加班时的灵感迸发,我用selenium做了个窗口化的爬*宝数据。(附源码链接)
完整代码&火狐浏览器驱动下载链接:https://pan.baidu.com/s/1pc8HnHNY8BvZLvNOdHwHBw 提取码:4c08
双十一刚过,想着某宝的信息看起来有些少很难做出购买决定。于是就有了下面的设计:
既然有了想法那就赶紧说干就干趁着双十二还没到
一、准备工作:
安装 :selenium 和 tkinter
pip install selenium
pip install tkinter
下载火狐浏览器驱动
二、网站分析
发现web端如果不登录就不能进行查找商品
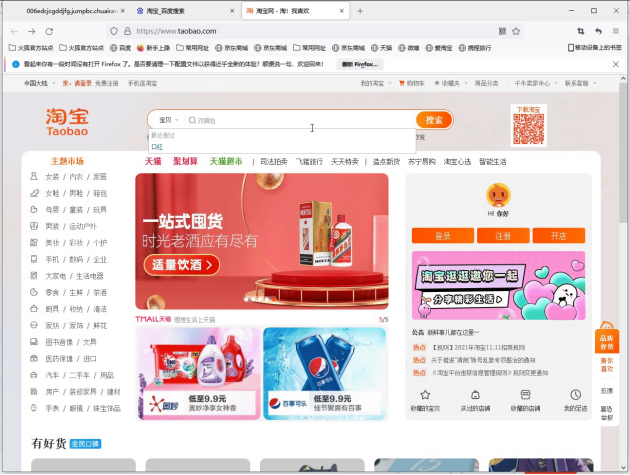
登录后查找口红
发现url竟然张这样
https://s.taobao.com/search?q=口红&imgfile=&js=1&stats_click=search_radio_all%3A1&initiative_id=staobaoz_20211117&ie=utf8&bcoffset=1&ntoffset=1&p4ppushleft=2%2C48&s=44
通过观察发现url中的q=**表示的是搜索的内容 s=**表示页数
接下来确定网页中我们将要采集的数据
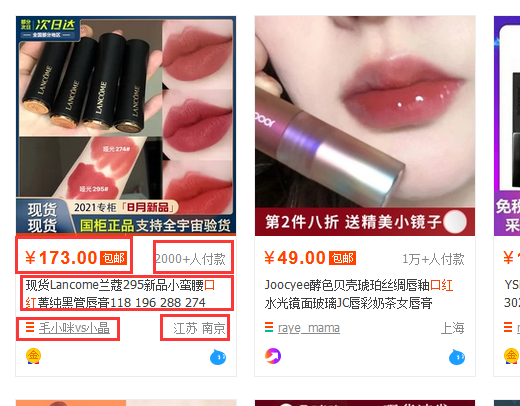
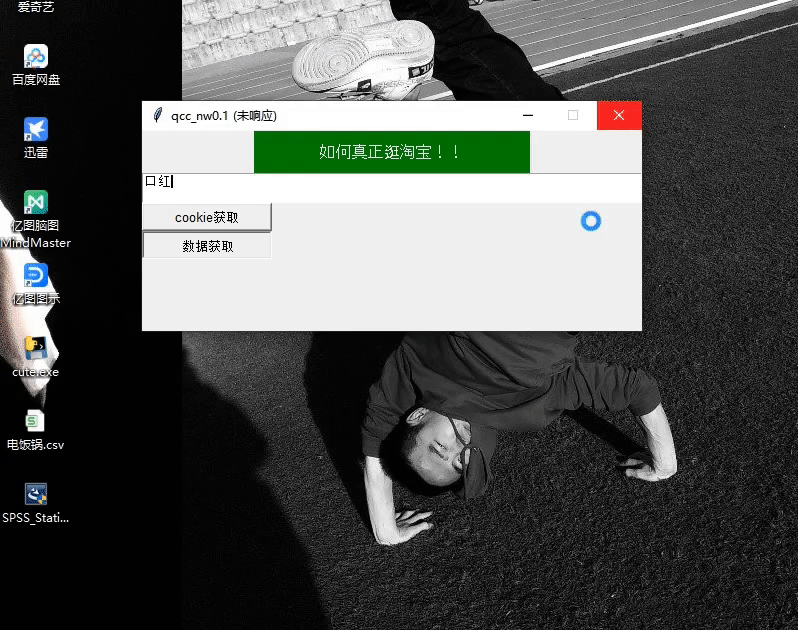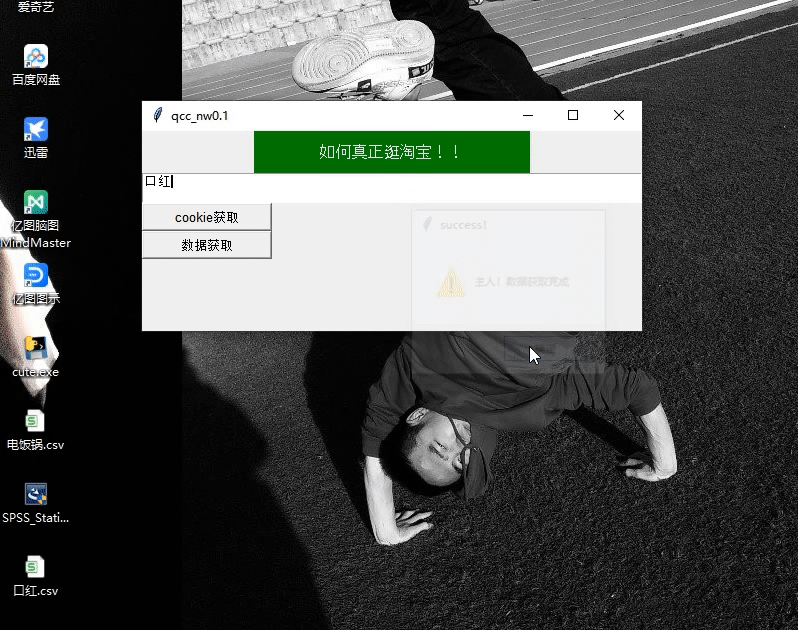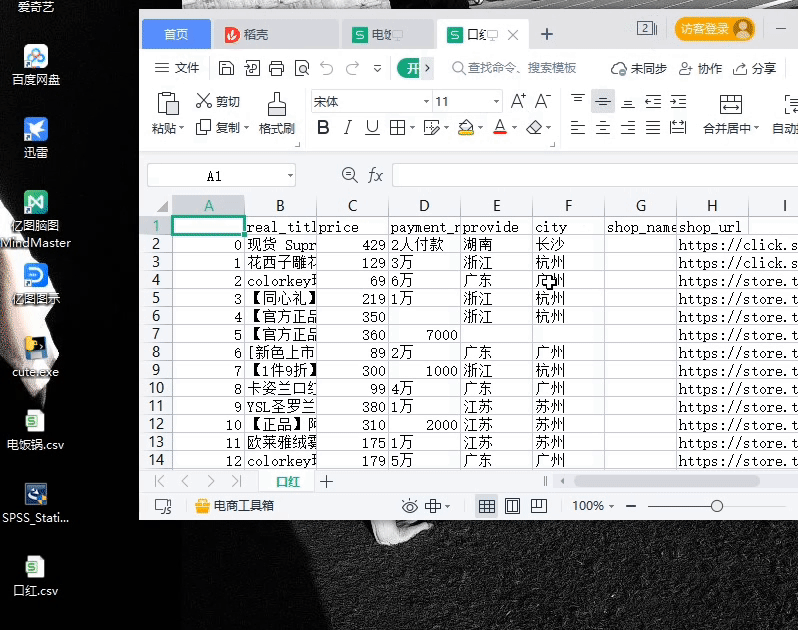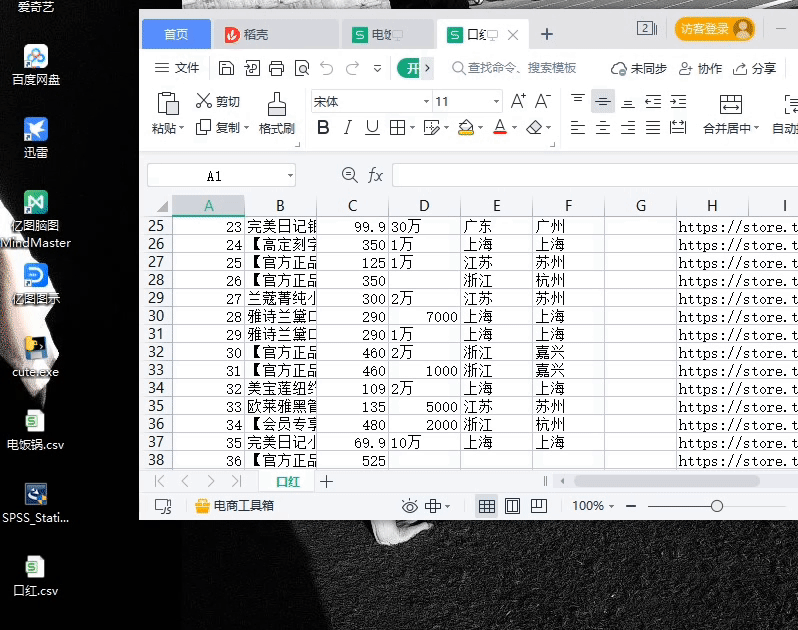
采集的数据有:商品价格;付款人数;商品标题;店铺url;店家地址;
三、代码编写
1、类库引用
import json
import pandas as pd
from selenium import webdriver
import time
from tkinter import *
import tkinter.messagebox
2、窗口化代码实现
# 设置窗口
window = Tk()
window.title('qcc_nw0.1')
# 设置窗口大小
window.geometry('500x200')
# lable标签
l = Label(window, text='如何真正逛淘宝!!', bg='green', fg='white', font=('Arial', 12), width=30, height=2)
l.pack()
# 输入要查询的宝贝的文本框
E1 = Text(window,width='100',height='2')
E1.pack()
def get_cookie():
pass
def get_data():
pass
# cookie获取按钮
cookie = Button(window, text='cookie获取', font=('Arial', 10), width=15, height=1,ommand=get_cookie)
# 数据开按钮
data = Button(window, text='数据获取', font=('Arial', 10), width=15, height=1,ommand=get_data)
cookie.pack(anchor='nw')
data.pack(anchor='nw')
window.mainloop()
3、免登陆功能实现
对已经登录网站的cookie获取
def get_cookie():
# 新建浏览器
dirver = webdriver.Firefox()
dirver.get('https://login.taobao.com/member/login.jhtml?redirectURL=http%3A%2F%2Fbuyertrade.taobao.com%2Ftrade%2Fitemlist%2Flist_bought_items.htm%3Fspm%3D875.7931836%252FB.a2226mz.4.66144265Vdg7d5%26t%3D20110530')
# 设置登录延时获取cookie
time.sleep(20)
# 直接用手机扫码登陆淘宝即可获取
dictCookies = dirver.get_cookies()
# 登录完成后,将cookies保存到本地文件
jsonCookies = json.dumps(dictCookies)
with open("cookies_tao.json", "w") as fp:
fp.write(jsonCookies)
读取获取后的cookie实现登录效果:
1)先对selenium使用的模拟浏览器进行下伪装设置否则会被检测
def get_data():
options = webdriver.FirefoxOptions()
profile = webdriver.FirefoxProfile()
ua = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36'
profile.set_preference('general.useragent.override', ua)#UA伪装
profile.set_preference("dom.webdriver.enabled", False) # 设置非driver驱动
profile.set_preference('useAutomationExtension', False) # 关闭自动化提示
profile.update_preferences() # 更新设置
browser = webdriver.Firefox(firefox_profile=profile, firefox_options=options)
2)读取获取到的cookie实现免登陆
# 删除原有的cookie
browser.delete_all_cookies()
with open('cookies_tao.json', encoding='utf-8') as f:
listCookies = json.loads(f.read())
# cookie 读取发送
for cookie in listCookies:
# print(cookie)
browser.add_cookie({
'domain': '.taobao.com', # 此处xxx.com前,需要带点
'name': cookie['name'],
'value': cookie['value'],
'path': '/',
'expires': None
})
4、解析网页进行数据获取
# 获取输入框中的信息
thing =E1.get('1.0','end') # 设置将要采集的URL地址
url= "https://s.taobao.com/search?q=%s"
# 设置采集的商品名称
browser.get(url%thing)
# 窗口最小化
browser.minimize_window()
# 获取商品总页数
page_count = browser.find_element_by_xpath('/html/body/div[1]/div[2]/div[3]/div[1]/div[26]/div/div/div/div[1]').text
page_count = int(page_count.split(' ')[1])
# 设置接收字典
dic = {'real_title':[],'price':[],'payment_num':[],'provide':[],'city':[],'shop_name':[],'shop_url':[]}
# 循环翻页设置
for i in range(page_count):
page = i*44
browser.get(url%thing + '&s=%d'%page)
div_list = browser.find_elements_by_xpath('//div[@class="ctx-box J_MouseEneterLeave J_IconMoreNew"]')
# 循环遍历商品信息
for divs in div_list:
# 商品标题获取
real_title = divs.find_element_by_xpath('.//div[@class="row row-2 title"]/a').text
# 商品价格获取
price = divs.find_element_by_xpath('.//div[@class="price g_price g_price-highlight"]/strong').text
# 商品付款人数获取
payment_num = divs.find_element_by_xpath('.//div[@class="deal-cnt"]').text
# 店家地址获取
location = divs.find_element_by_xpath('.//div[@class="row row-3 g-clearfix"]/div[@class="location"]').text
# 店家名称获取
shop_name = divs.find_element_by_xpath('.//div[@class="row row-3 g-clearfix"]/div[@class="shop"]/a/span').text
# 店家URL获取
shop_url = divs.find_element_by_xpath('.//div[@class="row row-3 g-clearfix"]/div[@class="shop"]/a').get_attribute('href')
# 判断地址是否为自治区或直辖市
if len(location.split(' '))>1:
provide=location.split(' ')[0]
city=location.split(' ')[1]
else:
provide=location.split(' ')[0]
city = location.split(' ')[0]
# 将采集的数据添加至字典中
dic['real_title'].append(real_title)
dic['price'].append(price)
dic['payment_num'].append(payment_num.replace('+人付款',''))
dic['provide'].append(provide)
dic['city'].append(city)
dic['shop_name'].append(shop_name)
dic['shop_url'].append(shop_url)
print(real_title,price,payment_num.replace('+人付款',''),provide,city,shop_name,shop_url)
# 使用pandas将获取的数据写入csv文件持久化存储
df=pd.DataFrame(dic)
df.to_csv('C:/Users/admin/Desktop/'+thing.strip('\n')+'.csv')
browser.close()
截止至此基本完成
发现这样的数据写入是不会保存的所以要添加一个提示框来终止get_data函数的运行
def warning():
# 弹出对话框
result = tkinter.messagebox.showinfo(title = 'success!',message='主人!数据获取完成')
# 返回值为:ok
在get_data函数中嵌套warning函数.
-----完活下班!!!!-----
加班时的灵感迸发,我用selenium做了个窗口化的爬*宝数据。(附源码链接)的更多相关文章
- selenium实战:窗口化爬取*宝数据(附源码链接)
完整代码&火狐浏览器驱动下载链接:https://pan.baidu.com/s/1pc8HnHNY8BvZLvNOdHwHBw 提取码:4c08 双十一刚过,想着某宝的信息看起来有些少很难做 ...
- 利用js编写一个简单的html表单验证,验证通过时提交数据(附源码)
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8 ...
- 构建ASP.NET MVC4+EF5+EasyUI+Unity2.x注入的后台管理系统(6)-Unity 2.x依赖注入by运行时注入[附源码]
原文:构建ASP.NET MVC4+EF5+EasyUI+Unity2.x注入的后台管理系统(6)-Unity 2.x依赖注入by运行时注入[附源码] Unity 2.x依赖注入(控制反转)IOC,对 ...
- ASP.NET中登录时记住用户名和密码(附源码下载)--ASP.NET
必需了解的:实例需要做的是Cookie对象的创建和对Cookie对象数据的读取,通过Response对象的Cookies属性创建Cookie,通过Request对象的Cookies可以读取Cookie ...
- 关于js渲染网页时爬取数据的思路和全过程(附源码)
于js渲染网页时爬取数据的思路 首先可以先去用requests库访问url来测试一下能不能拿到数据,如果能拿到那么就是一个普通的网页,如果出现403类的错误代码可以在requests.get()方法里 ...
- vue打包时,assets目录 和static目录下文件的处理区别(nodeModule中插件源码修改后,打包后的文件应放在static目录)
为了回答这个问题,我们首先需要了解Webpack如何处理静态资产.在 *.vue 组件中,所有模板和CSS都会被 vue-html-loader 及 css-loader 解析,并查找资源URL.例如 ...
- 曹工说Spring Boot源码(13)-- AspectJ的运行时织入(Load-Time-Weaving),基本内容是讲清楚了(附源码)
写在前面的话 相关背景及资源: 曹工说Spring Boot源码(1)-- Bean Definition到底是什么,附spring思维导图分享 曹工说Spring Boot源码(2)-- Bean ...
- 花时三月 终于Spring Boot 微信点餐开源系统! 附源码
架构 前后端分离: Nginx与Tomcat的关系在这篇文章,几分钟可以快速了解: https://www.jianshu.com/p/22dcb7ef9172 补充: set ...
- 使用TWebBrowser时存在内存泄漏问题的解决方案(使用SetProcessWorkingSetSize函数,或者修改OleCtrls.pas源码解决问题)
用TWebBrower不断打开多个网页,多某些版本的操作系统上运行一段时间后,发现占用系统内存达几百M,直到关闭程序后,占用的内存才能释放. 这个问题在网有很多讨论,比较多人的建议办法是用SetPro ...
随机推荐
- 面试官一口气问了MySQL事务、锁和MVCC,我
面试官:你是怎么理解InnoDB引擎中的事务的? 候选者:在我的理解下,事务可以使「一组操作」要么全部成功,要么全部失败 候选者:事务其目的是为了「保证数据最终的一致性」. 候选者:举个例子,我给你发 ...
- Pandas高级教程之:时间处理
目录 简介 时间分类 Timestamp DatetimeIndex date_range 和 bdate_range origin 格式化 Period DateOffset 作为index 切片和 ...
- 无法解析的外部符号"void_cdecl caffe::caffe_gpu_dot<double>(int,double........)"
将源码中的.cu文件添加到项目中即可,即使创建的就是NVIDIA的项目,也需要把这些个.cu文件添加进来
- HTML5背景知识
目录 HTML5背景知识 HTML的历史 JavaScript出场 浏览器战争的结束 插件称雄 语义HTML浮出水面 发展态势:HTML标准滞后于其使用 HTML5简介 新标准 引入原生多媒体支持 引 ...
- mysql order by语句流程是怎么样的
order by流程是怎么样的 注意点: select id, name,age,city from t1 where city='杭州' order by age limit 1000; order ...
- NX二次开发-调内部函数UGS::UICOMP_enum::set_width(int)更改BlockUI的枚举控件宽度
版本 NX11+VS2013 内容说明 这个内部函数的设置方法,我之前不会,是QQ群里的一位大佬分享出来的. 关于这块,我也百度搜了一下,找到了几个相关的. 1.直接手动修改BlockUI界面 在低版 ...
- NX Open显示符号(UF_DISP_display_temporary_point)
UF_DISP_display_temporary_point 使用方法: 1 Dim x As Double = 0, y As Double = 0, z As Double = 0 2 3 Di ...
- part1 软件测试基础知识面试题(含答案)
1.你的测试职业发展是什么? 测试经验越多,测试能力越高.所以我的职业发展是需要时间积累的,一步步向着高级测试工程师奔去.而且我也有初步的职业规划,前3年积累测试经验,按如何做好测试工程师的要点去要求 ...
- DOM的本质 和 方法
<JavaScript DOM编程艺术> 读书笔记 一句话解释DOM: DOM,即我们所看到的网页,其在浏览器背后的文档结构(树状分支结构),涵盖了每一个节点(称之为对象).可以通过JS等 ...
- pycharm中的terminal和Windows命令提示符有什么区别?二者用pip安装的包是不是位于相同位置?
那要看pycharm使用了什么shell,可以在设置->工具->终端里查看shell path.如果使用的是cmd.exe那就没区别.pycharm终端和Windows命令提示符用pip安 ...