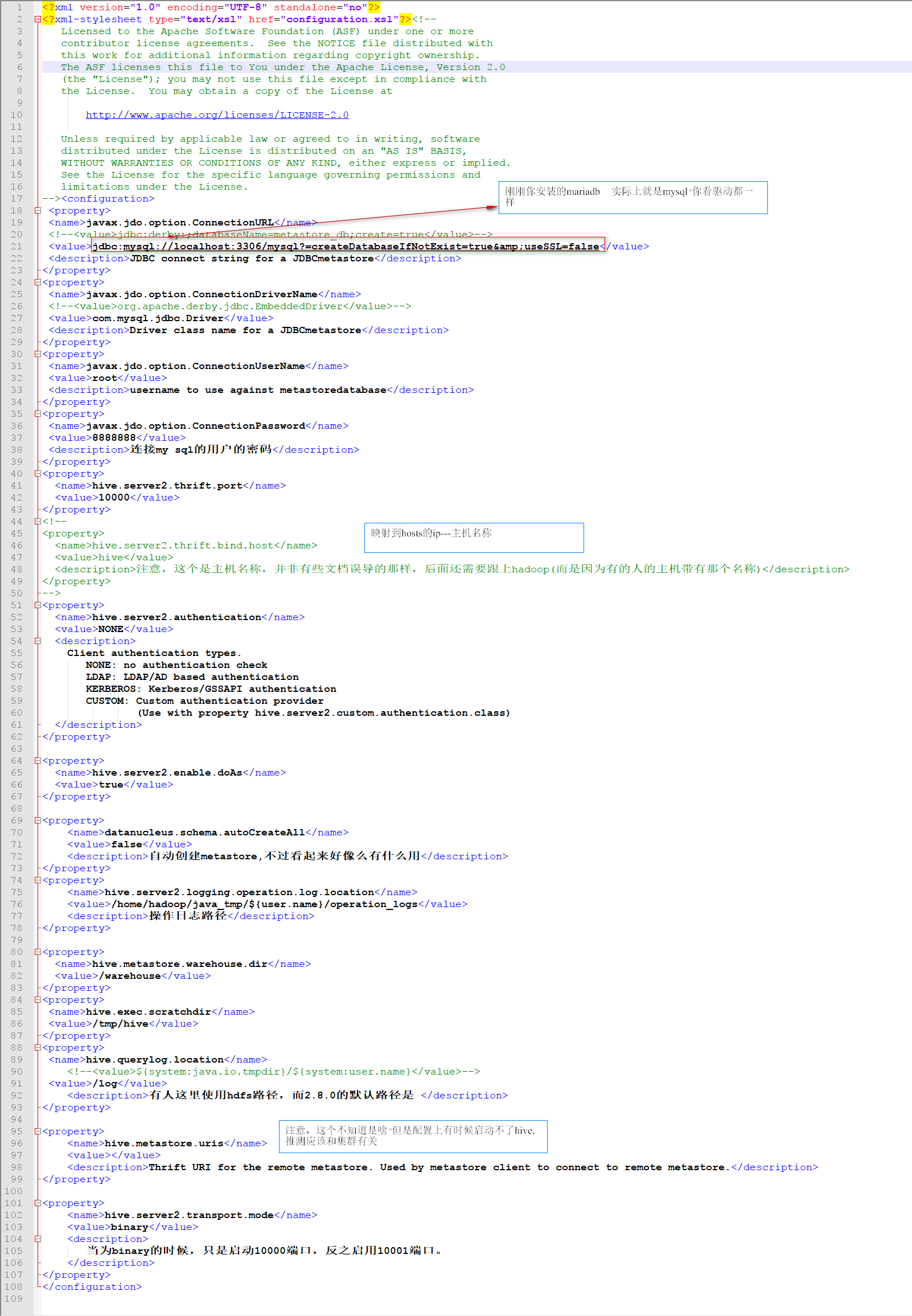
到此。hive安装完毕:
注意。网上有的说要进行初始化:$HIVE_HOME/bin/schematool -dbType mysql -initSchema (但我没执行这步也ok)【待考证】
启动 hive
hive --service metastore
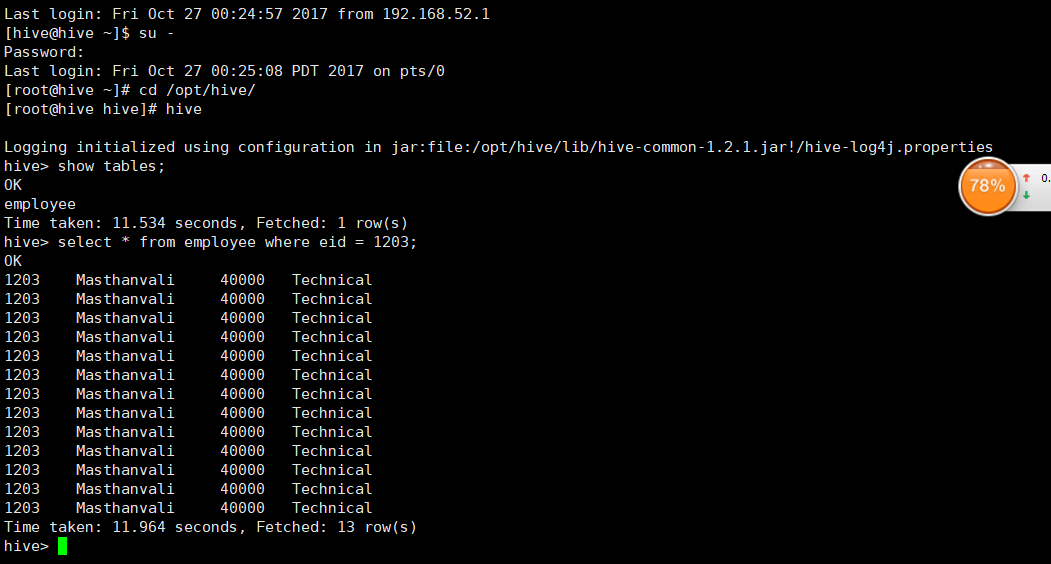
此时,在hive的安装目录任意位置,输入hive启动,然后jps 会出现RunJar这个进程
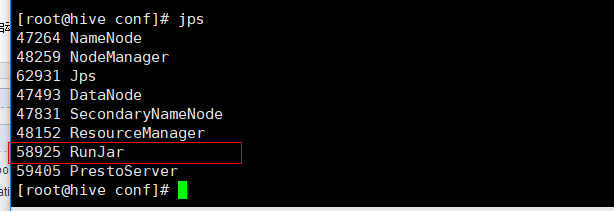
说明hive启动时正常的,侧面验证hive安装成功:
安装presto 安装参考
1》老规矩,上传到/opt 解压 配置profile 执行source /etc/profile 让变量生效
2》因为presto中的文件夹啥的自己创建:
创建目录
mkdir -p $PRESTO_HOME/etc/catalog
mkdir -p /home/hadoop/data_presto/data
关于etc下的其他文件和catalog文件夹:不扯淡,上官网解释

在我机器上的配置如下:
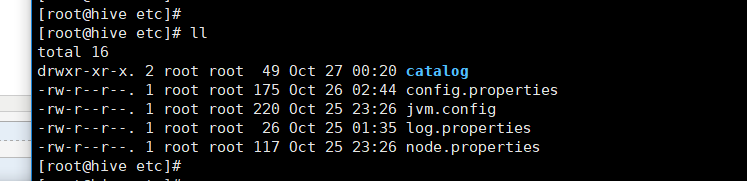
node.properties
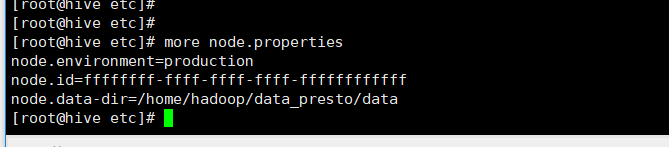
config.properties

jvm.config
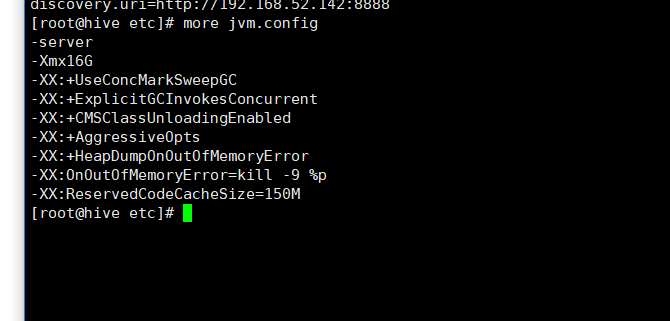
log.properties

进入catalog文件夹下,配置数据源的信息,我连接的是hive,然后就配置个hive.preperties文件即可:

到这,presto的配置也完毕了。
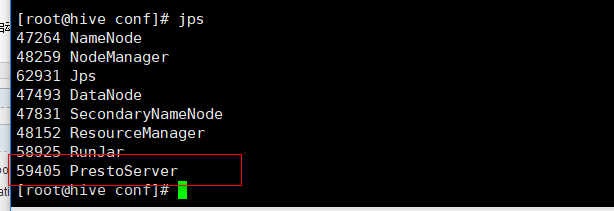
进入bin目录下,启动测试一把:
cd $PRESTO_HOME/bin 执行 ./launcher start 然后进程会出现PrestoServer
测试config的路径连接 我的是http:192.168.52.142:8888 成功如下: 会记录你的presto的每一步操作信息
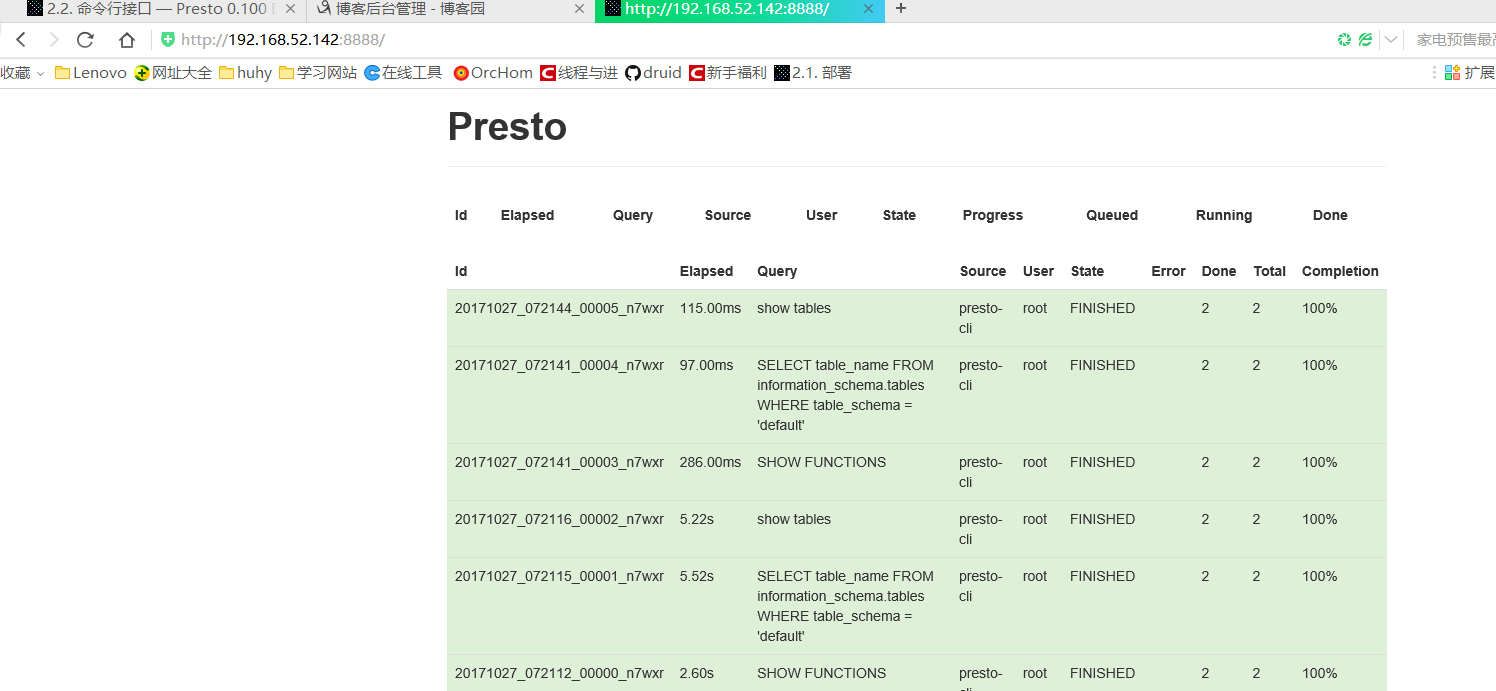
至此整个hadoop+hive +presto搭建完毕了!!!!!!!!!!!!!!
还没结束:还有一点presto的cli介绍一下: 安装server是:presto-server-0.100.tar
下载对应版本的 presto-cli-0.100-executable 不然会报错的:
分为三步:
1》上传 j解压 改名presto-cli:
2》改权限 chmod +x presto-cli
3》mv移动到bin目录下
4》命令行连接:在bin目录下运行
./presto-cli --server hive:8888 --catalog hive --schema default
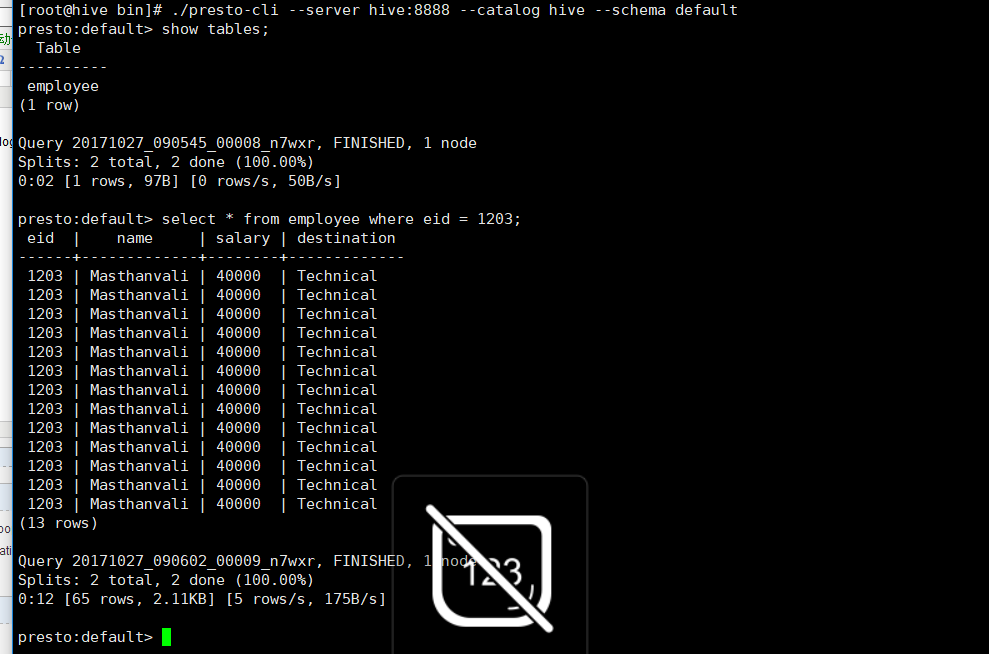
有人会问,你咋知道连接到hive了,那我用hive连接一下,验证一下
常见错误总结:
1》错误一:
Error: Defunct property 'task.max-memory' (class [class com.facebook.presto.execution.TaskManagerConfig]) cannot be configured. at com.facebook.presto.server.ServerMainModule.setup(ServerMainModule.java:254)
这是因为版本不一致造成的,所以我说的是server和cli版本要一致,我用的都是0.100版本:
2》错误二
连接拒绝 refused. Connected........
那就是prestoServer的进程没起来 ./laucher start这一步失败,去presto家目录看看配置文件是不是写错了
3》错误三
在config.properties中设置node-scheduler.include-coordinator=true
4》错误四
jdk 1.8 使用与server 0.86以上版本 0.85以下 jdk 1.7版本(这也是一开始为啥我把我的jdk7换成8的原因)
单机安装hive和presto的更多相关文章
- 单机安装hadoop+hive+presto
系统环境 在个人笔记本上使用virtualbox虚拟机 os:centos -7.x86-64.everything.1611 ,内核 3.10.0-514.el7.x86_64 注:同样可以使用r ...
- hive单机安装(实战)
hive使用与注意事项:http://blog.csdn.net/stark_summer/article/details/44222089 连接命令:beeline -n root -u jdbc: ...
- 安装Hive(独立模式 使用mysql连接)
安装Hive(独立模式 使用mysql连接) 1.默认安装了java+hadoop 2.下载对应hadoop版本的安装包 3.解压安装包 tar zxvf apache-hive-1.2.1-bin. ...
- 附录C 编译安装Hive
如果需要直接安装Hive,可以跳过编译步骤,从Hive的官网下载编译好的安装包,下载地址为http://hive.apache.org/downloads.html . C.1 编译Hive C.1 ...
- 一步一步安装hive
安装hive 1.下载hive-0.11.0.tar.gz,解压; 2.下载mysql-connector-java-5.1.29-bin.jar并放到hive/lib/下: 3.配置hive/con ...
- (原) 1.1 Zookeeper单机安装
本文为原创文章,转载请注明出处,谢谢 zookeeper 单机安装配置 1.安装前准备 linux系统(此文环境为Centos6.5) Zookeeper安装包,官网https://zookeeper ...
- Linux下Kafka单机安装配置方法(图文)
Kafka是一个分布式的.可分区的.可复制的消息系统.它提供了普通消息系统的功能,但具有自己独特的设计.这个独特的设计是什么样的呢 介绍 Kafka是一个分布式的.可分区的.可复制的消息系统.它提供了 ...
- Ubuntu 下 Neo4j单机安装和集群环境安装
1. Neo4j简介 Neo4j是一个用Java实现的.高性能的.NoSQL图形数据库.Neo4j 使用图(graph)相关的概念来描述数据模型,通过图中的节点和节点的关系来建模.Neo4j完全兼容A ...
- ubuntu安装hive
1.安装mysql,可参考下面链接 http://www.cnblogs.com/liuchangchun/p/4099003.html 2.安装hive,之前,先在mysql上创建一个hive,数据 ...
随机推荐
- 部署nexus服务
一.安装和启动 官网下载nexus-2.12安装包,地址:https://sonatype-download.global.ssl.fastly.net/nexus/oss/nexus-2.12.0- ...
- Vue.js系列之一初识Vue
在看vue.js之前,可以先看这两篇文章,对于为什么要使用vue会有一定帮助 1.Vue.js !important 2.界面之下:还原真实的MV*模式 !important 3.web前端优化之re ...
- [转]Elasticsearch Java API总汇
http://blog.csdn.net/changong28/article/details/38445805#comments 3.1 集群的连接 3.1.1 作为Elasticsearch节点 ...
- 【树】Flatten Binary Tree to Linked List(先序遍历)
题目: Given a binary tree, flatten it to a linked list in-place. For example,Given 1 / \ 2 5 / \ \ 3 4 ...
- 自己动手实现一个WEB服务器
自己动手实现一个 Web Server 项目背景 最近在重温WEB服务器的相关机制和原理,为了方便记忆和理解,就尝试自己用Java写一个简化的WEB SERVER的实现,功能简单,简化了常规服务器的大 ...
- j2ee高级开发技术课程第一周
一.课程目标 这学期开始了J2EE高级开发技术这门课,在此之前我学习了javaSE,为这门课的学习打下了一定的基础.到这学期的结束我希望我能熟悉javaee,能开发企业级应用,对开发轻量级企业应用的主 ...
- 13-hadoop-入门程序
通过之前的操作, http://www.cnblogs.com/wenbronk/p/6636926.html http://www.cnblogs.com/wenbronk/p/6659481.ht ...
- nuxt踩过的坑
nuxt.js 简单介绍 nuxt官网:https://zh.nuxtjs.org/ 1.nuxt.js的原理图: 具体的原理介绍官网有详细的解释,欢迎移步官网,这里不再复述. 2.nuxt.js的优 ...
- spring cloud连载第三篇之Spring Cloud Netflix
1. Service Discovery: Eureka Server(服务发现:eureka服务器) 1.1 依赖 <dependency> <groupId>org.spr ...
- Tornado简介
Tornado是一个具有强大异步功能的Python Web框架. Hello World 使用pip安装tornado: pip install tornado 编写控制器: import torna ...