08python语法入门--基本数据类型及内置方法
数字类型int与float
定义
类型转换
使用
字符串
定义
类型转换
使用
优先掌握的操作
需要掌握的操作
了解操作
列表
定义
类型转化
使用
优先掌握的操作
需要掌握的操作
了解操作
元组
作用
定义方法
类型转换
使用
字典
定义
类型转换
使用
优先掌握的操作
需要掌握的操作
集合
作用
定义
类型转换
使用
关系运算
去重
其他操作
练习
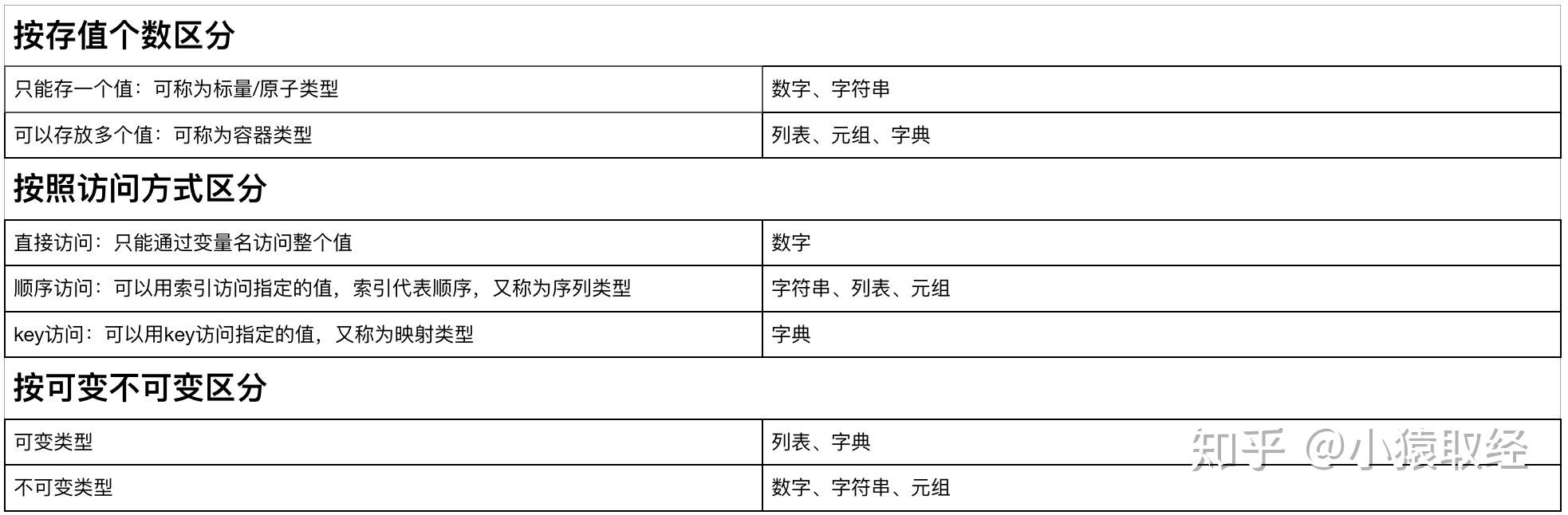
可变类型与不可变类型
数据类型总结
一、数字类型int、float
定义
# 定义:
# 整形int的定义
age = 10 # 本质:age = int(20)
# 浮点型float的定义
salary = 3000.3 # 本质:salary = float(3000.3)
# 注意:名字+括号的意思就是调用某个功能,比如:
# print(...)调用打印功能
# int(...)调用创建整形数据功能
# float(...)调用创造浮点型数据功能
类型转换
# 数据类型转换
# int()可以将由纯整数构成的字符串直接转换成整形,若包含其他任意非整数符号,则会报错
>>> s = '123'
>>> res = int(s)
>>> res,type(res)
(123, <class 'int'>)
>>> int('12.3')
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ValueError: invalid literal for int() with base 10: '12.3'
# 进制转换
# 十进制转其他进制
>>> bin(3)
'0b11'
>>> oct(9)
'0o11'
>>> hex(17)
'0x11'
# 其他进制转十进制
>>> int('0b11',2)
3
>>> int('0o11',8)
9
>>> int('0x11',16)
17
# float同样可以用来做数据类型的转换
>>> s = '12.3'
>>> res = float(s)
>>> res,type(res)
(12.3, <class 'float'>)
使用
数字类型主要就是用来做数学运算和比较运算,因此数字类型除了掌握与运算符结合使用之外,并无需要掌握的内置方法
二、字符串
定义
# 定义:在单引号、双引号、三引号内包含的一串字符
name1 = 'json' # 本质:name = str('任意形式内容')
name1 = "json" # 本质:name = str("任意形式内容")
name1 = """json""" # 本质:name = str("""任意形式内容""")
类型转换
# 数据类型转换:str()可以将任意数据类型转换成字符串类型,例如
>>> type(str([1,2,3])) # list->str
<class 'str'>
>>> type(str({'name':'jason','age':'18'})) # dict->str
<class 'str'>
>>> type(str((1,2,3))) # tuple->str
<class 'str'>
>>> type(str({1,2,3,4})) # set->str
<class 'str'>
使用
优先掌握的操作
>>> str1 = 'hello python!'
# 1.按索引取值
# 正向取
>>> str1[6]
'p'
# 反向取
>>> str1[-4]
'h'
# 对于str来说,只能按照索引取值,不能改
>>> str1[0]='H'
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: 'str' object does not support item assignment
# 2.切片
# 顾头不顾尾
>>> str1[0:9]
'hello pyt'
# 步长:第三个参数2代表步长,会从0开始,每次累加一个2即可,所以会取出索引0,2,4,6,8的字符
>>> str1[0:9:2]
'hlopt'
# 反向切片:-1表示从右往左依次取值
>>> str1[::-1]
'!nohtyp olleh'
# 3.长度len
# 获取字符串的长度,即字符的个数,但凡存在于引号内的都算作字符
>>> len(str1)
13
# 4.成员运算 in 和 not in
>>> 'hello' in str1
True
>>> 'tony' not in str1
True
# 5.strip移除字符串首尾指定的字符(默认移除空格)
# 括号内不指定字符,默认移除首位空白字符(空格、\n、\t)
>>> str1 = ' life is short! '
>>> str1.strip()
life is short!
# 括号内指定字符,移除首位指定的字符
>>> str2 = '**tony**'
>>> str2.strip('*')
tony
# 6.切分split
# 括号内不指定字符,默认以空格作为分隔符
>>> str3 = 'hello world'
>>> str3.split()
['hello','world']
# 括号内指定分隔符,则按照括号内指定的字符切割字符串
>>> str4 = '127.0.0.1'
>>> str4.split('.')
['127','0','0','1'] # 注意:split切割得到的结果是列表数据类型
# 7.循环
>>> str5 = '今天你好吗?'
>>> for line in str5:
... print(line)
...
今
天
你
好
吗
?
需要掌握的操作
1.strip,lstrip,rstrip (left、right)
>>> str1 = '**tony***'
>>> str1.strip('*')
'tony'
>>> str1.lstrip('*')
'tony***'
>>> str1.rstrip('*')
'**tony'
2.lower(),upper() 小写大写转换
>>> str2 = 'My nAme is tonY!'
>>> str2.lower()
'my name is tony!'
>>> str2.upper()
'MY NAME IS TONY!'
3.startswith,endswith
>>> str3 = 'tony jam'
# startswith()判断字符串是否以括号内指定的字符开头,结果为布尔值true或False
>>> str3.startswith('t')
True
>>> str3.startswith('j')
False
# endswith()判断字符串是否以括号内指定的字符开头,结果为布尔值true或False
>>> str3.endswith('jam')
True
>>> str3.endswith('tony')
False
4.格式化输出之format
之前我们使用%s来做字符串的格式化输出,在传值时,必须严格按照位置与%s一一对应,而字符串的内置方法format则提供了一种不依赖位置的传值方式
案例:
# format括号内在传参数时完全可以打乱顺序,但仍然能指名道姓地为指定的参数传值,name='tony'就是传给{name}
>>> str4 = 'my name is {name},my age is {age}!'.format(age=18,name='egon')
>>> str4
'my name is egon,my age is 18!'
>>> str4 = 'my name is {name}{name}{name},my age is {name}!'.format(name = 'tony',age=18)
>>> str4
'my name is tonytonytony,my age is tony!'
format的其他使用方式(了解)
# 类似于%s的用法,传入的值会按照位置与{}一一对应
>>> str4 = 'my name is {},my age is{}!'.format('tony',18)
>>> str4
'my name is tony,my age is18!'
# 把format传入的多个值当作一个列表,然后用{索引}取值
>>> str4 = 'my name is {0},my age is{1}!'.format('tony',18)
>>> str4
'my name is tony,my age is18!'
>>>
>>> str4 = 'my name is {1},my age is{1}!'.format('tony',18)
>>> str4
'my name is 18,my age is18!'
5.split,rsplit
# split会按照从左到右的顺序对字符串进行切分,可以指定切割次数
>>> str5 = 'C:/a/b/c/d.txt'
>>> str5.split('/',1)
['C:', 'a/b/c/d.txt']
# rsplit刚好与split相反,从右往左切割,可以指定切割次数
>>> str5.rsplit('/',1)
['C:/a/b/c', 'd.txt']
6.join
# 从可迭代对象中取出多个字符串,然后按照指定的分隔符进行拼接,拼接的结果为字符串
>>> '%'.join('hello')
'h%e%l%l%o'
>>> '|'.join(['tony','18','read'])
'tony|18|read'
7.replace
# 用新的字符替换字符串中旧的字符
>>> str7 = 'my name is tony,my age is 18!'
>>> str7 = str7.replace('18','73')
>>> str7
'my name is tony,my age is 73!'
# 可以指定修改的个数
>>> str7 = 'my name is tony,my age is 18!'
>>> str7 = str7.replace('my','MY',1) # 只把第一个my改为MY
>>> str7
'MY name is tony,my age is 18!'
8.isdigit
# 判断字符串是否时纯数字组成,返回结果为True或False
>>> str8 = '5201314'
>>> str8.isdigit()
True
>>>
>>> str8 = '123g123'
>>> str8.isdigit()
False
了解操作
# 1.find,rfind(略),index,rindex(略),count
# find:从指定范围内查找子字符串的起始索引,找得到则返回数字1,找不到则返回-1
>>> msg = 'tony say hello'
>>> msg.find('o',1,3) # 在索引为1和2(顾头不顾尾)的字符中查找字符o的索引
1
# index:同find,但在找不到时会报错
>>> msg.index('e',2,4) # 报错ValueError
# count:统计字符串在大字符串中出现的次数
>>> msg='hello everyone'
>>> msg.count('e') # 统计字符串e出现的次数
4
>>> msg.count('e',1,6) # 字符串e在索引1-5范围内出现的次数
1
# 2.center,ljust,rjust,zfill
>>> name = 'tony'
>>> name.center(30,'-') # 总宽度为30,字符串居中显示,不够用-填充
'-------------tony-------------'
>>> name.ljust(30,'*') # 总宽度为30,字符串左对齐显示,不够用*填充
'tony**************************'
>>> name.rjust(30,'*') # 总宽度为30,字符串右对齐显示,不够用*填充
'**************************tony'
>>> name.zfill(50) # 总宽度为50,字符串右对齐显示,不够用0填充...z代表zero
'0000000000000000000000000000000000000000000000tony'
# 3.expandtabs
>>> name = 'hello\tworld' # \t代表制表符(tab键)
>>> print(name)
hello world
>>> name.expandtabs(1) # 修改\t制表符代表的空格数
'hello world'
# 4.captalize,swapcase,title
# capitalize:首字母大写
>>> message = 'hello everyoen nice to meet you!'
>>> message.capitalize()
'Hello everyoen nice to meet you!'
# swapcase:大小写翻转
>>> message1 = 'Hi girl,I want to make friends with you!'
>>> message1.swapcase()
'hI GIRL,i WANT TO MAKE FRIENDS WITH YOU!'
# title:每个首字母大写
>>> msg = 'dear my friend,i miss you so much'
>>> msg.title()
'Dear My Friend,I Miss You So Much'
# is数字系列
# 在python3中
>>> num1 = b'4' # bytes
>>> num2 = u'4' # unicode,python3中无需加u就是unicode
>>> num3 = '四' # 中文数字
>>> num4 = 'IV' # 罗马数字
# isdigit:bytes,unicode
>>> num1.isdigit()
True
>>> num2.isdigit()
True
>>> num3.isdigit()
False
>>> num4.isdigit()
False
# isdecimal:unicode(bytes类型无isdecimal方法)
>>> num2.isdecimal()
True
>>> num3.isdecimal()
False
>>> num4.isdecimal()
False
# isnumberic:unicode,中文数字,罗马数字(bytes类型无isnumberic方法)
>>> num2.isnumberic()
True
>>> num3.isnumberic()
True
>>> num4.isnumberic()
True
# 三者不能判断浮点数
>>> num5 = '4.3'
>>> num5.isdigit()
False
>>> num5.isdecimal()
False
>>> num5,isnumberic()
False
'''
# 总结:
最常用的是isdigit,可以判断bytes和uncode类型,这也是最常用的数字应用场景
如果要判断中文数字或罗马数字,则需要用到isnumberic
'''
# 6.is其他
>>> name = 'tony123'
>>> name.isalnum() # 字符串中既可以包含数字也可以包含字母
True
>>> name.isalpha() # 字符串中只包含字母
False
>>> name.islower() # 字符串是否是纯小写
True
>>> name.isupper() # 字符串是否是纯大写
False
>>> name.isspace() # 字符串是否全是空格
False
>>> name.istitle() # 字符串中的单词首字母是否都是大写
False
>>>
三、列表
定义
# 定义:在[]内,用逗号分隔开多个任意数据类型的值
l1 = [1, 'a', [1, 2]] # 本质:l1 = list[1, 'a', [1, 2]]
类型转换
# 但凡能被for循环遍历的数据类型都可以传给list()转换成列表类型,list()会跟for循环一遍历出数据类型中包含的每一个元素然后放到列表中
>>> list('wdad')
['w', 'd', 'a', 'd']
>>> list([1,2,3])
[1, 2, 3]
>>> list({'name':'jason','age':18})
['name', 'age']
>>> list((1,2,3))
[1, 2, 3]
>>> list({1,2,3,4})
[1, 2, 3, 4]
使用
优先掌握的操作
# 1.按索引存取值(正向取值+反向取值):既可存也可取
# 正向取(从左往右)
>>> my_friends = ['tony','json','tom',4,5]
>>> my_friends[0]
'tony'
# 反向取(负号表示从右往左)
>>> my_friends[-1]
5
# 对于list来说,既可以按照索引取值,又可以按照索引修改指定位置的值,但是如果索引不存在就会报错
>>> my_friends = ['tony','jack','tom',4,5]
>>> my_friends[1]='martthow'
>>> my_friends
['tony', 'martthow', 'tom', 4, 5]
# 2.切片(顾头不顾尾,步长)
>>> my_friends[0:4] # 取出索引0-3的元素
['tony', 'martthow', 'tom', 4]
>>> my_friends[0:4:2] # 第三个参数2代表步长,会从0开始,每次累加一个2即可,所以会取出索引0、2的元素
['tony', 'tom']
# 长度
>>> len(my_friends)
5
# 成员运算in和not in
>>> 'tony' in my_friends
True
>>> 'xxx' not in my_friends
True
# 3.添加
# append():列表尾部追加元素
>>> l1 = ['a','b','c']
>>> l1.append('d')
>>> l1
['a', 'b', 'c', 'd']
# extend()一次性在列表尾部添加多个元素
>>> l1.extend(['a','b','c'])
>>> l1
['a', 'b', 'c', 'd', 'a', 'b', 'c']
# insert()在指定位置插入元素
>>> l1.insert(0,'first') # 0表示按索引位置插值
>>> l1
['first', 'a', 'b', 'c', 'd', 'a', 'b', 'c']
# 4.删除
# del
>>> l=[11,22,33,44]
>>> del l[2]
>>> l
[11, 22, 44]
# pop():默认删除列表最后一个元素,并将删除的值返回,括号内可以通过加索引值来指定删除元素
>>> l = [11,22,33,22,44]
>>> res = l.pop()
>>> res
44
>>> res = l.pop(1)
>>> res
22
# remove()括号内指名道姓表示要删除哪个元素,没有返回值
>>> l = [11,22,33,44]
>>> res = l.remove(22) # 从左往右查找第一个括号内需要删除的元素
>>> print(res)
None
# 5.排序
# reverse()颠倒列表内元素顺序
>>> l=[11,22,33,44]
>>> l.reverse()
>>> l
[44, 33, 22, 11]
# sort()给列表内所有元素排序
# 排序时列表元素之间必须是相同数据类型,不可混搭,否则报错
>>> l=[11,22,3,42,55]
>>> l.sort()
>>> l
[3, 11, 22, 42, 55] # 默认从小到大排序
>>> l = [11,22,3,43,7,55]
>>> l.sort(reverse=True) # reverse用来指定是否颠倒排序,默认为False
>>> l
[55, 43, 22, 11, 7, 3]
# 6.了解知识
# 我们常用的数字类型直接比大小,但其实,字符串、列表等都可以比较大小,原理相同:都是依次比较对应位置的元素的大小,如果分出大小,则无需比较下一个元素,比如
>>> l1=[1,2,3]
>>> l2=[2,]
>>> l2>l1
True
字符之间的大小取决于它们在ASCII表中的先后顺序,越往后越大
>>> s1='abc'
>>> s2='az'
>>> s2>s1 # s1与s2的第一个字符没有分出胜负,但第二个字符'z'>'a',所以s2>s1成立
True
# 所以我们也可以对下面这个列表排序
>>> l = ['A','z','adjk','hello','hea']
>>> l.sort()
>>> l
['A', 'adjk', 'hea', 'hello', 'z']
# 7.循环
# 循环遍历my_friends列表里面的值
>>> for line in my_friends:
... print(line)
···
'tony'
'jack'
'jason'
4
5
了解操作
>>> l=[1,2,3,4,5,6]
>>> l[0:3:1]
[1, 2, 3] # 正向步长
>>> l[2::-1]
[3, 2, 1] # 反向步长
# 通过索引取值实现列表反转
>>> l[::-1]
[6, 5, 4, 3, 2, 1]
四、元组
作用
元组与列表类似,也是可以存多个任意类型的元素,不同之处在于元组的元素不能修改,即元组下相当于不可变的列表,用于记录多个固定不允许修改的值,单纯用于取
定义方式
# 在()内用都好分隔开多个任意类型的值
>>> countries = ("中国","美国","英国") # 本质:countries = tuple("中国","美国","英国")
# 强调:如果元组内只有一个值,则必须加一个逗号,否则()就只是包含的意思而非定义元组
>>> countyies = ('中国',) # 本质:countyies = tuple('中国')
类型转换
# 但凡能够被for循环遍历的数据类型都可以传给tuple()转换成元Zu类型
>>> tuple('wdad')
('w', 'd', 'a', 'd')
>>> tuple([1,2,3])
(1, 2, 3)
>>> tuple({'name':'jason','age':'18'})
('name', 'age')
>>> tuple((1,2,3))
(1, 2, 3)
>>> tuple({1,2,3,4})
(1, 2, 3, 4)
# tuple()会跟for循环一样遍历出数据类型中包含的每一个元素然后放到元组中
使用
>>> tuple = (1, 'hhaha', 15000.00, 11, 22, 33)
# 按索引取值(正向取、反向取):只能取不能改,否则报错
>>> tuple[0]
1
>>> tuple[-2]
22
>>> tuple[0] = 'hehe'
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: 'tuple' object does not support item assignment
# 切片(顾头不顾尾,步长)
>>> tuple1[0:6:2]
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
NameError: name 'tuple1' is not defined
>>> tuple[0:6:2]
(1, 15000.0, 22)
# 长度
>>> len(tuple)
6
# 成员运算
>>> 'hhaha' in tuple
True
>>> 'hhaha' not in tuple
False
# 循环
>>> for line in tuple:
... print(line)
...
1
hhaha
15000.0
11
22
33
五、字典
定义方式
# 定义:在{}内用都好隔开多个元素,每一个元素都是key:value的形式,其中value可以是任意类型,而key则必须是不可变类型,通常key应该是str类型,因为str类型会对value有描述性的功能
info = {'name':'tony','age':18,'sex':'male'} # 本质info = dict({...})
# 也可以这样定义字典
info = dict(name='tony',age=18,'sex'='male') # info = {'name':'tony','age':18,'sex':'male'}
类型转换
# 转换1:
>>> info = dict([['name','tony'],('age',18)])
>>> info
{'name': 'tony', 'age': 18}
# 转换2:fromkey会从元组中取出每个值当作key,然后与None组成key:value放到字典中
>>> {}.fromkeys(('name','age','sex'),None)
{'name': None, 'age': None, 'sex': None}
使用
优先掌握的操作
# 1.按keycunqu值:可存可取
# 1.1取
>>> dic = {
... 'name':'xxx',
... 'age':18,
... 'hobbies':['play game','basketball']
... }
>>> dic['name']
'xxx'
>>> dic['hobbies'][1]
'basketball'
# 1.2 对于赋值操作,如果key原先不存在于字典,则会新增key:value
>>> dic['gender']='male'
>>> dic
{'name': 'xxx', 'age': 18, 'hobbies': ['play game', 'basketball'], 'gender': 'male'}
# 1.3 对于赋值操作,如果key原先存在于字典,则会修改对应value的值
>>> dic['name']='tony'
>>> dic
{'name': 'tony', 'age': 18, 'hobbies': ['play game', 'basketball'], 'gender': 'male'}
# 2、长度len
>>> len(dic)
3
# 3、成员运算in和not in
>>> 'name' in dic # 判断某个值是否是字典的key
True
# 4、删除
>>> dic.pop('name') # 通过指定字典的key来删除字典的键值对
>>> dic
{'age': 18, 'hobbies': ['play game', 'basketball']}
# 5、键keys(),值values(),键值对items()
>>> dic = {'age': 18, 'hobbies': ['play game', 'basketball'], 'name': 'xxx'}
# 获取字典所有的key
>>> dic.keys()
dict_keys(['name', 'age', 'hobbies'])
# 获取字典所有的value
>>> dic.values()
dict_values(['xxx', 18, ['play game', 'basketball']])
# 获取字典所有的键值对
>>> dic.items()
dict_items([('name', 'xxx'), ('age', 18), ('hobbies', ['play game', 'basketball'])])
# 6、循环
# 6.1 默认遍历的是字典的key
>>> for key in dic:
... print(key)
...
age
hobbies
name
# 6.2 只遍历key
>>> for key in dic.keys():
... print(key)
...
age
hobbies
name
# 6.3 只遍历value
>>> for key in dic.values():
... print(key)
...
18
['play game', 'basketball']
xxx
# 6.4 遍历key与value
>>> for key in dic.items():
... print(key)
...
('age', 18)
('hobbies', ['play game', 'basketball'])
('name', 'xxx')
需要掌握的操作
1.get()
>>> dic= {'k1':'jason','k2':'Tony','k3':'JY'}
>>> dic.get('k1')
'jason' # key存在,则获取key对应的value值
>>> res=dic.get('xxx') # key不存在,不会报错而是默认返回None
>>> print(res)
None
>>> res=dic.get('xxx',666) # key不存在时,可以设置默认返回的值
>>> print(res)
666
# ps:字典取值建议使用get方法
2.pop()
>>> dic= {'k1':'jason','k2':'Tony','k3':'JY'}
>>> v = dic.pop('k2') # 删除指定的key对应的键值对,并返回值
>>> dic
{'k1': 'jason', 'kk2': 'JY'}
>>> v
'Tony'
3.popitem()
>>> dic= {'k1':'jason','k2':'Tony','k3':'JY'}
>>> item = dic.popitem() # 随机删除一组键值对,并将删除的键值放到元组返回
>>> dic
{'k3': 'JY', 'k2': 'Tony'}
>>> item
('k1', 'jason')
4.update()
# 用新字典更新旧字典,有则修改,无则添加
>>> dic= {'k1':'jason','k2':'Tony','k3':'JY'}
>>> dic.update({'k1':'JN','k4':'xxx'})
>>> dic
{'k1': 'JN', 'k3': 'JY', 'k2': 'Tony', 'k4': 'xxx'}
5.fromkeys()
>>> dic = dict.fromkeys(['k1','k2','k3'],[])
>>> dic
{'k1': [], 'k2': [], 'k3': []}
6.setdefault()
# key不存在则新增键值对,并将新增的value返回
>>> dic={'k1':111,'k2':222}
>>> res=dic.setdefault('k3',333)
>>> res
333
>>> dic # 字典中新增了键值对
{'k1': 111, 'k3': 333, 'k2': 222}
# key存在则不做任何修改,并返回已存在key对应的value值
>>> dic = {'k1':111,'k2':222}
>>> res = dic.setdefault('k1',666)
>>> res
111
>>> dic
{'k1': 111, 'k2': 222}
六、集合
作用
集合、list、tuple、dict一样都可以存放多个值,但是主要用于:去重、关系运算
定义
定义:在{}内用逗号分隔开多个元素,集合具备以下三个特点:
每个元素必须是不可变类型
集合内没有重复的元素
集合内元素无序
s = {1,2,3,4} # 本质 s = set({1,2,3,4})
# 注意1:列表类型是索引对应值,字典是key对应值,均可以取得单个指定的值,而集合类型既没有索引也没有key与值对应,所以无法取得单个的值,而且对于集合来说,主要用于去重与关系运算,根本没有取出单个指定值这种需求
# 注意2:{}既可以用于定义dict,也可以用于定义集合,但是字典内的元素必须是key:value的格式,现在我们想定义一个空字典和空集合,该如何准确去定义两者?
d = {} # 默认是空字典
s = set() # 这才是定义空集合
类型转换
# 但凡能被for循环的遍历的数据类型(强调:遍历出的每一个值都必须为不可变类型)都可以传给set()转换成集合类型
>>> s = set([1,2,3,4])
>>> s1 = set((1,2,3,4))
>>> s2 = set({'name':'jason',})
>>> s3 = set('egon')
>>> s,s1,s2,s3
({1, 2, 3, 4}, {1, 2, 3, 4}, {'name'}, {'n', 'e', 'o', 'g'})
使用
关系运算
我们定义两个集合friends与friends2来分别存放两个人的好友名字,然后以这两个集合为例讲解集合的关系运算
>>> friends1 = {"zero","kevin","jason","egon"} # 用户1的好友们
>>> friends2 = {"Jy","ricky","jason","egon"} # 用户2的好友们
两个集合的关系如下图所示
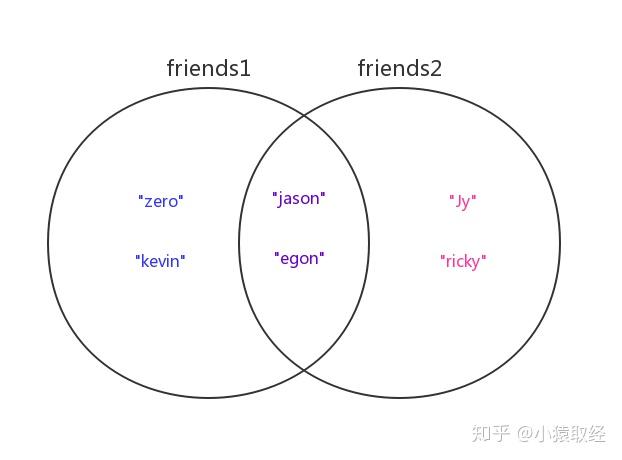
# 1.合集/并集(|):求两个用户所有的好友(重复好友只留一个)
>>> friends1 | friends2
{'kevin', 'ricky', 'zero', 'jason', 'Jy', 'egon'}
# 2.交集(&):求两个用户的共同好友
>>> friends1 & friends2
{'jason', 'egon'}
# 3.差集(-):
>>> friends1 - friends2 # 求用户1独有的好友
{'kevin', 'zero'}
>>> friends2 - friends1 # 求用户2独有的好友
{'ricky', 'Jy'}
# 4.对称差集(^) # 求两个用户独有的好友们(即去掉共有的好友)
>>> friends1 ^ friends2
{'kevin', 'zero', 'ricky', 'Jy'}
# 5.值是否相等(==)
>>> friends1 == friends2
False
# 6.父集:一个集合是否包含另外一个集合
# 6.1 包含则返回True
>>> {1,2,3} > {1,2}
True
>>> {1,2,3} >= {1,2}
True
# 6.2 不存在包含关系,则返回False
>>> {1,2,3} > {1,3,4,5}
False
>>> {1,2,3} >= {1,3,4,5}
False
# 7.子集
>>> {1,2} < {1,2,3}
True
>>> {1,2} <= {1,2,3}
True
去重
集合去重复有局限性
# 1. 只能针对不可变类型
# 2. 集合本身是无序的,去重之后无法保留原来的顺序
# 实例如下
>>> l=['a','b',1,'a','a']
>>> s=set(l)
>>> s # 将列表转成了集合
{'b', 'a', 1}
>>> l_new=list(s) # 再将集合转回列表
>>> l_new
['b', 'a', 1] # 去除了重复,但是打乱了顺序
# 针对不可变类型,并且保证顺序则需要我们自己写代码实现,例如
l=[
{'name':'lili','age':18,'sex':'male'},
{'name':'jack','age':73,'sex':'male'},
{'name':'tom','age':20,'sex':'female'},
{'name':'lili','age':18,'sex':'male'},
{'name':'lili','age':18,'sex':'male'},
]
new_l=[]
for dic in l:
if dic not in new_l:
new_l.append(dic)
print(new_l)
# 结果:既去除了重复,又保证了顺序,而且是针对不可变类型的去重
[
{'age': 18, 'sex': 'male', 'name': 'lili'},
{'age': 73, 'sex': 'male', 'name': 'jack'},
{'age': 20, 'sex': 'female', 'name': 'tom'}
]
其他操作
# 1.长度
>>> s={'a','b','c'}
>>> len(s)
3
# 2.成员运算
>>> 'c' in s
True
# 3.循环
>>> for item in s:
... print(item)
...
c
a
b
练习
"""
一.关系运算
有如下两个集合,pythons是报名python课程的学员名字集合,linuxs是报名linux课程的学员名字集合
pythons={'jason','egon','kevin','ricky','gangdan','biubiu'}
linuxs={'kermit','tony','gangdan'}
1. 求出即报名python又报名linux课程的学员名字集合
2. 求出所有报名的学生名字集合
3. 求出只报名python课程的学员名字
4. 求出没有同时这两门课程的学员名字集合
"""
# 求出即报名python又报名linux课程的学员名字集合
>>> pythons & linuxs
# 求出所有报名的学生名字集合
>>> pythons | linuxs
# 求出只报名python课程的学员名字
>>> pythons - linuxs
# 求出没有同时报这两门课程的学员名字集合
>>> pythons ^ linuxs
可变类型与不可变类型
可变数据类型:值发生改变时,内存地址不变,即id不变,证明在改变原值
不可变类型:值发生改变时,内存地址也发生改变,即id也变,证明是没有在改变原值,是产生了新的值
08python语法入门--基本数据类型及内置方法的更多相关文章
- python入门之数据类型及内置方法
目录 一.题记 二.整形int 2.1 用途 2.2 定义方式 2.3 常用方法 2.3.1 进制之间的转换 2.3.2 数据类型转换 3 类型总结 三.浮点型float 3.1 用途 3.2 定义方 ...
- python 入门基础4 --数据类型及内置方法
今日目录: 零.解压赋值+for循环 一. 可变/不可变和有序/无序 二.基本数据类型及内置方法 1.整型 int 2.浮点型float 3.字符串类型 4.列表类型 三.后期补充内容 零.解压赋值+ ...
- if循环&数据类型的内置方法(上)
目录 if循环&数据类型的内置方法 for循环 range关键字 for+break for+continue for+else for循环的嵌套使用 数据类型的内置方法 if循环&数 ...
- while + else 使用,while死循环与while的嵌套,for循环基本使用,range关键字,for的循环补充(break、continue、else) ,for循环的嵌套,基本数据类型及内置方法
今日内容 内容概要 while + else 使用 while死循环与while的嵌套 for循环基本使用 range关键字 for的循环补充(break.continue.else) for循环的嵌 ...
- wlile、 for循环和基本数据类型及内置方法
while + else 1.while与else连用 当while没有被关键字break主动结束的情况下 正常结束循环体代码之后执行else的子代码 """ while ...
- while和for循环的补充与数据类型的内置方法(int, float, str)
目录 while与for循环的补充 while + else 死循环 while的嵌套 for补充 range函数 break与continue与else for循环的嵌套 数据类型的内置方法 int ...
- python基本数据类型与内置方法
1.数据类型内置方法理论 1.每一种数据类型本身都含有一系列的操作方法,内置方法是其本身自带的功能,是其中最多的. 2.python中数据类型调用的内置方法的统一句式为>>>:句点符 ...
- Day 07 数据类型的内置方法[列表,元组,字典,集合]
数据类型的内置方法 一:列表类型[list] 1.用途:多个爱好,多个名字,多个装备等等 2.定义:[]内以逗号分隔多个元素,可以是任意类型的值 3.存在一个值/多个值:多个值 4.有序or无序:有序 ...
- day6 基本数据类型及内置方法
day6 基本数据类型及内置方法 一.10进制转其他进制 1. 十进制转二进制 print(bin(11)) #0b1011 2. 十进制转八进制 print(hex(11)) #0o13 3. 十进 ...
随机推荐
- 【爬虫】将 Scrapy 部署到 k8s
一. 概述 因为学习了 docker 和 k8s ,不管什么项目都想使用容器化部署,一个最主要的原因是,使用容器化部署是真的方便.上一篇文章 [爬虫]从零开始使用 Scrapy 介绍了如何使用 scr ...
- JS里默认和常用转换
* { font-family: PingFang, Monaco } JS里的六大简单数据类型 string 字符类型 number 数字类型 boolean 布尔类型 symbol ES6语法新增 ...
- 使用HTMLTestRunner在目标目录下并未生成HTML文件解决办法
使用pycharm工具应用HTMLTestRunner模块时,测试用例可以顺利运行,但在目标目录下并未生成HTML文件.使用python的IDLE,能够正常运行并创建写入测试结果. 测试环境:pyth ...
- python分支结构与循环结构
python分支结构 一.if 单条件形式 # 年轻人的世界都不容易 age > 18 age = int(input("请输入您的年龄:")) # input()函数 模拟 ...
- Git在实际生产中的使用
文章目录 Git在实际生产中的使用 简单情况下的代码提交 Fetch and Pull 仅获取某分支的代码 远程仓库已经合并了别人的代码 冲突产生原因与解决办法 不恰当的多个Commit合并为一个 G ...
- 【pwn】攻防世界 pwn新手区wp
[pwn]攻防世界 pwn新手区wp 前言 这几天恶补pwn的各种知识点,然后看了看攻防世界的pwn新手区没有堆题(堆才刚刚开始看),所以就花了一晚上的时间把新手区的10题给写完了. 1.get_sh ...
- Solon Web 开发
Solon Web 开发 一.开始 二.开发知识准备 三.打包与运行 四.请求上下文 五.数据访问.事务与缓存应用 六.过滤器.处理.拦截器 七.视图模板与Mvc注解 八.校验.及定制与扩展 九.跨域 ...
- 工作自动化,替代手工操作,使用python操作MFC、windows程序
目录 背景--为什么要自动化操作? 方法--怎么实现自动化操作? 查找窗体 发送消息 获取文本 总结 背景--为什么要自动化操作? 工作中总是遇到反复重复性的工作?怎么用程序把它变成自动化操作?将程序 ...
- IoC容器-Bean管理XML方式(注入空值和特殊符号)
Ioc操作Bean管理(xml注入其他类型属性), 字面量 (1)null值 (2)属性值包含特殊符号
- Ldap主从复制搭建
LDAP是轻量目录访问协议(Lightweight Directory Access Protocol)的缩写, LDAP协议的特点 读取速度远高于写入速度. 对查询做了优化,读取速度优于普通关系数据 ...